

当我们打开滴滴使用网约车服务时,出发前我们往往会关注要走哪条路,这条路要花多长时间,要花多少钱,有多少个红绿灯,路况是否拥堵…这些都与路径规划密切相关。路径规划对滴滴来说十分重要,它是网约车服务的重要一环,与用户体验直接相关,一次糟糕的“绕路”可能会引起一次投诉进线,甚至影响用户留存;而良好的路径规划不仅可以显著提升司乘双方的使用体验,还能让司机少堵在路上,进一步提升整体出行效率。
滴滴路径规划的背景以及业务逻辑的复杂性
类似于语言任务中的 token,物理世界的道路会被建模成一段一段的 link,这些 link 都具有唯一的 id 以及对应的道路属性,比如长度,方向,道路等级等。对于路口来说,进入路口的 link 和出路口的 link 往往都有多个。拿北京举例,北京的路网包含大约 200W 个 link,网约车订单可能会包含数十甚至上百个路口,在如此庞大且复杂的路网中和较为苛刻的时间限制下,规划出高质量的路线绝非易事。
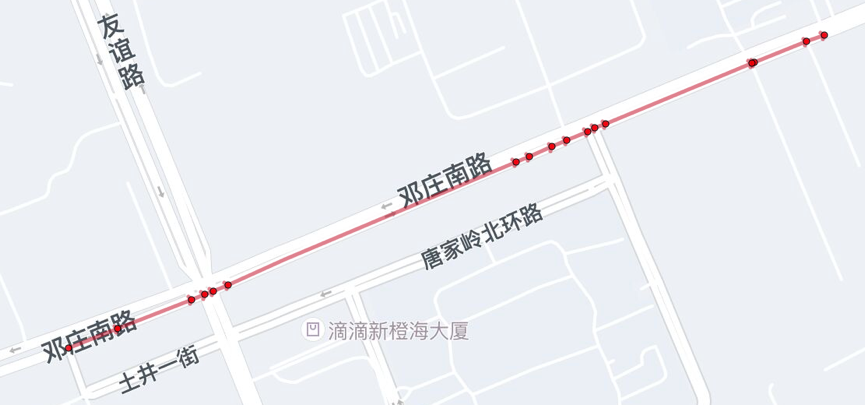
图中每一个带箭头的红色线段表示一个 link,可以看出不同 link 之间的长度差别是比较大的。
此外,我们知道物理世界的道路是会发生改变的,这种改变可能是永久的,比如修路,也可能是临时的,比如交通管制。所以路网数据也是动态的,实际上目前我们地图的路网数据是天级更新的,这也加大了路径规划任务的复杂度。
从实际业务来看,和自驾推荐走更快,更通畅的路线不同,由于网约车会基于里程、时长计费,我们需要同时考虑时间、距离、价格、安全因素,推荐相对快又相对便宜的路线。考虑用户的偏好,让用户在安全、快速到达目的地的同时,让行驶距离尽量短,总花费尽量少,是我们路径规划的核心原则。但很多时候“快”和“近”很难同时满足。距离更短的路往往是次干路或者支路,红绿灯多,堵车可能性更大;而绕远的高速路或者环路,通行能力更强,只要不极拥堵,车速通常更快,反倒用时更短。
有乘客希望更快,也有乘客希望不绕远。为了尽量平衡,从去年 3 月起,我们率先在网约车上线了“选择路线”功能,充分考虑乘客的出行偏好,提供最多三条路线供乘客选择(拼车、一口价订单司机需按照平台指定路线行驶);并联动司机服务部鼓励司机主动询问乘客是否有常走路线。今年 8 月,我们还进一步在北京、杭州、深圳、南京、西安、厦门等 28 个城市试行“行前多路线选择”功能。乘客实时呼叫网约车,发单前可以根据路线标签、预估里程、行驶时长等信息选择最合适的路线,系统自动同步至司机端导航。
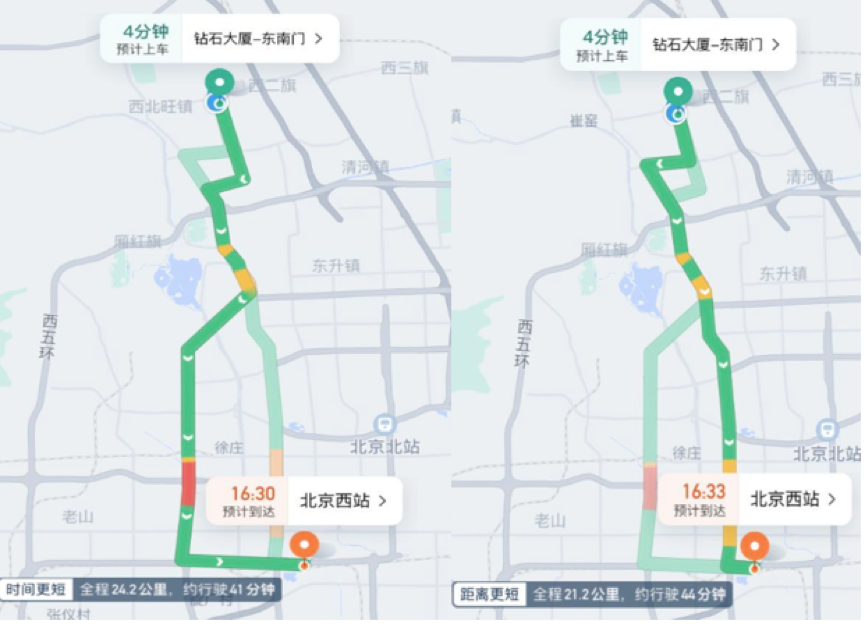
综上,想要做好让司乘双方都满意的路径规划是一件极具挑战的事情,但是这也为我们进一步提高出行服务质量提供了机遇。
路径规划算法和 AI 技术的融合
路径规划是指给定起终点的情况下,规划出一条或多条由起点到终点的路线。传统的路径规划是一个图论问题,当路网中的权值都是静态的时候,使用 dijkstra 等算法就可以求出权值之和最小的路线,比如求出两点之间距离最短的路线是容易的。然而在很多场景需要动态权值,调整权值大小也需要大量经验,目前线上采用的方式是先使用基于图论的算法生成一批低权值的路线,然后再经过基于机器学习算法的排序模型的筛选,这个过程涉及到粗排,精排,rerank,最后将排名靠前的路线透出给用户选择。这个路线规划系统涉及的链路还是比较长的,不同于基于图论算法生成高权值的路线,我们尝试探索一种基于 AI 算法的路线生成方式。
得益于滴滴海量的出行数据尤其是高质量的轨迹数据,我们可以利用深度学习技术去挖掘和学习司机的驾驶行为以及用户对路线的偏好,借助训练出的深度模型在短时间内为用户规划出满意的路线,降低线上的偏航率。
我们这里可以把寻路的过程和 AlphaGo 下围棋的场景进行类比,司机在路网中行驶犹如棋手在棋盘上落子,初级棋手往往通过记忆棋谱来获取暂时的领先,而最终赢棋往往要求棋手有“大局观”,每一步的落子考虑到之后棋局的演变,关键在于最终赢棋,而不在于一时的得失。寻路过程也是需要往后多看几步的,因为在某个路口的选择眼前可能看是最优的,放在全局看则不一定是最好的选择。我们探索路线生成的过程是和 AlphaGo“进化”过程是相似的,是一个从监督学习到强化学习的过程。
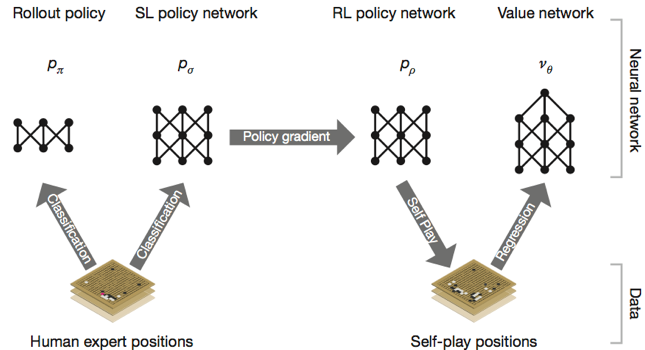
规划最符合司乘习惯的路线:从监督学习到强化学习
一.“克隆”高质量的历史轨迹
我们最先想到的是使用行为克隆(behavior clone)的方式解决寻路问题,这里可以将寻路看作一个连续决策的过程,把用户的历史真实轨迹当做专家轨迹,在每个路口(对应一个状态)用户作出的选择看作是一个近似最优的动作(action),接下来我们就可以在每个决策点做分类,专家行为作为正样本,非专家行为作为负样本,让分类模型去判断某个决策是否符合用户习惯,分类器会输出对一个状态和动作对输出一个概率值,这个概率越大代表用户越有可能在该状态采取对应的动作。这点与 AlphaGo 中的走子网络是类似的:通过专业棋手的棋谱数据来训练模型,让它学习专业棋手的下棋行为。
在实际处理中,因为路线是被建模成连续的 link 序列,所以我们在网络结构中引入了在序列预测上表现强大的 lstm,用 lstm 可以更好地建模用户从起点到当前位置的状态信息,在经过百万量级条轨迹训练后,我们的模型在每个路口的决策准确率达到了 98%+,我们将这个能够在每个路口输出决策概率的模型称作寻路 agent,它已经基本可以模拟用户的真实选择。
如果在每一次决策都选择概率最大的那一个 link(即贪心搜索)往往只能找到局部最优解,比如一条路前半段看起来更优,但是后半段可能不是最佳的。为了尽可能找到最符合用户习惯(即整条路线的概率最大),我们使用了 beam search 搜索策略,其主要思想就是在寻路过程中维护若干个(即 beam size)最优的候选集,这种方式相比穷举法大大缩减了需要探索的空间,相比于贪心搜索考虑的情况更多,往往能够找到得分更高的路线,在自然语言处理领域,比如机器翻译任务中被大量使用。可以通过下面简单的例子理解 beam search 的过程。
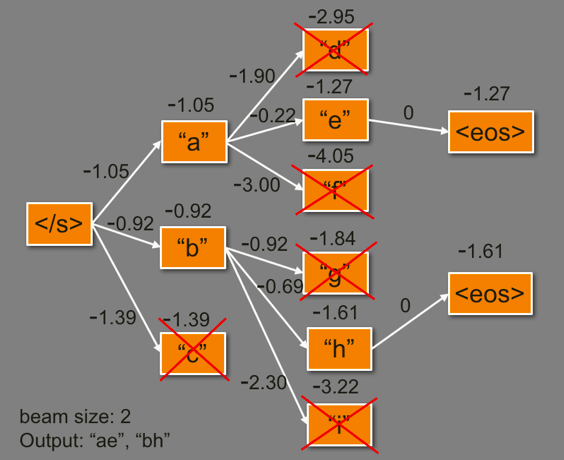
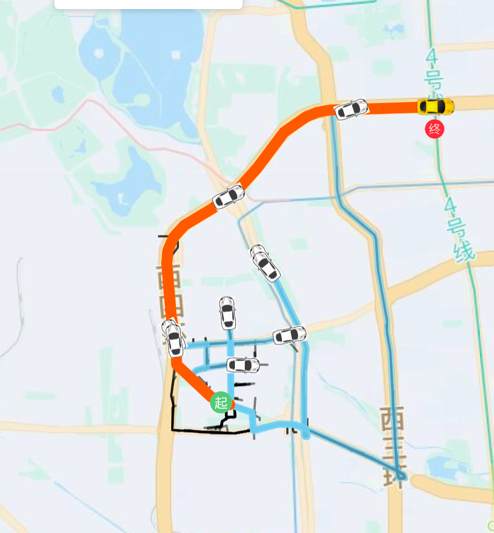
图中移动的小车展示了 beam search 在路径规划中的应用,在小车前进的过程中,我们可以给不同的路线打分,维护得分最高的 topK 路线,直到小车抵达终点。红色的路线表示最终得分最高的路线,也是最符合用户习惯的路线。
二.行为克隆的问题
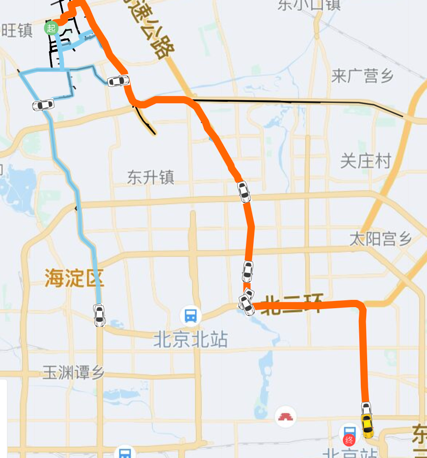
行为克隆实际上属于监督学习的范畴,在 AlphaGo 中如果让 agent 纯粹的去学习棋谱中的走法,它很难打败更加专业的棋手,所以 AlphaGo 引入了强化学习并搭配 MCTS 这一搜索策略,从而大大提升了对弈的胜率。同样的,纯粹的拟合专家轨迹是存在问题的:当寻路 agent 在某个路口判断错误,那么就会进入到没有遇到过的状态,在这种状态下 agent 的判断容易出错,而错误的累积会容易导致寻路过程演变成“一步错步步错”的结果。虽然我们的模型具有一定的泛化能力,寻路 agent 也可以找到终点,但由于我们没有显示的引入偏航后的监督信号,寻路 agent 往往需要更多不必要的“绕路”才能回到理想的路线上来。图中蓝色轨迹是小车偏航后所致,小车既有可能回到 demo 轨迹(红色路线)上来,也有可能越来越远,偏离 demo 轨迹,因为模型并没有学习到发生偏航后该如何快速纠正。
三.强化学习的应用
强化学习是近年来解决行为克隆带来的问题的热门方向。在文本生成领域,seqGAN 通过判别器(简称 D)来指导生成器(简称 G)的训练,在 G 生成下一个单词时,使用 MCTS 和 D 来评估这个单词的好坏,通过 reward 作为反馈,使用 Policy Gradient 来更新 G 的参数,从而增加 reward 大的单词的生成概率。与此方法类似的还有在游戏系列数据集上表现优秀的 GAIL,AIRL,这些方法的主要思想是另外训练一个能够指导生成网络更新的评估网络,缺点在于略显复杂,训练难度和计算量较大。
AlphaGoZero 通过“自己与自己对弈”的过程大大增强了棋力,类似的,我们想要通过生成学习的方式来增强路线引擎的能力。这里我们采用 Q-learning 的方式来学习一个寻路策略,为了加速模型收敛的速度,我们这里先使用前文提到的行为克隆的方式训练一个能够容易走到目的地的基础模型,然后使用该基础模型在路网上寻路,生成大量的采样轨迹,如果在某个状态,模型采取的动作与用户一致,则给该状态-动作对以+1 的 reward,相反如果在该状态模型采取的动作与用户不一致,则给该状态-动作对的 reawrd 为 0。这种人为设定 reward 的方式既没有引入对抗学习的过程,也不要额外学一个 reward 函数,计算量大幅度减小,同时它可以有效克服行为克隆带来的状态分布偏移的问题。
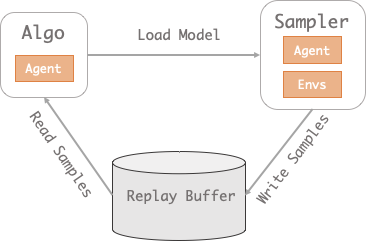
图中大致展示了我们的训练流程,通过老模型的 self-play 获取新的轨迹数据,将采样得到的新轨迹和真实轨迹融合训练,更新我们的策略模型,该过程是可以不断迭代的。经过多轮迭代后,路线生成模型的分类准确率虽然没有明显提升,但是生成轨迹质量更高:与真实轨轨迹的重合率明显提高,偏航后返回到 demo 轨迹的速度更快。这是让人惊喜的结果。
总结
滴滴的路线引擎每天需要处理超过 400 亿次的路线规划请求,我们致力于为平台用户提供安全,快捷的路线服务。本文介绍的路线生成方式是深度强化学习在路径规划业务上落地的一次探索,主要用来降低偏航率。考虑到路径规划业务的复杂性,我们会从更多的方向(比如躲避拥堵)来打磨我们的路线引擎,让它变得更加智能。
当然目前路线引擎还有它不完善的地方,还需要持续的迭代和优化,也欢迎大家给我们提供宝贵的意见。我们团队将会持续优化路线引擎系统的性能,迭代路线规划的算法,为司机和乘客创造更大的用户价值。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论