
Grafana Labs 发布了 Grafana Mimir 3.0,可以说是这款开源、可横向扩展的时序数据库的重要升级。本次版本采用全新的架构,将读写操作彻底分离,大幅提升了在大规模指标场景下的性能、可靠性和成本效率。
Grafana Mimir 自 2022 年推出以来,已成为普罗米修斯(Prometheus)和 OpenTelemetry 生态中领先的指标后端之一,目前在 GitHub 上拥有超过 4700 颗星,并由约 30 名维护者积极贡献。该项目的核心目标是打造一款高度可扩展、高效的开源时序数据库,能够支撑 10 亿条以上的活跃序列。
3.0 版本的核心亮点是全新的解耦架构,解决了早期版本中的关键瓶颈。在过去的 Mimir 版本中,ingester 组件同时负责写入和读取,这意味着在查询负载很重时,会挤占写入性能。新版架构引入 Apache Kafka 作为读写路径之间的异步缓冲层,使摄取和查询能够独立扩展,并消除了此前影响系统稳定性的互相依赖关系。
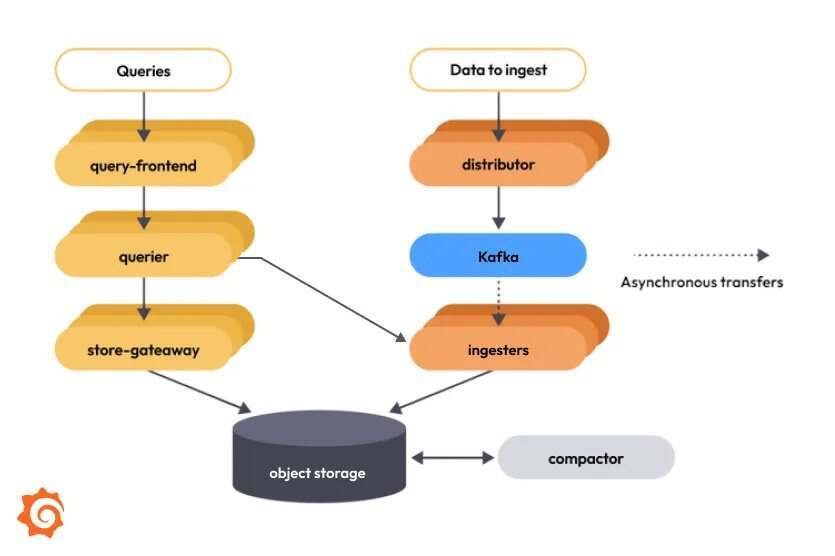
Mimir 3.0 架构
这次的架构升级引入了 “ingest storage(ingest 存储)”,这是 Grafana Labs 设计的关键组件,用来避免查询量的突然上升拖慢数据写入,反之亦然。内部测试显示,系统可靠性有了显著提升,尤其是在组件开始出现故障的早期阶段,读取路径因 ingester 随机故障而导致宕机的风险大幅下降。
架构调整的同时,Mimir 3.0 还将 Mimir Query Engine(MQE)设为默认查询引擎。MQE 首次在 Mimir 2.17 中推出,其处理方式不同于传统的普罗米修斯 PromQL 引擎。普罗米修斯的查询引擎会批量加载样本数据,导致内存使用不可预测;而 MQE 采用流式执行方式,在查询过程的每个步骤只加载当前需要的样本。Grafana Labs 表示,这种方式能够将峰值内存消耗降低多达 92%,让查询速度更快,也让系统在高负载下保持更稳定,同时依然保持 100% 的 PromQL 兼容性。
性能提升不仅体现在查询执行上。Grafana Labs 的测试结果显示,在他们的大规模集群中,资源使用量减少了最多 15%,同时性能和可靠性反而更好。这些收益来自解耦架构与流式查询引擎的组合效果。
Mimir 3.0 的设计反映了团队在大规模运行 Mimir 时的经验,其中包括像 CERN 这类大规模用户的反馈。他们将重点放在三个核心方向上:
通过分离职责提升可靠性
通过流式查询提升性能
通过更高效的资源使用降低成本
由于架构变更幅度很大,Grafana Labs 建议组织谨慎规划升级流程。升级需要在现有集群旁部署一个新的 Mimir 集群,然后调整写入客户端,让数据同时写入多个端点,最后再将读取客户端切换到新集群。在此期间,组织需要同时调整两个集群的 Helm 或 Jsonnet 配置。
目前,Mimir 3.0 的新能力已经在 Grafana Cloud Metrics(基于 Mimir 的托管指标服务)上线。对于自建部署的用户,项目文档提供了升级指南和发布说明,帮助团队顺利迁移到新架构。
这次发布体现了过去三年的打磨成果,也继续推动项目在指标存储与查询方面的发展方向。Mimir 3.0 的解耦架构与升级后的查询引擎,为组织在扩展可观测性系统时提供了更高的效率,同时降低了复杂度和资源成本。
对于寻找 Mimir 替代方案的组织而言,也有不少成熟的时序数据库可选。普罗米修斯是一款非常流行的开源工具,具备强大的 PromQL 查询语言,并与 Kubernetes 深度集成,不过其设计主要面向单节点场景。InfluxDB 则擅长应对高写入和高查询负载,拥有 InfluxQL 和 Flux 查询语言,适合 IoT 与实时分析场景。TimescaleDB 是 PostgreSQL 的扩展,适合熟悉 SQL 的团队,可复用现有工具,同时获得时序优化能力。云原生场景下,亚马逊 Timestream 和谷歌云 Monitoring 提供托管服务,可减少运维成本。Thanos 则通过加入长期存储和全局查询能力,扩展了普罗米修斯,并解决了部分 Mimir 同样关注的可扩展性问题。不同方案在可扩展性、查询性能、运维复杂度以及生态兼容性方面各有取舍。
原文链接:




