

AI 前线导读:
中兴回应列入被执行人名单:正常纠纷,并非失信被执行
贵州一学校推出智能校服,全方位监控学生
Facebook 开源无梯度优化工具 Nevergrad
第四范式完成超 10 亿元 C 轮融资,估值 12 亿美元
腾讯论文揭秘训练 AI 玩《王者荣耀》新成果,胜率 48%
华为公布智能计算战略布局,发布 ARM 新芯片
小冰的“秘密”,微软公司公开高人气中文聊天机器人背后技术
美国政府通过法律,要求广泛实现数据开放性与机器可读性
Facebook 发布超高速语音识别系统 wav2letter++
哪些 AI 突破不是真正的突破?ICLR 论文评审就此做出讨论
欧盟发布首份人工智能道德准则草案
Jack 谏言:认真看待 AI 风险
中兴回应列入被执行人名单:正常纠纷,并非失信被执行

据中国执行信息公开网披露,中兴通讯股份有限公司于 12 月 17 日被深圳市中级人民法院列入被执行人名单,执行标的为 3187.13 万元。
中兴通讯随后回应表示,该事件系中兴通讯与中建五局的正常商业纠纷,并非失信被执行。
自 2008 年起至今,中兴通讯与中建五局发生多起系列纠纷案件,此次被申请执行的案件是其中一起中建五局诉中兴通讯的案件,院于 2017 年 12 月 11 日做出再审终审判决,判决要求公司支付未付的工程款 1449 余万元人民币、对方的误工损失 286 余万元人民币及利息等,同时判决中建五局返还中兴通讯保函 2015 万元人民币及利息。针对此案件的执行申请,中兴已于 2018 年 12 月 24 日向深圳市中级人民法院提起执行异议,目前双方仍在友好协商解决纠纷。
实际上,这已经不是中兴通讯第一次被列入失信被执行人名单。今年 6 月,中兴通讯就被深圳市中级人民法院列入其中,执行标的仅 14.12 万元。
贵州一学校推出智能校服,全方位监控学生

据《环球时报》报道,贵州省仁怀市第十一中学为学生配备了一套智能校服,能精准、及时记录学生的出勤和活动,将学生进出校门的准确时间自动发送给学校老师和家长,
如果未经许可出校门、互换校服,会激活自动语音报警器,结合人脸、校服和摄像头,确保学生身份。
根据校服项目方经理袁必昌介绍,在校服肩部,分别加入了两颗智能芯片,智能校服升级后,智慧校园体系还可实现智能教学、智能学校、智慧生活等功能,例如“侦测”学生打瞌睡自动响起警报,建立“无现金校园”等。
Facebook 开源无梯度优化工具 Nevergrad
Facebook 宣布,开源自家一直在使用的无梯度优化工具:Nevergrad。Facebook 研究团队已经在强化学习、图像生成以及各种各样的项目中使用 Nevergrad 了。而且,Nevergrad 的无梯度优化,还能广泛运用于各种机器学习问题,如多模态问题、病态问题、可分离或旋转问题、部分可分离问题、离散、连续或混合的问题、有噪声的问题。
Nevergrad 项目地址:
https://github.com/facebookresearch/nevergrad
博客地址:
https://code.fb.com/ai-research/nevergrad/
噪声最优化示例项目地址:
https://github.com/facebookresearch/nevergrad/blob/master/docs/benchmarks.md
第四范式完成超 10 亿元 C 轮融资,估值 12 亿美元

12 月 19 日,第四范式宣布 C 轮融资,融资额 10 亿元人民币,估值约 12 亿美元。本轮新引入了国新、启迪、保利、三峡、中信、农业银行、交通银行等战略股东,红杉中国继续追加投资。至此,加上老股东中国工商银行、中国银行,中国建设银行,第四范式集齐中国五大行,成为唯一一家五大行投资的创业公司。
腾讯论文揭秘训练 AI 玩《王者荣耀》新成果,胜率 48%
腾讯 AI Lab 团队在 arXiv 发表论文,通过对 AI 进行训练,并与《王者荣耀》顶级人类玩家 PK,最后实现了 48%的胜率。
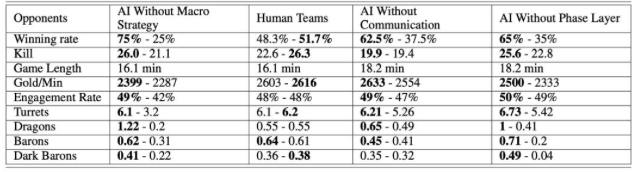
论文地址:https://arxiv.org/pdf/1812.07887.pdf
腾讯 AI Lab 团队提出了一种新的基于学习的分层宏观策略模型,用于掌握 RTS 子类型游戏——MOBA 游戏。
在层次宏观战略模型的训练下,智能体能够明确地做出宏观战略决策,并进一步指导其微观层面的操作。
此外,每个智能体都可以在做出独立的战略决策的同时,通过一种新颖的模仿交叉通信机制与盟友沟通。
华为公布智能计算战略布局,发布 ARM 新芯片

华为智能计算业务部总裁邱隆展示基于 ARM 架构的处理器芯片
12 月 21 日,在华为智能计算大会上,华为智能计算业务部总裁邱隆发布智能计算战略布局,同时首次发布基于 ARM 架构的处理器芯片,并自主设计了基于 ARM v8 架构的 TaiShan 核。同时,华为还宣布将在 2019 年推出全球首个 AI 管理芯片,内建 AI 管理引擎和智能管理算法,能从服务器全局进行针对故障的预警等管理。这是华为于 10 月提出的“云管端更层面发力 AI”的进一步发展。
关于 ARM 的细节:
7nm 数据中心 ARM 处理器芯片;
ARM v8 架构,自主设计 TaiShan 核;
48/64 核,2.6/3.0 GHz;
8 通道 DDR4-2993;
40*PCle 4.0 与 CCIX;
2*100GE 网络,RoCEv2/RoCEv1。
智能计算战略布局:通过更高效的管理、更快的数据读写、更快的网络 I/O、更高的能效,来从容面对蒜粒供应、数据血统、场景部署和专业技术四大挑战。此次大会中,邱隆还提出,云边端全场景覆盖,边缘计算升级成边缘云。云边协同、统一架构、数据互通、超高宽带、超低延时。
小冰的“秘密”,微软公司公开高人气中文聊天机器人背后技术

…只有混合 AI,才是真实的 AI…
微软于 2014 年在中国推出的中文版本聊天机器人在西方虽然声名不显,但目前却已经成为全球最受欢迎的方案之一。自推出以来,这款名为“小冰”的机器人已经与超过 6.6 亿用户进行过交流。
小冰是什么? 微软研究人员在一篇新近发表的论文中指出,小冰是一款“用户能够与之形成长期情感联系的人工智能伴侣。小冰的目标是通过分时测试这一特殊形式的图灵测试,其中机器与人类以分时模式在系统之内实现共存。”
这款聊天机器人拥有三大主要组件:智商(IQ)、情商(EQ)与个性(Personality)。其中的智商组件涉及特定的对话技能,例如回答问题、推荐问题以及讲故事等功能。情商则具有两个主要绝大部分:移情,包括预测交流对象的特征;以及社交技能,即对用户做出个性化响应。至于个性,研究人员在论文中指出,“小冰被设计成一个 18 岁的女性角色,她可靠、富有同情心、深情并拥有一种奇妙的幽默感。”
如何优化聊天机器人?在小冰的优化方面,微软公司设定了一项名为每会话对话转换(Conversation-turns Per Session,简称 CPS)的指标,其代表着“聊天机器人与用户在对话场景中的平均对话转换次数”。其基本思路在于,CPS 指标越高,则代表对话周期越长——这似乎能够很好地体现用户满意度(在大多数情况下)。小冰具有分层结构,其能够追踪对话状态,并从各种技能及行为中做出选择,从而随时间推移优化自身响应能力。
微软的数据红利: 自 2014 年启动以来,小冰已经生成了超过 300 亿次对话(截至今年 5 月);这证明 AI 应用程序本身即可成为重要的数据集生成器,并有望最终避免对大量外部数据的严重依赖。研究人员写道,“目前,有 70%的回应内容源自小冰以往的谈话内容积累。”
混合 AI: 小冰并没有使用大量预学习组件,不过如果认真观察系统架构,大家会发现其中明显采用了某些神经网络技术——例如在回应用户时,小冰可能使用“神经反应发生器(基于 GRU-RNN)”以提炼出潜在的回语反应;或者使用基于检索的系统使用外部知识库。其还会利用预学习系统支持其它组件,例如分析图像并从中提取实体,而后借此与用户交谈或玩游戏。这一切,都令小冰拥有着出色的个性化水平。
那么小冰的规模与有效性如何?微软方面解释称,自 2014 年推出以来,小冰已经成为一套能够支持多种其它聊天机器人的平台,“具体涵盖超过 6 万个官方账户、Lawson 以及 Tokopedia 的客户服务机器人、〈精灵宝可梦〉、腾讯以及网易聊天机器人”等等。
另外,自启动以来,小冰的 CPS(即用户参与指标)已经由第 1 版中的 5 提升至 2018 年年中的 23。
重要意义:随着 AI 技术的工业化,我们看到众多企业构建起能够与数亿人次交互的系统。而随着时间推移,这些系统的功能也在不断完善。这些产品与服务为我们提供了一种绝佳的 AI 部署校准方式,同时也让我们意识到 AI 技术已经做好正式登上主流舞台的准备。
Jack 的个人推测:在这里,我推荐大家参阅论文中的图十九,其概述了小冰自推出以来实现的功能成长。目前的聊天机器人由一系列不同服务与技能所构成——其中大部分为人类手工开发,一小部分由源自神经技术学习——而随着小冰使用次数的增长,微软能够获得与用户/系统交互活动相关的海量数据,以及此类系统如何在非人类基础设施层面实现交互的大量元数据。更具体地讲,微软(包括其他开发者)完全能够利用这些数据训练出各类端到端小冰类原型系统。虽然其功能无法与主系统相比肩,但仍然能够带来重要的学术性启发。
了解更多: The Design and Implementation of XiaoIce, an Empathetic Social Chatbot (Arxiv)
美国政府通过法律,要求广泛实现数据开放性与机器可读性

…可用数据量将远超你的想象…
千万别总以为政府吃白饭不干正事:美国众议院与参议院最近通过的新立法,就在强烈建议各联邦机构在软件许可允许的前提下以机器可读的格式进行数据公开。另外,这项立法还要求各机构公布全部数据资产清单。
了解更多:
Summary of the OPEN Government Data Act (PDF, Data Coalition summary)
OPEN Government Data Act explainer blog post (Data Coalition)
Facebook 发布超高速语音识别系统 wav2letter++
…wav2letter++采用 C++以实现极高运行速度…
Facebook AI Research 团队发布了 wav2letter++,这套采用卷积网络(而非递归网络)的语音识别系统在先进程度方面可谓风头无两。Wav2letter++利用 C++编写而成,因此其拥有着远超其它高级语言编写系统的执行效率。研究人员们写道,“在某些情况下,wav2letter++的运行速度能够达到其它用于训练语音识别类端到端神经网络的优化框架的两倍以上。”
结果:wav2letter++在 LibriSpeech 语料库上的单词误判率约为 5%,单一样本处理时长为 10 毫秒,而占用内存量约为 3.9 GB;相比之下,ESPNet 的误判率为 7.2%(每样本处理时长为 1548 毫秒);OpenSeq2Seq 误判率同样为 5%,每样本处理时长为 1700 毫秒,内存占用率则高达 7.8 GB。(不过需要强调的是,OpenSeq2Seq 可以通过在训练时使用混合精度的方式提高效率。)
重要意义: 语音识别已经由过去主要由私营部门及(秘密)政府机关开发的专有性技术,转化为更易被更多人采用的开放性成果。目前,Facebook 等企业就拿出多种高水平版本并免费供大家使用。这同时也被视为人工智能产业迎来广泛化应用的重要标志。
了解更多:
wav2letter++: THe Fastest Open-source Speech Recognition System (Arxiv)
哪些 AI 突破不是真正的突破?ICLR 论文评审就此做出讨论

…哪些 AI 突破并不属于真正的突破?评审人员认为,如果涉及大量工程因素,即代表缺乏突破性…
如果某项 AI 突破的大部分工作,都集中在精心规划下的系统工程设计与规模化算法的配合,那么这还能不能算是真正的“AI”突破?抑或只是一种工程技术层面的进展?这看似是个奇怪的问题,但却在人工智能研究人员当中成为反复出现的重要讨论对象。目前,一部分相关结论已经正式出版,而来源正是 DeepMind 提交至 ICLR 的一篇名为《超大规模视觉语音识别(Large-Scale Visual Speech Recognition)》的论文。
这篇论文主要讨论关于唇读技术的最新进展,其结果大大超越原有 SOTA。除了引入大规模基础设施之外,其中还结合了一系列优雅的算法技巧。然而,论文最终被拒,其中一位主评审人员解释称“这是一项出色的工程性工作,但却很难给其他人带来指导意义。”
重要意义: AI 研究界目前正面临着越来越多组织机构积极投入人工智能研究工作的浪潮。而且根据观察,我发现“小型计算”领域的研究人员与“大型计算”领域的参与方(例如 DeepMind 以及 OpenAI 等等)之间出现了一种紧张的关系。更具体地讲,如果来自某一领域的研究人员无法构建起适用于其它领域的系统成果,会引发怎样的影响?这种现象正在改变人工智能研究界的态势,目前大部分学术工作者都会对新算法的开发进行双重考量,而后在(相对较小的)数据集(也就是小型计算)上进行测试;但在另一方面,那些拥有大型技术基础设施(通常来自巨头级企业)的研究人员则主要着眼于大型算法,并主张以进一步扩大算法规模的方式探索技术发展方向。
了解更多:
Large-Scale Visual Speech Recognition public comments (ICLR OpenReview)
欧盟发布首份人工智能道德准则草案
欧盟委员会下辖人工智能高级专家组日前发布了其人工智能道德准则草案。他们目前亦邀请公众对此份草案提出反馈意见,并计划于 2019 年 3 月发布最终版本。
可信赖 AI:这份欧盟框架专注于将“可依赖 AI”作为人工智能技术的开发与部署目标。所谓可依赖 AI,要求其尊重基本权利与道德原则,且拥有技术健全性。框架当中确定了几项核心性道德约束:人工智能应旨在改善人类福祉、保护人类机构,并以公平透明的方式运作。
此份报告还规定了以上述人工智能系统约束要求为指导的十项具体要求,包括:问责制、数据治理、可访问性、人类监督、无歧视、遵循人类自治、尊重隐私、稳健性、安全性以及透明性。
具体问题: 近期人工智能的部分应用方式可能与上述原则产生冲突,例如自主武器、社会信用系统以及某些监控技术等。有趣的是,欧盟方面要求公众就人工智能及人工通用智能(简称 AGI)可能带来的长期风险提交具体意见,并表示这些问题在专家组中同样“极具争议性”。
重要意义: 这是一份相当详尽的报告,其中汇总了人工智能领域值得高度关注的一系列道德考量因素。不过这些指导方针能够带来怎样的长期影响,仍取决于相关合规制度的建立以及是否能够被主要 AI 参与方所重视。事实上,目前全部主要 AI 参与方皆来自欧洲以外的地区(其中的 DeepMind 可能是个不大不小的特例,虽然其总部位于伦敦,但母公司 Alphabet 却身在美国)。鉴于上述问题的重要意义(详见下文),我们很遗憾地意识到在这些关注重点上取得长期进展恐怕面临着诸多重大挑战。
了解更多:
Draft ethics guidelines for trustworthy AI (EU)](https://ec.europa.eu/digital-single-market/en/news/draft-ethics-guidelines-trustworthy-ai)
Jack 谏言:认真看待 AI 风险

多位全球顶尖人工智能专家都在认真思考先进 AI 可能给人类带来的长期未来威胁。我建议大家认真阅读这篇由 Vox 发表的解释文章,其中涵盖了关于这类观点的核心论点,同时对目前正在进行的 AI 安全工作做出了概括。
在 2016 年的一项调查中,有五成专家预测称 AI 将在未来 45 年内全面取代人类,亦有 5%受访者认为 AI 会给人类带来极端性负面后果——甚至导致人类灭绝。人工智能安全成为一大新兴研究领域,其目的在于降低这些灾难性风险的出现机率。相关举措包括通过技术性工作将人工智能与人类价值观相结合,并推动人工智能的国际治理研究。尽管重要意义得到普遍认可,但目前全球人工智能总支出约为 190 亿美元,而人工智能安全支出每年仅为约 1000 万美元。
了解更多:
The case for taking AI seriously as a threat to humanity (Vox)
When will AI exceed human performance? Evidence from AI experts (arXiv)
作者 Jack Clark 有话对 AI 前线读者说:我们对中国的无人机研究非常感兴趣,如果你想要在我们的周报里看到更多有趣的内容,请发送邮件至:jack@jack-clark.net。
参考链接:

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论