

一、前言
随着旅游业的发展,人们对搜索的要求越来越高。智能化大趋势下,个性化的推荐系统的应用及用户需求也越来越广泛。
旅游推荐系统主要面临的问题及挑战包括:
用户维度,用户的需求多种多样,如本地异地的差异,年龄、家庭结构的差异等;
时间、地理维度,每个时间点的需求都是不同的,如季节(冬季的温泉,夏季避暑…)、早中晚的需求差异,不同城市用户对同一目的地的旅游产品类别需求可能不同;
产品维度,如何输出多样性的产品也是推荐系统考虑的重点,如相似的酒店、景点等。
针对以上面临的问题和挑战,本文将分享携程推荐系统的更新迭代过程。
二、推荐系统架构
携程搜索推荐系统架构如下:
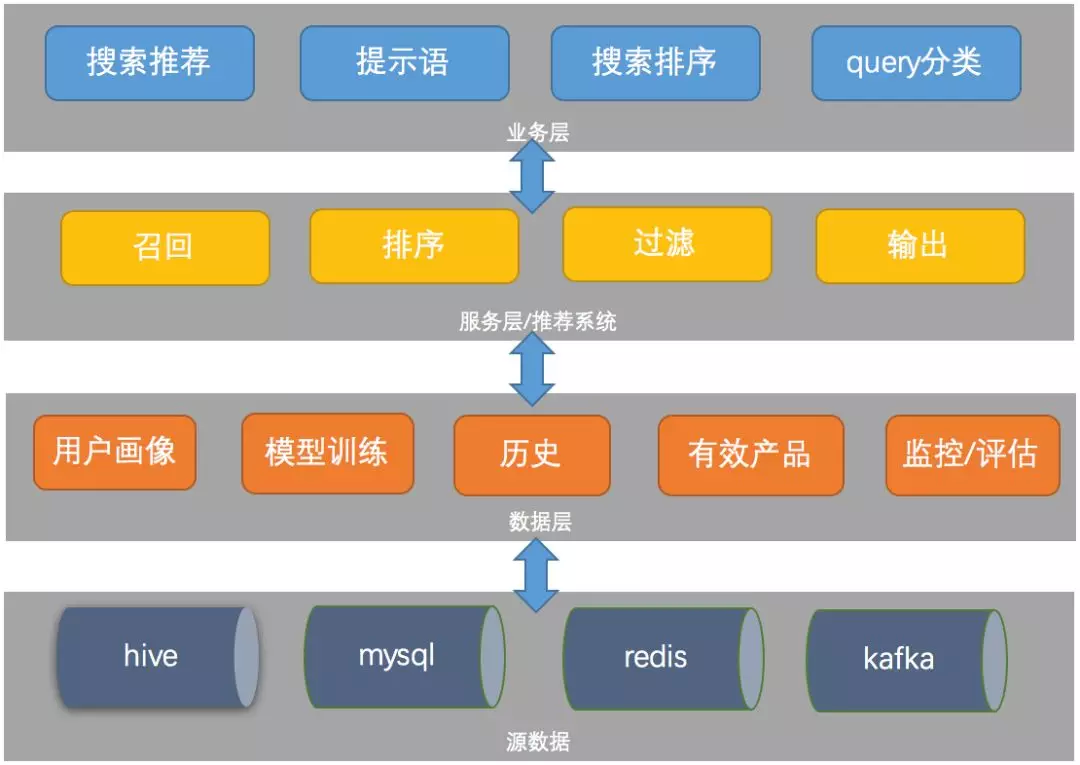
抛开业务和数据部分,这里只简单介绍推荐服务的结构,其简要构造如下:
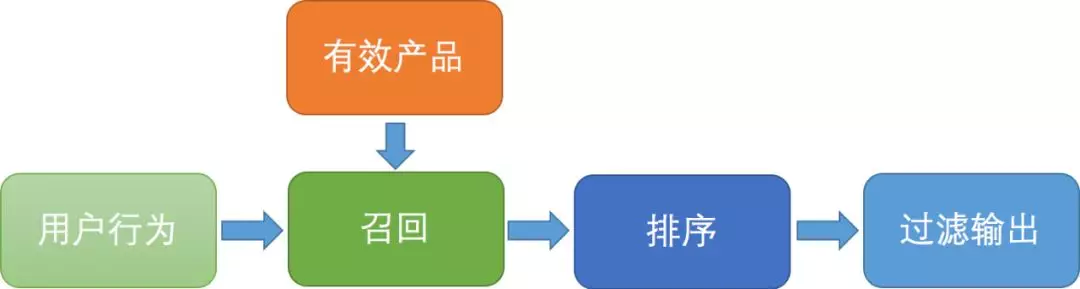
2.1 用户行为
用户行为数据展示了用户的操作习惯和偏好。对这部分数据进行离线分析,可以更好地理解用户,以此来做线上产品的推荐源。
对线上需要的行为数据,可以取一个月或者近 7 天的历史数据,以保证数据的时效性。
2.2 可用产品
这部分指的是可供用户使用的产品及可以提供帮助的文章等。主旨在于告诉系统,我们有什么产品,哪些产品是可以提供给用户的,及哪些是优质的产品。产品的定义比较广泛,可以不限定具体的售卖产品,也可指定用户偏好,比如用户对酒店、景点的偏向等。
2.3.召回
这部分是整个系统的重点,也是规划场景最多的地方。这部分可以细分成几大召回策略(以推荐实际酒店、文章、景点的系统为例):
2.3.1 补充策略
这部分主要输出当前热门的产品信息,比如当季热门的酒店、景点等。
在具体实现的时候可以考虑季节性的变化,比如以两周为周期,统计产品的点击情况,当用户对于温泉搜索量增加时,可以输出一些热门的温泉景点。
这部分补充策略,只是为了解决冷启动问题,即当用户没有行为,或者没有地理位置信息时,做最基本的补充。
2.3.2 基于位置召回
当得到具体位置信息之后,可以做更具体的补充召回:
1)根据当前用户所在地,推荐当地的热门产品;
2)判断用户是否在常住地。如常驻上海的用户,在上海搜索产品时,更喜欢周边游,而常驻北京的用户,在上海搜产品时,更喜欢东方明珠和迪士尼。
具体分类为:
本地需求(定位城市=常驻城市),输出当地人热搜/点击的产品;
外地需求(定位城市!=常驻城市),输出外地人热搜/点击的产品;
3)根据地理位置信息,输出用户周边的几公里内的产品。
2.3.3 基于历史关联策略
这部分内容是基于用户历史行为,推出相关的产品。需要对数据和行为进行总结,并提供相应的产品展示逻辑,丰富推荐召回的内容。比如用户预定迪士尼乐园的门票,可以推迪士尼附近的酒店等。
2.3.4 协同过滤
协同过滤是推荐系统经典的算法。其对用户行为、产品的相关性做了抽象和泛化。协同过滤算法主要分为 USER CF 和 ITEM CF,即基于用户的协同过滤和基于物品的协同过滤。
在这里我们主要用到基于物品的协调过滤,相比用户的协同过滤,物品的内容属性和数量更便于统计和计算。具体算法可以参看《推荐系统实践》这本书。
大体可以理解为,定了某一酒店的用户,又定了哪些酒店,及通常订了又订的逻辑。比如,以用户一个月的点击或订单数据为基础,计算出物品的相似度,当用户搜了某条产品时,推荐与其相似的其他产品。具体示例为:假设东方明珠、外滩、迪士尼产品相似,当用户搜索东方明珠的时,推荐外滩和迪士尼。
2.4 排序
上述召回策略,会召回大量的产品,如何对这些产品进行合理排序,是推荐系统的核心部分,同时也是反映系统优劣的指标。
这部分,经历几次迭代。
在 1.0 时代,在排序策略上进行了几次变动:
1)对召回产品按照类别,对相同类型产品,进行销量排序;
2)考虑到操作时间问题,加入操作时间权重。对历史行为的时间进行归一化得出权重,最大为 1。操作时间越近,权重越大;
3)考虑规则的重要性,加入规则分;
上述排序策略取得一定效果,但很难完善排序问题。
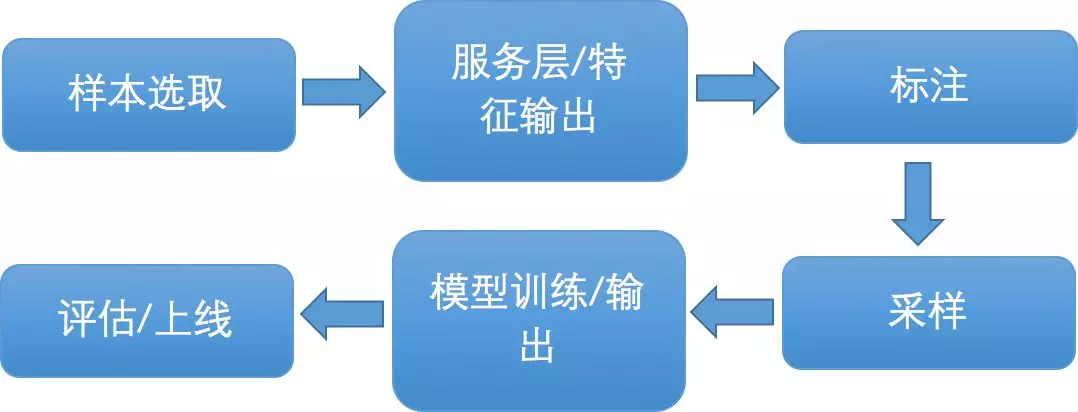
最终,选取了机器学习的排序算法。其基本实现为:对每个输出产品,规划特征,输出特征集。比如季节特征,当地人/外地人特征,一天内的早、中、晚特征等。接下来根据订单和点击数据,输出训练样本,为每个召回产品做一个打分,最高 5 分,最低 1 分。最后使用 XGBoost 工具,对样本进行训练,这样就能得出基本模型。
通过模型,对线上每个召回产品进行打分并排序,得出最终结果。同时在系统上线后,定期的进行更新,并通过 ABTest 系统不断对模型进行迭代。
大致流程如下:
2.5 过滤输出
这部分内容,主要做格式化输出,并过滤一些无效,黑名单产品。
每个场景的输出,都不太一样,就需要对其数据进行筛选。比如进入搜索默认页时,提前给出推荐产品,减少用户操作。还可以在用户搜某个具体城市时,输出相应的结果。
这里需要注意的是马太效应。由于推出的内容有限,对于一些产品,会导致点击多的会越来越多,而点击少的,则慢慢退出推荐序列。这里需要对那些不常用产品做展示规划。比如随机出一两条,给一定曝光,消除一部分马太效应。
三、展望
目前推荐系统已经运用在多个场景,但对场景及产品的引入毕竟有限,同时对 query 分析还不够完善,后续将丰富产品,并引入更多机器学习的内容,让系统更智能化和自动化。同时会加入更多深度学习内容,在搜索意图和 NLP 相关方面做更进一步的分析。
作者介绍:
葛荣亮,携程搜索部门高级研发工程师。2015 年加入携程,目前主要负责搜索平台的前端+数据挖据工作。
本文转载自公众号携程技术(ID:ctriptech)。
原文链接:
https://mp.weixin.qq.com/s/FxiyPZ-2E8Xmpdpwz2ohig

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论