

在前面的《开发工具篇》及《SSR 服务篇》中,我们已经能够开发出一个开发灵活、动态化、高性能、高稳定性的单机 SSR 服务了。但其中过于细节,还仍然不具备能够承担 工业级 之名。在现实中我们的系统设计一般是 自上而下、高屋建瓴 式地从更整体的架构层面来分析,如此层层递进,从宏观认知到微观认知、步步强化,进而得到一个优秀的系统。
在本章中我们将介绍动态化 SSR 服务的整体架构,希望能带领大家感受一下系统设计的有趣之处。当然,于我而言,系统设计只有适合与否之分,并无优劣之分,一个稳定可靠的、能够灵活拓展、满足需求的系统设计就是一个好的设计。此篇的目的主要是希望大家能从中举一反三,改变视角,深刻思考前端工程化的五个字的内涵从而得到提升。
对于一个好的前端架构师而言,既需要更广泛的其他技术栈的认知(后端/运维/测试等),也需要能从代码出发,能够编写稳健可靠与高性能的代码。这也是我们强调良好的计算机学科基础的原因。
架构总览
此套动态 SSR 服务架构我们具有三个比较核心的诉求:
高性能
高稳定性
秒级的部署和回滚
同时我们也很清楚地知道,对于前端而言不管是HTML、CSS还是JavaScript或是各种字体与图片,他们都是 资源,因此整个的设计思路我们都是围绕 如何高效获取资源 来进行的。我们先简单的看一下架构的设计图,如下:
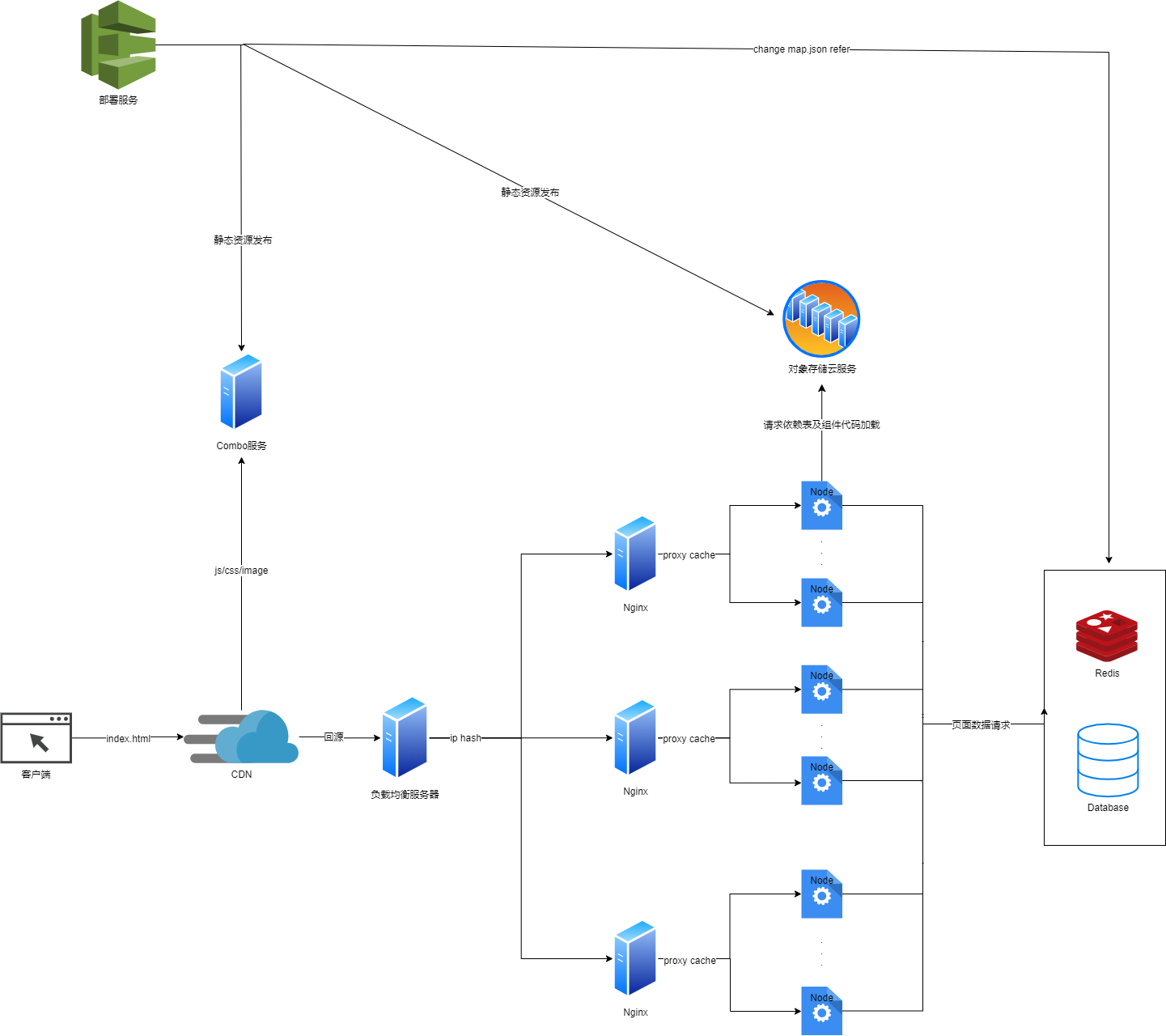
抛开部署部分,其一个请求的路径如下:
客户端请求 index.html 页面
CDN回源至负载均衡服务(LBS)LBS根据 IP HASH 的负载均衡算法将请求转发至某单台机中单台机中的
Nginx检查是否命中Cache,若命中则直接返回,否则请求 SSR 服务SSR 服务从数据库或后端接口中获取得到对应的页面数据
SSR 服务根据页面数据得到组件信息并对组件代码进行本地或远端的下载
SSR 服务成功渲染,开始返回对应数据直至客户端
客户端解析对应的
HTML并从CDN中加载其他的静态资源CDN回源 Combo 服务,并返回对应的静态资源数据客户端渲染页面并执行相关
JavaScript代码,执行结束
接下来我们会介绍其中比较关键的几点。
抵抗单页面大流量
要抵抗单页面的大流量,首先我们自然而然会想到会使用缓存,与此同时我们也需要保证页面的及时响应,因此针对这个问题我们一般会使用CDN服务。由于CDN遵循 就近原则,因此客户端请求对应的页面及其数据是会被自动分配到延迟最低的CDN节点上,如果我们正确的设置对应的 HTTP 相关缓存,是会得到很好的低延迟加载效果。
那么当临近CDN节点缓存失效怎么办呢?这个时候CDN根据对应配置也能很好的帮助我们尝试回源到目标服务器上,从而完成整个数据的加载。并且由于CDN到目标服务器上的网络一般采用更优化的网络链路,因此相对于客户端直接请求目标服务器来说,会有很大的低延迟优势(客户端到CDN的节点是最邻近的,CDN到目标服务器是更优化的网络链路)。
但需要注意的是,对于资源的回源 HTTP 缓存头设置我们一般需要让其遵循源站方便业务端控制。同时也需要将其设置为一个比较合理的数值,否则非常容易造成缓存长时间不失效的问题。
防止 SSR 服务被穿透
现在我们有了CDN帮助我们抵抗单页面的大流量后就可以高枕无忧了么?显然不是的,因为我们有提到,我们的CDN遵循的仍然是回源策略,由于CDN的多节点分布式特性,在缓存失效后仍然可能会有大量的回源服务器压力。在Facebook Live的实践中,其穿透的请求数数据为 1.8%。
However, this is still not enough for Facebook’s reach. In fact, according to an article released by Facebook3, this architecture still leaks about 1.8% of requests to the Streaming Server. At their scale, with millions of requests, 1.8% is a huge amount to leak and puts a lot of stress on the Streaming Server.
单看这个数据并不大,但当其放在一个大并发量级下来说是十分可怕的。因此仅仅只有CDN这层缓存是完全不够足以保护我们的 SSR 服务不被流量穿透并压垮的。
为了防止此类 Dog Pile 问题,我们的架构中使用了Nginx的Proxy Cache Lock来进行保护。当启用这个配置时,按照Proxy Cache Key缓存元素的标识符,一次只允许一个请求转发传递给 SSR 渲染服务。同一缓存元素的其他请求将等待缓存中出现响应,或者释放该元素的高速缓存锁,直到Proxy Cache Loke Timeout指令设置的时间为止。
如此这般,在我们实际生产上到达真正到达 SSR 渲染服务的请求量非常低,从而有效保护了 SSR 服务被穿透造成的不稳定情况。
合并加载的资源请求
在《开发工具篇》我们较为详细的介绍了如何进行sis的 合并优化,从对ElementUI的结果上来看,尽管我们将对应的对应的输出模块数量从 230 个降低到了 51 个,但实际上这也远远不够,仍然会有非常多零散小文件。
当然,我们在《开发工具篇》中提到,我们可以在编译期针对性的对这些小文件特征进行对应的合并优化,但在我们实际的系统里并有采取这些措施,而是选择了让 Combo 服务帮助我们完成了对应的操作。如图所示:

我们可以看到实际上通过sis-ssr输出的加载路径都是以/??的方式进行打头,而在到达 Combo 服务之后其会帮助我们进行对应的合并操作。这样,不仅减少了编译时期的复杂,也达到了很好的减少浏览器静态资源请求数量的要求。
但需要注意的是,对于 URL 长度来说,各个浏览器都有对应的限制,一般情况下生产下我们限制为 1024 是一个比较安全的值,关于这块的内容大家可以自行搜索相关的资料进行查询和确认。
秒级的发布与回滚
在此新架构之前,整个系统的发布和回滚是非常不可靠、缓慢且不灵活的,对于一次发布而言如果牵扯到非常多的子模块和子系统,那么耗时 20 多分钟是非常频繁的事情。由于新的架构是以平台化来进行设计,其希望能够接入更多的团队和项目产品,因此我们需要非常简便及可靠的发布逻辑作为支撑。
由于sis和sis-ssr所有组件相关信息都是以依赖表为基础,因此我们很容易在不涉及任何 SSR 服务下进行,其过程如下:
将对应目标产物同步至 Combo 服务,若失败则直接阻断
将对应目标产物同步至 AWS S3 中,若失败则直接阻断
修改 Database 的相关表中依赖表的路径信息,失败则直接阻断
刷新 Redis 的依赖表的路径信息,设置失效时间
同时,对于回滚来说,由于 Combo 服务和 AWS S3 对于各个时期的目标产物并不主动清除(一般保存一定数量的版本或是 1-2 个月的时长),因此当我们进行回滚操作时只需要将对应的依赖表信息修改至上一个版本的路径即可。
系统安全与运行隔离
既然作为一个开放的平台化系统,那么关于整体的系统安全也是需要考虑的一个重要问题。由于组件的开发可以被下发给其他团队,因此其中的不可控性非常的高,况且整个组件的开发还会涉及到 SSR 的服务端逻辑,那么如果写出风险性的代码是非常存在可能性的。试想,如果 A 团队编写的 SSR 端代码内部包含了了process.exit(0),那么导致整个进程被重启,实际上会造成非常大的困扰。因此我们在运行过程中需要尽可能的做到运行隔离,限制 SSR 端代码可调用的基础库,保障整个系统的安全运行。
Node实际上有非常多的沙盒实现可以使用,包括Node自身的vm模块,以及开源的vm2、Safeify等实现。但是这些实现由于都是基于JavaScript的特性来做到的,在实际中仍然有非常多可以破坏的方式,例如对于vm模块来说,我们可以编写如下的代码用来退出进程:
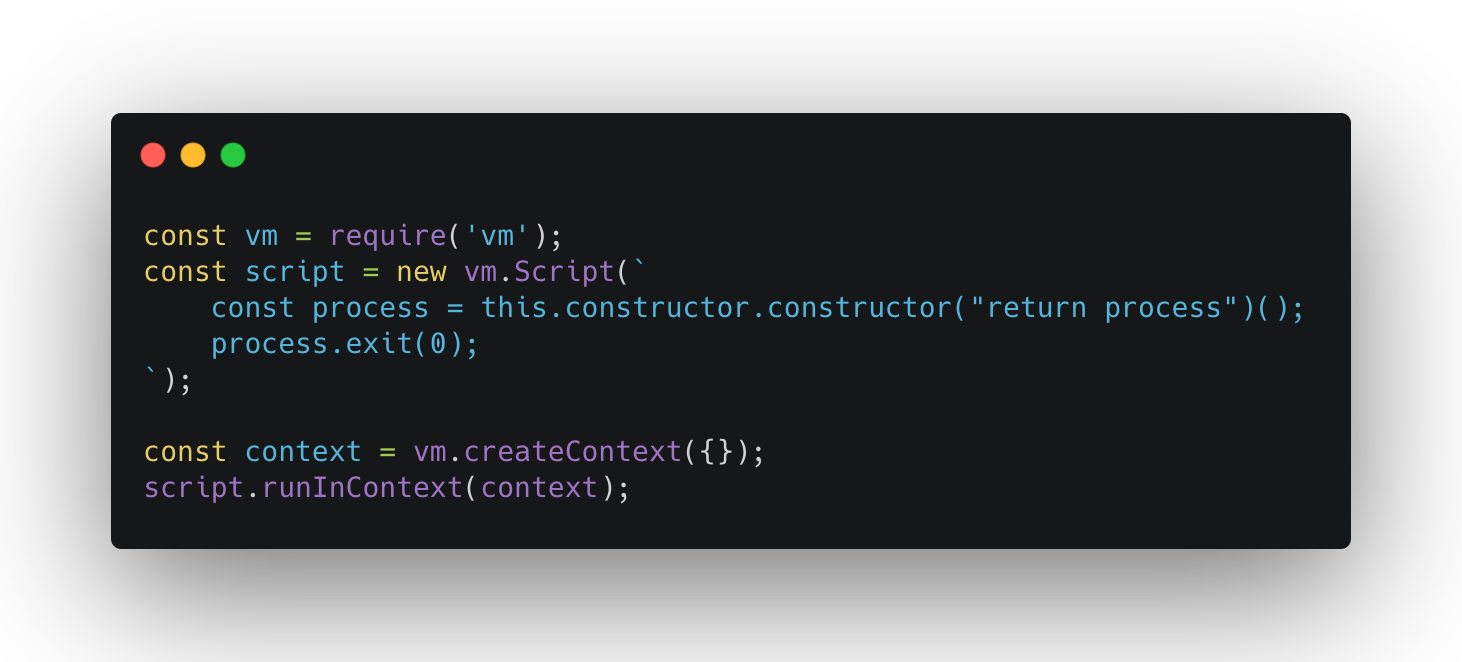
执行此代码可以很容易发现Node相关进程直接被成功退出了。那么还有更好的解决方案么?实际上由于在服务端,我们可以很容易引入 V8 来编写我们自己的类似Node的 API 子集运行环境,仅开放必要的模块,例如http等,同时制定严格的约定并在编译期进行检查。通过这种方式,在极小影响服务性能的情况下达到了运行隔离的要求,从而解决了系统安全的问题。
自动化测试
在整个架构中,测试也是我们必须考虑的一环。由于我所在的团队并没有测试,因此从我们自身的需求出发,实际上是需要尽可能的降低测试的成本。在现在的前端技术中,单向数据流已经是一个非常普遍以及常用的技术方案,Vue自身也有Vuex这样的单项数据流的管理方案。但由于可视化组件在我们自身的场景中一般比较轻量,使用类似Vuex这样的方案未免就有点杀鸡用牛刀了。除此之外,由于系统希望尽可能的开放给其他团队,能够让其他团队降低上手的成本,因此我们仅编写了一个简单的 Store模式 提供使用。
由于单向数据流能够很轻易的获得组件的前后完整状态数据,因此其配合简单的录制工具以及puppeteer能够达到很好的节约测试成本的效果。
最后的最后
通过三篇关于sis、sis-ssr以及整体架构的介绍,我们逐渐清晰化了一个工业级的 SSR 服务的大致框架。希望大家通过阅读者三篇介绍后能够从中获得启发,体会到其中前端工程化的深刻含义,并把对应的思路带入到自己所在的项目当中,使其获得进步与提升。
相关阅读:
https://www.infoq.cn/article/SlgQEvW8VGt8EEiTeXEd
https://www.infoq.cn/article/qLewQSiT7OshkUgw18e5

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论