

如今,将深度学习应用于大数据管道往往需要手工“拼接”许多独立的组件(如 TensorFlow、Apache Spark、Apache HDFS 等),这个过程可能非常复杂,而且容易出错。
Analytics Zoo提供了一个在 Apache Spark 上实现分布式 TensorFlow、Keras 和 BigDL 管道的统一分析和 AI 平台,简化了这个过程。
它将 Spark、TensorFlow、Keras 和 BigDL 程序无缝地合并到一个集成管道中,可以透明地扩展到大型 Apache Hadoop/Spark 集群,用于分布式训练或推理。
早期用户(如世界银行、Cray、Talroo、Baosight、美的/库卡等)已经基于 Analytics Zoo 构建了分析+AI 应用程序,它可以应用于范围广泛的工作负载(包括基于迁移学习的图像分类、用于短时降水预测的 sequence-to-sequence 预测、用于推荐工作的神经协同过滤、无监督时序异常检测等等)。
本文提供了几个具体的教程,介绍如何使用 Analytics Zoo 在 Apache Spark 上实现分布式 TensorFlow 管道,以及在实际的用例中使用 Analytics Zoo 实现端到端的文本分类管道。
人工智能应用程序的不断进步将深度学习带到新一代数据分析开发的前沿。特别是,我们看到越来越多的组织需要将深度学习技术(如计算机视觉、自然语言处理、生成对抗神经网络等)应用到他们的大数据平台和管道。如今,这常常需要手工“拼接”许多独立的组件(例如 Apache Spark、TensorFlow、Caffe、Apache Hadoop 分布式文件系统 HDFS、Apache Storm/Kafka 等),这可能是一个复杂且容易出错的过程。
在英特尔,我们一直与开源社区用户以及京东、UCSF、Mastercard等合作伙伴和客户广泛合作,在 Apache Spark 上构建深度学习(DL)和 AI 应用程序。为了简化端到端的开发和部署,我们开发了Analytics Zoo,这是一个统一的分析+ AI 平台,它将 Spark、TensorFlow、Keras 和 BigDL 程序无缝地合并到一个集成管道中,可以透明地扩展到大型 Apache Hadoop/Spark 集群,用于分布式训练或推理。
早期用户(如世界银行、Cray、Talroo、Baosight、美的/库卡等)已经基于 Analytics Zoo 构建了分析+AI 应用程序,它可以应用于范围广泛的工作负载,其中包括基于迁移学习的图像分类、用于短时降水预测的 sequence-to-sequence 预测、用于推荐工作的神经协同过滤、无监督时序异常检测等等。
本文提供了几个具体的教程,介绍如何使用 Analytics Zoo 在 Apache Spark 上实现分布式 TensorFlow 管道,以及在实际的用例中使用 Analytics Zoo 实现端到端的文本分类管道。
Apache Spark 上的分布式 TensorFlow
使用 Analytics Zoo,用户可以方便地使用 Spark 和 TensorFlow 在大型集群上构建端到端的深度学习管道,如下所述。
使用 PySpark 进行数据预处理和分析
举例来说,要使用分布式的方式处理对象检测管道的训练数据,可以使用 PySpark 简单地把原始图像数据读入一个 RDD(弹性分布式数据集),这是一个跨集群分区的不可变记录集合,然后运用一些转换解码图像,并提取边界框和类标签,如下所示。
结果 RDD (train_rdd)中的每条记录都包含一个 NumPy ndrray 列表(即图像、边界框、类和检测到的框的数量),然后可以直接在 Analytics Zoo 上用于 TensorFlow 模型的分布式训练;这是通过从结果 RDD 创建TFDataset来完成的(如下所示)。
使用 TensorFlow 开发深度学习模型
在 Analytics Zoo 中,TFDataset 表示一个分布式元素集,其中每个元素包含一个或多个 Tensorflow Tensor 对象。然后,我们可以直接使用这些 Tensor(作为输入)来构建 Tensorflow 模型;例如,我们可以使用 Tensorflow Object Detection API 构建一个 SSDLite+MobileNet V2 模型(如下所示)。
在 Spark 和 BigDL 上进行分布式训练/推理
在构造好模型之后,我们可以直接在 Spark 上(利用 BigDL 框架)以分布式的方式训练模型。例如,在下面的代码片段中,我们应用迁移学习技术来训练一个在 MS COCO 数据集上预训练过的 Tensoflow 模型。
在后台,从磁盘读取输入数据并进行预处理,利用 PySpark 生成 Tensorflow Tensor 的 RDD;然后,在 BigDL 和 Spark(如BigDL技术报告所述)上以分布式的方式对 Tensorflow 模型进行训练。整个训练管道可以自动从单个节点扩展到基于 Xeon 的大规模 Hadoop/Spark 集群(无需修改代码或手动配置)。
另外,模型训练好以后,我们可以使用 PySpark、TensorFlow 和 BigDL(类似于上面的训练管道)在 Analytics Zoo 上执行大规模的分布式评估/推断。或者,我们也可以使用 Analytics Zoo 提供的 POJO 风格的服务API来部署低延迟的在线服务(例如,Web 服务、Apache Storm、Apache Flink 等)模型,如下所示。
下图显示了 Analytics Zoo 中 Apache Spark 管道上的分布式 TensorFlow 的整个工作流(包括训练、评估/推断和在线服务)。
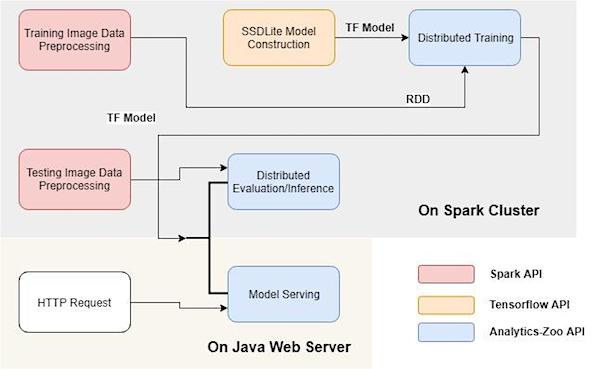
端到端分析和 AI 管道
Analytics Zoo 还为用户提供了丰富的端到端管道分析和 AI 支持,包括:
易于使用的抽象,如 Spark Dataframe 和 ML 管道支持、迁移学习支持、Keras 风格的 API、POJO 风格的模型服务 API 等等;
面向图象、文本和 3D 图象的常见特征工程操作*;*
内置的深度学习模型,如文本分类、推荐、对象检测、图象分类等;
参考用例,如时间序列异常检测、欺诈检测、图像相似性搜索等。
使用这些高级管道支持,用户可以在几行代码中轻松构建复杂的数据分析和深度学习应用程序,如下所述。
使用 NNImageReader 将图象加载到 Spark DataFrames 中
使用 DataFrames 转换处理加载的数据
使用内置的特征工程操作处理图像
使用迁移学习 API 加载已有的 Caffe 模型,删除最后几层,冻结开始几层,追加几个新层(使用 Keras 风格的 API)
使用 Spark ML 管道训练模型
基于 Analytics Zoo 的真实 AI 案例
如上所述,有许多早期用户已经在 Analytics Zoo 上构建了真实的应用程序。在本节中,我们将更详细地描述如何在Microsoft Azure的 Analytics Zoo 上使用 NLP 技术构建端到端的文本分类管道。
文本分类概述
文本分类是一种常见的自然语言处理任务,其目的是将输入文本语料库分类为一个或多个类别。例如,垃圾邮件检测将电子邮件的内容分为垃圾邮件或非垃圾邮件类别。
一般来说,文本分类模型的训练包括以下步骤:收集和准备训练数据集及验证数据集、数据清理和预处理、训练模型、验证和评估模型、优化模型(包括但不限于添加数据、调整超参数、调整模型)。
Analytics Zoo 中有几个预定义的文本分类器可以开箱即用,即 CNN、LSTM、GRU。我们选择从 CNN 开始。我们在下面的文本中使用 Python API 来说明训练过程。
在上面的 API 中,class_num 是这个问题中的类别数量,embedding_fileis 是预训练词向量文件的路径(目前只支持 Glove ),sequence_length 是每个文本记录中包含的单词数,encoder 是词编码器的类型(可以是 CNN、LSTM 或 GRU),encoder_output_dim 是这个编码器的输出。该模型接收词索引序列作为输入,输出标签。
数据收集和预处理
训练数据集中的每个记录包含两个字段,一个是 dialogue 和一个是 label。我们收集了数千条这样的记录,并通过手动和半自动的方式收集标签。然后,我们对原始文本进行数据清理,去掉无意义的标记和混淆的部分,并将它们转换为文本 RDD,每个记录的格式为一个(文本、标签)对。接下来,我们对文本 RDD 进行预处理,并输出我们的模型可以接收的正确形式。请确保你的数据清洗和处理对训练和预测都是一样的!
上面是数据清理只有的文本 RDD 示例(每条记录是一个文本-标签对)。
1.数据读取
我们可以使用 Analytics Zoo 提供的 TextSet 以分布式方式读取文本数据,如下所示。
2.分词
然后我们将句子分解为单词,将每个输入文本转换为一个标记(单词)数组,并对标记进行规范化(例如,删除未知字符并转换为小写)。
3.序列对齐
不同的文本可能会生成不同大小的标记数组。但是,文本分类模型要求输入的所有记录大小固定。因此,我们必须将标记数组对齐到相同的大小(在 parametersequence_lengthin 文本分类器中指定)。如果标记数组的大小大于所需的大小,则从开头或结尾对单词进行删除;否则,我们将无意义的单词填充到数组的末尾(例如“##”)。
4.词索引
标记数组大小对齐后,需要将每个标记(单词)转换为索引,可用来查找其词向量(在文本分类器模型中)。在单词转换为索引的过程中,我们还通过删除文本中出现频率最高 N 个单词来移除停用词(即经常出现在文本中但无助于语义理解的单词,如“the”、“of”等)。
5.转换成样本
经过以上步骤,每个文本都变成一个有形状的张量(sequence_length, 1),然后我们从每个记录构造一个 BigDL样本,以生成的张量作为特征,以标签整数作为标签。
模型训练、测试、评估和优化
在以相同的方式准备好训练数据集(train_rdd)和验证数据集(val_rdd)之后,我们实例化一个新的 TextClassifier 模型(text_classifier),然后创建一个优化器以分布式方式训练模型。我们使用稀疏分类交叉熵(Sparse Categorical Cross Entropy)作为损失函数。
训练时可调整的参数包括轮数、批大小、学习率等。你可以指定输出指标的验证选项,如在训练过程中设置准确度验证,以检测过拟合或欠拟合。
如果在验证数据集上获得的结果不好,我们就必须优化模型。通常,这是指重复调整超参数/数据/模型、训练和验证的过程,直到结果足够好为止。通过调整学习速率、添加新数据和扩充停用词字典,我们的准确率得到了显著提高。
有关 Analytics Zoo 中的文本处理和分类支持的更多细节,请参阅这些文档。
作者简介:Jason Dai 是英特尔大数据技术高级首席工程师兼首席技术官,负责领导全球工程团队(包括硅谷和上海)开发先进的大数据分析和机器学习技术。他是 Apache Spark 的提交者、PMC 成员、Apache MXNet 导师、Strata Data Conference 北京站的联合主席以及 BigDL(Apache Spark 的分布式深度学习框架)的创建者。
查看英文原文:Analytics Zoo: Unified Analytics + AI Platform for Distributed Tensorflow, and BigDL on Apache Spark

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论