

本文是腾讯云 TVP 王晓波老师在云+社区开发者大会(杭州站)上的演讲,分享了同程艺龙关于如何基于公有云提供的这些基础设施,来简化“多活”架构的一些设计和实践。
今天我们讲什么是“多活”,为什么做“多活”,有什么困难,如果利用云去做“多活”,省哪些事?我们切入正题,什么是多活?其实多活这几年都在讲,都在听多活,但是我们想想看,你问什么是多活的时候,大家一下子说不出去,或者说的很大,明天杭州毁灭,付钱付不了,那杭州什么时候毁灭,还没有。
我去年的时候去德国参观了一个机房。印象中德国机房是一个流水的线非常齐,各种高大上,我参观后发现确实如此:这个机房处在一个乡下的地方,上空是德国政府规定禁飞区,房子是一米多厚的混凝土墙,门是钢板的,因为要防核弹,还有地下,每一层要经过好几道铁门可以进去。
为什么要做这样的防护?因为当时在设计的时候,要保证它的存活率,如果这个机房不存在了,欧洲的数据就没有办法用了,所以要做的很高大上,很有保障性。
我问,为什么没有备份?他们回答说,有备份,在法国,但是没有使用过,因为数据太实时了,如果到法国有耗时,这就没有办法做,是一个小时级的差距,所以要防护做到最强,要防核弹——这么牛!但是,我进去一看,发现内部那个机房其实非常老土,因为是 N 多年前的,现在还在用,好几层大通间,共享一套空调设施,冷通道都没有,还是小型机。
停电怎么办?他们说,电力系统是两套,这样可以防止住。我问,那这里碰到停电的情况多,还是核弹打到的情况多?他们回答,核弹没有过,但是停电多,有一些宕机的时间,甚至有维护的时间。但是,我们互联网提供服务,很难对客户说我们今天晚上不卖货了,今天晚上我们要停机维护——这是不可能的。但是传统的机构里有这样的时间,他们停机维护时间,就是为了让服务器重启一下。
这时候想到多活,怎么做“多活”?机房要“多活”,这个机房明显做不了“多活”,为什么?
因为它的数据太实时了,第二考虑整个机房“多活”,那机房内部有没有“多活”,他那里没有考虑,所以建了一个站,还是很有用的。
如果做多活要从基础设施入手,从水电机房到基础设施,到机柜机架,到网络结构,整个电力设施,上面辅助所有的中间间,如何保证我们多个机房之间把数据准确并且非常实时高效同步到一个点上去。这个好像我们可以做到这个“多活”了,但是依然是一个伪命题,你可以做到真正的百分之百,把一个数据从杭州传到北京吗,肯定有延迟,我的系统架构要做适应,如果下面的一切搞定,就非常简单,一个脚本就多活了,但是数据不可能做到,我要适应这种所谓的延时,或者数据不一致,带来应用架构会改变,整个一系列的会变成革命一样的事,从最底层服务器到最顶层代码和数据的读取,我是读取本地数据还是远程数据,当发生宕机切换的时候我将出现在哪里,这些都要被考虑到。
那么说了这么多,说到“多活”我们会想到什么,第一是网络,我们考虑机房的网络的挂机,这个是促进今天大家都做多活的原因,整个机房会不会引起崩溃,这个事发生远比核弹炸了水淹了,停电了,因为现在很少出现整个城市停电,我之前去西藏旅游碰到一个小县城,当时出现半个城市的停电,但是我在的宾馆还是有电的,因为有柴油机,所以今天遇到停电的情况还是比较少的。

但是另外一件事导致机房瘫痪是非常大的,就是上上代的网络架构,导致整个机房瘫痪,原来我们那里有一个核心交换机,就是潜入层到汇集层,到核心交换机,每一个流量会通过核心交换机交换,一个信息的网络出现了,这是一个标配,经常会给核心交换机放配置,主配,放两台,这种情况下机房非常容易被这种故障导致。
我们有时候有两台机器一台备着,当主机挂了,你的备用机就不会发生 BUG 吗?因为同一个 BUG 代码是一样的,所以当时所有的工程师要进行办公,因为不办公就瘫了,但是到今天的网络,如果新机房采用这种网络模式的机房很少了,大部分是新的,加上 SDN 的管理,这样很难在机房找到网络的单节点,这样的我们认为网络问题是不是可以解决,其实不是,我们要考虑入口在哪里,比如在苏州机房在苏州,当时在外地没有机房的情况下,我们有一件事,叫做江苏公网抖动,一抖动,机房接入是好的,但是骨干网发生故障怎么办,但是某些省,比如有一次发生上海用户访问我们的时候访问不到,因为上海到江苏的主干网有问题,怎么解决?比如简单的就是买一个动态的 CBN。但是还是有问题,为什么?因为每一个节点到你们机房,这些是买的,这条线不是专线,还是主干路,依然会碰到主干网抖动,导致某些人无法访问。这些地方需要各个地方介入入口,调动一些节点,并且用专线进行互联,打到机房,避免网络抖动造成的问题。
还有我有两个机房,我拉一个专线,确实是有看到物流光线过来的,我们一根不安全,拉两根,有时候也不安全,拉四根、十根,但是一百根线是同一个机房,接进来了,我们再接一个三个机房,变成一个环,另外一个点还可以,这是 OK 的,但是只能存在同城,同一个城市的网络。
这想到我们的机房,大家第一想到机房要做双活,机房内部的情况想到比较少,德国的机房整个大房间,在同一个设施提供的情况下一毁具毁,我们在一个老旧的地方部署服务器,尽量不要在一个机柜里,一个冷通道里,尽量在机房的每一个角落,让故障少一点,整体机房的故障比较少,但是几个发点,一个机柜一个冷通道里,发生的故障很多,我可以散开部署。散开部署没有问题,到我们机房改造的时候,可以做什么?其实模块有独立的空调,有独立的电瓶,整个网络都是独立的,每一个模块都是节点,这样考虑机房,还要考虑机房内部模块之间如果挂掉怎么办。
再考虑应用,这些技术都完好的时候来部署应用,在应用在两个机房跑起来的时候,没有问题,但是数据产生问题,如何要数据同步起来,我们程序本身是一个大的单体的应用,所有的都写在一个里面,但是做这些事单体还比较好处理,保证两边数据同步可以了,但是真正的上下复制百分之百同步巨难无比,没有哪家可以做到,但是理论比较简单,但是不可实现,我们不得不进一步拆分,拆分的时候自己给自己拆出事了。
再下来我们数据可不可以做“多活”,是不是在多个逻辑节点里是多活的状态,这个我们大家会忽略一个点,正常是可用数据“多活”可以的,但是没有想到过程数据的多活问题,现在两个机房 AB,正常 50%B 和 50%A,A 出问题要切到 B 去,正常两边数据要同步,切过去发现挂了,可能是两边服务器不一样,一个单点扛不住可能会崩溃,但是如果还是放在那个服务器挂了,我们试过,就是我们的 Cash 数据,这个点太多了,从数据出来到输出,这个过程中无数的节点在做 Cash,做单体的节点的时候都不重要,丢一个没有问题,可以形成新的但是 A 流量和 B 流量,杭州打到杭州,苏州打到苏州,苏州切过来的时候,发现苏州的所有的中间过程都没有,全部打通,这时候需要耗费的资源是多少可以把这个 cash 预留下来,除了 cash 还有 q,如何把丢失的过程接过来也是一个问题。
这么复杂这么难为什么要做“多活”?我一开始也想这个问题,不是给自己找麻烦吗,挂就挂一次有什么大不了,还是有问题的,挂了老板找,用户会叫,我们是不是一定要做到如何的多活?今天世界上很多人都声称把多活做了,永远死不了,但是往往会死。我在想这个事的时候,今天比较流行中台去想这个事,A 在说中台 B 在说,C 要不要做,不能落伍,人家都说中台好,我也做吧,可能 C 被坑进去了,耗费很多的资源做。

到底你要解决容灾还是解决扩容,还是为了双活,还是为了多活,还是为了做异地和同城,还是做多云,一个云挂了,多个不会挂,这样两个云数据怎么打通,杭州某云到苏州某云拉一根线条这个好像不现实。这一系列的选择我们如何选择这个问题放在最后回答。
我们再来看,为什么这些问题排除之后,从几个维度想一下,第一是故障,为了解决故障做了很多的事,从服务器到机房到机构的故障,在影响我们每天的计算机的运行,如何解决这一系列的故障,我如何解决?我要做多活,至少我有一台服务器变成两台服务器,最简单的理论说也是一个多活,因为我有两个多活。
从机房的内网到接入这系列如何备份,网络瘫痪在之前的概率蛮多的,因为没有云的情况,很多都会遇到瘫痪的情况。然后从 BUG 的发生,到中间间的雪崩都会引起故障,所以要避免故障要做快速的故障的恢复,一分钟 10 分钟半小时还是 24 小时恢复,当然也有 24 小时恢复的。第二个点是容量,这也是我要做多活的非常重要的原因,因为业务的增长导致资源匮乏,这时候特别是中小公司,对于大厂来说,放个几万台服务器不是什么问题,但是小公司还是蛮紧张的,因为资源提供者没有那么多提供给你用,就见缝插针,这里放一千台,那里放一千台,最后连不上,扩容有问题。第三是价格不一样,杭州卖机柜价格比较高,我们能不能到隔壁到温州买一个机房,你怎么解决跨城的问题。
还有一个问题是资源不够,我老是拿不到资源,应用等着服务器,等着机房,有空间,但是拿不到,我不在这个区域在另外一个区域,我是否可以拿到机房,这是我们要做双活的考虑。
第二风险的考虑,老旧设施,老一代的网络结构,想到你要把网络改了就好了,但是基础的部分做更新最慢,因为业务爆炸式的增长,不可能说今天老板我们不要卖了,等我两分钟把机房搞一下再卖,因为这些历史包袱到今天还在跑,如何避免这些还在跑的风险。
还有大量的机房调用也有一个机房不够,往往快速拿另外一个机房,两个靠的近还好,离的远,你的应用永远慢,第二是单纯的网络抖动,我要怎么办。还有机房的未知事件,这些加起来是我为什么要做多活的原因。

来了一个问题,怎么选择它?我们的选择是什么?第一个考虑的问题到底在同城建还是异地建,这个考虑的是如果同城网络延时少,单元化的要求变小。因为我们发现应用价格发生了变化,做成一个一个单元,包含多少服务多少应用,是一个闭环的,这个其实说起来就是一个计划,做起来极其麻烦,在同城因为网络延迟小,可能要求没有那么高,有两个机房,苏州有太湖和阳澄湖,两个机房可以直接互通,可以数据读取。但是异地的时候就发生了,我们发现北京有一个机房,如果用这样的方式应用服务器在苏州,数据库在北京,基本不用玩了,因为延时已经耗死你了,这时候先考虑同城,后考虑异地。
最后是容灾还是扩容,仅仅是解决容灾问题我们选择路径更多,我们是不是用花这么大的代价做多活,还是可以等等一些时间的,我只要做一个储备,数据可以做一个冷备,因为真正的故障没有那么多,不可能每家公司都做多活,也没有发生一片灾难,所以基础设施本来也在做双活,做灾备,也是可以的。这个事相对来说可以做弱一点,因为我们更多可以把资源放在我们急需的业务。
双活还是多活,其实数量的变化会带来质变,有一些同步的事会相对比较简单,这样只要两个点的同步都可以,但是多个点会发现不现实。
再下来是成本的问题,这个考虑非常大,这个成本我们在想这个事,分两个块,本身做这个事要做多少钱,要重新选择机房,这个是一个本身的成本,第二个成本是这个事做完之后到底产生多少效益,这个事做好了我挽回多少损失,增加多少订单,如果没有结果,像德国的那个机房,一米的混凝土,还有防核弹,这个理论上说成本是不核算的,人都炸了,还要系统干什么。

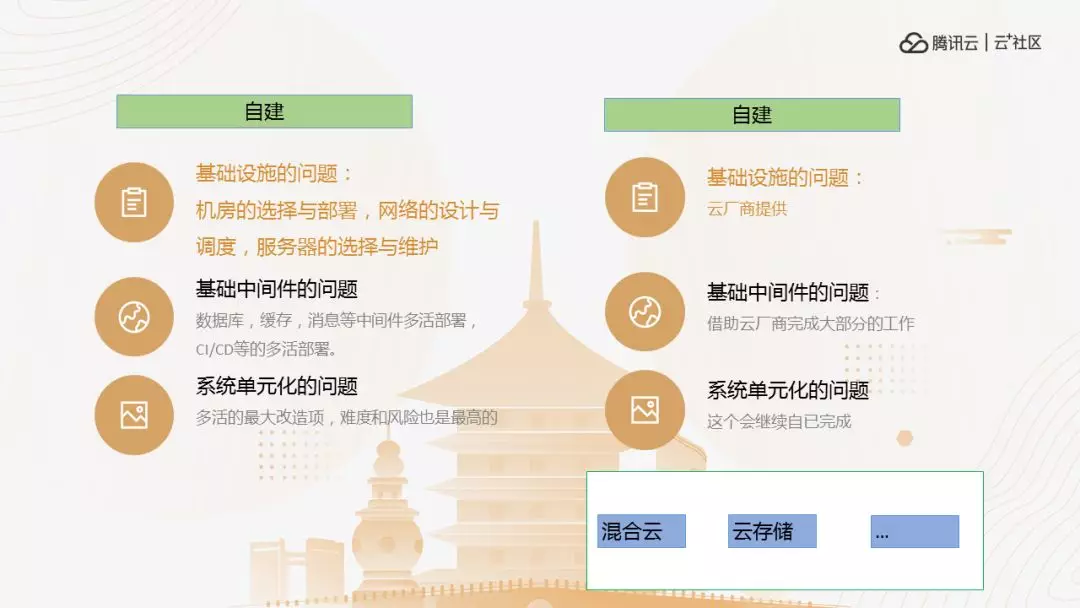
我们从容灾,走到双活到多活,从同城到异地。我们利用一部分云的资源解决,因为要找一个机房很麻烦,机房扩容很难,机位也很难。比如向腾讯申请 10 万,腾讯说不好意思,下个月,这是不现实的,基础设施的选择,腾讯的网络结构完成不是我们说的上上上代的网络机构,第二基础设施,机房容灾已经考虑过了,利用云做机房的时候,其实把这个事会做的简单一点。
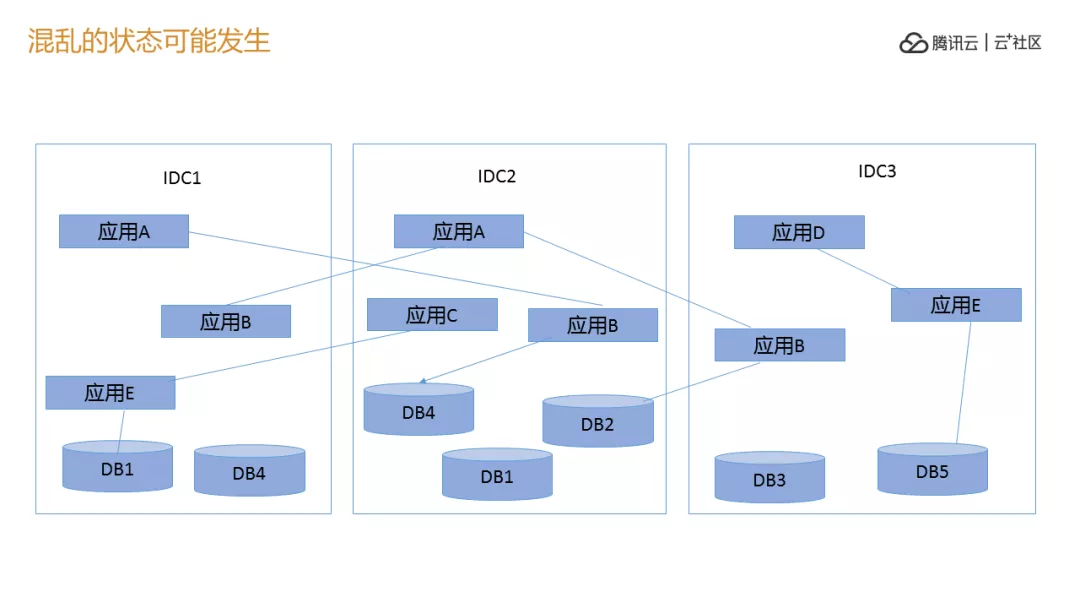
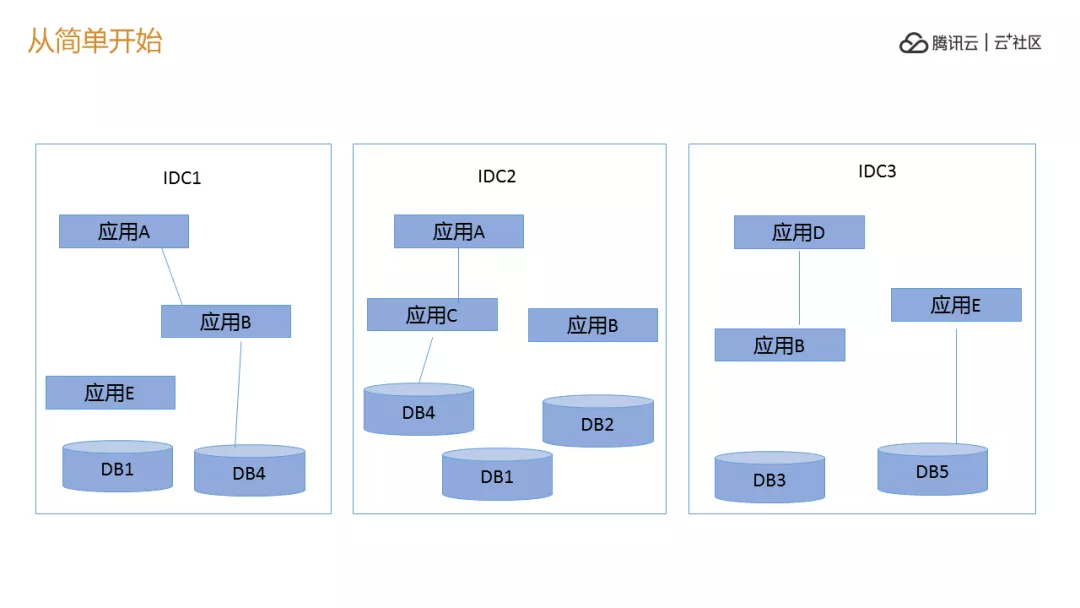
其实这个时候我们有一个问题,往往出现这种情况,因为都是通的,有专线,然后一把调过去,出现一个缓慢的调用,A 机房到 B 机房到 C 机房的数据库,到任何几个机房发生故障的时候三个机房一块完蛋。我们想变成不管几个机房,让任何一个点挂的时候,另外两个不挂,可以把其中一个服务切换到另外一个点上,这是我们的想法。
这个想法本质上可以的,是一个去单点的过程,我们有多少单点去,去服务器和数据库的单点,网络的单点,机房的单点,部署地的单点。
服务机单点很容易,加一个服务器可以了,如果用传统的,再加服务器比较难。我们现在看去应用单点化,如果是一个简单的单体应用这样的一个应用,我们要把它去单点怎么办,因为他的多活问题不存在他是机房,因为本身逻辑耦合导致任何逻辑输出一定要 pass 掉,所以我们开始做微服务,然后带来新的问题,可以熔断、限流、降级,很好。但是其实本质上问题是没有被解决,大量的微服务的产生,如果多机房状态可以想象成如果做刚才的那把机房做自闭环的时候每个节点,因为你应用的部署点多了,你的关系多了,你要降到哪里,你现有的几乎微服务的中心都没有考虑我如何降到另外一个机房,这些怎么做?都要自己做。
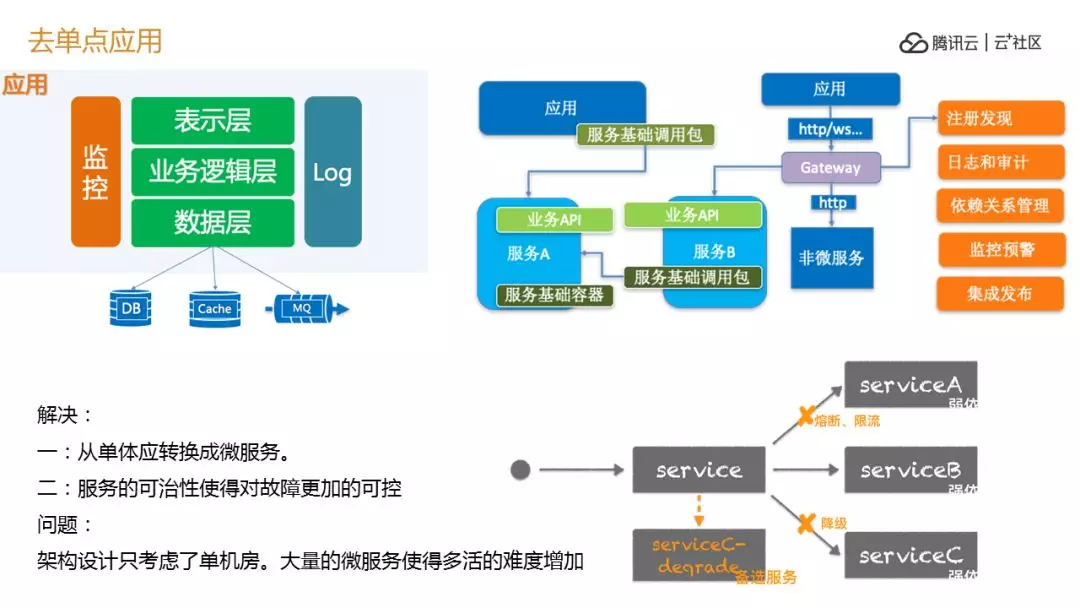
我们要对所有的微服务做一个全局的服务中心,我们很多的节点有我们的注册中心在,这几个中心都要打通,他的关系不能跨机房,本机房的控制中心只给本机房用,当它发生切换熔断的时候,要告诉全局注册中心这个机房不可以用,应该到 2 或者 3 去。
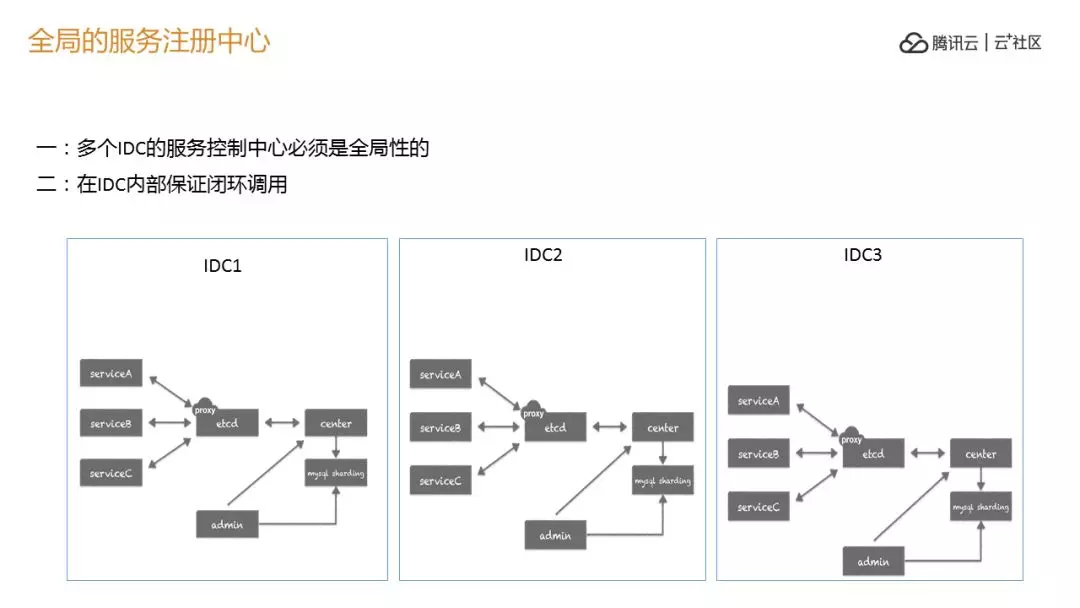
这是去数据库的单点,当我们做完之后有一个问题,混层的问题,大量异机房的各种服务,所以我们把下面的中间件沉下去,变成一个中间服务器,我们自己做了一个满负荷的协议,其实是伪装的,其实是中心件。这样保证我们数据库链接问题,在单机房的时候这些问题 OK 了,但是跨机房的时候,我们正常会分成 1024 个数据库,同城是比较早实现满负荷部署的容器里,这个建完之后,一跨机房一跑完蛋了,很多东西在另外一个机房,整个调用的延时就出来了,我们要做一个规划,不要跨机房划分。
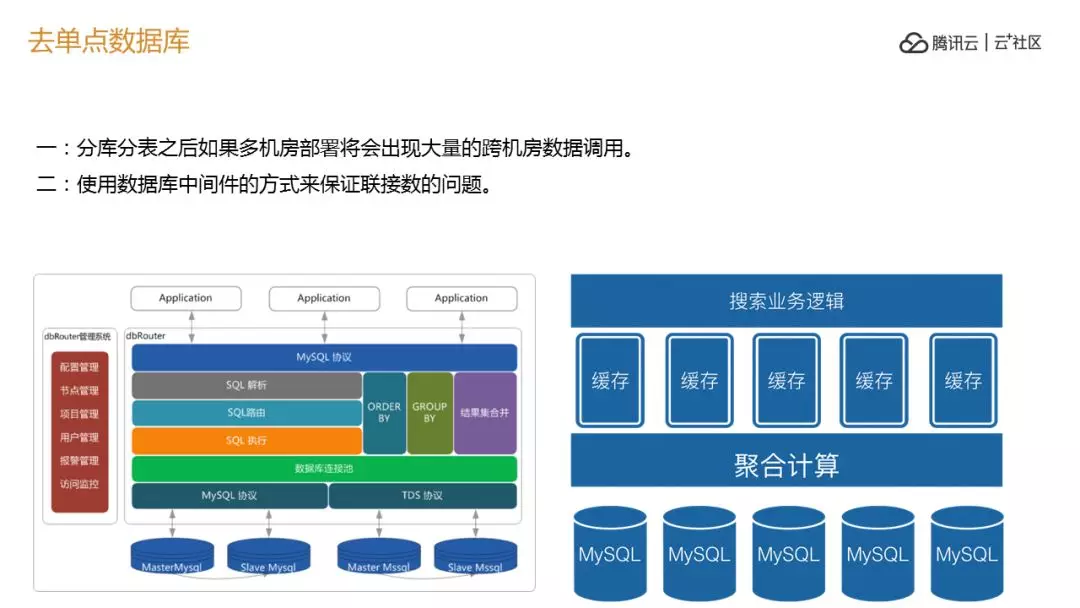
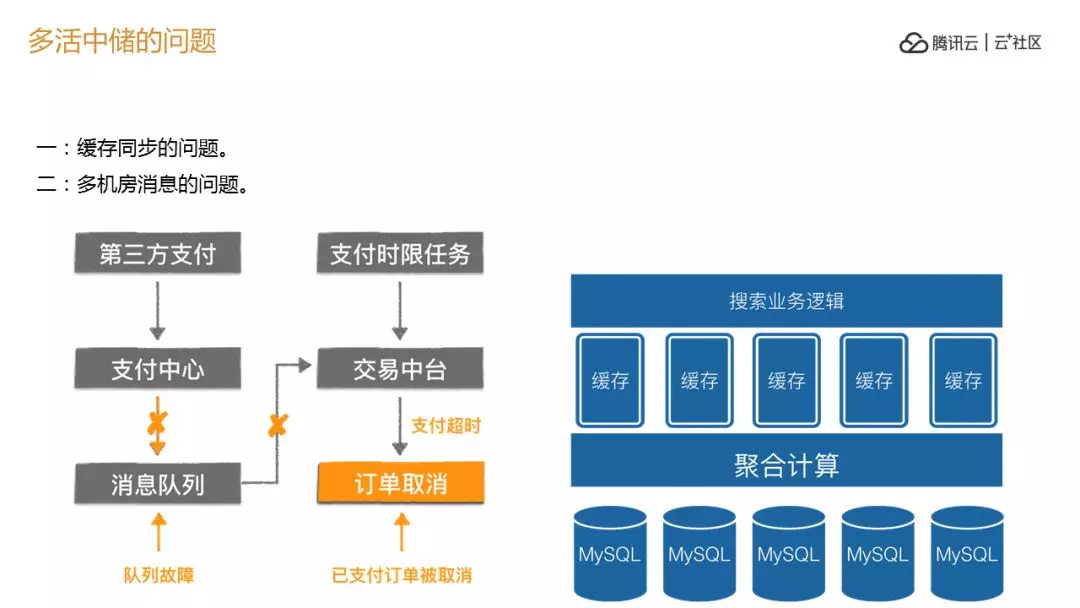
在这个过程中会形成一个问题,缓存的问题,这样会有一个 cash,如何换到另外一个机房去,保证切换的时候提前规划谁可以切换到谁,可以提前规划,哪些 cash 可以预热,整个同城所有的都是治理的结果,所以知道中间数据被谁使用。
另外一个是消息,非常麻烦。举个例子支付完会推送告诉你支付成功了吗,一般放一个 Q 在那里,告诉你订单成功不要取消,放 Q 的地方挂了,中间断了怎么办,这时候要对中间件进行改造,让它可以做多机房的切换。
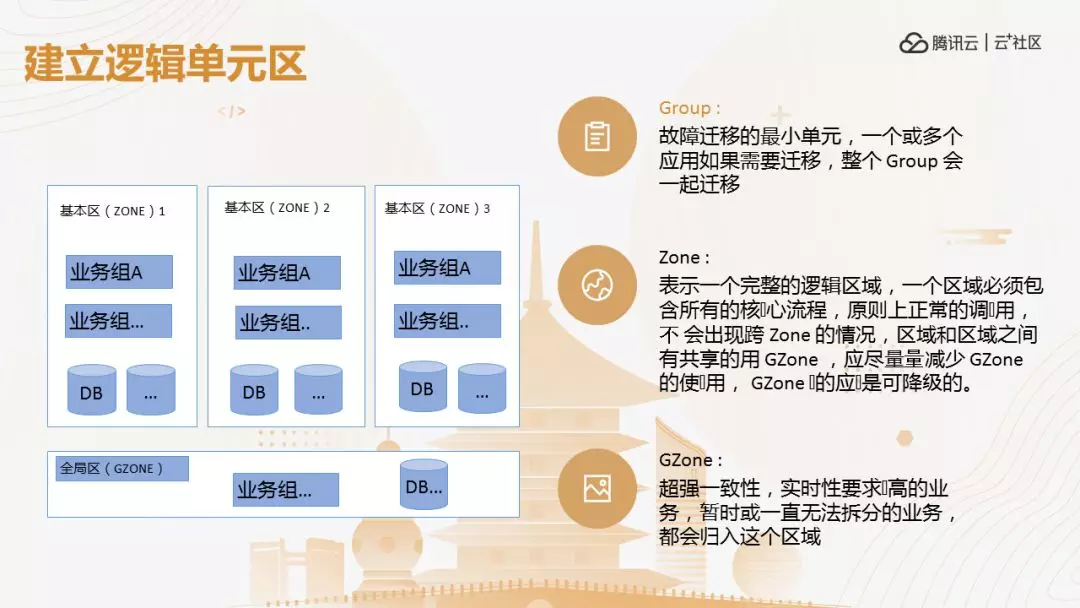
再下来我们单元化改造,用户进来一系列的东西在一个单元完成,看起来很简单,同步起来就好了,但是我们的业务真的这么简单吗,如果是一级代码就简单了,不用做了,比如我们一个买机票的数据,经过 N 多级的计算,比如今天杭州萧山到巴黎,到底多少架飞机可以去,这个数据是活的,每一个飞机去的时间不一样,价格也不一样,是阶梯的价格,根据时间查询不一样,时间不一样,人数不一样,价格一直不一样,价格和交易市场一样,价格一直变化,不像做电商袜子三块钱,一直是三块,它不一样,这个变化非常多,怎么做单元化非常难,我们画单元区,第一是 Group 区,可以切的最小的单元,一个 Group 在一个机房里面,这个机房可以画一个基本区,我们叫 ZONE,这个是逻辑区,多个 Group 形成一个圈层,当你这个区建立好之后,如果按照这么部署,把所有的代码布了 N 多份,一个是成本问题,还有一个问题是下面很多的数据,订单处理后台怎么多活?比如我的风控的离线的数据计算要不要多活,这一系列的问题会发生,所以做全球机动的一个 ZONE 的区域,实施业务,暂时无法区分的业务都在这里,在整个机构里完成这些不可拆分的基础的数据。
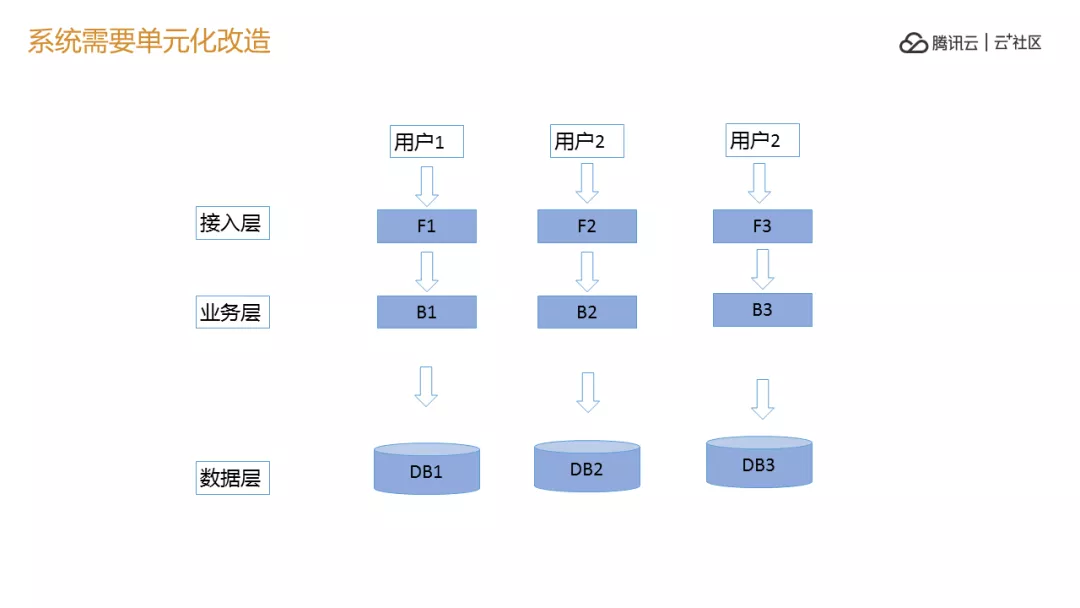
当发生区域调动的时候,AGroup 到 BGroup,AZONE 到 BZONE,会提前调动。这是整个的结构,我们自己建立这些接入端不可能,太贵了,第二是到自己网关层,会识别用户是在哪里,识别出来是谁,每一个 ZONE 有一个识别探针。
这是对云数据进行管理,当发生多活情况的时候,你应用的部署到服务器的部署,整个 CMB 最原始的单机已经无法支撑了,所以建立业务级的 CMB 做更多云数据迁移,然后故障迁移的时候会判断关联应用是什么,这个关联应用一定是在一个 Group 里面,把 Group 迁掉,进行恢复。
这些做完之后还有整个线上的流量,如果不做迁移的时候并不能体现是高容量。再下来我们的难点是什么,基础设施,中间件,还有单元化的服务,这些都很重要。如何让云平台加速?第一是基础设施,如果用一个云话,我整个机房内部云都是要搞定的,不需要再操心。还有中心件,我的 Q 我的 CASH 都要做,这些东西目前都不是百分之百可以决定,但是大部分可以用云解决掉,还有单元化的问题,这部分我认为云帮不上忙,这是我们自己做的,因为任何一家云厂商没有提供一个开箱即用的服务,叫多活,两百块钱买一个多活用一天,是没有的,所以只能通过这几步做掉。
最后希望大家重新考虑多活这个事,是不是真的要做百分之百的多活,到底可以做到怎么样,是一个问题,所以每一步的选择非常重要,成本和真实的需求,最后反映到到底要做一个什么样的多活,谢谢大家。
作者介绍:
王晓波,腾讯云 TVP,同程艺龙机票事业群 CTO。专注于云计算,高并发互联网架构设计、分布式电子商务交易平台设计、大数据分析平台设计、高可用性系统设计。拥有十多年丰富的业务技术架构,基础架构经验,深刻理解技术驱动力的重要性。
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:
https://mp.weixin.qq.com/s/AOy61BvdAKkwdETdVx0zMg

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论