

导读: 下一代人工智能计算模型,主要是使用一些自动化技术帮助我们设计更好的深度学习网络结构,并在任务中提升性能。在深度学习如火如荼的当下,如何设计高效的神经网络架构,是研究者面临的重大挑战。本文将从网络架构搜索——这一当下火热的话题切入,探讨其中一类利用权重共享加速搜索的方法,并且分析这类方法存在的问题,给出自己的解决方案。
本次分享的具体内容有:
从 AI 的三大挑战,引出自动化机器学习和网络架构搜索的重要性
网络架构搜索的通用框架
权重共享的网络架构搜索算法以及面临的挑战
我们在网络架构搜索方面的工作
总结和未来展望
01 从 AI 的三大挑战,引出自动化机器学习和网络架构搜索的重要性
1. AI 领域未来面临的挑战
AI 领域未来面临的挑战,有 3 件事是确定的:数据 ( data ),模型 ( model ),知识 ( knowledge )。

① 数据
Data-efficiency:如何利用有限或多模态数据训练模型?
在如今的数据爆炸时代,会产生海量的数据,其中只有很少的数据有数据标注,大量的数据没有数据标注,且数据很"脏"。于是引出了第一个问题:如何从海量数据中,真正学习到自己想要的东西。
AI 未来的发展方向是从全监督发展成自监督和无监督的方向。
② 模型
Auto-learning:如何为人工智能应用设计强大高效的模型?
这一代的计算模型主要是基于深度学习的,尤其是卷积神经网络。深度学习在图像识别领域的应用,使得原先的模型从手工识别特征发展到自动学习特征。
基于这种发展的趋势,我们将模型继续推进一步,使得深度学习的网络设计也从手动转为自动。这是模型部分所面临的挑战。
③ 知识
Knowledge-aware:如何定义和存储知识,使训练后的模型安全可靠?
现有模型的算法,大部分都是拟合和训练数据,并不能保证拟合得到的结果具备分析常识的能力,即"不能真正地学习知识"。由于计算机缺乏常识,对知识的学习,可能会成为 AI 未来 5 年的研究方向。
2. AutoML
本文的重点是模型部分,主要分析手动和自动两种思路的区别。
2017 年自动化网格搜索架构被提出后,"手动更好"还是"自动更好"这类争论不断。在争论的过程中逐渐催生出了一个新的方向,称为自动化机器学习 ( AutoML )。这一方向在工业界得到了更多的关注度。
工业界的关注度超过学术结,主要有两个原因:
① 工业界的算力更强。
AutoML 算法对计算资源的消耗非常大。例如,Google 发表的 NAS 方面的论文,每天需要上万个 GPU 才能完成计算。
② 工业界有很强的需求。
AutoML 可以帮工业界节省很多的开发成本。以华为为例,华为有各种各样不同的手机产品,从旗舰机到低端的手机,芯片的计算能力会差很多。用户会需要在不同的手机中完成相似的功能 ( 如拍视频 ),因此针对不同的芯片需要设计不同的网络架构以满足用户的需求;另一方面,用户的需求 ( 如清晰度的要求 ) 是实时变化的,如果使用人工机器学习算法,会带来巨大的人力投入。基于此,工业界存在自动化算法的需求。
3. NAS
① 简介
NAS,是 AutoML 的一个子课题,核心是:使用自动设计的网络架构,来替代手工设计的网络架构,使用自动算法探索 ( unexplored architectures )。
在 2015 年前,所有的神经网络架构几乎都是手工设计的。如下图,是一个典型的神经网络架构——ResNet
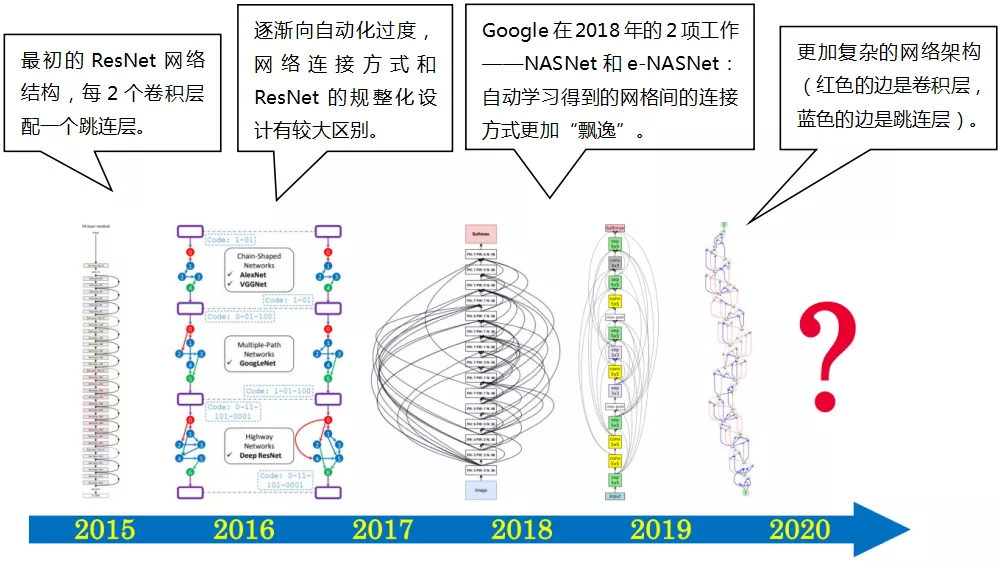
② NAS 对业界的影响
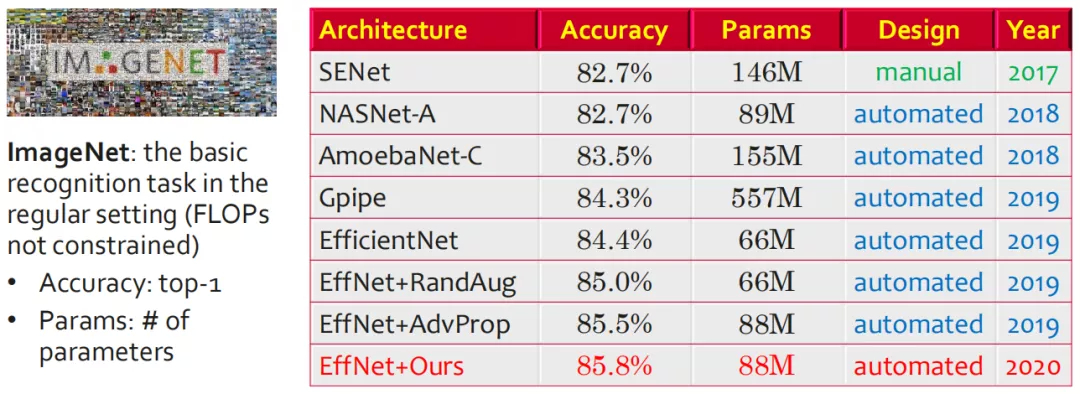
对于 ImageNet 这类标准的视觉任务,从 2018 年开始,最佳的算法属于 NAS 这类自动搜索出来的网络架构。2018 年-2019 年,最佳算法是 Google 开发出来的;2020 年,华为在 Google 的 EfficientNet 的基础上增加了一些自研算法,其准确率超过了 Google 自有的性能。
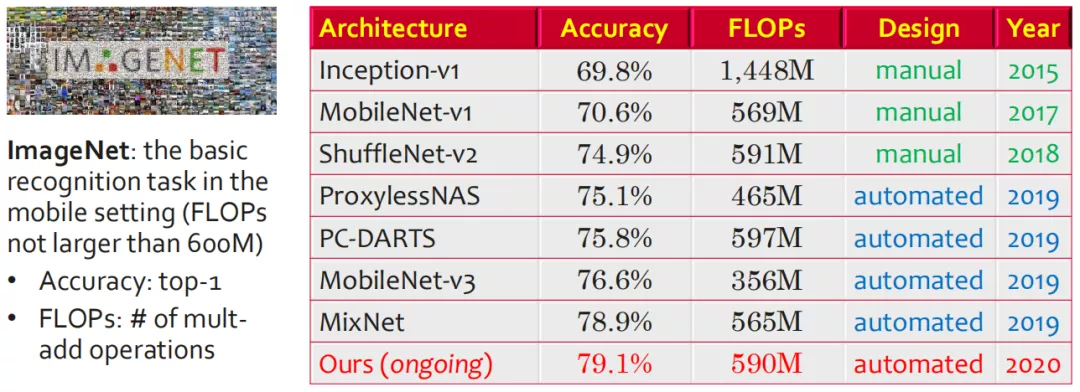
另一方面,在 Mobile setting 方面 ( 即 FLOPs 不超过 600M ) 的图像分类任务中,NAS 比人工设计方法具有更好的表现。因为"资源受限",就更需要精细化设计,这是人工所不擅长的。在这一赛道上,华为自研算法在表现上已经超过了 Google。目前这项研究还在进行中。
这类 NAS 的方法带动了业界很多任务领域发生了变化,除了分类任务外,检测、分割、底层视觉等任务的实现方法都产生了很大的变革。下一部分会简要介绍业界 NAS 框架的通用 pipeline。
02 网络架构搜索的通用框架
1. 通用 Pipeline
业界和 NAS 相关的文献已有超过 200 篇,但这些文献的思路都大同小异,都是基于 “trialand update” 的思路开展的工作。所谓 “trialand update”,就是在超大的搜索空间中,按照一定的规则启发式地寻找最优的网络架构。
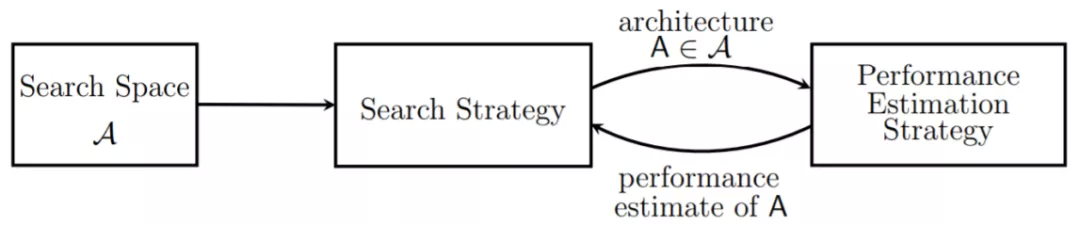
常使用以下步骤:

2. NAS 三要素
NAS 的三要素是: 搜索空间,搜索策略,评估方法。

搜索空间:哪种结构可以被找到?
搜索策略:如何从较大空间中进行结构采样?
评估方法:如何评估采样结构?
① 搜索空间
定义搜索空间的过程中,会遇到很多选项:
选项一:定义一个开放空间还是封闭空间?
目前大部分的搜索空间都是封闭空间,即:
搜索空间是预先定义好的
能搜索到哪些网格架构是预先清楚了解的
未来的发展方向可能会是开放性的搜索空间。
选项二:是否预先定义单元格 cell?是基于 cell 的搜索还是对网格架构做整体搜索?
推测未来的发展方向是整体搜索,但如今算法发展程度有限,主要还是基于 cell 的搜索。
选项三:操作集的规模要多大?
这个需要根据具体场景定义;通常使用下图中操作集的子集。

② 搜索策略
目前常见的搜索策略包括两类:独立的搜索策略和权值共享的搜索策略。我们的工作,主要偏向于后者。

权值共享的含义是:
在训练的较大网络中,包含很多小的网络;
在评估小网络的时候,可以利用以前计算的结果。
③ 评估方法
评估方法与搜索策略"强绑定"。独立的搜索策略,每个网络搜索出来后,需要独立地从头到尾训练一遍;而权重共享的搜索策略,会有对应的更加高效的方法进行评估。
03 权重共享的网络架构搜索算法以及面临的挑战
1. 搜索效率是关键
前期 Google 采用独立的搜索策略,将采样的每个网络结构从头到尾都训练一遍,搜索过程耗时长,搜索效率极低 ( 每个搜索耗用上千个 GPU 天 )。
针对这一问题,采用的解决办法是:复用前面训练好的结果。这样逐渐就形成了"权重共享"这样的方式。
解决方法:采样结构间共享计算
好处:将单个搜索的成本降低到少于一个 GPU 天
带来了新的问题:权重共享机制引入了误差
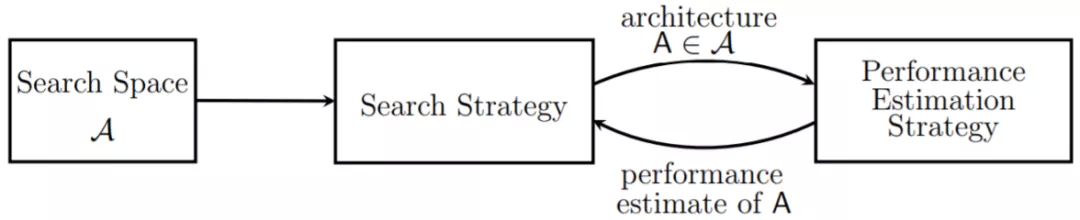
2. NAS 的两大主流方向
① 独立 NAS 方法:独立搜索与评价
优点:
搜索 pipeline 相对灵活
更容易执行多目标优化
搜索和评估分离,因此更稳定
缺点:
搜索过程耗时
② 权重共享 NAS 方法:联合搜索和评估
优点
:
搜索过程计算效率高
缺点:
大量权重共享,会给搜索带来不稳定性
因此,如何处理这种不稳定性,也是本文后面分析的主要内容。
3. 可微 NAS
如今业界常用的方法是 DARTS 法 ( 可微分网络架构搜索方式 ),将网络架构构建成 cell-based 的方法,每个阶段都是一个单元,每个单元内都会有很复杂的结构;而单元结构的数量,可以在训练过程中做调整。
① 基于单元的搜索空间
可重复单元,单元数量可调。
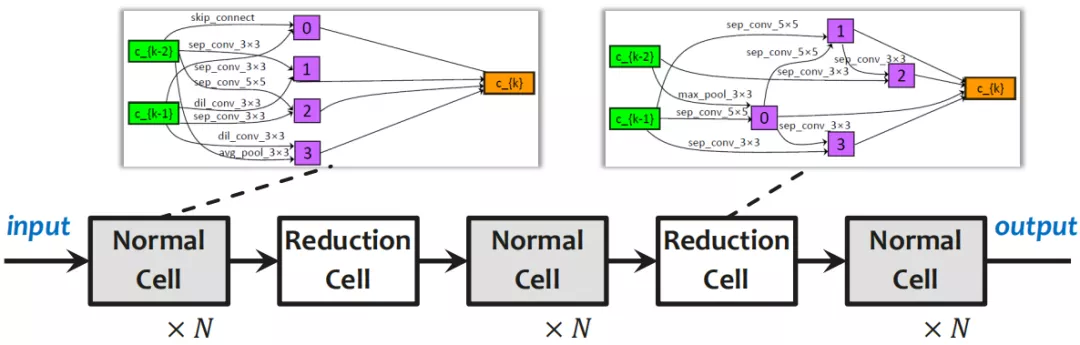
② 在每个 Normal Cell 中,搭建有向无环图 ( DAG )
所有运算符都可以出现在每个边上,并带有加权和
将架构搜索变成一个持续优化的问题
将架构剪枝,保留主导算子,最终确定架构
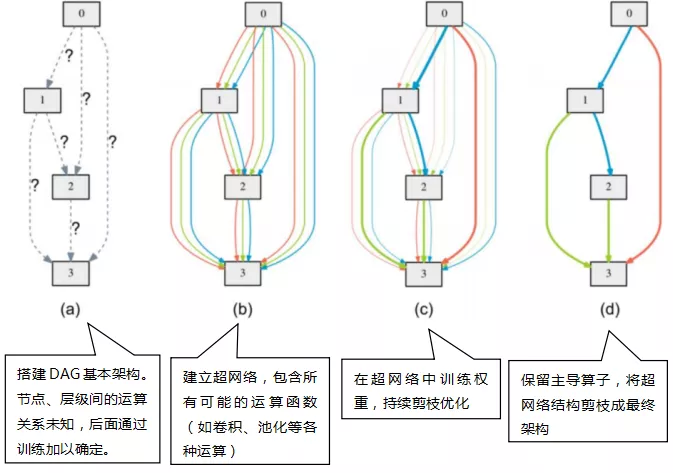
这样处理,只需要超网络的一次训练,就可以得到这样的网络架构。
4. DARTS 的本质和弊端
通过测试发现,DARTS 结构非常不稳定。
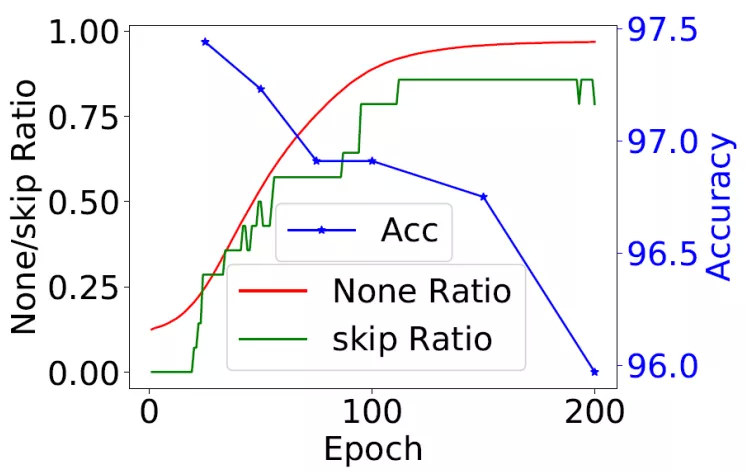
当网络训练参数设定在 50 轮的时候,得到的网络架构还比较"正常";但是当训练迭代设定在 100 轮时,会得到很"奇怪"的网络架构:所有节点间都是"跳连" ( skip_connect ) 运算,这样就失去了网络的意义。
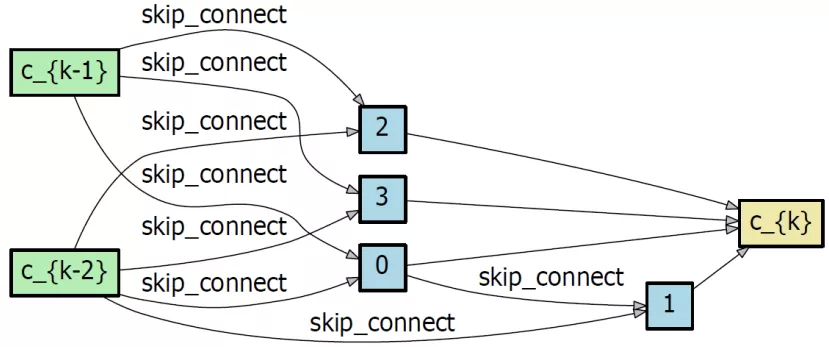
DARTS 的本质是训练超级网络,再通过剪枝处理形成子网络。但是这里有个前提假设:优化良好的超级网络可以产生良好的子网络。
但是,上述假设并不一定成立:超级网络和子网络之间可能存在很大的"优化差距"。
一个极端的例子:搜索崩溃,超级网络中的所有边缘都被一个弱的 skip_connect 算子控制,但是超级网络的验证精度仍然很高
当前解决方案:提前终止,这使得搜索结果相当不确定
由此可以看到,即使超网络训练得再好,也不一定能够得到一个有效的子网络。因此,我们后面的工作主要集中在缩小优化误差。
04 我们在神经结构搜索方面的代表性工作
1. P-DARTS ( Progressive-DARTS ):缩小搜索和评估之间的差距
① 概览
我们着眼点:"优化误差"的一个特例——深度误差
观察:搜索过程在浅层架构上执行,但评估过程在深层架构上执行
深度误差:浅层架构中的最佳配置不一定适用于深层架构
我们的解决方案:逐步增加搜索深度
两种有用的技术:搜索空间近似和搜索空间正则化
在标准图像分类基准上取得了不错的结果:
在 CIFAR10/CIFAR100 和 ImageNet 上,大大改进了 DART 以外的功能
搜索成本低至 0.3 GPU 天 ( 单 GPU 7 小时 )
② 缩小深度差距
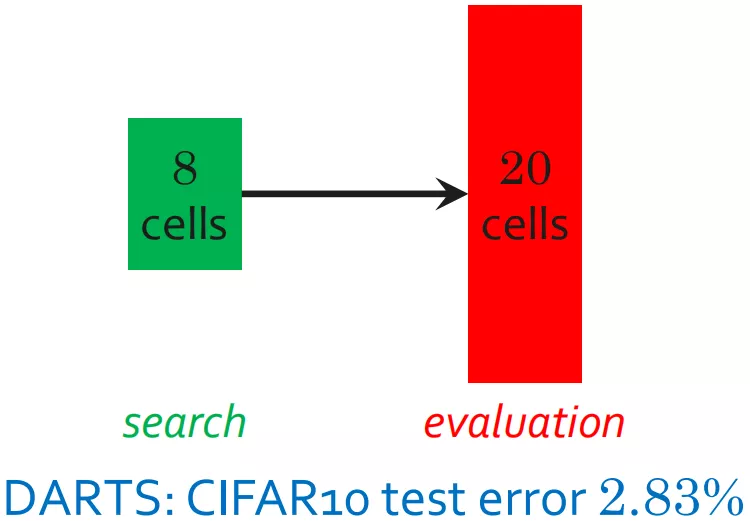
上图中,在 DARTS 搜索阶段,堆叠了 8 个单元;网络应用阶段,堆叠了超过 20 个单元。这样会带来"深度误差"。即使忽略"深度误差",训练过程中得到的网络也是 8 层结构上的最优网络,不是 20 层结构上的最优网络。而如果直接搜索深层架构 ( 20 个单元 ),计算效率又非常低下且不稳定。
基于此,我们的解决方案是:在搜索过程中逐步增加网络深度。
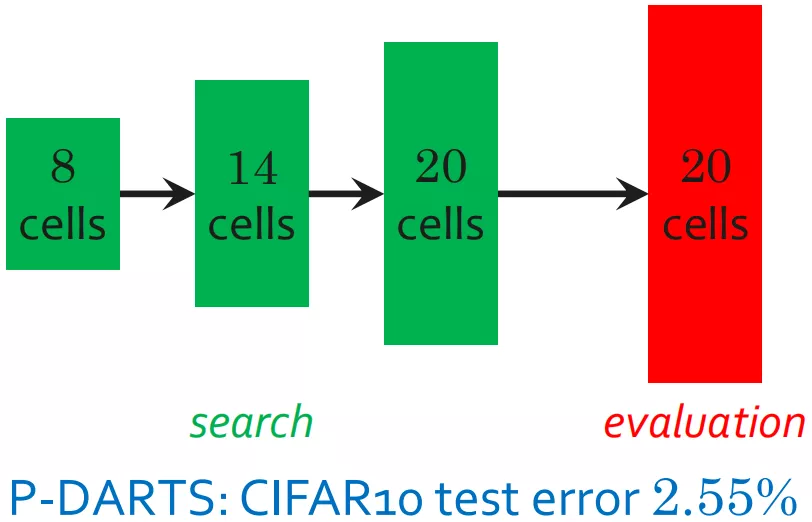
③ 整个流程
使用搜索空间近似法可降低搜索成本:每次增加超级网络深度时,我们都会修剪一部分弱边。
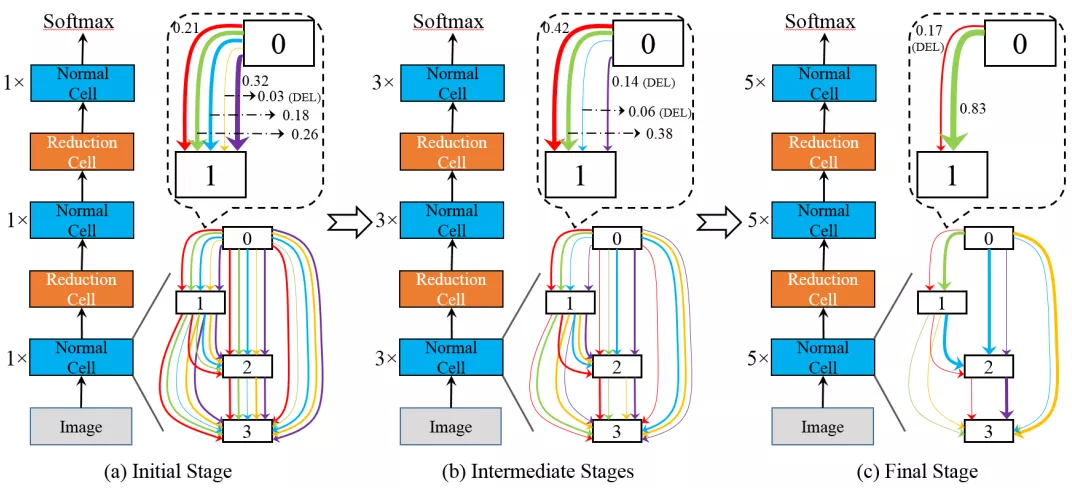
④ 优化技巧
在深层网络上,由于跳连操作对网络的稳定性有较大的影响,因此尽可能保留同样数量的跳连操作。这样的操作,给网络架构带来一个非常强的"先验",增强网络的稳定性。因此,对搜索空间的选择是非常重要的。
结果 ( 选取 CIFAR10 作为测试集 ):
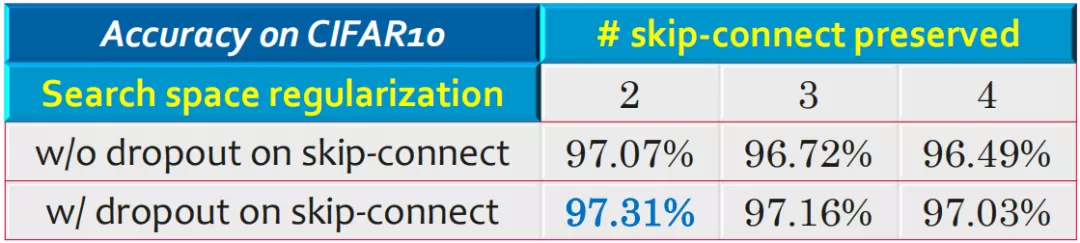
⑤ 在经典数据集上的表现
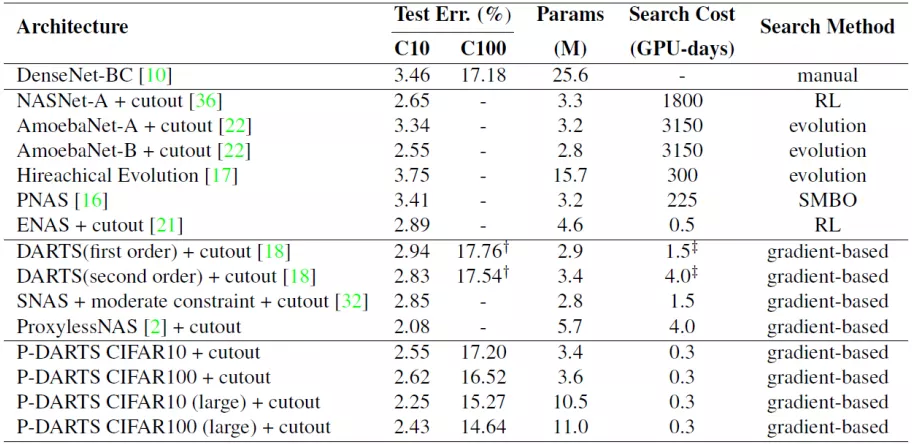
相比于 DARTS 方法,NAS 具备更优的性能和更快的搜索效率。
在 CIFAR10 数据集:
错误率:P-DARTS 2.55% vs DARTS 2.94%
单次搜索资源消耗:NAS 0.3 GPU 天 vs DARTS 4 GPU 天
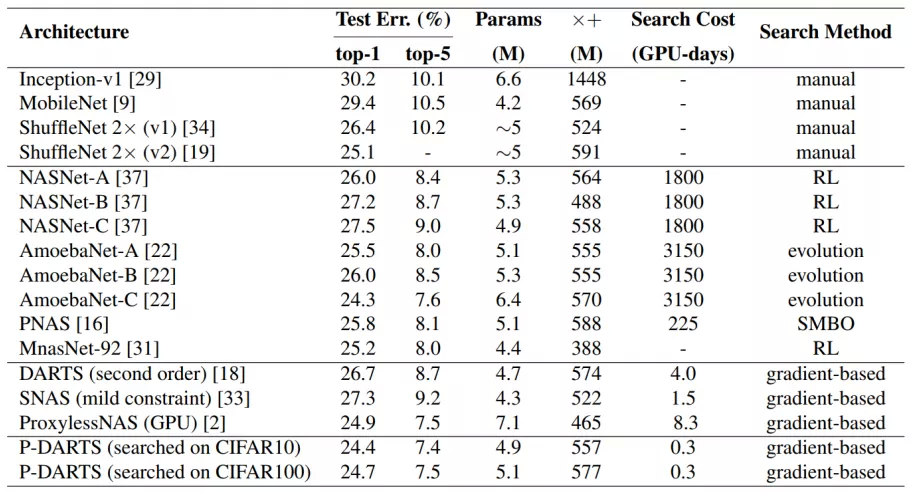
在 ImageNet 数据集:
错误率:NAS 24.4% vs DARTS 26.7%
单次搜索资源消耗:P-DARTS 0.3 GPU 天 vs DARTS 4 GPU 天
⑥ 在单元中的搜索架构
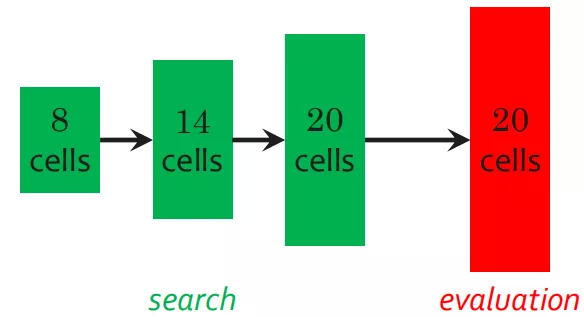
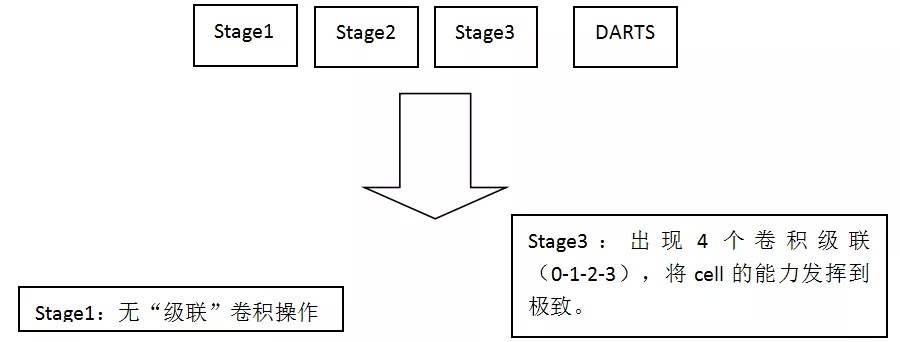
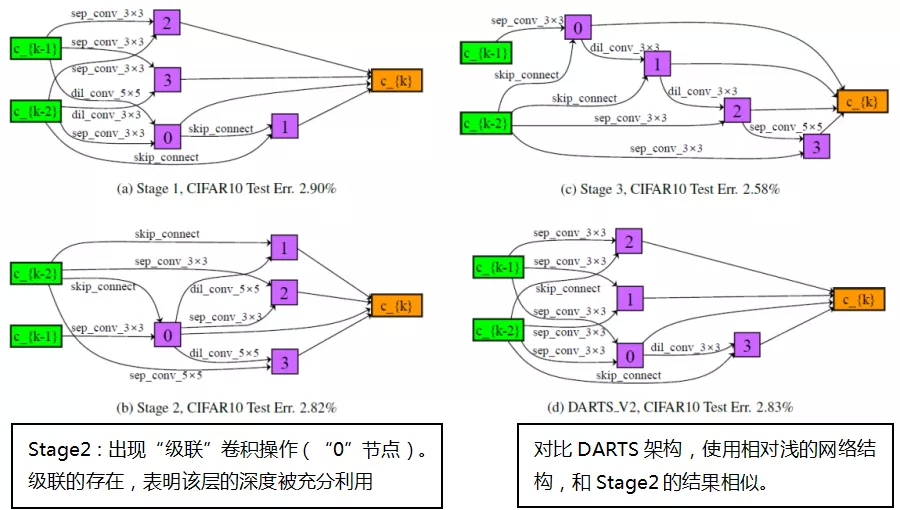
与 DARTS 相比,更深入的架构,进而验证了深度差异的存在。
2. PC-DARTS ( Partial Channel ):NAS 正则化与规范化
① 概览
我们关注"优化差距"的另一个方面——过拟合
观察:超级网络可以很容易地拟合训练数据;但是经过修剪,子网不能继承超级网的能力
“过度拟合问题”:最好的超级网络不一定产生修剪后的最佳子网
我们的解决方案是随机抽取部分超级网络频道,这样处理的一个附带好处可以加快搜索过程。我们在标准图像分类基准上取得了不错的结果:
在 CIFAR10 和 ImageNet 上,在 DARTS 基础上产生了很大的改进
搜索成本低至 0.06 GPU 天 ( 单个 GPU 1.5 小时 )
② 总体流程
PC-DARTS 包括两个重要步骤:PC ( PartialConnection ) 和 EN ( Edge Normalization,边正则化 )
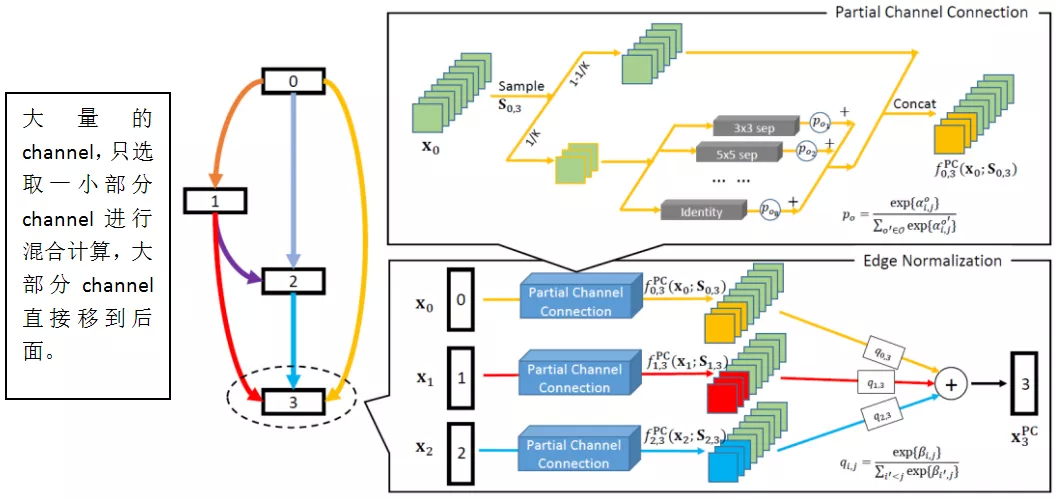
使用 PC 的方式,训练速度会变慢,但是稳定性会变强;
使用 EN 的方式,用额外的参数进行"选边",这样会提高"剪枝"操作的稳定性。
③ 在经典数据集上的表现
相比于 DARTS 方法,PC-DARTS 具备更优的性能和更快的搜索效率
在 CIFAR10 数据集:
错误率:PC-DARTS 2.57% vs DARTS 2.76%
非常快的搜索速度,单次搜索资源消耗:0.06 GPU 天
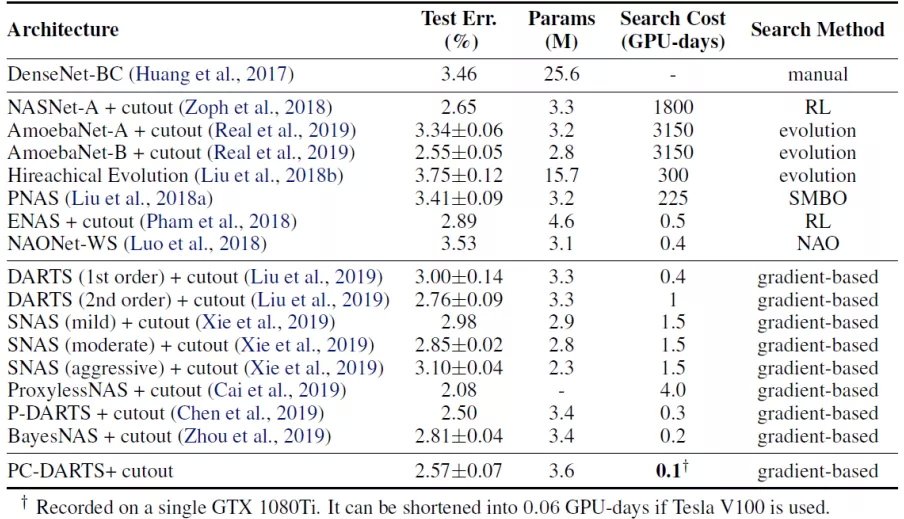
在 ImageNet 数据集:
单次搜索资源消耗:3.8 GPU 天;错误率降至 24.2%,比 P-DARTS 错误率更低。
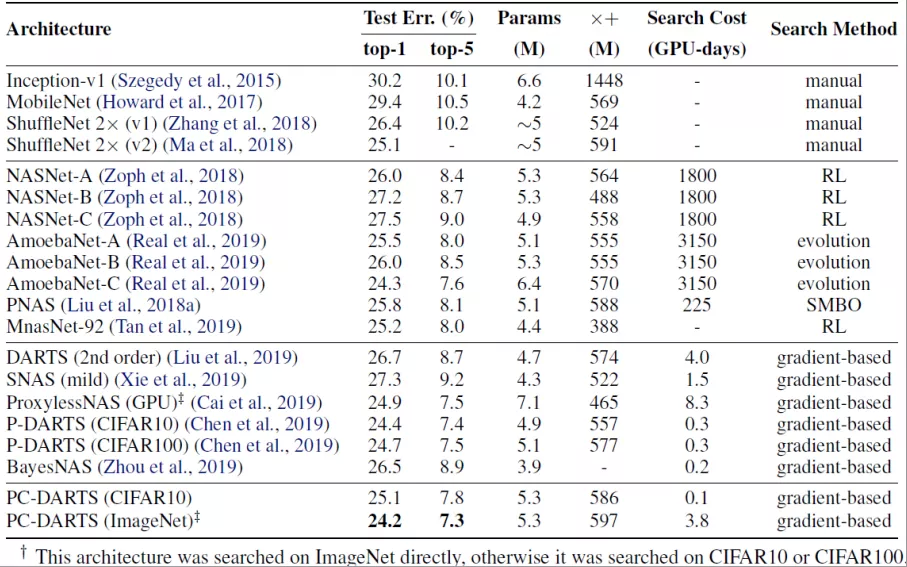
④ 网络消融研究
边缘规范化提高了搜索稳定性:
PC-DARTS 的 EN 部分不仅适用于此方法,也适用于其他基于 channnel 的方法
搜索效率和准确性之间存在权衡:
大多数情况下,大型数据集需要采集更丰富的信息
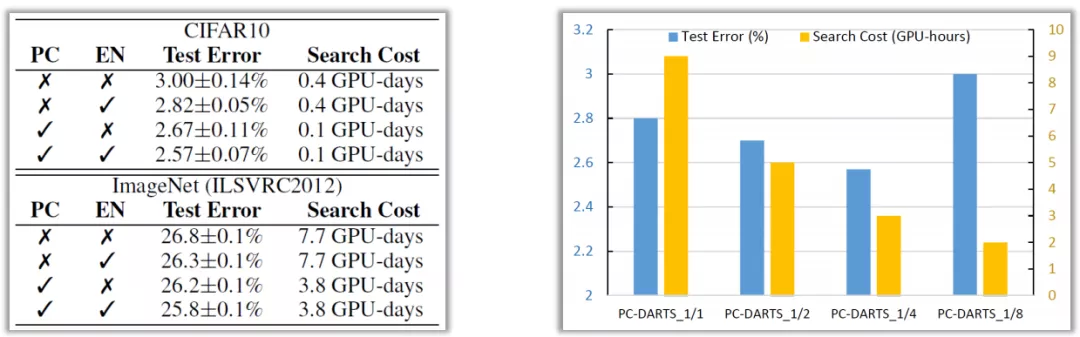
⑤ 单元搜索结构
从 CIFAR10 和 ImageNet 中搜索不同的单元格;在 CIFAR10 上的搜索任务,基本上都是并联卷积,很少有串联部分,也获得了很好的性能;而在 ImageNet 搜索任务中,建立的单元格更深。
3. Stabilized-DARTS:缩小稳定优化误差
我们处理数学中的“优化误差”:
一个重要的关键在于梯度计算的近似误差。原始的 DARTS 方法,可能会导致梯度方向的错误。
为了缩小优化误差,我们对梯度进行了更好的估计,确保每次优化的梯度方向和真实的梯度方向夹角小于 90 度,缓解了 DARTS 的不稳定特性。
我们的方法在一个非常大的搜索空间中工作,实现了搜索性能的稳定:
4. LA-DARTS:在可区分的 NAS 中引入延迟
我们允许基于 DARTS 的方法进行延迟预测,在保证精度的前提下,PC 端 DARTS 的延迟减少了 20%。
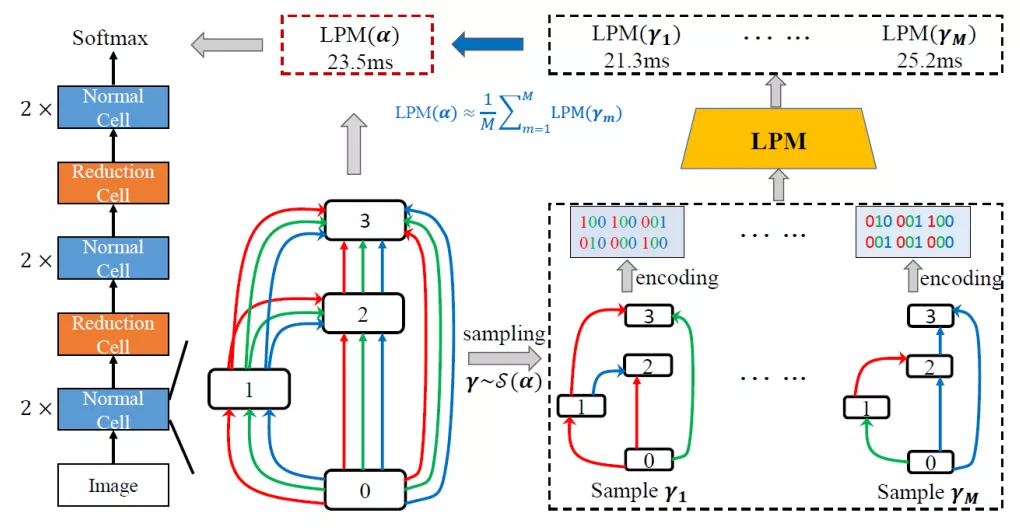
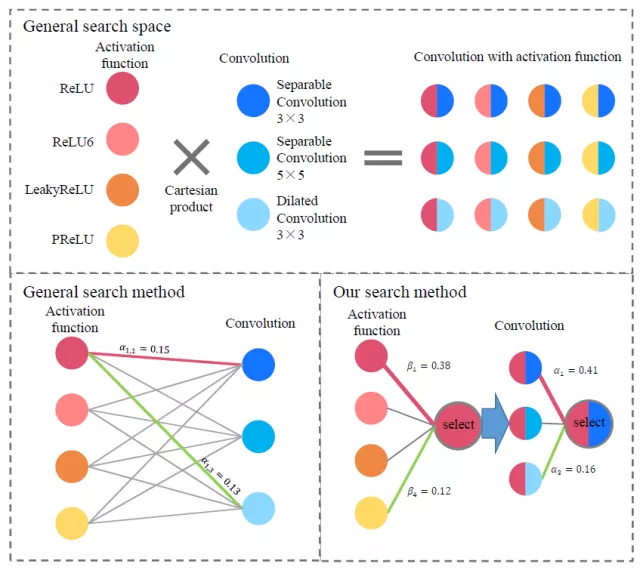
5. Scalable-DARTS:扩大因子分解的搜索空间
我们通过分解扩大 channel 的搜索空间:
将一个大的算子集分解成几个小的集合
搜索空间中的运算符数量增加,但额外成本很少,不稳定风险可控
在 CIFAR10 和 ImageNet 的准确性都得到了一致的提高
05 总结和未来展望
1. 总结
① AutoML 是一个新兴的话题,也是人工智能未来的一部分,NAS 是 AutoML 的一个分支,是深度学习的前沿方法。
② NAS 的两个主要选择:离散优化与权重共享优化
启发式搜索是保守的,适用于小空间,并且行为稳定
可微搜索很有前途,但仍有许多严重问题需要解决
③ 朝向稳定可微搜索:缩小优化差距
P-DARTS,PC-DARTS,Stabilized DARTS:侧重于搜索策略
Scalable-DARTS:侧重于扩大搜索空间
LA-DARTS:侧重于硬件友好性
2. 未来趋势
问题 1:哪种搜索策略更好,是离散搜索还是权重共享搜索?
离散:大多数用户似乎负担不起计算开销
权重分享:稳定性低于满意度,但已取得进展
问题 2:基本搜索单元应该是什么,是层还是基本运算符?
较小的基本单位意味着较大的搜索空间,这需要搜索稳定性
较小的基本单元可能给硬件设计带来挑战
问题 3:如何将搜索到的架构应用到现实场景中?
硬件:可区分的搜索方法还不适合,比如延迟问题。
个人愿景任务:是否共享同一主干?
今天的分享就到这里,谢谢大家。
本文来自 DataFunTalk
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论