
当我们讨论视频清晰度时,我们在讨论什么?
一、背景介绍
很多时候清晰度会被等同于视频分辨率和码流等等,在 PGC 时代也确如此,电影、电视剧、新闻媒体等都是通过专业设备录制剪辑和压缩,制作精良的源视频能够代表最高的清晰度,下采样降低分辨率和增大 QP 压低码流等操作都会丢失有效信息,导致视频清晰度变差。此类场景下我们能够通过峰值信噪比(PSNR)和基于人眼视觉特征的 SSIM 等评价准则来测量用户接受视频的主观质量,与源视频越相近则清晰度越高。然而在 UGC 时代用户多样化的视频录制设备和参差不齐的专业水平,无法继续提供有效的高质量源视频作为参考,用户看的视频既可能是由于压缩传输质量变差,也可能是由于低光照噪声和抖动等视频采集问题,这时只能根据 Human Visual System(HVS)的日常观察经验来判定视频的清晰程度。另外,比如游戏视频和屏幕分享等媒体内容的日趋多样化,也使通用且有效的视频清晰度评估算法发展变得更加困难。本文主要分享多媒体实验室和全民 K 歌团队合作开发的针对细分主播场景定制的无参考清晰度评估算法,主要介绍我们如何在细分场景获取有效标注数据、模型训练和模型部署之后的数据上报汇总分析的细节内容:
区别于常见 CV 标注的主观打分数据集构建细节
清晰度算法着重解决的问题及结果分析
针对低质量视频的讨论分析
客观无参考质量评估算法效果展示,如下为算法对最近采集上报视频的预测分数以及视频码率和分辨率(由于最多上传三个视频,故转码 gif 格式呈现,可能有一定质量变化):




二、数据集构建
近些年来,比较流行的基于 rank learning 的质量评估算法在很多公开的 IQA 数据集上(比如 TID2013、LIVE challenge 和 KonIQ-10K)都有比较明显的指标提升,rank learning 的无监督思路在一定程度上可以通过人为产生的数据对来缓解对主观标注的数据的依赖,进而在目前相对其他 CV 任务体积较小的主观数据集上取得不错的性能提升,但是依然很难有效解决训练样本与实际应用场景样本分布差异的 gap,针对细分场景的足够大小的数据集依然是质量评估算法落地的不可或缺的步骤。
通常的,CV 任务标注目标是如物体类别、位置和 mask 等客体信息,少量的熟练的标注人员即可满足标注的需求,但是 QA 相关的数据集捕捉的是广泛的人群对同一个媒体内容的平均主观评价信息,属于用户主体信息,必须有效地收集足够数量的被测者的评价结果,过滤掉个人的偏好等,从而获取接近真实大众评价,即所谓的 mean opinion score (MOS)。目前主观数据集的构建一般是参考 ITU recommendations。广泛使用的 TID-2013 数据集,共有 3000 张失真图片,共计有非重复的 971 人在实验室环境下参与一共 524,340 次打分,采用的是 pair-wise 的打分方式,平均每张图片被约 170 人打分,从这些数字我们可以看到主观数据集的构建是非常的耗时耗力,这也是现有主观数据集的大小受限的主要原因。
在足够的资金支持下,我们可以选择通过众包方式来完成主观打分,但将任务直接分发给公司外部的众包测试会遇到很多不稳定的因素,带来过多的噪声信息,无法控制每个 session 之间的休息间隔和用户多次重复参与打分等现象。为此我们从 2018 年就开始搭建了包含视频和音频的主观测试平台,通过建立防水墙和白名单等模式,经过了长时间的不同任务训练筛选过滤,屏蔽掉很多非法刷任务的薅羊毛党,逐步保留下来了一批质量相对稳定的用户定期参与我们的主观打分任务,这使得我们通过通过众包的方式能获得相对可靠的主观打分。
具体的数据集构建信息:
视频内容:2595 条视频,长度 5s,2135 条来自 K 歌,460 条来自微视
打分方式:三分类 (好中坏三挡)
参与人数:134 个独立用户
打分人次:30 组 x100 条视频 x60 人次=(2595+405) * 60=180,000,其中 405 条冗余视频用作一致性校验
有效比例:85.3%,根据打分偏向,一致性和 outlier 检测,共计剔除 264 组无效打分
打分方式:相对于常用的五分类打分,为了降低众包打分的复杂度,我们选用了更简单的三分类打分方式,可以一定程度避免混淆,也方便后续的埋点数据校验,易于数据的清洗。
Ksong Dataset 部分视频展示,最后一行为来自微视的视频源:

数据分布问题:K 歌直播场景为了保障产品的流畅度,相比于短视频等场景在在码率方面有所牺牲,一定程度上限制了高质量视频的比例,所以我们通过人脸检测+人工二次分类筛选出和 K 歌场景类似的约 460 条码率较高的微视短视频片段,其中大部分视频质量较高,从而使得数据源的分布更加均衡。
用户打分 raw data,打分选项 1,2,3 对应低,中,高质量:
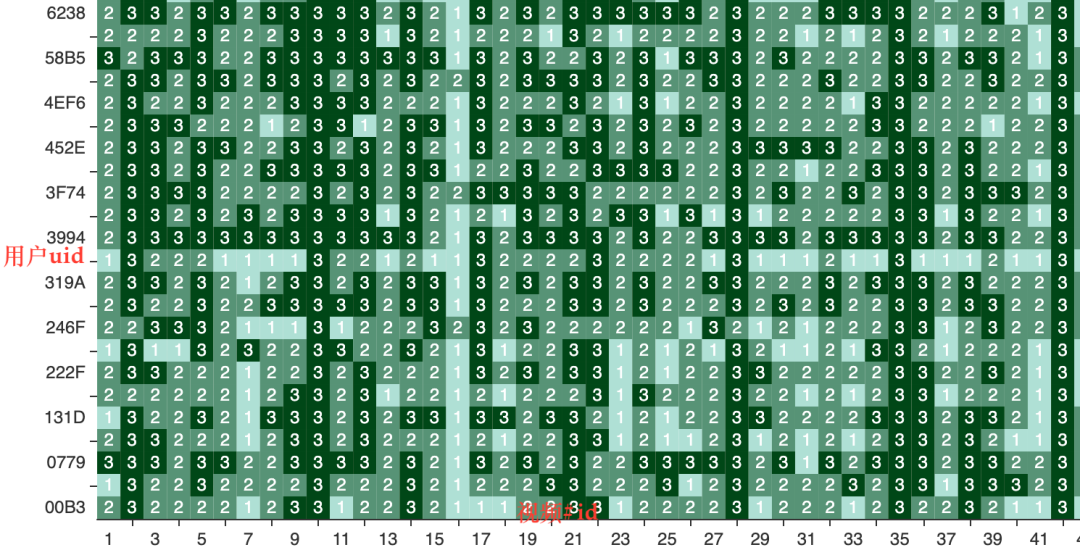
数据清洗:虽然参与打分的志愿者整体质量有所保障,但仍需对所有打分做数据清洗。用户参与的每个 session 包含共计 100 条视频,主观测试预估时长约 15mins,每组视频中有随机的约 13 条视频会重复出现两次。如果用户对这些埋点的 anchor 视频判定分数差距过大,比如同一个视频两次打分为 3 和 1,则该用户在此 session 所有的数据都会被视作无效数据丢弃。如果用户过多的给出接近全部是同一分数的打分,比如 80%打分均为 2,则也视为无效数据。另外,每组视频都获取到约 60 人次的打分,如果单一用户打分与平均打分偏差过大,则会被视作 outlier 丢弃。
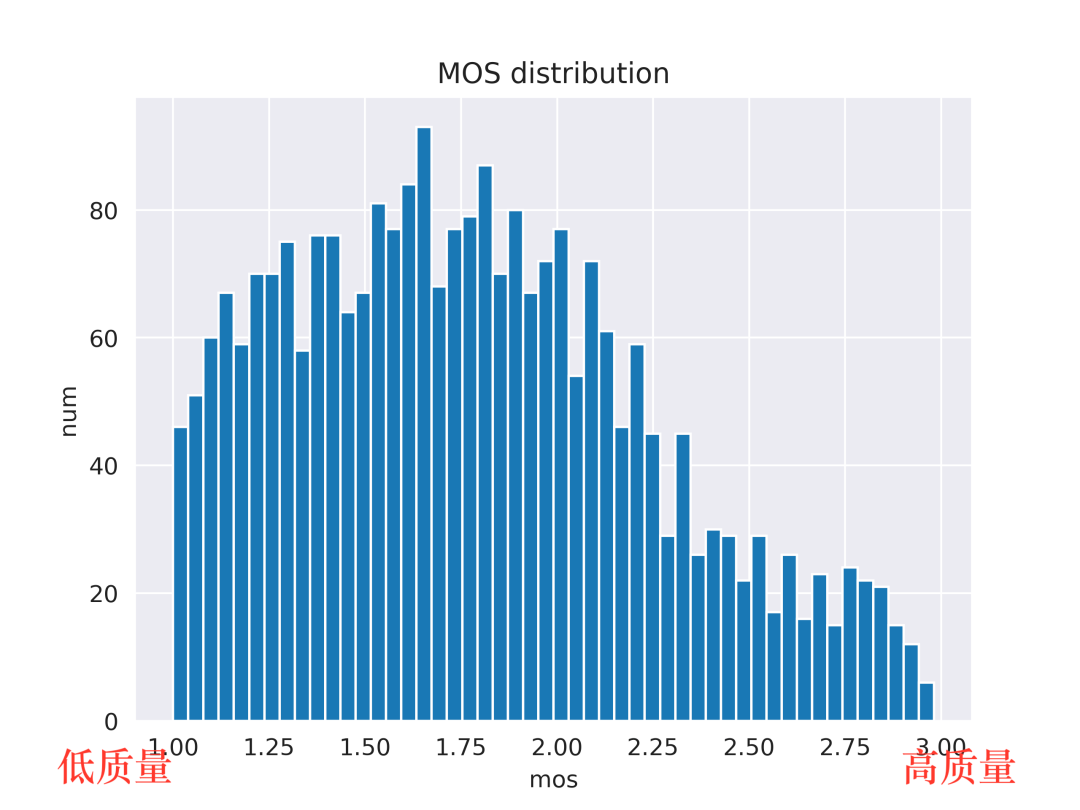
最终获得的数据集的 MOS 打分分布如上图所示,可以看出大部分的视频偏向于低质量的区间[1,2],也再次验证了加入码率更高的视频源的必要性。
三、算法及分析
我们的视频清晰度评估算法使用离散的视频帧作为输入,不考虑额外的时域信息,算法针对前处理、模型和训练方式的整体改进可以简要概括为三点:
Larger input:更接近 720p 的 672x448 输入尺寸
Hyper-column 结构:抬升 low-level 特征对质量预测的影响
结合 Rank-learning:利用 rank order 强化学习效果
使用不同的缩放函数的效果对比:降采样 4 倍之后使用 nearest neighbor 上采样:

Larger input:传统的质量评估方法如 SSIM 和 BRISQUE 等仅依赖于 low-level 特征即可达到不错的性能,这些算法除非是 multi-scale 情况下,通常是使用原始分辨率作为输入。CNN 常用的输入缩放尺寸如 224 等会大大降低图像原有的信息量,导致后续的算法性能降低。经过部分实验对比,通过全卷积方式 FCN 输入更大的图像尺寸,能够明显地提升预测效果。考虑应用场景视频的 aspect ratio 大都为 16:9 和 4:3 等,同时为了避免非均匀缩放拉伸带来的干扰 ,我们采用了(224x3)x(224x2)=672x448 的输入尺寸来更充分得利用有限的输入尺寸。如下图所示,视频的输入帧经过缩放之后填充至 642x448 的尺寸,保持 aspect ratio 的情况下输入的长或者宽缩放至 642 或 448,剩余部分使用 zero-padding 黑边;如果输入为横屏模式,则对视频帧做 90 度翻转。
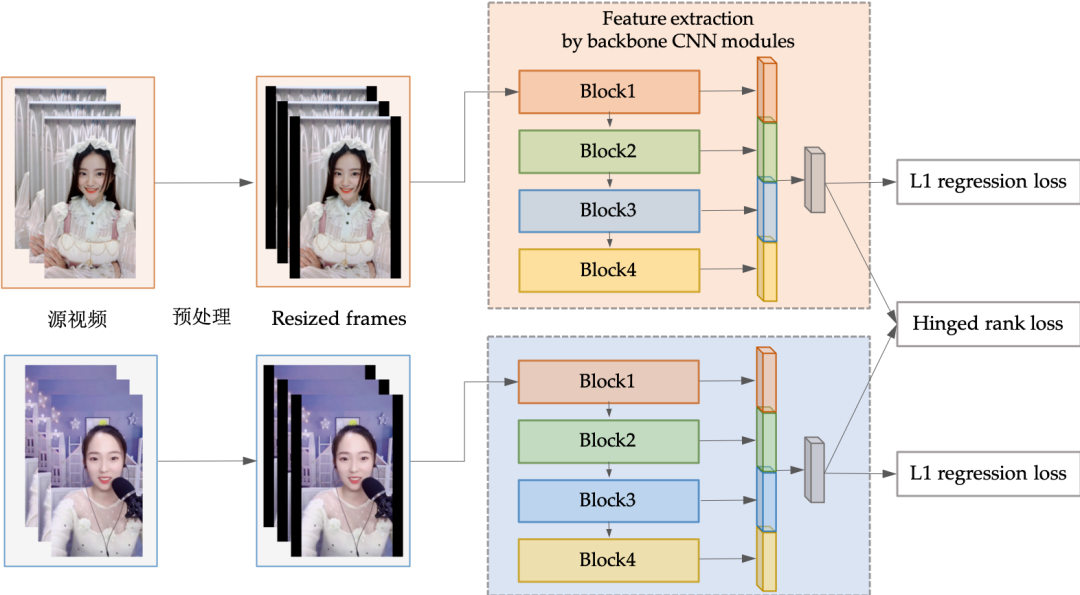
Hyper-column 结构:如上图的特征提取模块所示,我们借鉴语义分割中的 hyper-column 结构,对每个 block 的最后一层做 global avg pooling,分别提取不同 level 的特征向量并将所有 block 的的特征拼接在一起通过 FC layer 进行最终的评分预测。相比于直接在使用最后一层 layer 信息,hyper-column 对于语义分割可以提供更多的 local 细节位置信息,而对于质量评估则提供了更多的比如梯度变化等 low-level 图像失真信息。
Rank-learning: 除了常用的用于回归训练的 L1 loss,我们也结合使用 hinged ranking loss 来通过不同视频之间的分数差来强化视频 order 的学习效果
L1 Loss: L_reg = sum|mos - pred|
Hinged rank loss: L_rank = sum(max(0, thres-(mos_a – mos_b)*(pred_a-pred_b) ))
Overall Loss: L = L_rank + lambda*(sum(|mos_a-pred_a|+|mos_b-pred_b|))
模型训练方式分为两步:首先在公开数据集 KonIQ-10K 进行预训练,之后在 KsongDataset 进行进一步调优训练,两次训练采用相同的参数如下:
{ "arch":"resnet18 or other backbones", "epochs":100, "batch_size":256, "opt_id": Adam, "lr":1e-4, "loss_type": reg+rank, "workers":24, "shuffle":1, "fixsize":[672,448]}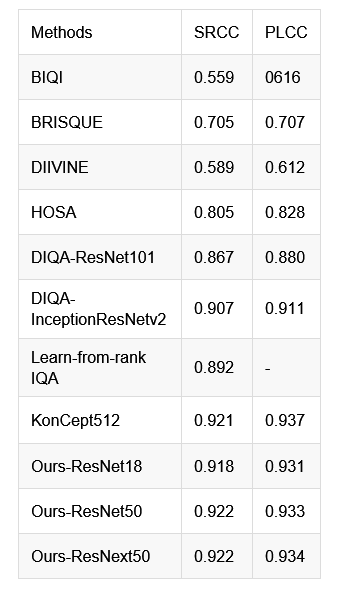
在 KonIQ-10K 数据集上,BIQI, BRISEQUE, DIIVINE 和 HOSA 为使用传统特征的评估算法,指标最好的 HOSA 的 PLCC 和 SRCC 均在 0.8 左右(PLCC 和 SRCC 区间为-1 到 1,越接近约 1 则正相关性越强,-1 为负相关,0 为相关性最弱;PLCC 关注线性一致性,SRCC 关注单调性);和近期的 DIQA 和 Learn-from-rank IQA 等 CNN based 方法对比,我们的算法的预测效果与 state-of-the-art 的指标不相上下,SRCC 和 PLCC 指标均在 0.9 以上。

Hyper-resnet18 在 KsongDataset 的 scatter plot,散点分布越贴合中心实线,算法与人眼主观预测的相关性越好:
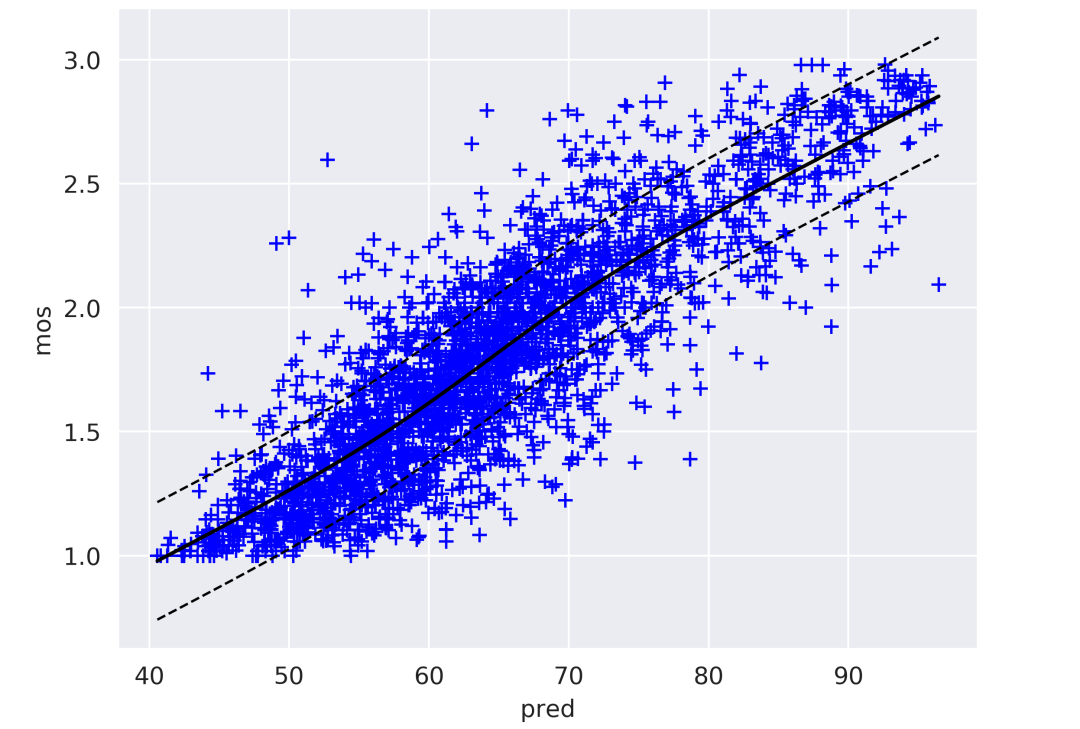
从使用不同 backbone models 结果对比来看,基于 ResNet50/ResNext50 的算法在 KSongDataset 上的 PLCC/SRCC 指标相对较高,但是考虑到 ResNet18 指标与之很接近,但模型更小且前馈速度更快,所以目前我们主要使用的是基于 ResNet18 的质量评估算法。
四、讨论
目前我们算法已经集成在 QUAlity Standalone Interface (QUASI) SDK,对 K 歌每日线上视频片段进行扫描,经过从 2020 年 1 月份至今约 3 个月左右的线上监测,我们进一步验证了算法对清晰度评估的可靠性,同时也收集到一批低质量的视频序列。作为无参考视频清晰度闭环反馈的关键步骤,我们针对性分析了低质量视频的产生原因,迭代了低质量原因分析算法,从而进一步提升 K 歌直播视频的整体质量。
2020-04-13 低质量视频片段,常出现强噪声、过曝光等明显失真类型:


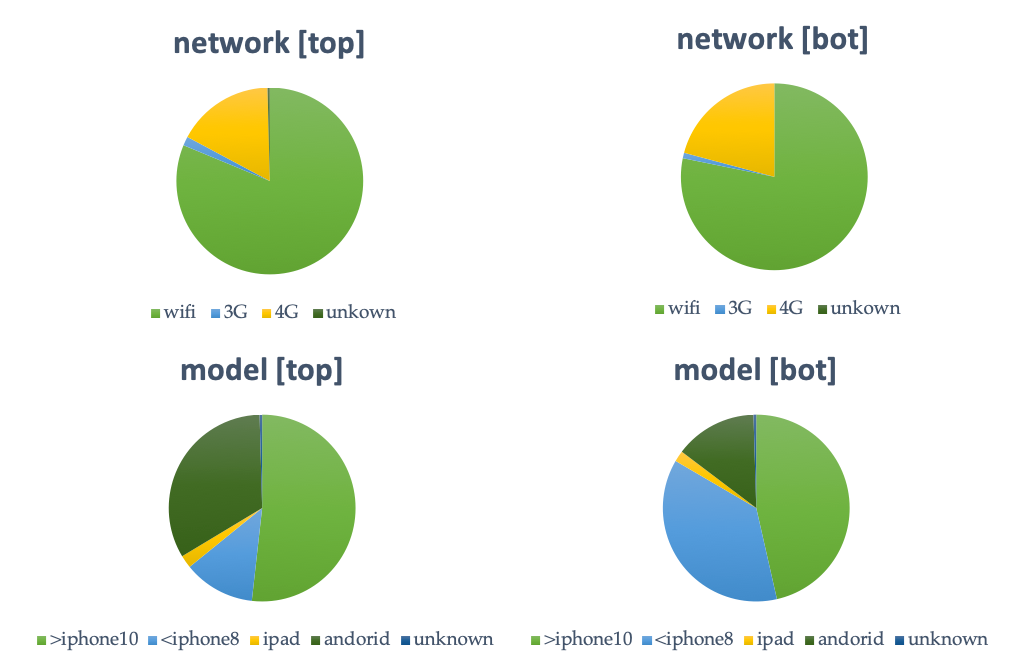
低质量视频分析:我们首先分析了头部用户和尾部用户的质量是否和设备网络等硬件设备有明显相关性。如下图所示,我们采集了约 450 个主播的网络和设备信息,发现网络类型主要是 3G、4G 和 WIFI,从分布比例上头尾主播没有明显的差异。用户机型方面,我们主要分为三类:>=iPhone10 的机型,<=iPhone8 的机型、和 android 机型。由于 android 型号复杂且收集的型号不全,我们更侧重 iPhone 机型用户的对比,如下图所示,我们发现头部用户使用相对老旧的“<=iPhone8 的机型”的主播相比尾部用户的比例更少。
由于全民 K 歌主播大多使用手机的前置摄像头来采集直播画面,我们来看下 iPhone 不同机型的设备细节:
iPhone7 front camera:7 MP, f/2.2 aperture, 1080p HD video recording
iPhone8 front camera: 7 MP, f/2.2 aperture, 1080p HD video recording
iPhone 11 Pro max: 12 MP, ƒ/2.2 aperture, 1080p HD at 30 or 60 FPS

硬件方面 iPhone11 相对于 iPhone7 的提升主要是在分辨率从 7MP 提升至 12MP,其他字面硬件细节区别不大,但根据专业测评网站的不完全的测评打分(iPhone X, Xs 11 Pro)我们可以看到,每年的 iPhone 更新换代对前置摄像头的录制效果也是有比较可观的提升的。这样我们可以初步得出一个结论:头部较多比例的主播使用了相对较新的硬件设备,对视频录制的效果提升有一定的帮助。
虽然我们是无法保障每个用户都是用最好的设备,但是我们依然是可以采用不同的措施来辅助改善用户的视频清晰度的。手机平板等前置摄像头相对于后置摄像头自身感光 CMOS 元器件面积过小,镜头入光量也有限,导致在常见的室内/夜晚等直播环境下对录制光照环境比较敏感,视频质量容易受到环境光的干扰,很容易在弱/强光源下导致欠/过曝光的现象,如背景光过弱导致整体画质变差、背景灯光直射导致局部过曝光和光线不均。在弱光环境下,相机 ISO 调高也会导致非常明显的白噪声类型失真。所以根据收集到的低质量视频,我们调整测试开发了相应的基于 low-level 特征的过曝光和噪点检测的等算法,可以实时监测用户直播的周遭光照环境,可以试试提供:如调整室内灯光、增加补光设备和摄像头角度调整等建议和调整策略。
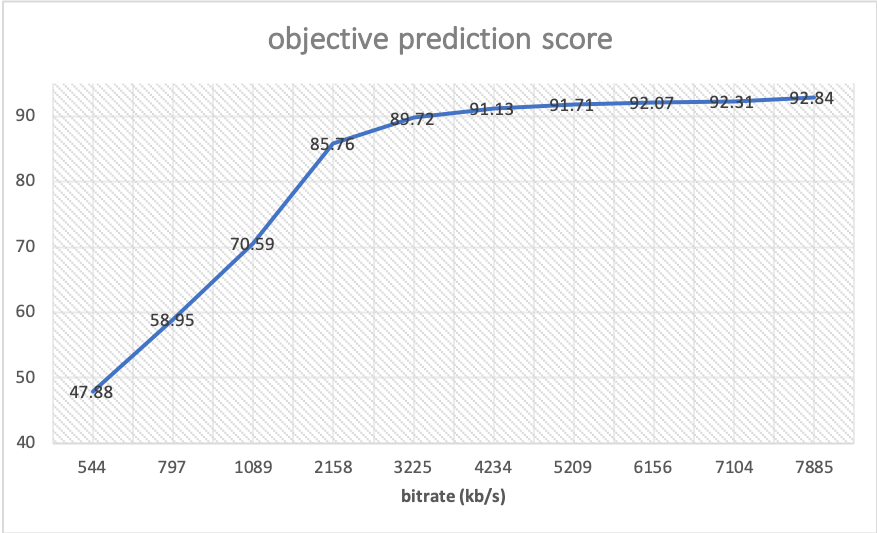
码率 &质量:另外,我们也可以看下清晰度算法对一些高质量视频在不同转码码率的质量变化趋势预测效果。我们将上图所示高质量 demo 视频转码至 500-8000kb/s 之间的不同码率,可以看到视频在 2000kb/s 的码率以上时,视频质量的降低较为缓慢,但当码率低于 2000kb/s 之后视频质量就开始出现比较明显的下降趋势。感兴趣的同学可以在附件中对比观看不同码率的视频的质量,进一步确认效果(附件链接:https://share.weiyun.com/gipQeGlS).
demo 视频在 500-8000kb/s 的码率区间的无参考清晰度打分:
五、总结
本文主要介绍了我们针对细分的主播场景的清晰度算法的开发过程,包含数据集构建、算法细节和算法上线后的一些反馈分析讨论。在未来的工作中,我们会将清晰度算法的应用扩展到更多的如游戏和视频会议等应用场景,欢迎有需求的小伙伴一起合作开发新的算法。
PS:用个人见解来回应导语的问题,视频的清晰度,是以人眼为标杆视频对捕捉场景的还原度,不存在分辨率和码流越高清晰度越高的必然关系,不论是建筑、风光、人像等自然图像,或者屏幕录制、CG 动画、游戏等非自然图像,我们都是以日常观察作为先验知识去感受视频是否清晰,视频的捕获、编码、传输等处理如源场景和人眼之间的一层层玻璃,每个阶段的质量干扰均会降低终端用户感知的清晰度。UGC 用户多变的视频录制场景、随视频会议普及的非自然屏幕内容(Screen Content Coding)以及 5G+云游戏的多样化的游戏场景不仅对视频编码传输等有着更高的要求,也更需要适用性更广的无参考质量评估算法来辅助提升优化视频的用户体验。
头图:Unsplash
作者:张亚彬
来源:腾讯多媒体实验室 - 微信公众号 [ID:TencentAVLab]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




