

古埃及人根据天狼偕日升和尼罗河泛滥周期的长期观测,准确预测出洪水到来和退去的时间,并收获大量肥沃土地来耕耘;托勒密根据喜帕恰斯留下的大量观测数据建立模型,高精度预测了今后某个时候某个星球所在的位置;再从“朝霞不出门,晚霞行千里”的古谚语,到通过气象卫星、雷达收集并进行气象数据同化来精确预测天气,我们发现“预测未来”不再仅仅打着“科幻、超能力”的标签,更能通过获取、分析数据,让未来照进现实。
云计算为何需要预测?
预测源起于“动”,正因非静态才无法确定未来某一时刻的状态。而“动”的程度决定了预测的难度。
从云上用户 需求侧 看:业务负载、业务规模、设置的告警阈值都在变动
从云资源 供给侧 看:用户数、资源使用率、碎片率也在变动
如果能提前预测客户需求,就能通过智能推荐、智能告警等来提升易用性,更能提前进行硬件规划、资源腾挪,保障流量洪峰下的扩容诉求,助力实现 “极优、极简”的云上体验。
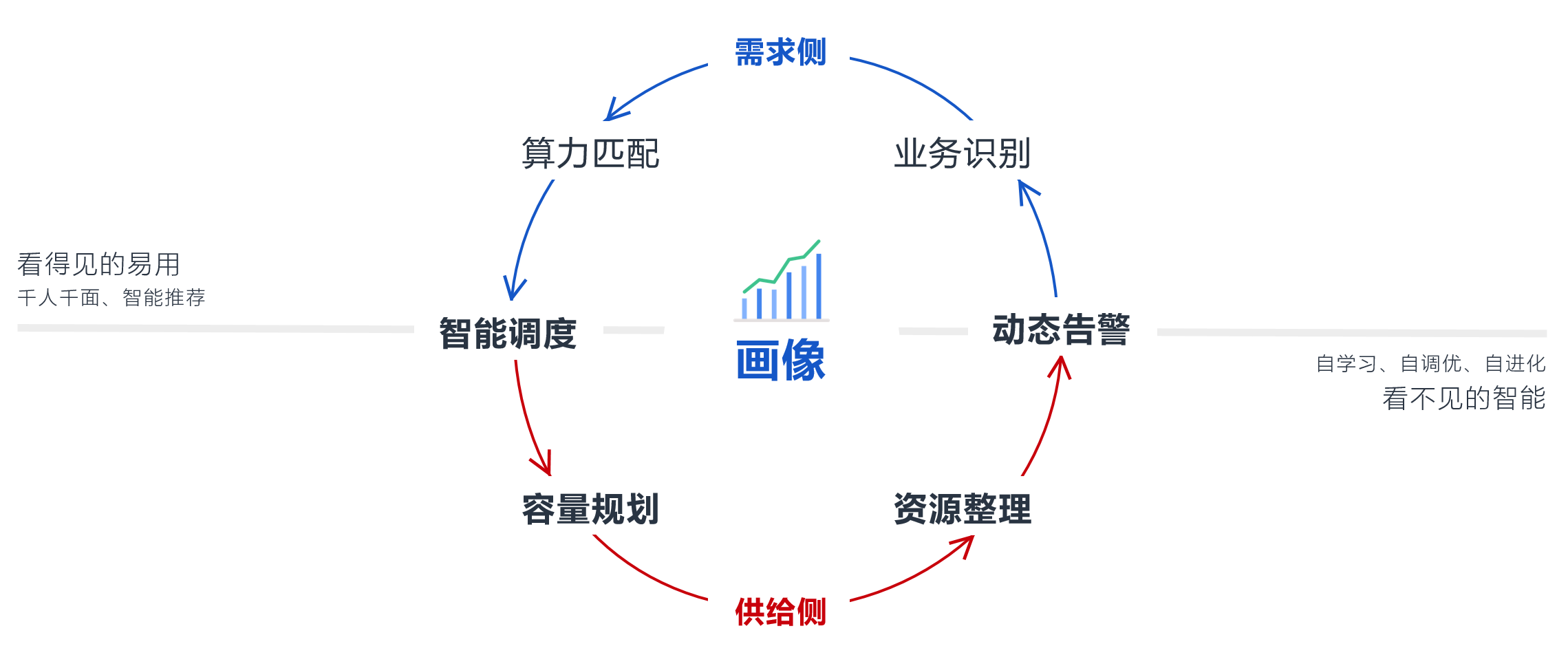
图 1 “看得见的易用”与“看不见的智能”
预测的内核:云上资源智能画像
资源智能画像(以下简称“智能画像”)是构成华为云瑶光“多维智慧”的关键一环。根据 VM 历史资源利用率、VM 请求时间间隔、Flavor 生命周期等历史数据,利用 关联分析模型 和 深度学习算法,可用来描绘资源表面、内在以及未来。智能画像的引入让云平台资源管理更加精细化、智能化。
画像关键技术剖析
关键技术一:时序预测
在云服务中,像容量预测,主机热点、动态告警等都涉及到时序预测,即如果知道一段历史时间(T*时刻以前)的数据变化规律,如何去预测未来一段时间的变化趋势呢?生活中如天气的变化、人口增长、经济增速、股票波动,甚至最近大家比较关注的新冠疫情的发展都属于时序预测范畴。
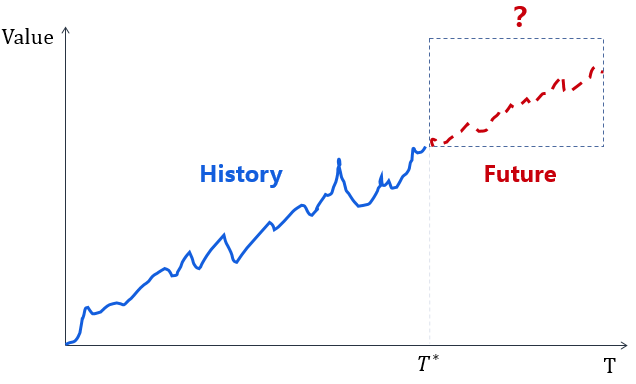
图 2 时序预测
云上时序预测的输入主要来源于主机或虚拟机的资源利用率,而云上业务的复杂多变,也提升了分析资源利用规律的复杂度。总体而言,有三方面的挑战:
波形的复杂性:我们初步分析历史 trace 的数据并形成图像,可以看到有少部分是平稳的甚至是有近似周期性的,也有一部分呈现上升或下降的趋势,但更多的是单个“山峰”或者偶尔突发的情况,甚至会有频繁地上下震荡;
业务的叠加性:以上波形表征的多样性,主要是由于云平台中单台物理主机上可能运行着多个租户的多个 VM,同时单个 VM 也可能运行着多种应用;
不可以预见的人为因素:比如因促销而产生的批量订单往往会导致某个资源池无法容纳;超大规格 VM 的偶然创建也可能引发一些容量事件。
#经典 #
如果从波形的特性来看,可以大致把时序预测归为 周期性 和 非周期性 两大类。对于周期性的预测问题,谷歌在文献[1]中提到可以判别历史曲线中是否有重复出现的相似性模式窗口,当然可以通过 Pearson 相关系数来计算任意两个模式窗口的相似度。但由此引发一个问题:模式窗口(即周期长度)的大小又如何确定?我们首先想到的是快速傅里叶变换(FFT),即把原始数据的时域变化转为频域的变化,然后模式窗口的大小等于采样率与信号功率最大的频率分量的频率之商。
其实还有一个更加直观的办法,如图 4 所示,大家可以想象一个连绵起伏的山峰,如果每个山头是类似的,那么任意相邻两个山头最高点(峰值)之间的距离应该是近似相等的。基于这个语义,我们想到一个办法:把时域数据转为功率谱,取出功率谱中前_l _个(比如 100 个)峰值,计算相邻两个峰值之间的距离,如果这个距离数据的变异系数(即标准差除以期望)足够小(如小于 0.1),那么可以认为这些峰值是等间距的,尤其可以判定其周期性及周期的长度。
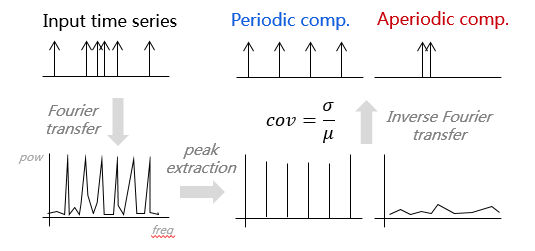
图 3 周期性预测办法
至于非周期性的预测,则有非常多的模型可以参考。如比较经典的 ARIMA 模型(图 5),其主要分为 AR(自回归)和 MA(滑动平均)两部分。首先把原始数据进行差分(即依次把后一时刻的值减去前一时刻的值得到新的序列,可以多次差分,但一般不超过三次),将不平稳的序列变平稳。当差分得到平稳序列以后即可进行模式识别:判别其符合 AR、 MA 或 ARMA 模型。AR 模型(自回归)认为需要预测的值是历史数据的加权;而 MA 模型(滑动平均)认为下一个值的波动性是历史波动性的加权。综合这两方面可以得到下一个预测结果。
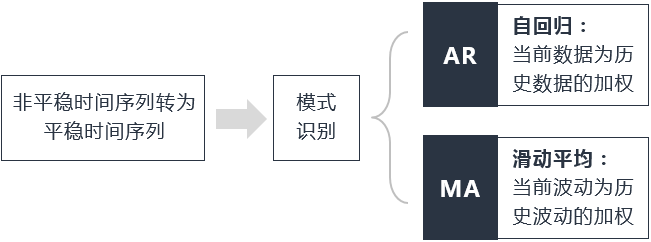
图 4 ARIMA 模型
此外还有马尔科夫(Markov-Chain)模型(图 6),其核心思想是条件概率。比如到银行很可能是办理金融业务、最近体温升高则有可能患上新冠肺炎等等。同样的道理,我们可以把 CPU 的利用率划分成若干个区间,通过对历史数据的统计,比如当处于区间[30%, 60%)(State 2)时,未来的利用率有 60%的概率还会停留在本区间范围,而分别有 20%的概率会转移到区间[0%, 30%)(State 1)或区间[60%, 100%)(State 3)。通过这样的办法,可以得到一个完整的马尔科夫状态转移(MDP)图,由此可以对未来的时刻的资源变化进行预测。
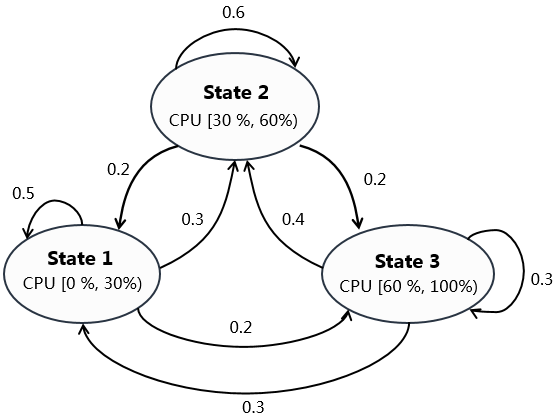
图 5 马尔科夫模型
#进阶 #
Facebook 针对其社交平台上用户点击和转发事件数的预测提出了 Prophet 模型[2]。。由于其社交平台的数据具有明显的周期性、趋势、节假日以及存在个别的异常点(噪音),所以 Prophet 本质上是一个广义叠加模型(GAM),即把前面提到的四方面分别建模再进行累加而成。AWS 则提出了 DeepAR 模型[3],主要用于其店铺销售的预测,其基础理论是 LSTM[4],即长短期记忆神经网络,通过一些门的设计来控制历史长河中哪些信息应该遗忘、哪些应该保留下来。
#前沿 #
谷歌在 AGILE 系统[5]里提出了一种分解预测再组合的思路。打个比方,在一个房间中,如果一千个人同时在说话,那么最终的音频可能是一段看起来杂乱无章“噪音”,但是如果把每个人说的话分离开来,那么每个人说话是清晰的也是可预测的。
基于这个思想,可以设计一个分解-组合的预测模型(图 7)。首先,对原始的资源曲线使用 EMD(黄鄂院士所提出的经验模态分解)技术分解成若干平稳子序列以及残差项;然后对于每个平稳子序列使用传统的时序预测算法进行预测;最后再把所有预测结果进行累加,从而得到最终的结果。
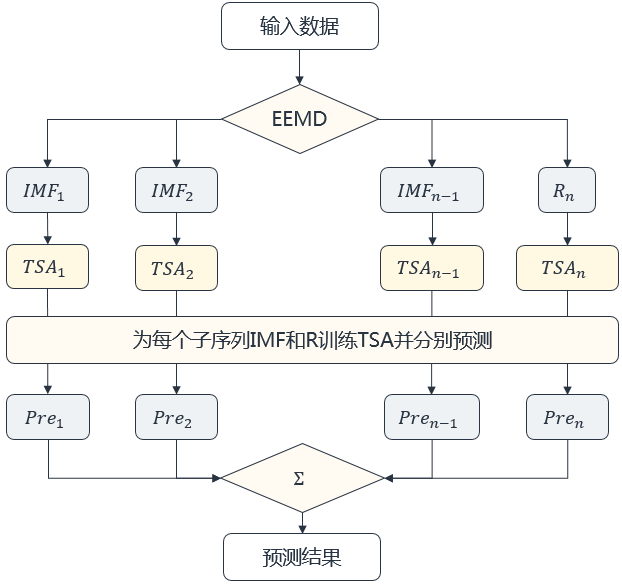
图 6 分解-组合预测法
关键技术二:业务识别
云平台每时每刻承载着海量的业务,这些业务中有些是 CPU 密集型的,有些是内存密集型,也有些是网络密集型等等。假设大家都“抢”CPU 资源,且这些业务都放在同一台主机上,那么就会引发资源争夺的“打架”行为,造成业务之间的互相干扰;但如果把相同密集型的业务分开放,比如 CPU 密集型与网络密集型混合放置,那么也许可以“和平共处”[6]。由此,引出一个问题(图 8):在云上如何从底层的资源监控数据能够准确地识别上层业务类型,从而尽可能减少业务间的干扰性,保证租户 QoS?
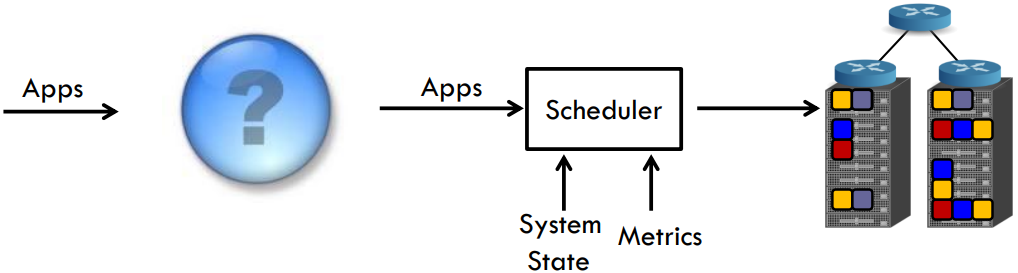
图 7 业务识别与 QoS 调度
首先,我们可以通过各维度资源的利用情况进行关联性分析,使用 Spearman 系数计算任意两个维度的关联程度,形成一个“feature map”(图 9)。此外,我们还可以在原始的数据序列中使用多个不同大小的滑动时间窗口,在每个时间窗后中提取数据更细粒度的特征,类似“卷积核”的办法。综合以上两方面,可以对业务类别进行初步的画像。
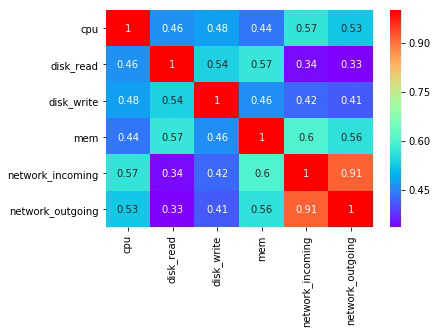
图 8 资源利用相关性
关键技术三:算力匹配
我们在业务识别中发现一个现象:相当一部分用户其实不清楚什么样的虚拟机类型/套餐(通常称为 flavor)最适合其业务。因为从监控数据可以看出,大部分用户资源跑得很闲,即未能将资源充分利用起来;另外也有部分用户一直处于满负载状态,如可能运行大数据作业或 AI 应用。那么,如何给用户推荐既满足其业务诉求又使得性价比最高的最佳资源配置?如图 10 所示,用户通常只知道自己需要运行什么样的应用、有多大的数据量、需要什么时间点完成以及有多少预算等等,虽然用户倾向于更便宜的虚拟机类型,但通常不知道哪种类型性价比最高。

图 9 算力匹配
一般的思路是把所有用户与历史所使用过的虚拟机类型(flavor)构成一个二维矩阵,如果一个用户使用过某种虚拟机类型,那么我们就可以根据租户的资源使用情况对 item 进行综合打分。当然,最终的矩阵是非常稀疏的,我们需要做的是通过 SVD&PQ 这类的算法进行矩阵分解并且预测那些用户没有使用过的虚拟机类型的分值,并根据这个分值大小进行推荐。
但是,如果仅根据最高预测分值进行推荐,可能会导致某些用户增加的成本较高。如图 11 所示,假设某个用户原来使用 1u1g 的虚拟机规格,瞬间给其推荐 4u8g 的配置,从业务上也许已经缓和其高负载状况,但是用户需要多付的钱可能是其不能接受的。因此,需要综合考量虚拟机价格和规格大小进行推荐距离度量,给出合理的推荐范围。
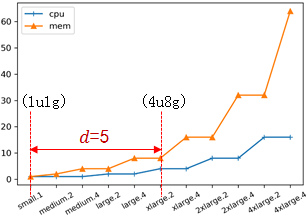
图 10 推荐距离度量
Case Study
容量画像与最佳适应调度
一方面,如果能够对资源池余量进行精准画像,即通过设计测算定理预测每种 flavor 未来还能放置多少;另一方面,可以统计每种 flavor 在过去请求 trace 中的分布比例。结合这两方面的信息,可以设计一种容量调度算法 Besfit Capacity 用于虚拟机在线调度,以让任意两种 flavor 的剩余容量比尽可能接近于它们的历史请求比。
这里采用首次发放失败时,算法接收的请求数量与最大理论上界的比值作为评测指标,从下可以看到,相比传统 Cosfit 算法及其改进算法,Besfit Capacity 算法表现更优,甚至某些场景下比传统 Bestfit 算法更好。
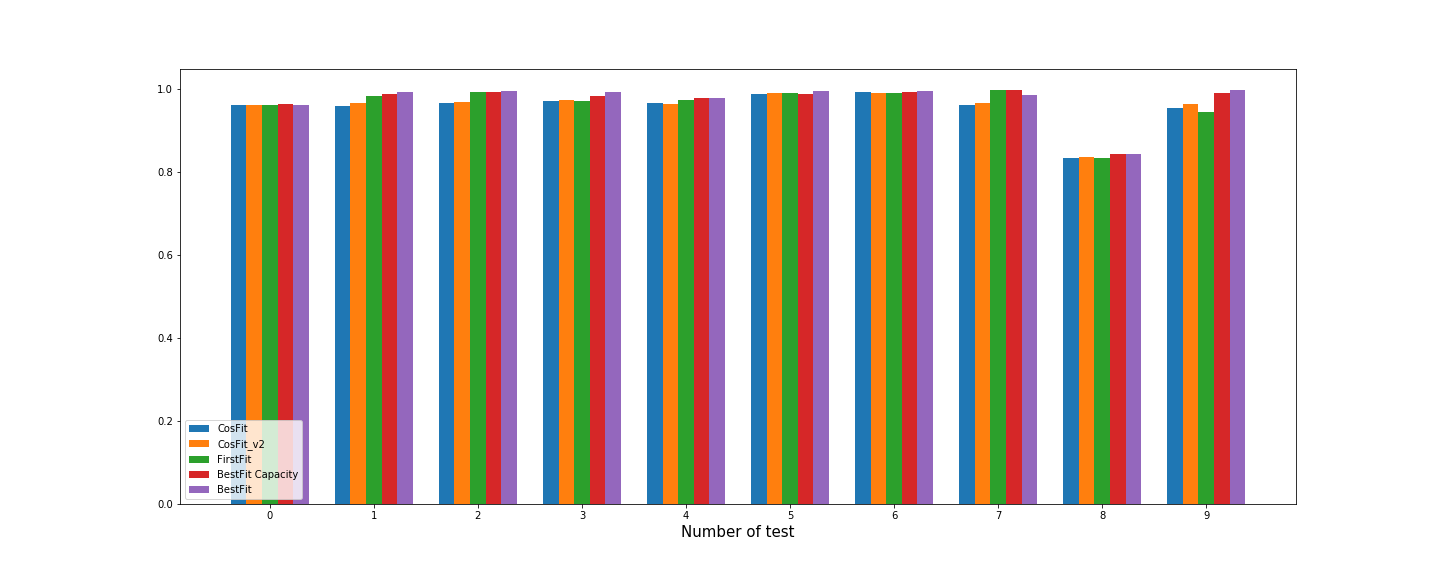
图 11 容量调度对比实验
利用率画像与弹性调度
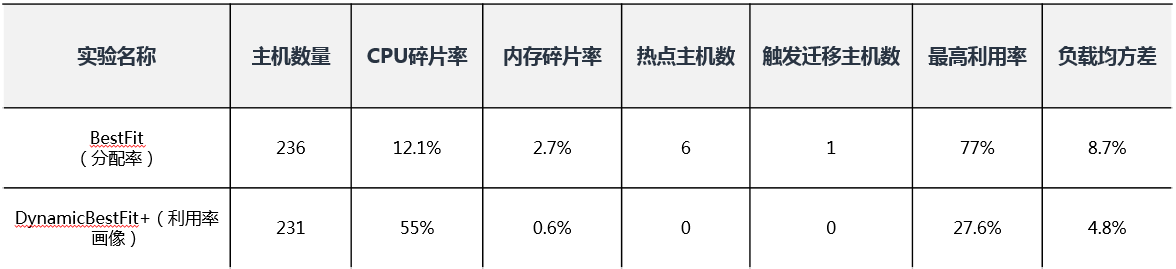
传统虚拟机调度是基于分配率的,但实际上大部分虚拟机处于低利用率状态,并且不均衡的利用率情况下,容易产生热点主机(即主机资源利用率>60%)。这里通过利用率预测的办法,把基于利用率调度与基于分配率调度进行对比实验,同时对相同一段时间的历史请求序列进行回放。从表 1 可以看到,相比分配率调度,利用率画像+动态 Bestfit 算法可以少用 5 台主机,内存碎片率减少 2.1%,同时热点主机数从原来的 6 台减少到 0 台。
表 1 - 利用率调度与分配率调度对比实验
资源预测与容量规划
前面介绍的分解-组合预测法 EEMD 与传统 Holt-Winters 进行的实验对比分析,使用两个 trace 分别预测它们未来半小时、一小时以及一个半小时的资源用量,并且预测多次。从下图可以看出,EEMD 预测法拟合效果更好、性能更加稳定,尤其在较长时间的预测场景中,预测误差可比 Holt-Winters 减少 20%以上。我们使用这个方法进行容量规划,预测准确度 95%以上,上线后有效将容量引起的客户事件数减少 60%以上。
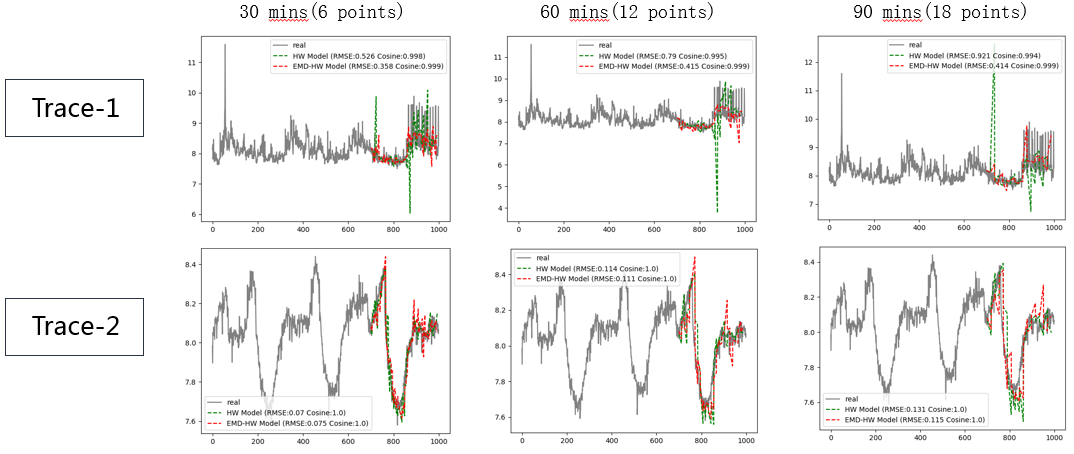
图 12 EEMD 与 Holt-Winters 对比实验
华为云瑶光(Alkaid)智慧云脑作为面向云、AI、5G 的智能云操作系统,承载未来“分布式、确定性、多维智慧”的云,致力于打造“极优、极简”的云上体验。#瑶光 TechTalk#是联合瑶光实验室的技术大咖们组织的系列深度技术专题,这里有算法技术科普、有前沿技术剖析、有瑶光实践干货。戳链接看本期回放,直播间扫码 Get 最新瑶光资讯https://huaweicloud.bugu.mudu.tv/watch/y7d83y3o
参考文献
[1] PRESS: PRedictive Elastic ReSource Scaling for cloud systems, CNSM, 2010.
[2] Forecasting at Scale, The American Statistician, 2017.
[3] DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks, CoRR, 2017.
[4] Long Short-Term Memory, Neural Computation, 1997.
[5] AGILE: Elastic distributed resource scaling for Infrastructure-as-a-Service, ICAC, 2013.
[6] Paragon: QoS-Aware Scheduling for Heterogeneous Datacenters, ASPLOS, 2013.

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论