
十多年前,与当时的大多数 Web 应用程序一样,GitHub 也是一个使用 Ruby on Rails 开发的网站,它的大部分数据都保存在 MySQL 数据库中。
多年来,这个架构经历了多次迭代,以满足 GitHub 的增长和不断变化的弹性需求。例如,我们单独将某些功能的数据保存在独立的 MySQL 数据库中;我们增加了读副本数量,将读负载分摊到多台机器上;我们还使用了 ProxySQL,减少主 MySQL 实例打开的连接数。
但不管怎样,GitHub 仍然只有一个主数据库集群(我们称之为 mysql1),这个集群保存着 GitHub 核心功能所需的大部分数据,比如用户信息、代码仓库、Issues 和拉取请求。
随着 GitHub 的增长,这种架构难免会面临巨大的挑战。我们努力让数据库系统保持合理的大小,并使用更新、更强大的机器。任何一个影响 mysql1 的故障都会影响所有在这个集群保存数据的功能。
2019 年,为了满足增长和可用性方面的需求,我们启动了一个计划,目标是改进我们对关系型数据库进行分库的工具和能力。正如你所想的那样,这是一项复杂而艰巨的任务,需要引入和创建各种各样的工具。
这样做的结果是,在 2021 年,数据库主机的负载降低了 50%。这极大减少了与数据库相关的故障,并提升了 GitHub 网站的可靠性。
虚拟分库
我们引入的第一个概念叫作数据库模式虚拟分库。在进行真正的数据库分表之前,我们要先确保在应用层面能够将表分开,并且不影响团队开发新功能或修改已有的功能。
为此,我们将数据库表按照领域进行分组,并使用 SQL Linter 来分清领域之间的边界。这样我们才能安全地进行数据分库,避免执行跨分库的查询和事务。
模式领域(Schema Domain)
模式领域是我们用来实现虚拟分库的一个工具。模式领域就是指那些经常一起被用在查询(例如表连接和子查询)和事务中的数据库表的集合。例如,模式领域 gists 包含了与 gists、gist_comments 和 starred_gists 这些功能相关的表。因为它们具有相关性,所以应该被分在一起,它们合在一起被称为一个模式领域。
模式领域之间有清晰的边界,并暴露出各个功能之间模糊的依赖关系。在 Rails 应用程序中,这些信息保存在 db/schema-domains.yml 配置文件中,如下所示:
gists: - gist_comments - gists - starred_gistsrepositories: - issues - pull_requests - repositoriesusers: - avatars - gpg_keys - public_keys - usersSQL Linter
我们基于模式领域构建了两个 Linter,用于确保领域之间具有清晰的虚拟边界。我们在查询语句上添加注解,就可以识别出那些跨越多个模式领域的查询和事务,并可以允许一些例外情况。如果一个领域没有违反这个规则,就可以进行虚拟分库,它们的物理表就可以被迁移到另一个数据库集群中。
Query Linter
Query Linter 用于检查只有属于同一个模式领域的表才能被针对同一个数据库的查询引用。如果它检测到查询中包含来自不同领域的表,就会抛出异常。异常中带有有用的信息,可以帮助开发人员解决问题。
因为 Linter 只在开发和测试环境中启用,开发人员可以在开发过程中发现不合规的查询。另外,在 CI 运行期间,Linter 可以确保不会有新的不合规查询被引入。
Linter 还提供了特殊的/* cross-schema-domain-query-exempted */注释,用它来注解 SQL 查询语句可以允许一些例外情况,将上述的异常忽略掉。
我们还给 ActiveRecord 增加了新方法,这样添加注释就更容易了:
Repository.joins(:owner).annotate("cross-schema-domain-query-exempted")# => SELECT * FROM `repositories` INNER JOIN `users` ON `users`.`id` = `repositories.owner_id` /* cross-schema-domain-query-exempted */将所有查询加上注解,就可以得到需要修改的查询语句的清单。以下是我们用来解决例外情况的常用方法。
有时候,我们只需要把表连接查询拆成单独的查询。例如,用 ActiveRecord 的 preload 方法取代 includes 方法。
另一种比较有挑战性的情况是 has_many :through 关系导致需要连接来自不同模式领域的表。对于这种情况,我们提供了通用解决方案:has_many 新增了 disable_joins 选项,告诉 ActiveRecord 不要执行底层表连接操作,改为执行多次查询,并在查询之间传递主键值。
在应用层进行数据连接,而不是在数据库层,这也是一种常见的解决方案。例如,使用两个单独的查询替代 INNER JOIN,然后在 Ruby 中执行“union”操作(例如,A.pluck(:b_id) & B.where(id:...))。
有时候,这样做会带来性能上的极大提升。根据数据结构和数据集势的不同,MySQL 的查询计划器有时会生成性能较差的查询执行计划,而应用层的数据连接可以获得较稳定的性能。
与大多数与稳定性和性能相关的变更一样,这些都用 Scientist 库做过实验。我们对新旧两种实现进行了实验对比,可以客观地评估每一个变更的性能。
Transaction Linter
除了查询语句之外,事务也是我们的一个关注点。现有的应用程序代码都是基于一定的数据库模式。MySQL 事务可以保证同一数据库不同表之间的一致性。如果事务中的查询所涉及的表被移到其他数据库中,那就无法保证一致性。
为了弄清楚需要检查哪些事务,我们引入了 Transaction Linter。与 Query Linter 类似,它可以确保一个事务所涉及的表都属于同一个模式领域。
这个 Linter 运行在生产环境中,进行大量的采样,并将对性能的影响降到最低。结果被收集起来,用于分析哪些地方存在跨领域事务,这样我们就可以决定是否要更新某些代码或修改我们的数据模型。
对于那些对事务一致性要求很高的地方,我们将数据抽取到同属一个模式领域的新表中。这样可以确保它们位于同一个数据库集群中,继续享有事务一致性保证。这种情况多发生在“多态性”表上,这些表的数据来自不同的模式领域(例如,reactions 表保存了来自多个不同功能的数据,如 Issues、拉取请求、讨论等)。
不停机迁移数据
模式领域在经过虚拟分拆之后,就可以进行物理表迁移。为了进行数据迁移,我们采用了两种不同的方法:Vitess 和写切换(Write-Cutover)。
Vitess
Vitess 是一个建立在 MySQL 之上的伸缩层,用于满足数据分片需求。我们用了它的垂直分片特性,在不停机的情况下将一些表迁移到一起。
我们在 Kubernetes 集群上部署了 Vitess 的 VTGate。应用程序连接到这些 VTGate 端点上,而不是直接连接到 MySQL。VTGate 实现了同样的 MySQL 协议,对于应用程序来说与 MySQL 没有什么两样。
VTGate 进程通过 Vitess 的另一个组件 VTTablet 与 MySQL 实例发生交互。Vitess 的数据表迁移特性是通过 VReplication 来实现的,这个组件负责在数据库集群之间复制数据。
写切换
在 2020 年初,Vitess 的采用还处在早期阶段。除此之外,我们还采用了另一种迁移大规模数据表的方法。这样可以降低依赖单一解决方案所带来的风险,确保 GitHub 网站的持续可用性。
我们利用 MySQL 的常规复制特性将数据迁移到另一个集群。在一开始,新集群被加到旧集群的复制树中,然后再用一个脚本快速执行一些变更来实现切换。
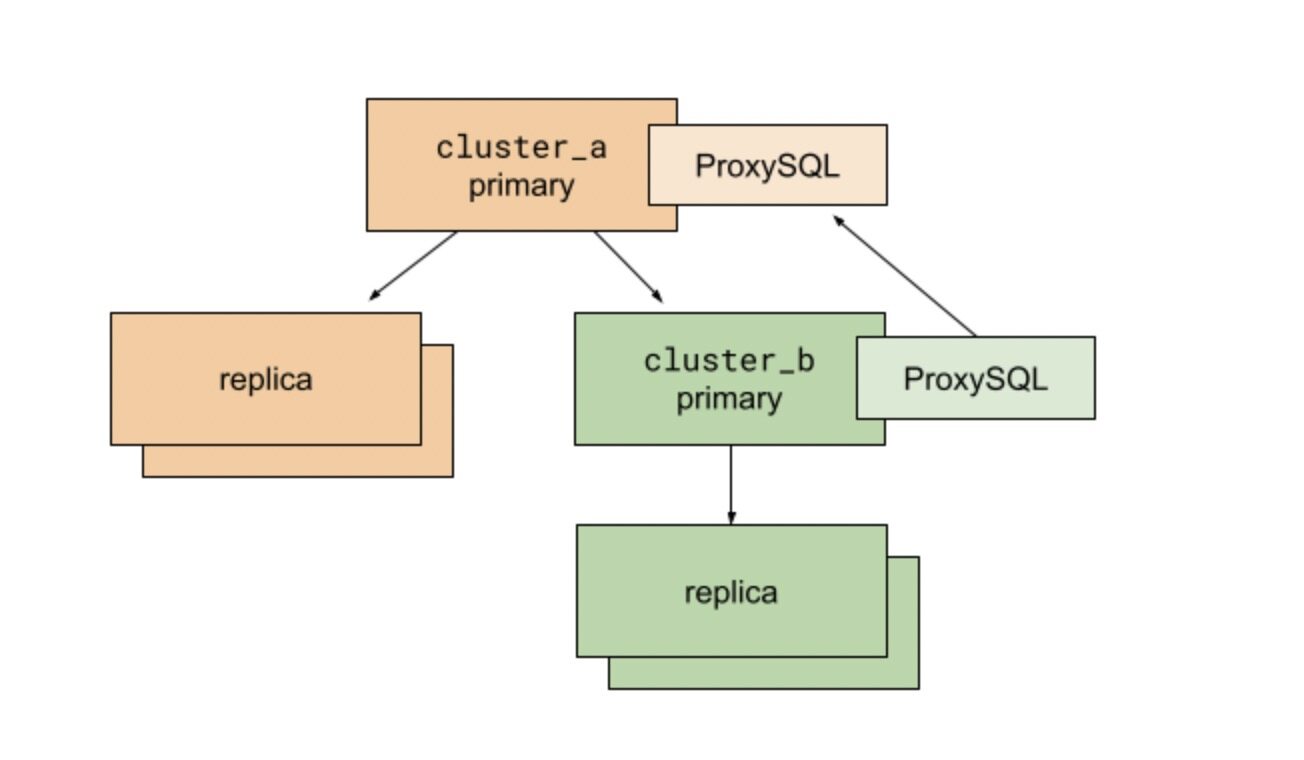
在进行写切换之前的 MySQL 集群
在运行脚本之前,我们先调整应用程序和数据库复制结构,将目标集群 cluster_b 作为现有集群 cluster_a 的子集群。我们用 ProxySQL 实现 MySQL 主实例之间的多路客户端连接。cluster_b 上的 ProxySQL 将流量路由到 cluster_a 的主实例上。有了 ProxySQL,我们可以快速改变数据库的流量路由,将对客户端(也就是我们的 Rails 应用程序)的影响降到最低。
基于这样的结构,我们可以很自然地将数据库连接迁移到 cluster_b。所有的读流量都流向复制了 cluster_a 主实例数据的主机,所有的写流量仍然流向 cluster_a 主实例。
随后,我们开始执行切换脚本:
开启 cluster_a 主实例的只读模式。这个时候,所有向 cluster_a 和 cluster_b 的写入操作都是不允许的。所有尝试向数据库执行写入操作的 Web 请求都会失败,并返回 500 错误。
从 cluster_a 主实例读取最后执行的 MySQL GTID。
轮询 cluster_b 主实例,确认最后执行的 GTID 已达到。
停止从 cluster_a 到 cluster_b 的复制。
更新 cluster_b 的 ProxySQL 配置,将流量重定向到 cluster_b 主实例。
关闭 cluster_a 和 cluster_b 主实例的只读模式。
大功告成!
经过精心的准备和调整,我们发现,即使是我们最繁忙的数据库表,执行完以上 6 个步骤也只需要几十毫秒。由于我们是在一天内流量最不繁忙的时间进行切换,因写入失败而导致的用户可感知错误非常少。这样的结果已经超出了我们的预期。
发现
我们通过写切换来拆分 mysql1——我们最初的数据库主集群。我们一次性迁移了 130 张最繁忙的数据库表,它们为 GitHub 的核心功能提供支撑:代码仓库、Issues 和拉取请求。写切换是我们用来降低迁移风险的一种策略,让我们可以使用多种独立的工具。另外,因为部署拓扑问题和需要提供读己之所写(Read-Your-Write)支持,我们并没有在所有地方都使用 Vitess 作为迁移数据库表的工具,但我们预计在未来会将它作为数据迁移的主要工具。
结果
在文章简介里所提到的 mysql1,也就是我们的数据库主集群,它保存着 GitHub 核心功能的大部分数据,比如用户、代码仓库、Issues 和拉取请求。从 2019 年开始,我们逐渐具备了对这个关系型数据库进行伸缩的能力,并获得了如下结果:
在 2019 年,mysql1 平均每秒处理 95 万个查询,其中 90 万个查询发生在副本上,5 万个发生在主实例上。
现在,也就是在 2021 年,同样是这些表,它们分布在不同的集群中。在两年之内,它们见证了持续的增长,而且一年比一年快。所有这些集群的服务器加在一起,平均每秒处理 120 万个查询,其中 112 万 5 千个查询发生在副本上,7 万 5 千个发生在主实例上。与此同时,每台主机的平均负载减少了一半。
这极大减少了与数据库相关的故障,并提升了 GitHub 网站的可靠性。
更多的分库策略
除了垂直分库,我们也进行水平分库(也就是分片)。我们可以将数据库表拆分到多个集群中,为可持续的增长提供支持。我们将在后续文章中分享更多与之相关的工具、Linter 和 Rails 改进的细节内容。
结论
在过去的十多年,GitHub 学会了如何通过伸缩数据库来满足不断增长的需求。我们通常选择的是“普通”的技术,这些技术被证明很适合我们的规模,因为对于我们来说,可靠性是最为重要的。与此同时,我们也使用一些被业界证明可行的工具,有了这些工具,我们只需要对代码做简单的修改,它们为我们的数据库在未来增长铺平了道路。
原文链接:https://github.blog/2021-09-27-partitioning-githubs-relational-databases-scale/




