

现如今,互联网服务正经历着根本性的变化,并逐渐转向智能计算时代。现代互联网服务提供商普遍采用人工智能来增强其服务。在这种背景下,研究人员提出了许多创新的人工智能算法、系统和架构,因此基准(benchmark)和评估基准的重要性也随之上升。然而,现代互联网服务采用基于微服务的体系结构,由多种模块组成。这些模块的多样性和执行路径的复杂性、数据中心基础设施的庞大规模和复杂层次结构、数据集和工作负载的保密问题对设计基准提出了巨大挑战。
这篇论文中,百度、阿里、腾讯等几家顶级互联网服务提供商联合中国的 17 个互联网企业共同推出了第一个具有行业标准的互联网服务 AI 基准——AIBench。AIBench 提供了一个高度可扩展、可配置、灵活的基准测试框架。作者从三个最重要的互联网服务领域(搜索引擎、社交网络和电子商务)中确定了 16 个较为突出的人工智能问题领域。在 AIBench 框架的基础上,作者利用真实世界的数据集和工作负载,设计并实现了第一个端到端的互联网服务 AI 基准。在 CPU 和 GPU 集群上,作者对端到端应用程序基准进行了初步评估。与 AI 相关的组件显著地改变了互联网服务的关键路径和工作负载特性,证明了端到端 AI 应用程序基准的正确性和必要性。这篇论文是目前为止最全面的 AI 基准工作。我们将在 AI 前线第 92 篇论文导读中详细解读这项 AI 基准工作。
AIBench 网页:
http://www.benchcouncil.org/aibench/index.html
1 介绍
人工智能技术的进步为图像、视频、语音、音频等处理技术带来了突破,推动了大规模人工智能算法、系统和体系结构的部署,因此现代互联网服务提供商普遍采用人工智能来增强其服务。例如,阿里巴巴提出了一种新的 DUPN 网络,以实现更有效的个性化。Google 推出了 TensorFlow 系统和 TPU 来提高服务性能。亚马逊采用人工智能进行智能产品推荐。
因此,测量和评估这些算法、系统和体系结构的压力逐渐增大。首先,现实中的数据集和工作负载被互联网服务提供商视为一级机密问题,只有少数公开可用的性能模型,或针对行业规模互联网服务的研究成果可用于进一步研究。由于没有公开的互联网服务基准,只有内部的研究人员才能推动互联网服务的现状,这种不可持续的状态对推进开放式互联网服务造成了巨大障碍。
其次,人工智能已经渗透到互联网服务的几乎所有方面。因此,为了覆盖现实人工智能场景的关键路径和突出特点,应该提供端到端的应用基准(application benchmarks)。我们需要找到具有代表性的数据集,总结出主要的人工智能问题领域(组件基准,component benchmarks),并进一步了解什么是最密集的计算单元(微基准,micro benchmarks),在此基础上,我们可以构建一个简洁而全面的人工智能基准框架。
最后,从体系结构的角度来看,在早期阶段将一个完整的人工智能应用程序移植到一个新的体系结构是很困难的,甚至是不可能的。而在后期,仅仅使用微基准或组件基准则不足以对不同模块进行深入分析,或在现实应用场景中确定瓶颈问题。目前最先进的 AI 基准只提供了很少的微基准或组件基准,均无法覆盖行业规模的互联网服务的全部案例。因此,构建一个由全部的微基准或组件基准,以及端到端应用基准组成的互联网服务 AI 基准,对于弥合这一巨大缺口具有重要意义。
论文贡献:
提出并实现了一个高度可扩展、可配置、灵活的人工智能基准框架。
与 17 个行业合作伙伴共同确定了 16 个突出的人工智能问题领域,并相应地针对这些领域实施了 16 个组件基准。
设计并实施了第一个行业规模的端到端互联网服务人工智能基准,其中包含一个底层电子商务搜索模型。
在 CPU 和 GPU 集群上,实现端到端的互联网服务 AI 基准,并对性能、运行效率和执行时间进行了深入分析,为进一步优化提供了指导。
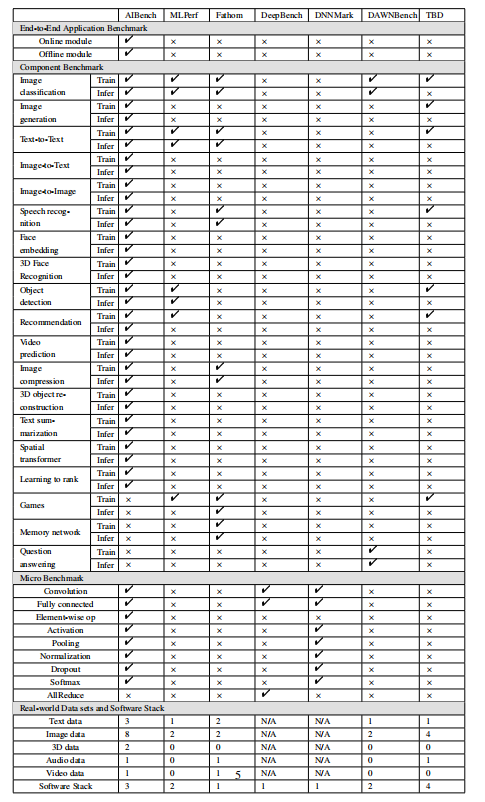
表 1:AI 基准对比
2 AIBench 框架
2.1 框架结构
AIBench 框架提供了一个通用的、灵活且可配置的 AI 基准框架,如图 1 所示。它提供了松散耦合的模块,这些模块可以通过配置和扩展组成端到端的应用程序,包括数据输入、人工智能问题领域、在线推理、离线训练和部署工具模块。
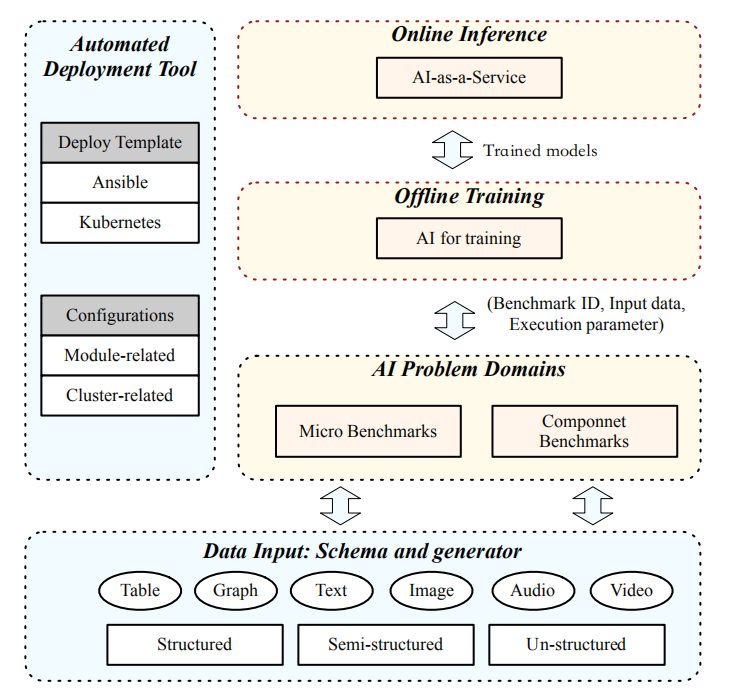
图 1:AIBench 框架
数据输入模块负责将数据输入其他模块。该模块不仅从权威的公共网站收集了具有代表性的真实数据集,而且在匿名化后从行业合作伙伴处收集了数据集。在该数据模式的基础上,进一步提供了一系列数据生成器,以支持大规模的数据生成,如用户或产品信息。该框架集成了各种开源数据存储系统,并支持大规模数据的生成和部署。
为了实现框架的多样性和代表性,作者首先确定在最重要的互联网服务领域发挥重要作用的突出 AI 问题领域。然后给出了以这些 AI 问题领域为组件基准的人工智能算法的具体实现。此外,在这些组件基准测试中分析最密集的计算单元,并将它们作为一组微基准来实现。
框架还提供了离线训练和在线推理模块,以构建端到端的应用程序基准。首先,离线训练模块从 AI 问题领域模块中选择一个或多个组件基准,通过指定所需的基准 ID、输入数据和执行参数(如批大小)。然后离线训练模块对模型进行训练,并将训练后的模型提供给在线推理模块。在线推理模块将训练好的模型加载到服务系统中,例如 TensorFlow 服务。通过与关键路径中的其他非 AI 相关模块协作,一个端到端的应用程序基准就构建完成了。
为了能够在大型集群上轻松部署,该框架还提供了部署工具,其中包含两个分别使用 Ansible 和 Kubernetes 的自动部署模板。其中,Ansible 模板支持在物理机或虚拟机上的可扩展部署,而 Kubernetes 模板则用于在容器集群上部署。
2.2 突出 AI 问题领域
为了覆盖互联网服务中广泛的主要人工智能问题领域,作者深入分析了搜索引擎、社交网络和电子商务三大主要互联网服务的核心场景,如表 2 所示。一共确定了 16 个具有代表性的人工智能问题领域:
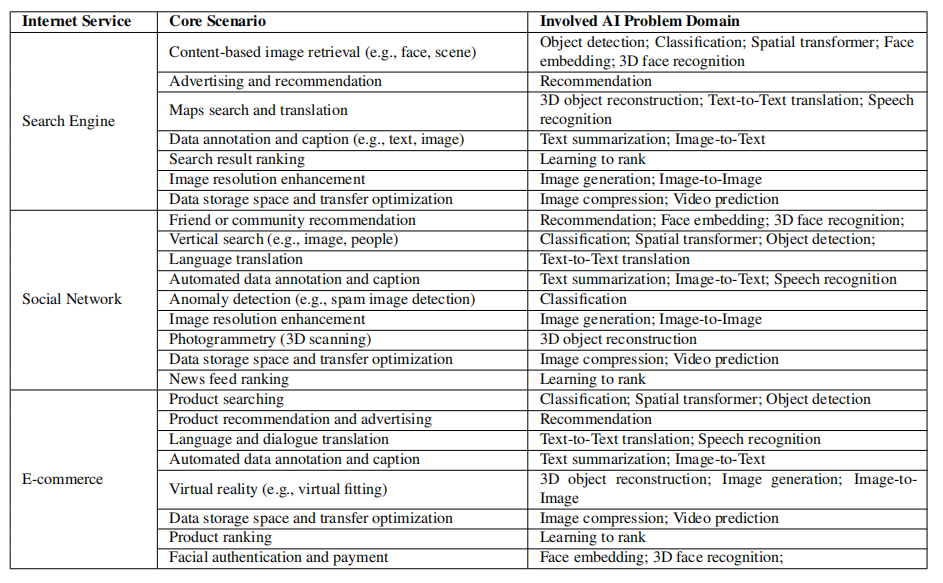
表 2:互联网服务中的突出 AI 问题领域
分类:从输入数据中提取不同的主题类,这是一个有监督的学习问题,通过定义一组目标类别并训练模型进行识别。它是互联网服务或其它应用领域的典型任务,广泛应用于类别预测、垃圾邮件检测等多种场景中。
图像生成:提供一个无监督的学习问题来模拟数据的分布并生成图像。此任务的典型场景包括图像分辨率增强,可用于生成高分辨率图像。
文本到文本翻译:将文本从一种语言翻译到另一种语言,这是计算语言学最重要的领域,可以用来智能翻译搜索和对话。
图像到文本:自动生成图像的描述。它可以用来生成图像标题和识别图像中的光学字符。
图像到图像:将图像从一个表示转换为另一个表示。它可以用来合成不同年龄的人脸图像,模拟虚拟化妆。面部老化可以帮助搜索不同年龄阶段的面部图像。
语音识别:将语音输入识别和翻译为文本。该任务主要应用于语音搜索和语音对话翻译。
人脸嵌入表示:将人脸图像在内嵌空间中转化为一个向量。该任务的典型场景是人脸相似度分析和人脸识别。
三维人脸识别:从不同角度从多幅图像中识别出三维人脸信息。主要研究三维图像,有利于实现人脸相似度和人脸认证场景。
目标检测:检测图像中的对象。典型的场景是垂直搜索,如基于内容的图像检索和视频对象检测。
推荐:提供建议。此任务广泛用于广告推荐、社区推荐或产品推荐。
视频预测:通过预测先前帧的变换来预测未来的视频帧。典型的应用场景是视频压缩和视频编码,用于高效的视频存储和传输。
图像压缩:压缩图像并减少冗余。从数据存储开销和数据传输效率的角度来看,这项任务对于互联网服务是非常重要的。
三维物体重建:预测和重建三维物体。典型的应用场景有地图搜索、光场渲染和虚拟现实。
文本总结:为文本生成摘要,对于搜索结果预览、标题生成和关键字发现非常重要。
空间变换:执行空间变换。典型应用场景是空间不变性图像检索,这样即使图像被大幅拉伸,也可以检索图像。
学习排序:学习搜索内容的属性,对搜索结果的得分进行排序,这是搜索服务的关键。
2.3 微基准和组件基准
针对上面总结的突出人工智能问题,作者给出了人工智能算法的具体实现。表 3 和表 4 列出了 AIBench 中的组件基准和微基准。总的来说,AIBench 包括 16 个用于 AI 问题的组件基准和 12 个从典型 AI 算法中提取计算单元的微基准。
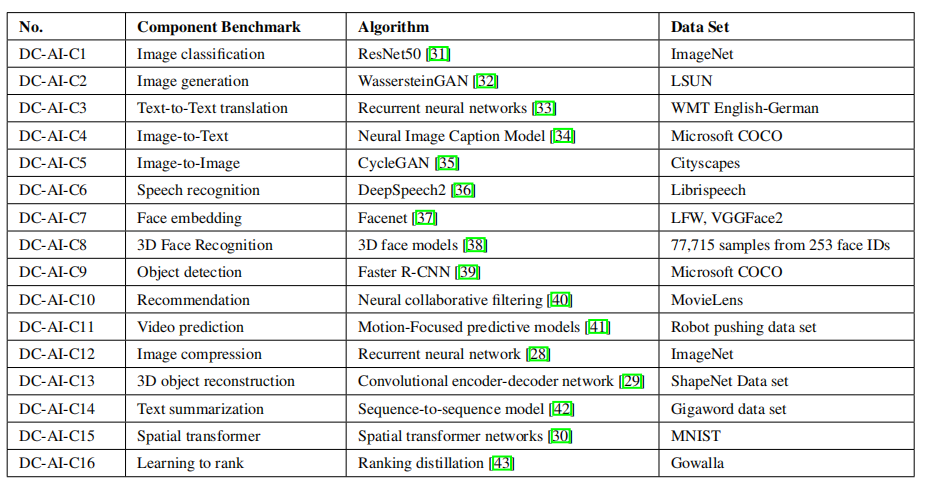
表 3:AIBench 组件基准
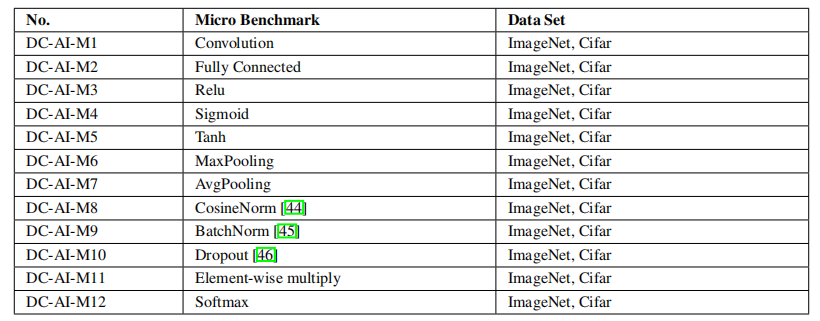
表 4:AIBench 微基准
2.4 数据模型
为了满足不同应用的数据集的多样性,作者收集了 15 个具有代表性的数据集,包括 ImageNet、CIFAR、LSUN、WMT English-German、CityScapes、Librispeech、Microsoft Coco、LFW、VGFace2、Robot Pushing、MovieLens、ShapeNet、Gigaword、MNIST、Gowalla 以及来自行业合作伙伴的 3D 人脸识别数据集。
2.5 评价指标
AIBench 专注于准确性、性能和能源消耗等行业重点关注的指标。在线推理的度量包括查询响应延迟、尾部延迟和性能方面的吞吐量、推理精度和推理能耗。离线训练的度量包括每秒处理的样本、训练特定 epoch 的时间、训练达到目标精度的时间和训练达到目标精度的能量消耗。
3 设计和实现应用基准
在 AIBench 框架的基础上,作者实现了第一个端到端的 AI 应用基准,对现实的电子商务搜索任务进行完整的用例建模。
3.1 设计和实现
端到端应用基准由四个模块组成:线上服务器、离线分析器、查询生成器和数据存储,如图 2 所示。
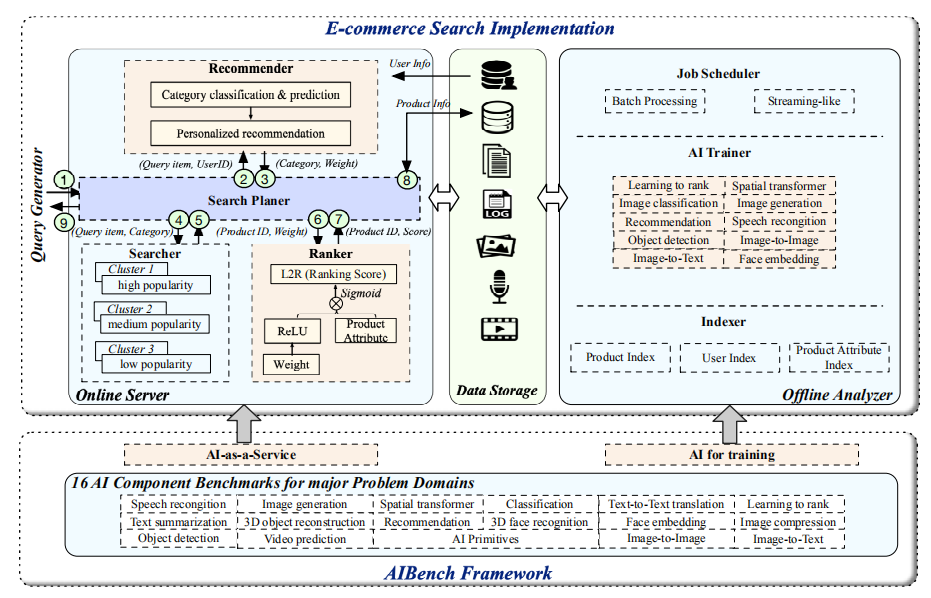
图 2:AIBench 实现
在线服务器(Online server)接收查询请求,然后结合 AI 推理进行个性化搜索和推荐。
离线分析器(Offline analyzer)选择适当的 AI 算法实现,并进行训练以生成学习模型。此外,离线分析器还负责构建数据索引以加速数据访问。
查询生成器(Query generator)模拟并发用户,并根据特定的配置将查询请求发送到线上服务器。作者实现了基于 JMeter 的查询生成器。
数据存储模块(Data storage module)存储各种数据,包括结构化、非结构化和半结构化数据,以及各种数据源,包括表格、文本、图像、音频和视频。
3.1.1 在线服务器
在线服务器结合传统的机器学习和深度学习技术提供个性化的搜索和推荐。在线服务器由四个子模块组成,包括搜索计划器、推荐器、搜索器和排序器。
搜索计划器(Search Planer)是在线服务器的入口。它负责接收来自查询生成器的查询请求,并将请求发送到其他在线组件并接收返回结果。作者使用 Spring Boot 框架来实现搜索计划器。
推荐器(Recommender)根据从用户数据库中获取的用户信息,对查询项进行分析,并提供个性化推荐。作者使用 Flask Web 框架和 Nginx 构建类别预测推荐器,并采用 TensorFlow 实现在线推荐。
搜索器(Searcher)部署在三个不同的集群上。按点击率和购买率,产品可以按人气高低分为三类。不同流行度产品的索引存储在不同的集群中。对于每个类别,搜索器都采用不同的部署策略。高人气的集群包含更多的节点和备份,保证了搜索效率。而受欢迎程度较低的集群部署的节点和备份数量最少。作者使用 Elasticsearch 来建立和管理三个搜索集群。
排序器(Ranker)使用推荐器返回的权重作为初始权重,通过一个个性化的 L2R 神经网络对产品得分进行排序。排序器也使用 Elasticsearch 实现产品排序。
在线服务流程如下:
(1)查询生成器模拟并发用户,向搜索计划器发送查询请求;
(2)搜索计划器接收查询请求并将查询项发送给推荐者;
(3)推荐器对查询进行分析,并将类别预测结果和个性化属性权重返回给搜索计划器;
(4)搜索计划器向搜索器发送初始查询项和预测的分类结果;
(5)搜索器搜索反向索引并将产品 ID 返回给搜索计划器;
(6)搜索计划器向排序器发送产品 id 和个性化属性权重;
(7)排序器根据初始权重对产品进行排序,并将排序得分返回给搜索计划器;
(8)搜索计划器根据产品标识发送产品数据库访问请求,获取产品信息;
(9)搜索计划器将搜索到的产品信息返回给查询生成器。
3.1.2 离线分析器
离线分析器负责训练模型和建立索引,以提高在线服务性能。它由人工智能训练器、作业调度程序和索引器三部分组成。
人工智能训练器(AI trainer)利用数据库中存储的相关数据训练模型。
作业调度程序(Job scheduler)提供了两种训练机制:批处理和流式处理。在现实场景中,一些模型需要经常更新。例如,当我们搜索一个项目并点击第一页中显示的一个产品时,应用程序将立即基于我们刚刚单击的产品训练新模型,并在第二页中显示新的推荐。该基准实现考虑了这种情况,并采用流式方法每隔几秒钟更新一次模型。对于批处理,训练器将每隔几个小时更新一次模型。
索引器(Indexer)用于为产品信息构建索引。
3.2 其他行业应用程序的可扩展性
以医学人工智能场景为例,作者介绍了如何利用 AIBench 框架构建临床诊断应用的端到端基准。人工智能相关的临床诊断关键路径包括以下步骤。1)根据病史数据离线训练一系列诊断模型,如检测模型、分类模型、推荐模型等;2)检测患者体检数据中的异常信息,如 CT 图像的肿瘤检测;3)分类预测潜在疾病;4)推荐最佳治疗方案。
为了构建端到端的临床诊断应用基准,AIBench 框架灵活地提供了与 AI 相关的离线模块和在线模块。在离线模块中,选择目标检测、分类和推荐的组件基准作为训练模型。在在线模块中,将这些模型作为服务进行加载以在线推理。
4 实验设置
4.1 节点配置
作者部署了一个 16 节点的 CPU 和 GPU 集群。对于 CPU 集群,所有节点都连接到一个 1GB 的以太网网络。每个节点配备两个 Xeon E5645 处理器和 32 GB 内存。每个处理器包含六个内核。每个节点的操作系统版本均为 Linux CentOS 6.9,Linux 内核版本为 3.11.10。软件版本分别是 JDK1.8.0、Python3.6.8 和 GCC 5.4。GPU 节点配备了四个 Nvidia Titan XP。每个 Titan XP 拥有 3840 个 Nvidia Cuda 内核和 12GB 内存。表 5 列出了每个节点的详细硬件配置。
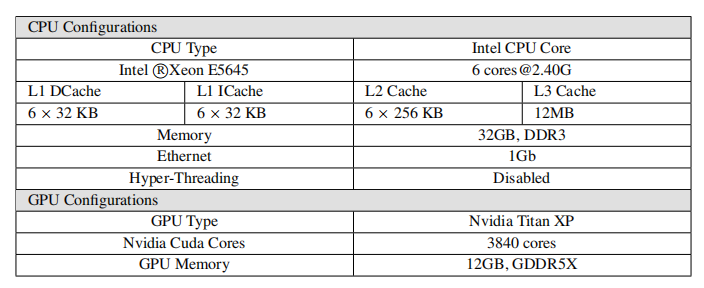
表 5:硬件设置细节
4.2 基准部署
在线服务器设置:在线服务器部署在 16 节点 CPU 集群上,包含 1 个查询生成器节点、1 个搜索计划器节点、2 个推荐器节点、9 个搜索器节点、1 个排序器节点和 2 个数据存储节点。表 6 列出了详细的模块设置信息和涉及的软件信息。
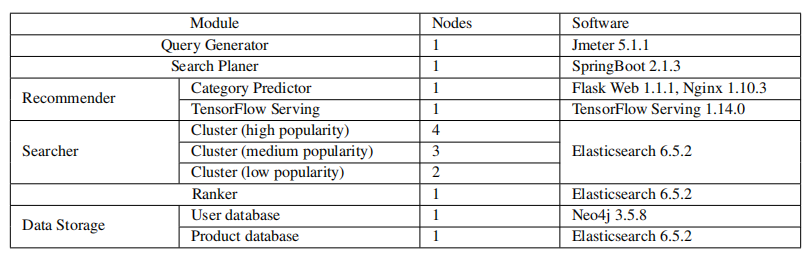
表 6:在线服务器设置
离线训练器设置:离线训练器部署在 GPU 上。CUDA 和 Nvidia 驱动程序版本分别为 10.0 和 410.78,使用 1.1.0 版本 PyTorch 实现。
4.3 性能数据收集
作者使用 Network Time Protocol 在所有集群节点上实现时钟同步,并获得在线服务器的延迟和尾延迟度量。使用分析工具 Perf,通过硬件性能监视计数器(PMC)收集 CPU 微体系结构数据。对于 GPU 评测,作者使用 Nvidia 评测工具包 nvprof 来跟踪 GPU 的运行性能。
5 评估
作者对端到端人工智能应用程序基准,包括在线服务器和离线分析器中包含的 10 个人工智能组件基准进行了测评。
5.1 在线服务器评估
作者评估了 16 节点 CPU 集群上的在线服务器性能。产品数据库包含 10 万个具有 32 个属性字段的产品。查询生成器用 30 秒的预热时间模拟 1000 个用户。用户在每个思考时间间隔内连续发送查询请求,遵循泊松分布。当 20000 个查询请求完成时,收集性能数据。
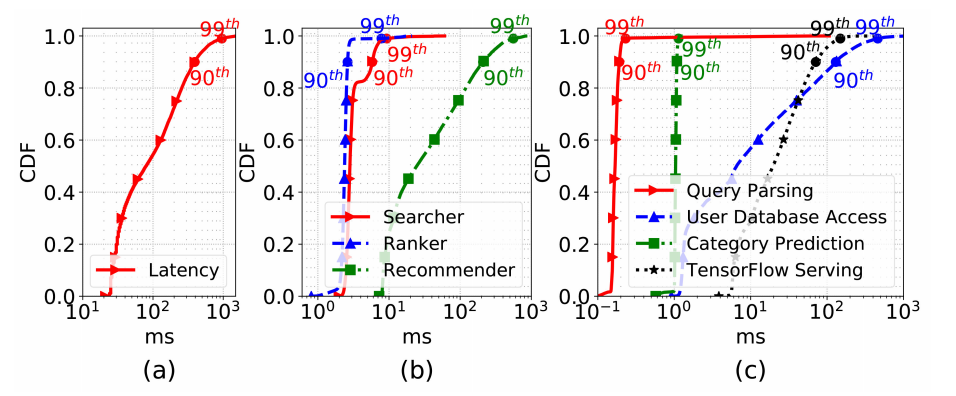
图 3:在线服务器延迟
延迟是衡量服务质量的重要指标。图 3 给出了在线服务器的延迟。如图 3(a)所示,当前基准实现的整个执行路径的总延迟的平均值、第 90 百分位和 99 百分位对应分别为 161.13 毫秒、392 毫秒和 956 毫秒。作者进一步深入分析了每个模块的延迟(图 3b),推荐器占据了最大的延迟:平均延迟 75.7 毫秒, 90 百分位延迟 209.4 毫秒,99 百分位延迟 557.7 毫秒。相比之下,搜索器和推荐求的延迟都在 4 毫秒之内。
此外,图 3(c)给出了推荐器在查询解析、用户数据库访问、类别预测和 TensorFlow 服务方面的延迟分解。作者发现数据库访问和 TensorFlow 服务延迟是影响服务性能的前两个因素。复杂的数据结构和频繁的垃圾收集对数据访问速度有很大的影响。而 TensorFlow 服务则需要使用推荐模型进行前向推理,从而产生较大的延迟。为了衡量 AI 组件对服务性能的影响,找出瓶颈,作者从以下几个方面进行了讨论。
人工智能相关组件对服务性能的权重。人工智能组件显著改变了关键路径。在评估中,在 AI 相关和非 AI 相关组件上花费的时间平均为 34.29 和 49.07 毫秒,第 90 百分位延迟为 74.8 和 135.7 毫秒,第 99 百分位延迟为 152.2 和 466.5 毫秒。这表明,一个工业规模的人工智能应用基准套装是现代互联网服务必不可少的。
AI 的局限性。在线推理模块需要对训练后的模型进行加载,并进行前向计算得到结果。然而,神经网络模型的深度或大小可能在很大程度上影响推理时间。当模型的大小从 184mb 增加到 253mb,TensorFlow 服务的延迟急剧增加,平均延迟从 30.78 毫秒增加到 125.71 毫秒,第 99 百分位延迟从 149.12 毫秒增加到 5335.12 毫秒。因此,互联网服务架构师必须在服务质量和神经网络模型的深度或大小之间进行权衡。
微结构行为的差异:
非 AI 相关组件与 AI 相关组件之间的差异。作者使用 perf 对 AI 相关和非 AI 相关组件的缓存行为进行了采样。作者发现,与非 AI 相关的组件相比,AI 相关的组件会遭受更多的缓存缺失(cache miss)。TensorFlow 服务每千条指令有 61 个 L2 缓存缺失,而非 AI 相关组件的平均数量仅为 37。
从小型神经网络模型到大型神经网络模型的变化。作者比较了两种神经网络模型,一种是较小的 184mb,另一种是较大的 253mb。对于更大的模型,每千条指令的 L3 缓存缺失率会急剧增加,从 1.38 增加到 8.9,这会导致大量内存后端暂停以从内存中获取数据。因此,第 99 百分位的延迟增加了 30 倍以上。
5.2 离线训练评估
在本小节中,主要分析了 GPU 的执行效率,并评估了 Titan XP 上端到端 AI 应用程序基准的离线分析器中使用的十个组件基准。
作者通过函数级运行时间分解和执行暂停分析全面分析了 GPU 的运行效率。图 4 显示了每个组件基准的 SM 效率,从 29%(学习排序)到 95%(推荐)不等。
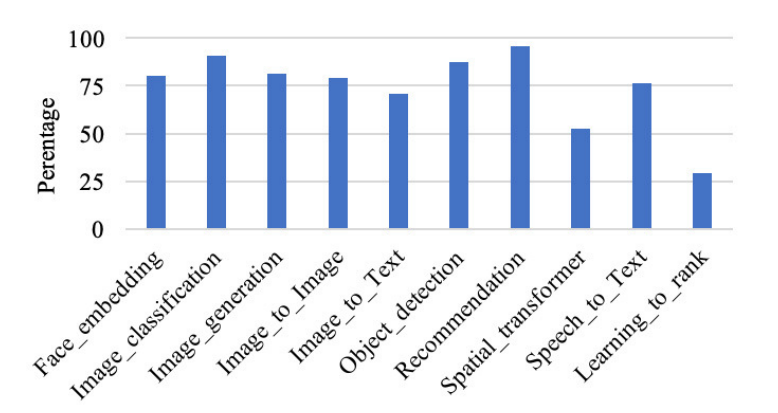
图 4:SM 效率
为了研究影响性能的因素,作者首先进行运行时间分解分析,将基准分解为热点内核或函数,然后根据不同的暂停百分比来计算 GPU 的执行效率。
5.2.1 运行时间分解
作者利用 nvprof 对运行时间进行跟踪,找出占运行时间 80%以上的热点函数。作者将占用大量运行时间的函数挑选出来,并根据它们的计算逻辑将它们分为几类内核。通过统计,将十个组件基准中最耗时的函数分为六类内核:卷积、通用矩阵乘法(gemm)、批规一化、relu 激活函数、元素操作和梯度计算。每个内核都包含一组解决类似问题的函数。例如,gemm 内核包括单精度或双精度浮点通用矩阵乘法等。图 5 显示了上述六个内核的运行时间分解,即每个内核中所有相关函数的平均值。
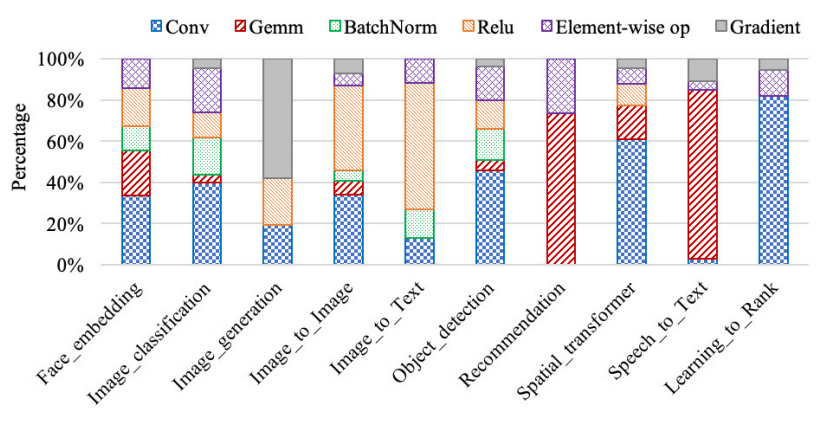
图 5:10 个组件基准的运行时间分解
此外,对于每个内核,作者总结了在十个组件基准中占用大量运行时间的典型函数,如表 7 所示。
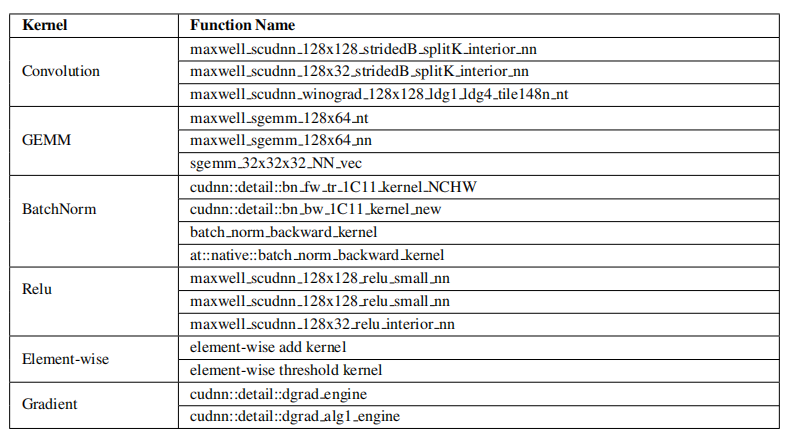
表 7:每个内核的热点函数
从图 5 中我们发现,学习排序花费了太多时间进行卷积,相应的函数调用是 maxwell_scudnn_128x32_stridedB_splitK_interior_nn,SM 效率为 18.5%,这就是学习排序基准的 SM 效率最低的原因。作者认为,这六个内核及其相应的函数不仅是 CUDA 库优化的优化方向,也是微结构优化的优化方向。
5.2.2 GPU 执行效率分析
针对以上六个最耗时的内核,作者评估了这些内核的八种暂停,包括指令获取暂停(Inst_fetch)、执行依赖暂停(Exe_depend)、内存依赖暂停(Mem_dependent)、纹理暂停(Texture)、同步暂停(Sync)、常量内存依赖暂停(Const_mem_depend)、管线忙暂停(Pipi_busy)、内存限制暂停(Mem_throttle)。
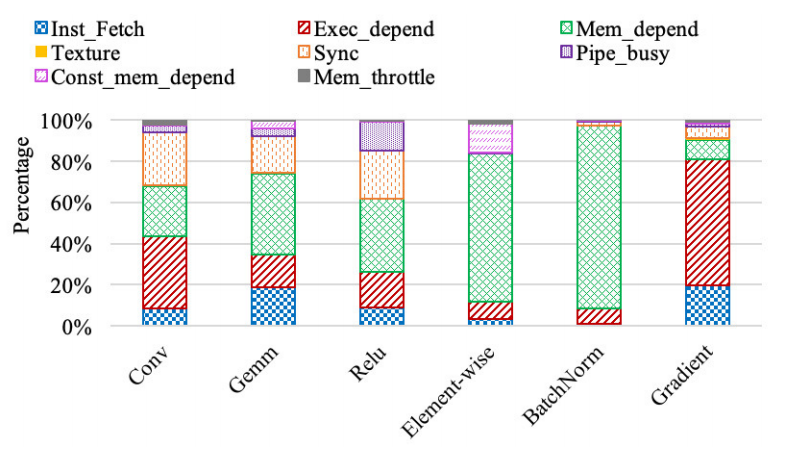
图 6:每个内核的暂停分解
图 6 显示了每个内核的八种暂停的分解。作者发现前两个 GPU 执行暂停是内存依赖暂停和执行依赖暂停。内存依赖关系暂停可能是由于高速缓存缺失,因此加载/存储资源不可用。优化策略包括优化数据对齐、数据局部性和数据访问模式。由于指令级并行度较低,可能会出现执行依赖暂停,因此利用 ILP 可以在一定程度上缓解部分执行依赖暂停。
作者还确定了表 7 中函数级的暂停,以便为函数调用提供潜在的优化指导。例如,“卷积”类中 maxwell_scudnn_128x32_stridedB_splitK_interior_nn 函数的内存依赖暂停百分比达到 61%,而“GEMM”类中 maxwell_sgemm_128x64_nn 函数的内存依赖暂停百分比为 18%,说明需要不同的优化策略才能实现最大的性能改进。
结论
这篇论文介绍了 17 家中国企业联合推出的第一个行业标准互联网服务人工智能基准套装。作者提出并实现了一个高度可扩展、可配置和灵活的人工智能基准框架,并从三个最重要的互联网服务领域:搜索引擎、社交网络和电子商务中提取出 16 个突出的人工智能问题领域。在 AIBench 框架的基础上,设计并实现了第一个端到端的互联网服务 AI 基准套装,并给出了一个底层的电子商务搜索模型。在 CPU 和 GPU 集群上,作者对端到端应用程序基准进行了初步评估。与 AI 相关的组件显著地改变了互联网服务的关键路径和工作负载特性,证明了端到端 AI 应用程序基准的正确性和必要性。
论文原文:
AIBench: An Industry Standard Internet Service AI Benchmarks Suite

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论