

本文根据京东微信手Q业务部马老师在京东&DataFun Talk算法架构系列活动中所分享的《京东购物在微信等场景下的算法应用实践》编辑整理而成,在未改变原意的基础上稍做修改。
此次分享的是以 WQ(微信手 Q)购物智能推荐系统介绍智能推荐算法在实际中的应用,介绍的 WQ 购物从海量服务到简单的个性服务到现在的个性化服务发展历程。他从以下四个部分进行了介绍。
首先讲解了 WQ 个性化推荐有哪些产品、有哪些业务;第二部分讲如何构建 WQ 推荐平台,如何支持这些业务需求;第三部分简单介绍了用户画像(用户画像、物料画像);最后讲解 WQ 大数据平台如何搭建。通过这次讲解让大家对推荐系统搭建流程有个初步了解,使大家能够在 3-5 天时间里通过这种开源框架搭建一个自己的小型推荐系统。
1. WQ 个性化推荐
WQ 个性化推荐在微信购物界面体现的方方面面,主要有关键词推荐(新用户主要通过上下文信息推荐,准确度不是很高)、素材推荐(入口图、焦点图、品牌特卖)、商品(卖场、秒杀、拼购等)资讯(趣好货、购物圈)以及其他如猜你喜欢、类目入口(由于手机屏幕大小原因,条目不能全部显示,智能通过用户兴趣选择用户感兴趣的条目)栏目馆区等,具体见下图。
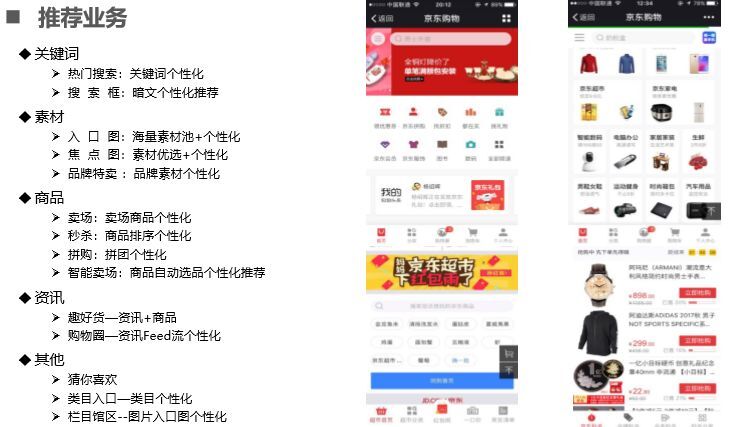
WQ 这些海量个性化推荐业务主要由 ABC(AI 人工智能、BigData 大数据、Cloud 云服务)技术支持,主要解决用户体验问题,运营效率问题、业务效果问题。如金手指(热搜词+规则+推荐)的下单转化率提升为 200%-400%,随着时间略有波动,热搜词采用插件式接入(加载 js 插件,依据你页面上下文,类目进行热搜词推荐),简单易用;智能卖场由原先运营人员和商家谈判、选品、上线,周期为两人一周构建卖场,通过 ABC 基于算法、基于不同规则生成不同智能卖场只需一个人员 10 分钟就能完成,而且程序自动维护,解决效率问题;入口图(素材)这一方面主要解决用户体验问题,使用户达到所见即所想,打造触动内心的极致体验。
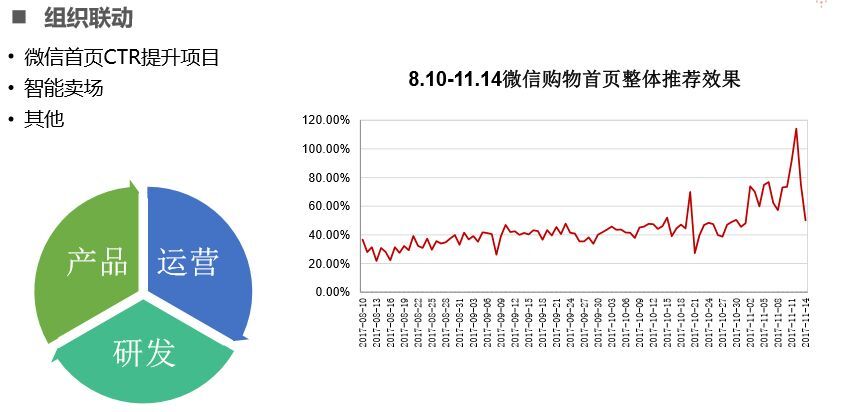
除了 ABC 技术提高推荐转化率,团队发现组织联动在推荐效果也有明显提升,上图是去年 8 月到 11 月的推荐效果提升,如果单纯的靠算法优化,效果只能提升 30%达到 50-60%就是算法极限,但是如果和产品联动效果由 30%提升到 90%,因此建议在做算法优化是加入产品运营联动。如在穿搭推荐中先前无论如何算法优化,转化率一直很低,最后发现是产品素材质量太差,无法引起用户兴趣。另一方面在智能卖场做数据挖掘、爬虫抓取关联商品,再进行聚类确实能够发现人的行为,但是运营能抓住用户价值点,如果在物料上加入这些价值点,能够明显提升推荐效果。
2. WQ 推荐平台
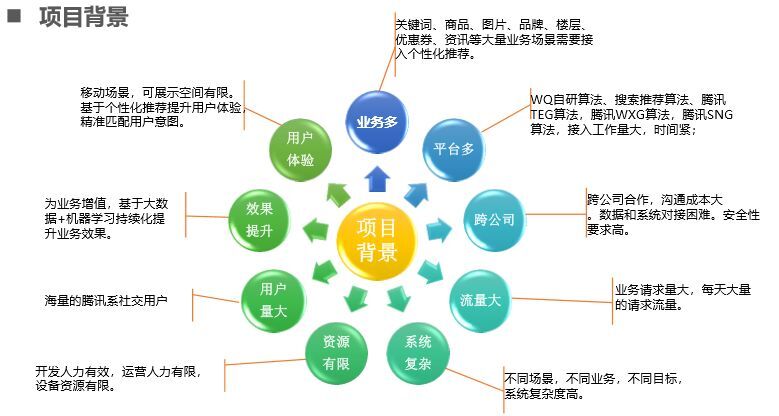
WQ 推荐系统需要知道解决那些问题:
(1)首先业务需求多,原先想的是一个一个业务对接,但是关键词开发需要人员,资讯开发也需要人员,但是开发人员资源有限,开发压力大,无法应对也无需求;
(2)平台多,接入工作流量大,每个都去对接工作量大;
(3)跨公司问题,数据不是完全共享,安全性能要求高,只能系统对接,因此流量红点压力大;
(4)用户体验问题,只能向前不能倒退
(5)效果问题,增长放缓,只能从技术、算法方面来提升;
(6)用户量大,资源有限等。
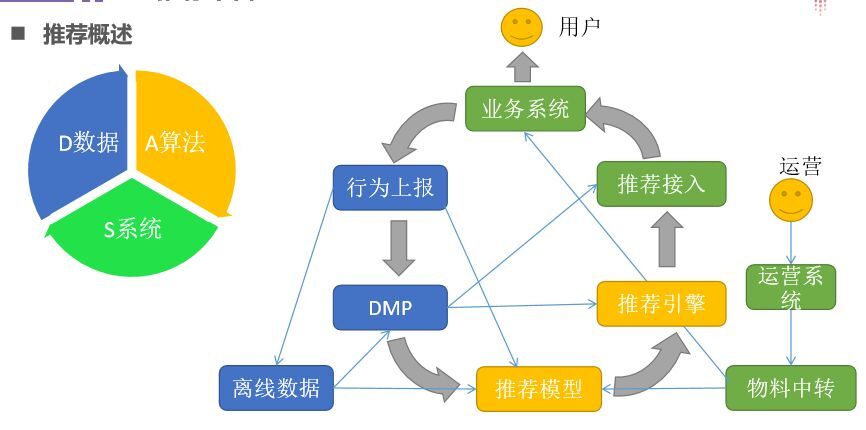
推荐系统核心是“数据”、“算法”、“系统”,有这三种推荐系统就能运行。具体工作是:首先用户会请求我们的业务系统,之后请求推荐引擎,推荐接入实现业务分流到对应的推荐平台,然后通过推荐算法、模型返回用户所需数据。除此之外还有一个数据的反向上报(行为上报),因为我们的推荐都是基于大数据,如果我们能收集用户的行为越多,对用户的行为就越准,推荐也就越精确。对用户的(点击,搜索,浏览)做 DMP(大数据管理平台),让模型训练算法,其响应时间一般是限度控制在 300-500 毫秒。
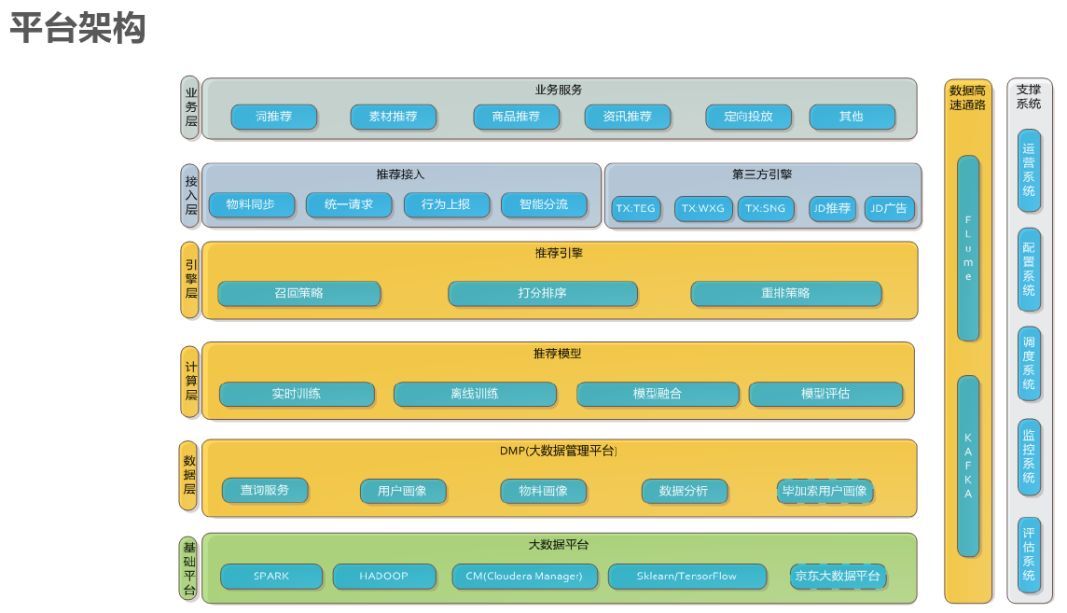
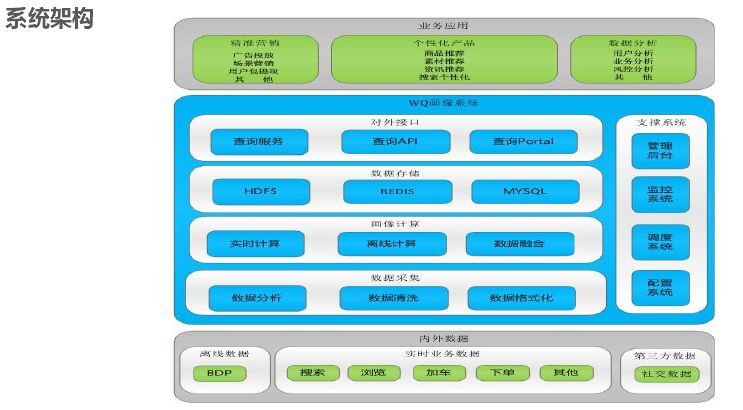
WQ 推荐系统平台架构如下所示,依据架构依据相关开源软件能够 3-5 天搭建一个推荐系统。首先业务层,主要是有哪些业务;其次是接入层,我们有第三方接入引擎,还要做分流,都要做 A/B text;接入后要做推荐引擎,我们分为三层:为召回策略(添加条件,选择最相关)、打分排序、重排策略;引擎打分需要模型,这一块为计算层。再然后是数据层,这块主要是用户画像和物料画像以及数据分析等;最底层是基础平台,来支持我们做推荐,算法训练,我们的实时用的是 Spark,离线用的是 Hadoop,用 CM 做集成,用 Sklearn/TensorFlow 做离线分析,对于大账号推送用全站数据(京东大数据平台)比 WQ 效果要好。除此之外比较重要的一个是数据上报,最开始用的是自己研发的用 C/C++实现,后来需要与业界对标,采用 Flume 和 Kafka。集群时间是分钟级,但是用户画像是毫秒级,用户画像是基于用户行为而不是数据库。
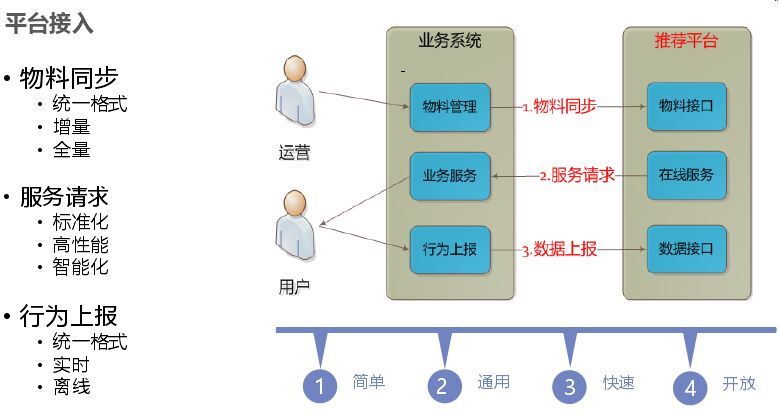
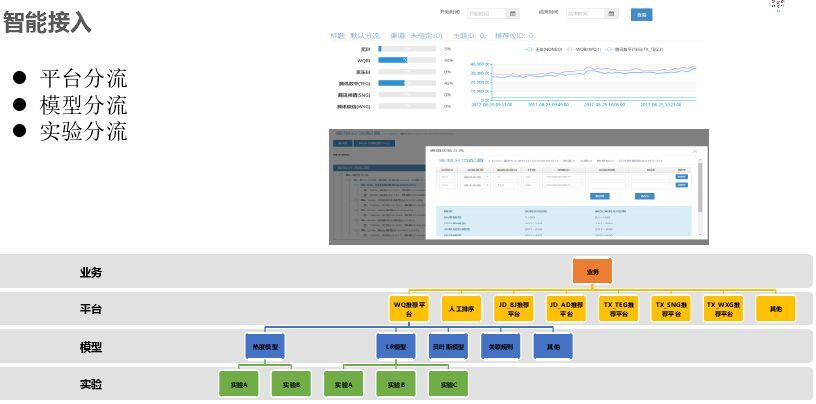
在平台接入时,需要简单、通用、快速、开放为目标。将业务抽象为物料,统一格式,业务只需要实现物料上报、请求服务、行为上报三步。对于算法选择前期配置就能快速上线,选择快速上线算法是热度和 IOR 算法。智能接入:由于平台多,通过物料、用户、平台判断哪个平台转化效率高,就将平台流量多分给推荐平台,达到整体最优,对于模型选择各自去训练,然后选择、融合。
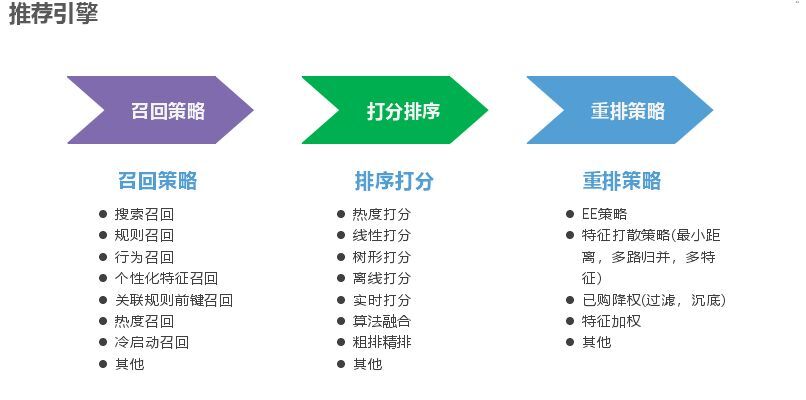
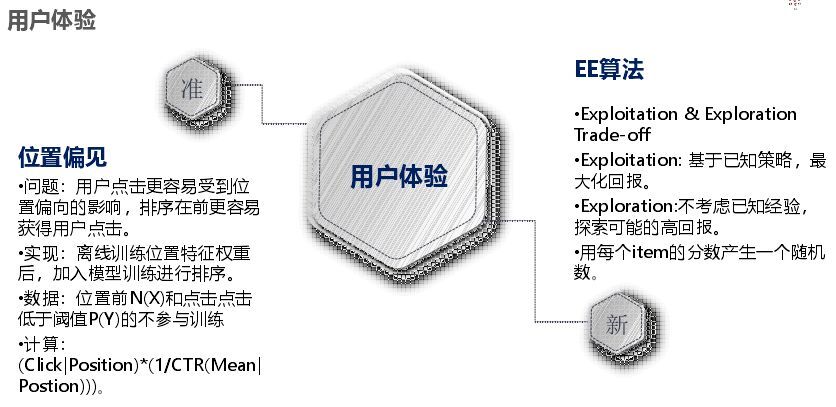
接入之后就是推荐引擎,常见的有召回策略、打分策略、重排策略。召回策略如下所示,所谓个性化召回就是画像打上的那些标签,是偏向某个类目还是某个品牌偏好等做召回,关联规则前键召回是根据用户前面的行为来关联后续感兴趣的商品;打分就是和模型结合;重排也有很多算法,例如特征加权就是用户有什么偏好给他提前。重排主要是基于个人,模型是基于群体特征,重排命中也能很好提升效率,EE 策略主要改善体验问题,我们发现如果一个人行为很少,进来之后什么都不点,如果模型在 5-10 分钟未更新,推荐的就是一直是这个,如果特别偏门,群体又比较小,模型就没有影响,个人就需要推荐一些新的东西,EE 策略就是以一定概率来显示推荐而不是单纯以排名推荐,我们用的是汤姆森算法。
接下来讲一下模型,我们的推荐模型就是解决 GMV(成交)最大化、CTR * CVR 最大化、CTR 最大化(首页、中间页引流,最容易,点击转化率)核心是“他点的”/“他看的”。这个模型还有一个瞬息系约束,一方面就是 EE 策略,另一个就是某一类商品在一定时间不能超过多少,保证用户体验。在评价推荐效果方面,如果直接做到下单,其中很多因素不可控,这时考虑 CTR * CVR 模型,提升转化率,主要考虑物料、用户以及上下文场景。
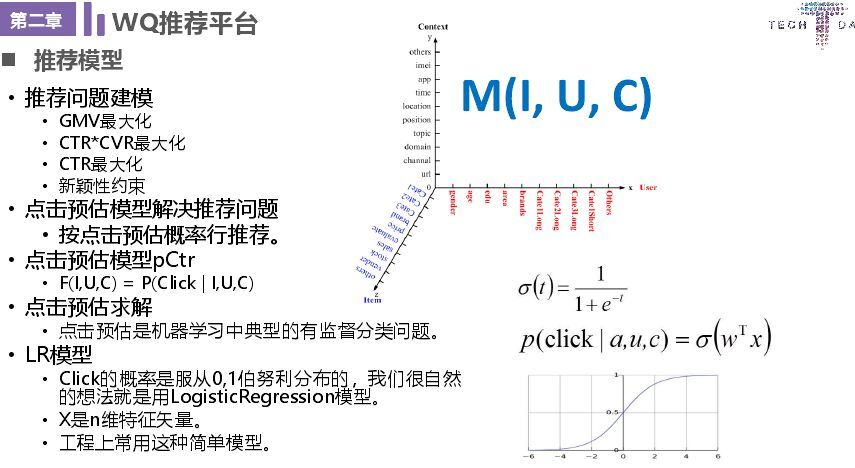
接下来就是机器学习过程,主要有环境搭建、收集数据、分析数据、准备数据、训练算法、测试算法、应用算法。这个过程很简单,但是我们要解决冷启动问题、假曝光问题(这个主要是产品预加载,在用户还未看数据就显示,这种就是假曝光)异常数据清洗问题(爬虫、刷单)、正负样本问题、数据稀疏问题等问题。在推荐过程中数据是基础中的基础,下面是数据处理中常用的方法。

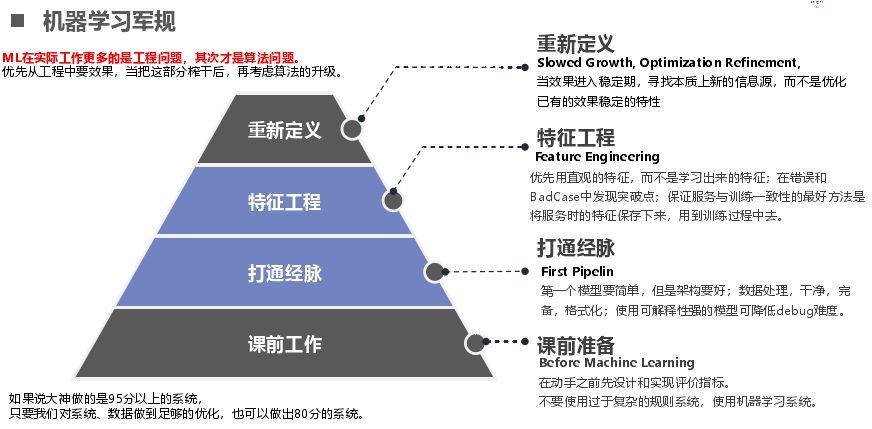
在算法里面对我们比较受益的是机器学习军规,做 C++或前端时有雅虎军规、effective C++这些都有很规则性的东西告诉你怎么做。在机器学中有一个机器学习军规,其实在 ML 中首要的是工程问题,其次才是算法问题。我们把数据做好了效果也就好了,如果大神能做 95 分,我们做好了这些也有 80 分。
而用户体验方面,一个是要准,另一个是要新。新就是 EE 算法,准就是位置偏见,例如冷启动时你把某一个商品放在前面,那么他的转化率一直高;这种就不能他分值高就一直在前面,这种情况就要看不同商品在此位置时的转化率,这个就是位置偏见。
3. WQ 用户画像
接下来简单介绍下用户画像,做推荐时你首先要知道用户是谁,如果你只用 cookie Mapping 的话效果太差,这个我们是和微信合作,我们是拿到 open ID 的,如果有微信场景可以参考这种方式;其次用户是什么用户,这就是用户画像;再者用户还是那个用户么(可能前一秒和下一秒不是同一个用户)因此要注意更新。画像主要解决身份问题,还有就是 WQ 数据和自己收集数据以及全站数据,这些数据整个融合而做的一个用户画像。
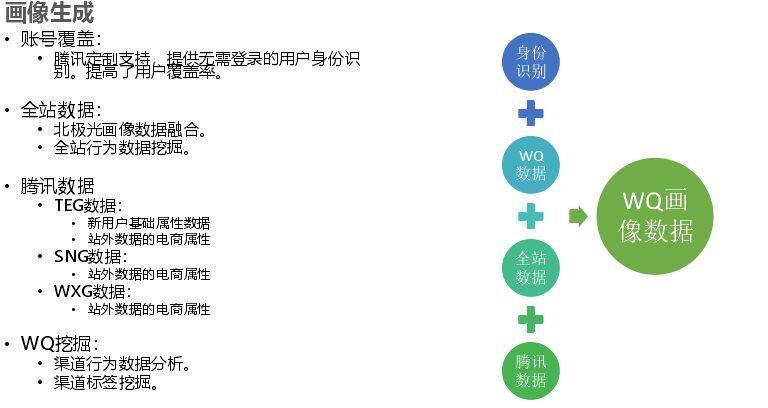
用户画像的系统架构首先是一个内外部数据的融合,然后是做采集(分析、清洗、格式化然后做一些画像计算)这里用到很多算法,如统计算法等。

4. WQ 大数据平台
大数据平台主要解决实时问题、系统复杂问题、业务支持(支持 ML 算法等)下面是系统需要的达到的目标。
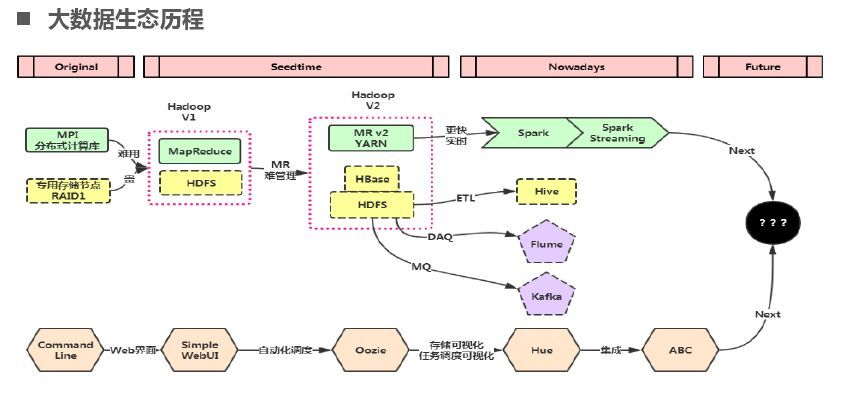
接下来讲一下大数据生态,最开始时是并行计算(最原始的那种命令行并行计算)然后就是 Hadoop(MapReduce 和 HDFS 开始也是简单 UI)在 Hadoop V2 就有了 HBase 之后就是更快的 Spark(Hive、Flume、Kafka),下面是整个大数据生态。
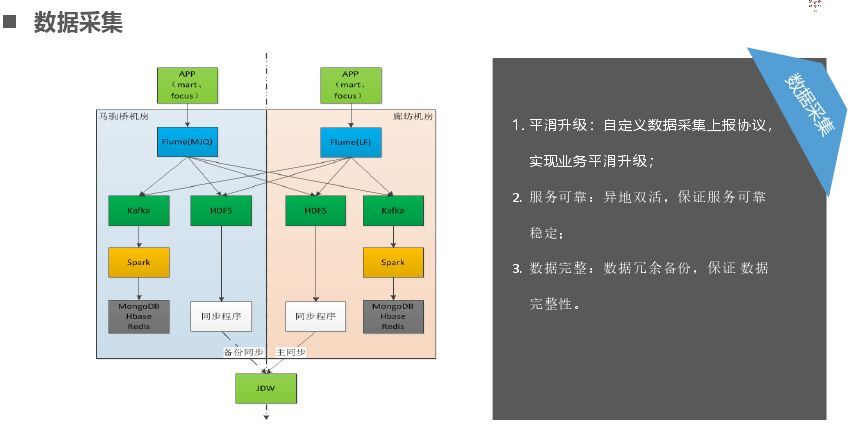
最后讲一下大数据采集,对于我们做账务,事务型的数据不能丢,可以慢不能丢,所以可以异地多活(主要是做一个异地防或多级防的备份),这个需要看具体业务需求。
本文来自京东微信手 Q 业务部马老师在 DataFun 社区的演讲,由 DataFun 编辑整理。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论 1 条评论