
要点
对工程生产力的投资往往发生在特定的转折点,例如员工人数增加、危机事件发生后、组织成熟度提升、进入新市场,或追求卓越运营。
有些决策至关重要,将对构建工具的演变产生深远的影响。例如,在单仓库和多仓库架构之间做出选择会影响开发生命周期、测试策略和整体工程工作流程,需要采用量身定制的方法来优化生产力。
随着组织规模的扩大,即使风险预防措施似乎会减缓开发速度,战略且务实地实施控制措施和门槛(例如强制代码审查或金丝雀部署)也至关重要。
如果你想引领工程生产力的改进,你需要一种数据驱动的方法。这可以帮助你的领导层了解看似微小的低效之处,这些低效之处最终会造成大规模的浪费。
是否构建专有工具或使用第三方解决方案取决于可扩展性需求、优化机会、生态系统集成需求以及按照行业标准持续发展的承诺等因素。
我在 2024 年旧金山 QCon 的演讲深入探讨了以下主题:
从失败中学到的教训
2011 年时,我是一个处理 PB 级数据来支持我们公司零售网站的服务团队的工程师。随着黑色星期五的临近,我们需要进行负载测试以确保网站能够处理高峰流量,但由于时间限制,我们砍掉了测试。考虑到测试很费时间,我们认为它不值得投资。结果黑色星期五到来时,我们的服务没有足够的硬件来处理负载。我们疯狂地扩展,结果却让一个关键数据库过载了。
亚马逊商店在一年中最繁忙的购物日盲飞了八个小时。第二天,我的主管问我如何防止这种情况再次发生。这是一个转折点。突然之间,建立我之前建议的负载测试基础设施成为了优先事项。那次失败是一个价值数百万美元的运维问题,也成为了一个转折点——不仅对我的职业生涯,对亚马逊的基础设施也是如此。教训是?永远不要浪费一场大危机!
我们重要的收获是识别在哪些拐点上,对工程生产力的投资变得有利可图。识别反复出现的模式是非常重要的。
工程师数量
最明显的拐点通常是组织雇佣的工程师数量。随着公司从三千名工程师扩展到六千名,再到五万人,以前微不足道的效率谷地可能变得非常明显。
我倾向于考虑运维摩擦的程度、其发生的频率以及受影响的人数。例如,一位工程师最近强调了一个需要十秒钟完成的手动任务。这个看似微不足道的不便发生得足够频繁,以至于在亚马逊的规模上相当于每年损失大约三十五年的工程生产力。这不仅意味着失去大量时间,还代表着工程师错过的机遇——他们本可以投下更高杠杆、更战略性的赌注。
自动化这项任务需要四个月,再加上额外的两个月用于持续的运维维护。也就是说,投资半个工程师年可以收获三十五个工程师年,这是资源的明智分配。这些好处会随着时间的推移而累积。在五年的时间里,仅固定人员编制,累积节省的金额就达到 174 工程师年,在高增长环境中,这些好处甚至更加放大。
虽然量化工程生产力可能很困难,但并非不可完成的任务。我推荐 Douglas Hubbard 的主做《如何测量任何事物》,它提供了一些有价值的方法来量化看似无形的指标。即使最初的估计不精确——比如,范围在二十到五十年之间——获得一个合理的近似值提供了方向性的数据,这对于做出明智的投资决策是必要的。
拐点:一场危机
工程师人数构成了一个拐点,而危机代表了另一个重要的拐点。正如我前面提到的,我经历了这样一个转折点,也就是前面提到的 2011 年黑色星期五的例子。
八年后,亚马逊 Prime Video 需要负责泰勒·斯威夫特的“你需要冷静下来”的全球首映式直播。鉴于她庞大的粉丝基础,我们预计会有数千万同时观看用户。为了应对 2011 年运维问题而开发的技术被用来验证平台处理这种并发用户量的能力。
从 2011 年的运维问题演变到 2019 年支持数千万观众的直播,这是一段相当长的旅程。首先,我专注于为我的团队创建基础设施,只是想防止之前事件重演。然后,我意识到将其提供给其他团队会有很多潜在好处。采用率是有机增长的,从两个团队发展到十个,然后是一百个。
这个项目最初是一个个人宠物项目,最终扩展到了支持数千个服务的规模,并演变成我的主要职责。它成为了亚马逊全公司的负载和性能测试基础设施,用于上面提到的泰勒·斯威夫特首映式和 AWS 服务的推出等事件。这一进展揭示出了危机(无论是个人还是专业层面的)作为工程生产力进步拐点的潜力。
成熟度
组织成熟度也可以作为一个拐点。像亚马逊、微软、谷歌、Meta 等大型软件公司,通常在工程生产力工具上有大量重复。虽然我不是巨量冗余的爱好者,但这种重复既常见又往往有道理。
在快速增长的时期,快速独立行动至关重要,因此各个组织会优化他们的工具集以加快上市时间。
或者,在高度不确定性的条件下,进行一定程度的实验也是合理的。当前生成式人工智能的状态就体现了这种情况。虽然它对工程生产力的最终影响是肯定的,但它将如何重塑编码、测试和相关流程的具体方式还是很模糊,因此同时探索多种方法是一个合理的策略。
虽然一定程度的重复是有意义的,但总会有一个汇聚的时刻,那时废弃冗余系统和整合基础设施成为优先事项。在我重新加入亚马逊并在亚马逊全球商店工作时,我注意到越来越多的客户使用我们的移动应用,所以我觉得有必要改进我们的测试基础设施以反映这种变化。

当我们考虑构建基础设施以改善设备配置、测试执行和通过物理和虚拟设备进行资源管理的能力时,我与亚马逊内部其他团队进行了交流,这些团队负责移动应用(例如亚马逊 Prime 视频、亚马逊音乐以及以设备为中心的组织,如 Alexa 和 Kindle)的交付。这些讨论让我们看到了相当大的重复努力,这是在快速扩张期间团队独立开发的结果。所以,目前我专注于推动这些组织朝着更加统一的模型汇聚。作为高级负责人,我有自由度来健康地打破组织边界,并为整个亚马逊的最佳利益行事。
重要的是要认识到,拐点并不总是需要扩张;汇聚和整合同样是有效的目标。我在谷歌领导了将四个不同的集成测试基础设施整合的项目,那时的经验也加强了这种观点。
运维或工程效率
提高运维或工程卓越的标准也可以作为变革的催化剂。随着组织的发展和工程师数量的增加,关卡变得更重要了,这样才能保持我们的高标准。
安全实践的演变就是一个例子。信不信由你,在 2009 年,直接用 SSH 访问生产服务器是很常见的。今天,授予类似的访问权限到 EC2 或 S3 生产环境是绝对不可接受的。
同样,曾经普遍存在的还有未经审查的直接代码提交。虽然代码审查被鼓励作为最佳实践,但仓库工具本身并不强制执行它。现在,我们的代码审查工具确保在合并代码之前获得指定审查者的批准。这些控制虽然引入了一定程度的摩擦,但在大尺度上是必不可少的。
每个 AWS 服务都应该实施金丝雀来监控它们的健康度吗?几年前我们决定,鉴于我们向客户提供的 SLA,答案是肯定的。因此,适当的金丝雀现在是启动任何 AWS 服务的强制性先决条件。
代码更改应该在足够的代码覆盖率上进行限制吗?同样,答案是肯定的。虽然团队保留了确定他们特定的代码覆盖率目标的自主权,但他们也需要有意识地决定生产中可接受的未测试代码水平。
这些控制措施虽然可能被视为对敏捷性的阻碍,但都是对过去的运维事件的直接响应,最终目的是提高我们的工程标准。
新市场作为拐点
新市场的出现也可以作为一个拐点。
回到 2014-2020 年,当我在亚马逊的 Builder Tools 组织工作时,我的主要重心是为网络服务提供工程生产力基础设施,因为那代表了当时大部分正在进行的工作。但公司扩展到设备领域的步伐带来了新的挑战。我们现有的持续集成和持续交付(CI/CD)工具针对网络服务优化。移动电话、Alexa 设备和 Kindle 设备却有着不同的需求。
多年来,我们已经扩展了我们的 CI/CD 基础设施,以适应一些我从未想过我们会做的事情,例如测试旋转门。亚马逊 Go 商店有一个无需结账的模式,客户进入,扫描他们的支付方式,选择他们的物品,然后离开,无需与收银员互动。这些商店的旋转门由软件控制,我们需要测试它们。
随着公司将其业务扩展到新市场,嵌入在工具中的先前假设可能不再有效,我们需要拓宽视野。
基础决策作为拐点
最后,某些决策本质上是基础性的,塑造了后续工程实践和工具的轨迹,影响几代人。观察亚马逊过去十五年的演变,我见证了这些决策的持久影响。
大约在 2007 年,亚马逊在管理一个大型、紧密耦合的代码库(被称为“Obidos”)方面遇到了很多挑战。这些挑战包括编译时间、部署复杂性、内存限制和协作开发的困难。我们决定将单体分解为微服务——这个概念今天被广泛接受,但当时较少见。分解单体的主要目标是建立清晰的团队界限,从而最小化相互依赖性。
这种方法导致了“两个披萨团队”的采用,这个术语指的是可以用两个披萨(通常是六到九个人)喂饱的工程师数量。其目的是创建负责离散微服务的自治团队,这些服务通过 RPC 或 HTTP 在网络上通信,不共享代码。为了加强这种解耦,我们采用了多仓库策略,让每个团队维护自己的独立仓库。
单仓库与多仓库的问题本质上是架构偏好的问题。我在谷歌(单仓库环境)和亚马逊(多仓库环境)的经验表明,这两种方法都涉及管理复杂性,尽管形式不同。一个并不比另一个更好:由你处理复杂性的地方决定该如何权衡。
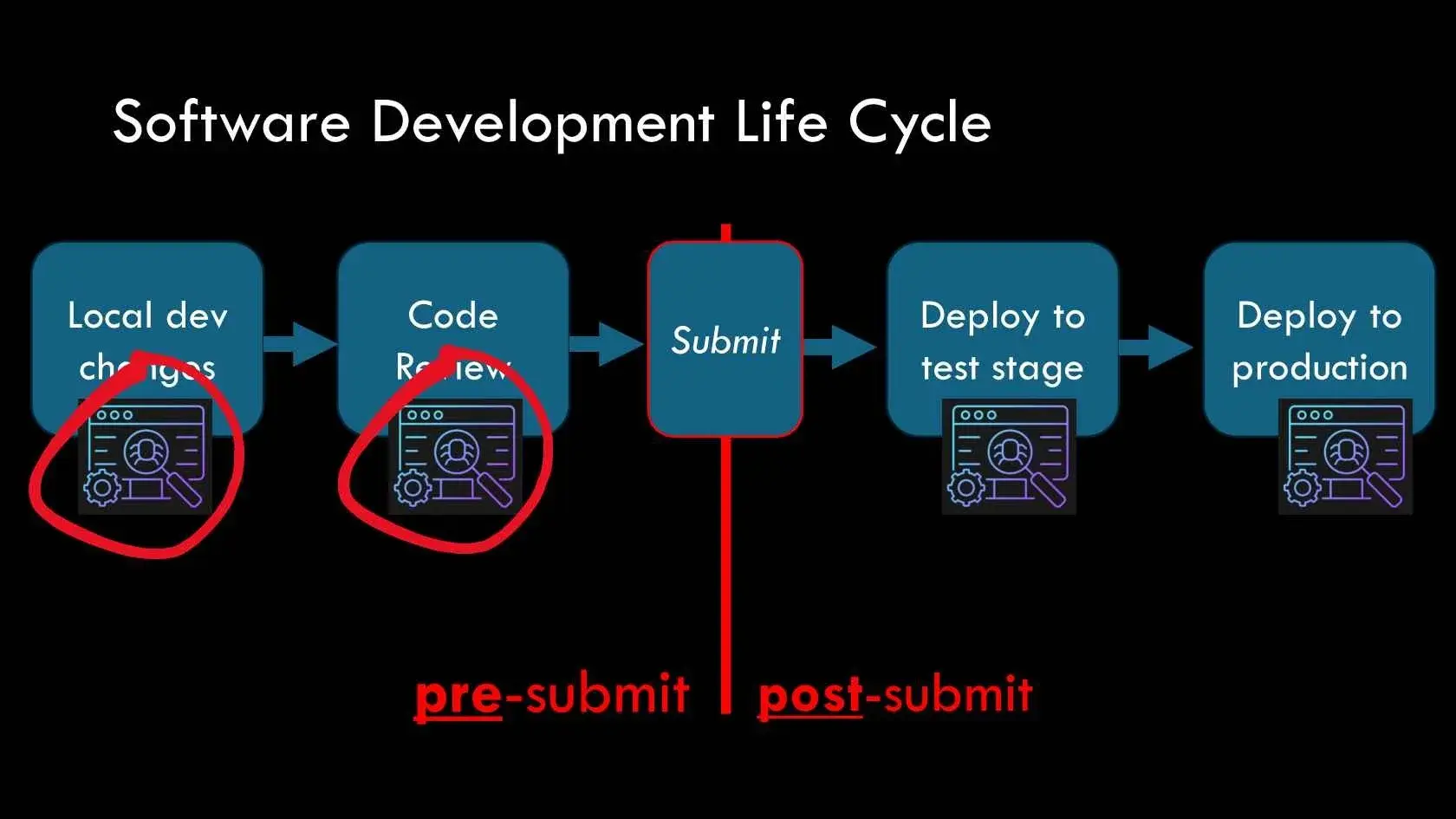
考虑软件开发生命周期,它通常包括本地开发变更、代码审查、提交和合并、部署到测试环境,最终部署到生产环境等步骤。理想情况下,每个阶段都要执行集成测试。
用房子的比喻来说,多仓库环境就像一个有很多独立房间的房子。一个仓库中的错误被限制在那里,主要影响负责它的团队,限制了对其他团队的干扰。
相比之下,单仓库环境类似于一个单间公寓:错误可能产生深远的后果。谷歌拥有 12 万名工程师的庞大工程团队,已经投入了大量资源在基础设施和流程上,以减轻缺乏分支的单仓库相关风险。虽然这种方法在大部分情况下是有效的,但它也有缺点,例如验证复杂度更高和部署挑战。
多仓库架构本质上限制了潜在错误的爆炸半径。但在单仓库环境中,影响可能是广泛的,因此提交前测试是至关重要的。因此,像谷歌这样的公司优先投资于提交前集成测试,以识别和防止此类问题。另一方面,亚马逊利用其多仓库架构固有的爆炸半径减少优势,专注于提交后测试策略。提交前和提交后的策略是各自的反面;然而,每种策略在其各自的环境内都是有效的。
由于这种需要左移和早期测试的需求,谷歌在基础设施上投入了大量资金,用于快速配置和取消配置的临时、封闭的测试环境。相比之下,多仓库环境历来强调长期存在的、静态的测试环境,具有高保真度,以及健壮的金丝雀部署、遥测、回滚机制和生产报警能力。(现在,甚至亚马逊也在增加对左移的关注)。
在多仓库环境中管理库依赖关系是一种独特的挑战。我们需要创建机制,以实现依赖库从一个仓库到其他仓库的受控分发,以及跟踪组织中的库版本,以解决潜在的安全漏洞。
专有工具与第三方/开源工具
我们经常需要在开发专有工具和利用第三方解决方案之间做出选择。投资定制工具有几个理由。首先,现有的第三方或开源解决方案可能缺乏你的特定需求所需的可扩展性。我在 2012 年开发亚马逊的负载和性能测试基础设施的经验就是一个很好的例子:没有现成的工具能够实现必要的吞吐量。
其次,优化可能需要定制开发。谷歌的内部 IDE 是一个相关的例子。鉴于谷歌有 12 万名高薪工程师,投资于提高他们效率的 IDE 是一个明智的战略决策。
第三,一个集成工具的一致生态系统可能比需要大量集成工作的一系列不同的第三方解决方案更有效。这是亚马逊、微软和谷歌等大型组织在全面的工程生产力平台上进行内部投资的理由。
然而,意识到与专有工具相关的潜在陷阱很重要。在一个特定的组织“泡沫”中被孤立的风险始终存在。保持对行业趋势的关注,并确保内部工具继续随着外部进步而持续发展是至关重要的。如果做不到这一点,专有解决方案可能会变得过时,效果不如商业上可用的替代品。虽然我在开发专有工具上花费了我职业生涯的很大一部分时间,但我认识到了固有的权衡和在追求这条道路时需要仔细考虑的必要性。
总结
总之,优化工程生产力的路径是多方面的,需要对各种拐点进行深思熟虑的评估:人员数量、危机、组织成熟度、新市场和追求运维卓越。基础架构决策,如选择单仓库和多仓库策略,进一步影响资源分配和测试方法的优先级。
最终,决定投资于专有工具还是第三方解决方案需要平衡评估可扩展性、优化潜力、生态系统效应以及持续与行业进步保持一致的需求。组织可以通过深思熟虑地考虑这些因素,培养一个既促进效率又促进创新的工程环境。
原文链接:
Inflection Points in Engineering Productivity as Amazon Grew 30x




