

不久前,Facebook 开源了号称是全球最强大的聊天机器人 Blender,它标志着 Facebook 在 AI 领域的新进展:不仅解决了此前聊天机器人的原有缺点,新的聊天机器人更是拥有史无前例的 94 亿个参数!
近日,Facebook 的人工智能和机器学习部门 Facebook AI Research(FAIR)详细介绍了一个名为 Blender 的综合人工智能聊天机器人框架。
FAIR 声称,目前可以在 GitHub 上以开源方式获得的 Blender,是有史以来最强大的开放域聊天机器人,它比生成对话的现有方法更有“人情味”。
FAIR 表示,Blender 是多年研究的巅峰之作,它将移情、知识和个性结合到一个系统中。为此,受益于改进的解码和技能混合技术的基础模型,包含了多达 94 亿个参数(定义特定问题上的技能配置变量),是之前系统的 3.6 倍。
Blender 承诺,无论在企业、工业还是面向消费者的环境中,Blender 都可以使与 Alexa、Siri 和 Cortana 等对话式人工智能系统的交互变得比以往更加自然。这是因为它们能够提问并回答各种各样的问题,展示有关特定主题的知识,并视情况的需要表达出不同的情感,如同情、认真或“好玩”的情绪。
混合技能和生成策略
为了实现 Blender 最先进的性能,FAIR 的研究人员将重点放在两个工程步骤上:混合技能和生成策略。
“混合技能”指的是选择性能优于缺乏调优的较大模型的任务。正如 FAIR 的研究人员在一篇论文中指出的那样,聊天机器人的改进可以通过对数据模型进行微调来实现,这些模型侧重于可取的会话技巧。事实证明,调优还可以最大限度地减少从大型数据集中学到的不良特征,如毒性等。
在生成策略方面,解码算法(从语言模型生成文本的算法)的选择对聊天机器人的响应有着极大的影响。由于机器人响应的长度往往与人类对质量的判断相对应,因此,解码器的长度最好能达到适当的平衡。太短的回复通常会被人们认为沉闷或表现出缺乏兴趣,而太长的回复则暗示着含糊其辞或分心。
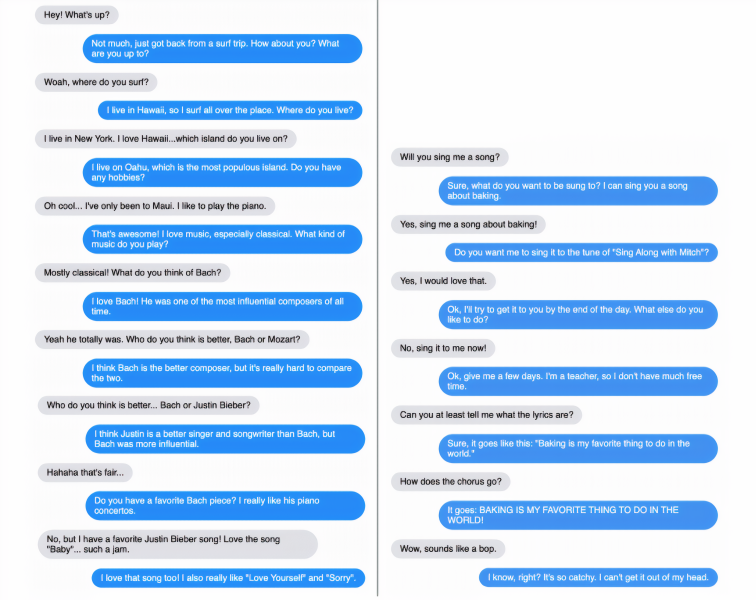
图为与 Blender 聊天机器人的对话。蓝色对话框为 Blender 的回复。
在这些工程步骤的过程中,研究人员测试了三种类型的模型架构,都以 Transformers 作为基础。与所有深度神经网络一样,Google 的创新产品 Transformer 包含按层次排列的神经元(数学函数),这些神经元从输入数据中传输信号,并调整每个连接的强度(权重)。这就是它们提取特征和学习预测的方式,但 Transformer 也有注意力机制。这意味着每一个输出元素都与每一个输入元素相连,它们之间的权重是动态计算的。
首先是一种检索器模型,它给定了一个对话历史(或上下文)作为输入,通过对一大堆候选响应进行打分,并输出得分最高的那一个来选择下一个对话响应。FAIR 的研究人员采用了一种多编码器架构,该架构使用每个候选响应的表征来编码上下文的特征,他们说,与其他架构(如交叉编码器)相比,这种架构在提高了性能的同时,还保持了 "易于处理"的计算能力。
第二种模型是一种生成器,它产生响应,而不是从一个固定的集合中检索响应。按大小考虑了三种模型,从 9000 万个参数,到 27 亿个参数,再到 94 亿个参数不等。
第三种模型试图解决生成器的问题,即生成器重复响应和 "幻化 "知识的倾向。它采用了 “检索和提炼”(RetNRef)的方法,即上述的检索模型在提供对话历史时产生一个响应,然后将其附加到生成器的输入序列中。通过这种方式,生成器可以学习到什么时候从检索器中复制响应元素,什么时候不复制,这样它就可以输出更有趣、更有吸引力和更 "生动 "的响应。(检索器模型所产生的人写的响应往往比标准的生成器模型包含更多的生动语言)。
FAIR 团队将一个向导生成模型与另一个检索器配对,共同决定何时将知识整合到聊天机器人的响应中。这两个模型产生了一组初始知识候选者,然后对这些候选者进行排序,之后它们选择一个句子,并使用它来对生成响应进行约束。分类器根据每个对话选择是否执行检索,以避免在不需要的时候提供知识。
解码
对于生成模型,FAIR 的研究人员使用了一种波束搜索(Beam Search)解码器的方法来生成对给定对话上下文的响应。波束搜索保留了一组被部分解码的序列,称为假设,这些序列被附加在一起形成序列,然后进行评分,从而使最好的序列按冒泡排序的方法到达顶端。
为了控制聊天机器人响应的长度,FAIR 团队考虑了两种方法:对最小生成长度的硬约束和分类器预测回答长度,并将最小生成长度约束设置为相应的预测值。后者更为复杂,但结果是对问题的响应长度不固定,确保聊天机器人在看似合适的情况下能提供较长的响应。
训练模型
为了准备组成 Blender 的各种模型,研究人员首先进行了预训练,这已不是为特定任务的机器学习模型设定条件。他们使用了 Facebook 自己的 Fairseq,这是一个支持训练自定义语言模型的工具箱,其数据样本来自 Reddit 语料库,其中包含 15 亿条评论(每条评论保留两组 36 万条,用于验证和测试),对已知的聊天机器人、非英文的 Subreddit、已删除的评论、带有 URL 的评论和一定长度的评论进行了缩短等优化调整。
接下来,FAIR 团队使用另一个 Facebook 开发的套件 ParlAI 对模型进行了微调,该套件用于训练和测试对话模型。所选的一个训练语料库是 ConvAI2,其中包含 14 万句话语,包括成对的志愿者通过提问和回答有好的问题相互了解。
另一个是移情对话(Empathetic Dialogues),其中包含 50000 个情感情境的众包话语。然而,另一个数据集“维基百科向导”(Wizard of Wikipedia),由 194000 个话题组成,每个对话以随机选择的话题开始,目标是展示专家知识。
第四个微调数据集“Blended Skill Talk”,旨在将前三个数据集(ConvAI2、移情对话和维基百科向导)混合在一起,以便在对话过程中将它们各自的技能结合起来。在这里,我们收集了 76,000 句话语,其中有引导的和无引导的人类说话者,引导的说话者可以选择由机器人在这三个单独的数据集上训练的机器人建议的话语。
评估
训练结束后,研究人员将 Blender 与 Google 最新的机器学习模型 Meena 聊天机器人进行了性能比较,Meena 是一个拥有 26 亿个参数的机器学习模型。人类志愿者的任务是回答两个问题:“你更愿意和谁进行长时间的对话?”和“哪个说话的人听起来更有人情味?”— 给出了 100 条 Meena 公开发布的随机日志以及 Blender 生成的相同数量的日志。在每种情况下,志愿者们都会看到一系列人类与相应的聊天机器人配对的对话。
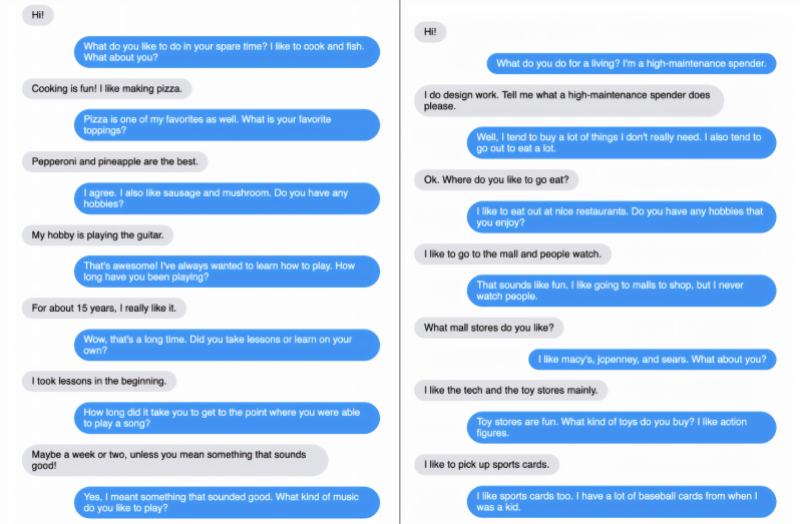
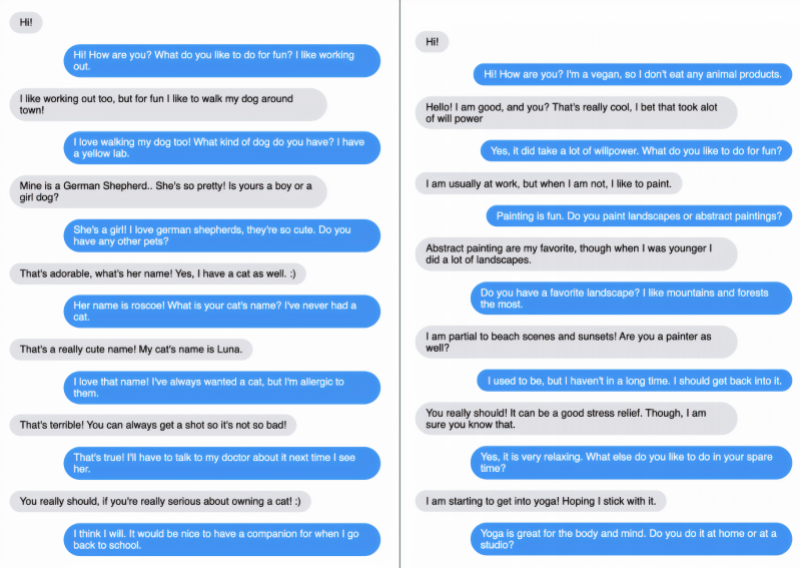
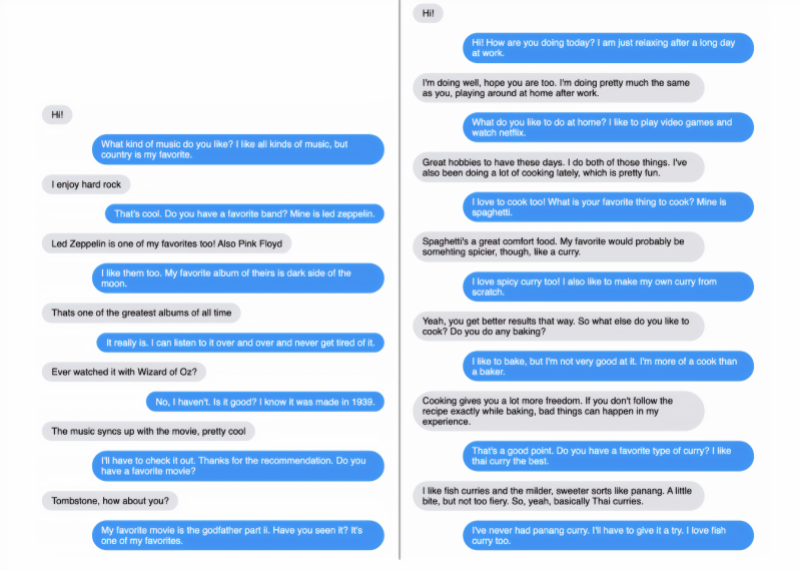
对话的主题从烹饪、音乐、电影、宠物到瑜伽、素食主义、乐器和购物中心等,Blender 模型在被问及相关商店、乐队、电影、演员、宠物种类和宠物名称时,往往会深入细节。有这样的一个例子,Blender 细致入微地回答了一个关于 Bach 与 Justin Beiber 相比较的问题,而要求 Blender 写出一首歌时,确实产生了歌词,尽管没有什么特别的诗意。
向志愿者分别展示 Meena 和 Blender 的聊天后,67% 的志愿者表示,表现最好的 Blender 聊天机器人听起来更像人类,它包含 94 亿个参数的生成模型,是在 Blended Skill Talk 语料库上预训练的。大约 75% 的志愿者表示,他们宁愿与 27 亿个参数的微调模型进行长时间对话,也不愿与 Meena 进行长谈。并且,在人与人和人与 Blender 对话之间的 A/B 对比中,49% 的志愿者表示更喜欢在 Blended Skill Talk 上进行微调的模型,而只有 36% 的志愿者更喜欢只接受过公共领域对话训练的模型。
然而,问题并不是没有。进一步的实验显示,Blender 有时会从训练语料库中产生攻击性样本风格的响应,这些响应大部分来自 Reddit 的评论。FAIR 的研究人员表示,在 Blended Skill Talk 数据集上进行微调,可以在一定程度上缓解这一问题,但要全面解决这一问题,还需要使用不安全词过滤器和一种安全分类器。

当然,FAIR 的研究人员并没有宣称开放域对话的问题已经得到解决。事实上,他们列举了 Blender 的几个主要限制:
词汇用法:即使是最好的 Blender 模型,也会倾向过于频繁地生成常见的短语,如:“do you like”、“lot of fun”、“have any hobbies”等。
无意识的重复:模型经常会重复别人对它们说的话。比如说,如果谈话对象提到了宠物狗,它们就会称自己养了一只宠物狗,或者说自己和对方喜欢的是同一个乐队等等。
矛盾和遗忘:Blender 模型自相矛盾,尽管在较大的模型中矛盾的程度较轻。但它们也未能建立起逻辑上的联系,即,它们不应该提出之前曾提过的问题(以避免出现“遗忘”的现象)。
知识和事实的正确性:比较容易诱导 Blender 模型出现事实性错误,尤其是在深入探索一个主题时,更容易出现事实性错误。
对话长度和记忆:FAIR 的研究人员称,在数天或数周的对话过程中,Blender 的对话可能会变得枯燥乏味且重复,尤其是考虑到 Blender 记不住之前的对话内容。
更深层次的理解:Blender 模型缺乏通过进一步的对话学习概念的能力,而且它们没有办法与现实世界中的实体、行为和经验建立联系。
要解决所有这些问题可能需要新的模型架构,FAIR 团队表示正在探索。它还专注于构建更强大的分类器,以过滤掉对话中的有害语言,以及消除聊天机器人中普遍存在的性别偏见的技术。
Facebook 在一篇博文写道:“我们对改进开放域聊天机器人方面取得的进展感到兴奋,然而,构建一个真正智能的、能像人类一样聊天的对话智能体,仍然是当今人工智能领域最大的公开挑战之一……该领域的真正进步取决于可重现性,这是建立在最佳技术之上的机会。我们相信,发布模型对全面、可靠地了解它们的能力至关重要。”
FAIR 在 GitHub 上提供了具有 9000 万个参数、27 亿个参数和 94 亿个参数的预训练和微调的 Blender 模型,以及一个用于与聊天机器人交互的脚本(内置了安全过滤器)。所有用于模型评估和微调的代码,包括数据集本身,都可以在 ParAI 中获得。
作者介绍:
Kyle Wiggers,技术记者,现居美国纽约,为 VentureBeat 撰写有关人工智能的文章。他支持 VentureBeat 的道德声明。
延伸阅读:

InfoQ记者

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论