

引言
美团搜索是美团 App 连接用户与商家的一种重要方式,而排序策略则是搜索链路的关键环节,对搜索展示效果起着至关重要的效果。目前,美团的搜索排序流程为多层排序,分别是粗排、精排、异构排序等,多层排序的流程主要是为了平衡效果和性能。搜索核心精排策略是 DNN 模型,美团搜索始终贴近业务,并且结合先进技术,从特征、模型结构、优化目标角度对排序效果进行了全面的优化。
近些年,基于 Transformer[1] 的一些 NLP 模型大放光彩,比如 BERT[2] 等等(可参考《美团BERT的探索和实践》),将 Transformer 结构应用于搜索推荐系统也成为业界的一个潮流。比如应用于对 CTR 预估模型进行特征组合的 AutoInt[3]、行为序列建模的 BST[4] 以及重排序模型 PRM[5],这些工作都证明了 Transformer 引入搜索推荐领域能取得不错的效果,所以美团搜索核心排序也在 Transformer 上进行了相关的探索。
本文旨在分享 Transformer 在美团搜索排序上的实践经验。内容会分为以下三个部分:第一部分对 Transformer 进行简单介绍,第二部分会介绍 Transfomer 在美团搜索排序上的应用以及实践经验,最后一部分是总结与展望。希望能对大家有所帮助和启发。
Transformer 简介
Transformer 是谷歌在论文《Attention is all you need》[1] 中提出来解决 Sequence to Sequence 问题的模型,其本质上是一个编解码(Encoder-Decoder )结构,编码器 Encoder 由 6 个编码 block 组成,Encoder 中的每个 block 包含 Multi-Head Attention 和 FFN(Feed-Forward Network);同样解码器 Decoder 也是 6 个解码 block 组成,每个 block 包含 Multi-Head Attention、Encoder-Decoder Attention 和 FFN。具体结构如图 1 所示,其详细的介绍可参考文献[1,6]。
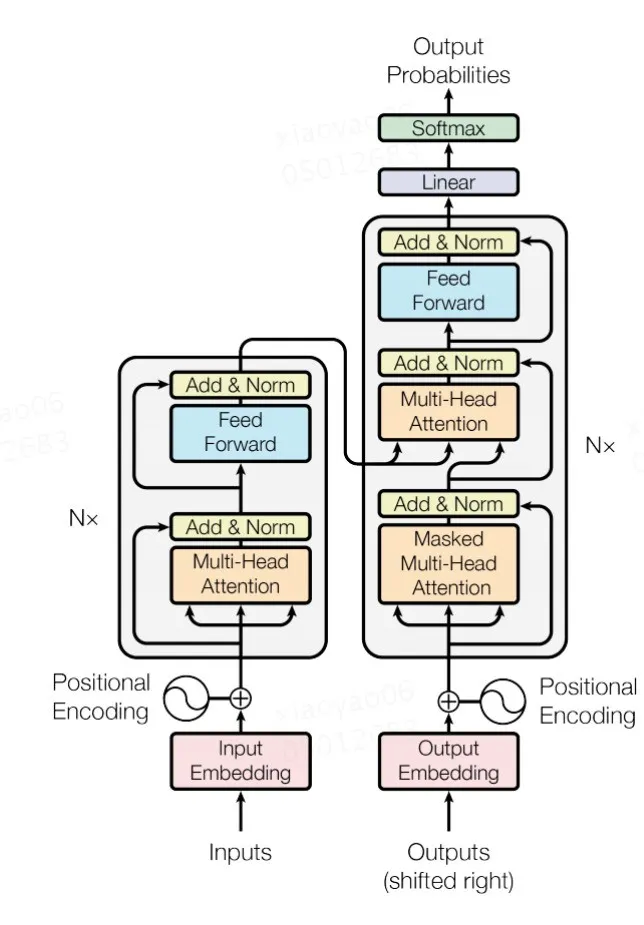
图 1 Transformer 结构示意图
考虑到后续内容出现的 Transformer Layer 就是 Transformer 的编码层,这里先对它做简单的介绍。它主要由以下两部分组成。
Multi-Head Attention
Multi-Head Attention 实际上是 h 个 Self-Attention 的集成, h 代表头的个数。其中 Self-Attention 的计算公式如下:
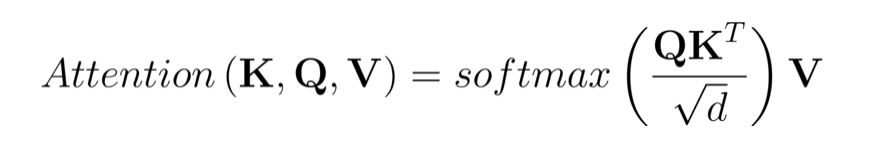
其中,Q 代表查询,K 代表键,V 代表数值。
在我们的应用实践中,原始输入是一系列 Embedding 向量构成的矩阵 E,矩阵 E 首先通过线性投影:
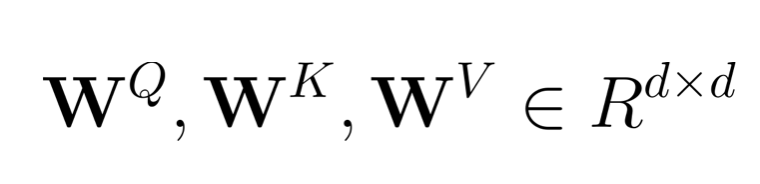
得到三个矩阵:

然后将投影后的矩阵输入到 Multi-Head Attention。计算公式如下:
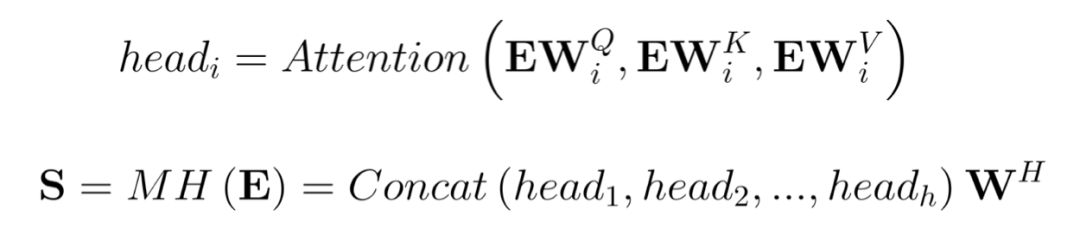
Point-wise Feed-Forward Networks
该模块是为了提高模型的非线性能力提出来的,它就是全连接神经网络结构,计算公式如下:
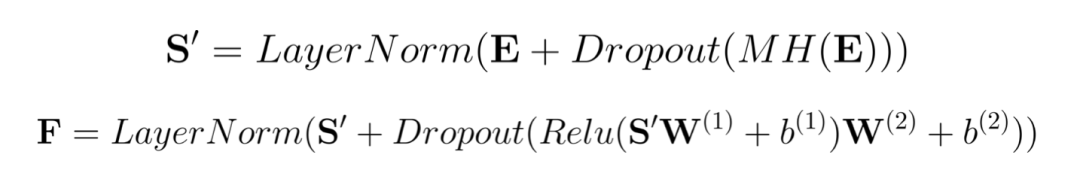
Transformer Layer 就是通过这种自注意力机制层和普通非线性层来实现对输入信号的编码,得到信号的表示。
美团搜索排序 Transformer 实践经验
Transformer 在美团搜索排序上的实践主要分以下三个部分:第一部分是特征工程,第二部分是行为序列建模,第三部分是重排序。下面会逐一进行详细介绍。
特征工程
在搜索排序系统中,模型的输入特征维度高但稀疏性很强,而准确的交叉特征对模型的效果又至关重要。所以寻找一种高效的特征提取方式就变得十分重要,我们借鉴 AutoInt[3] 的方法,采用 Transformer Layer 进行特征的高阶组合。
模型结构
我们的模型结构参考 AutoInt[3] 结构,但在实践中,根据美团搜索的数据特点,我们对模型结构做了一些调整,如下图 2 所示:
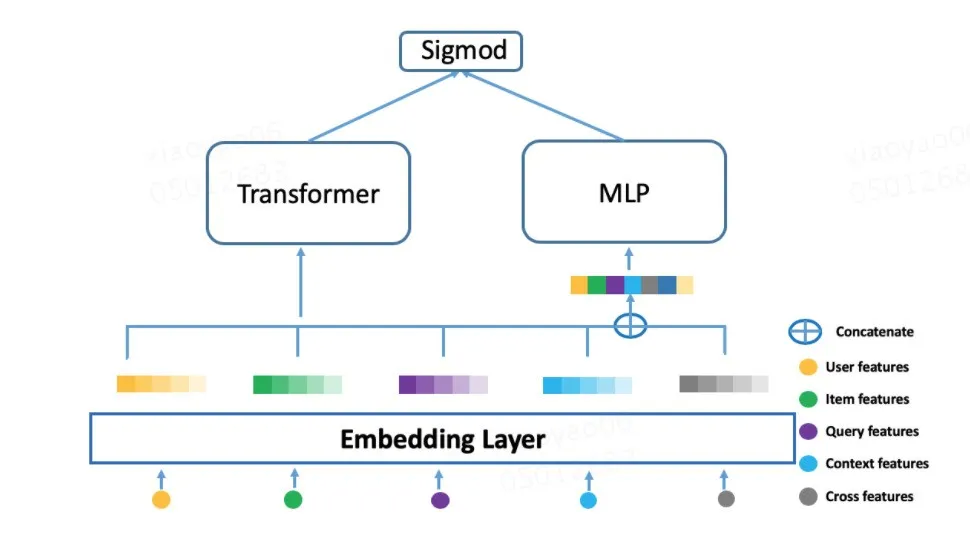
图 2 Transformer & Deep 结构示意图
相比 AutoInt[3],该结构有以下不同:
保留将稠密特征和离散特征的 Embedding 送入到 MLP 网络,以隐式的方式学习其非线性表达。
Transformer Layer 部分,不是送入所有特征的 Embedding,而是基于人工经验选择了部分特征的 Embedding,第一点是因为美团搜索场景特征的维度高,全输入进去会提高模型的复杂度,导致训练和预测都很慢;第二点是,所有特征的 Embedding 维度不完全相同,也不适合一起输入到 Transformer Layer 。
Embedding Layer 部分:众所周知在 CTR 预估中,除了大规模稀疏 ID 特征,稠密类型的统计特征也是非常有用的特征,所以这部分将所有的稠密特征和稀疏 ID 特征都转换成 Embedding 表示。
Transformer 部分:针对用户行为序列、商户 、品类 、地理位置等 Embedding 表示,使用 Transformer Layer 来显示学习这些特征的交叉关系。
MLP 部分:考虑到 MLP 具有很强的隐式交叉能力,将所有特征的 Embedding 表示 concat 一起输入到 MLP。
实践效果及经验
效果:离线效果提升,线上 QV_CTR 效果波动。
经验:
三层 Transformer 编码层效果比较好。
调节多头注意力的“头”数对效果影响不大 。
Transformer 编码层输出的 Embedding 大小对结果影响不大。
Transformer 和 MLP 融合的时候,最后结果融合和先 concat 再接一个全连接层效果差不多。
行为序列建模
理解用户是搜索排序中一个非常重要的问题。过去,我们对训练数据研究发现,在训练数据量很大的情况下,item 的大部分信息都可以被 ID 的 Embedding 向量进行表示,但是用户 ID 在训练数据中是十分稀疏的,用户 ID 很容易导致模型过拟合,所以需要大量的泛化特征来较好的表达用户。这些泛化特征可以分为两类:一类是偏静态的特征,例如用户的基本属性(年龄、性别、职业等等)特征、长期偏好(品类、价格等等)特征;另一类是动态变化的特征,例如刻画用户兴趣的实时行为序列特征。而用户实时行为特征能够明显加强不同样本之间的区分度,所以在模型中优化用户行为序列建模是让模型更好理解用户的关键环节。
目前,主流方法是采用对用户行为序列中的 item 进行 Sum-pooling 或者 Mean-pooling 后的结果来表达用户的兴趣,这种假设所有行为内的 item 对用户的兴趣都是等价的,因而会引入一些噪声。尤其是在美团搜索这种交互场景,这种假设往往是不能很好地进行建模来表达用户兴趣。
近年来,在搜索推荐算法领域,针对用户行为序列建模取得了重要的进展:DIN 引入注意力机制,考虑行为序列中不同 item 对当前预测 item 有不同的影响[7];而 DIEN 的提出,解决 DIN 无法捕捉用户兴趣动态变化的缺点[8]。DSIN 针对 DIN 和 DIEN 没有考虑用户历史行为中的 Session 信息,因为每个 Session 中的行为是相近的,而在不同 Session 之间的差别很大,它在 Session 层面上对用户的行为序列进行建模[9];BST 模型通过 Transformer 模型来捕捉用户历史行为序列中的各个 item 的关联特征,与此同时,加入待预测的 item 来达到抽取行为序列中的商品与待推荐商品之间的相关性[4]。这些已经发表过的工作都具有很大的价值。接下来,我们主要从美团搜索的实践业务角度出发,来介绍 Transformer 在用户行为序列建模上的实践。
模型结构
在 Transformer 行为序列建模中,我们迭代了三个版本的模型结构,下面会依次进行介绍。
模型主要构成:所有特征(user 维度、item 维度、query 维度、上下文维度、交叉维度)经过底层 Embedding Layer 得到对应的 Embedding 表示;建模用户行为序列得到用户的 Embedding 表示;所有 Embedding concat 一起送入到三层的 MLP 网络。
第一个版本:因为原来的 Sum-pooling 建模方式没有考虑行为序列内部各行为的关系,而 Transformer 又被证明能够很好地建模序列内部之间的关系,所以我们尝试直接将行为序列输入到 Transformer Layer,其模型结构如图 3 所示:
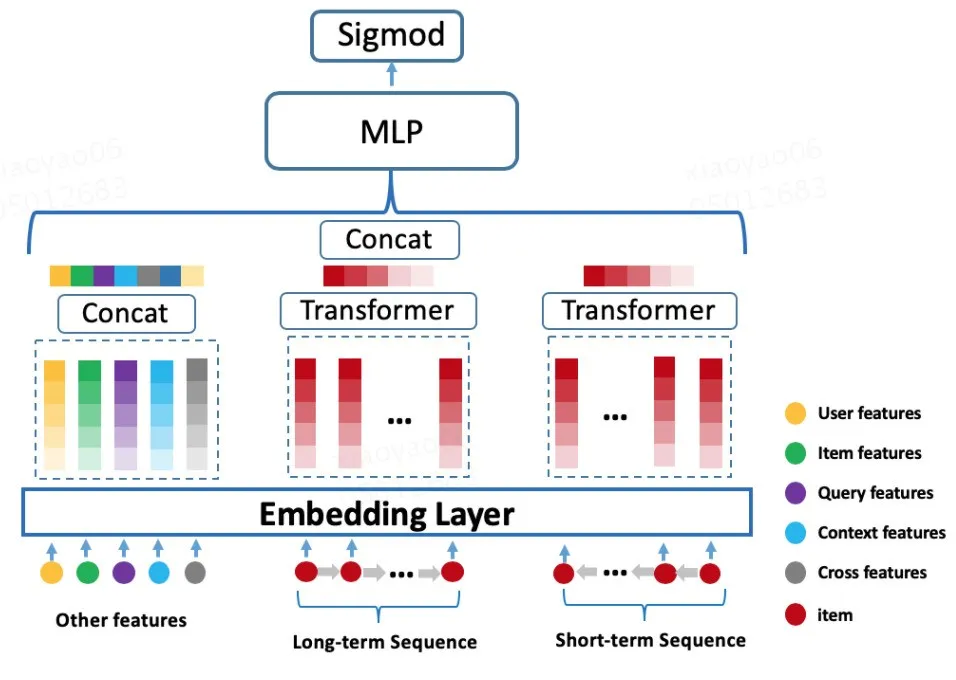
图 3 Transformer 行为序列建模
行为序列建模模块
输入部分
分为短期行为序列和长期行为序列。
行为序列内部的每个行为原始表示是由商户 ID,以及一些商户泛化信息的 Embedding 进行 concat 组成。
每段行为序列的长度固定,不足部分使用零向量进行补齐。
输出部分
对 Transformer Layer 输出的向量做 Sum-pooling (这里尝试过 Mean-pooling、concat,效果差不多)得到行为序列的最终 Embedding 表示。
该版本的离线指标相比线上 Base(行为序列 Sum-pooling) 模型持平,尽管该版本没有取得离线提升,但是我们继续尝试优化。
第二个版本:第一个版本存在一个问题,对所有的 item 打分的时候,用户的 Embedding 表示都是一样的,所以参考 BST[4],在第一个版本的基础上引入 Target-item,这样可以学习行为序列内部的 item 与 Target-item 的相关性,这样在对不同的 item 打分时,用户的 Embedding 表示是不一样的,其模型结构如下图 4 所示:
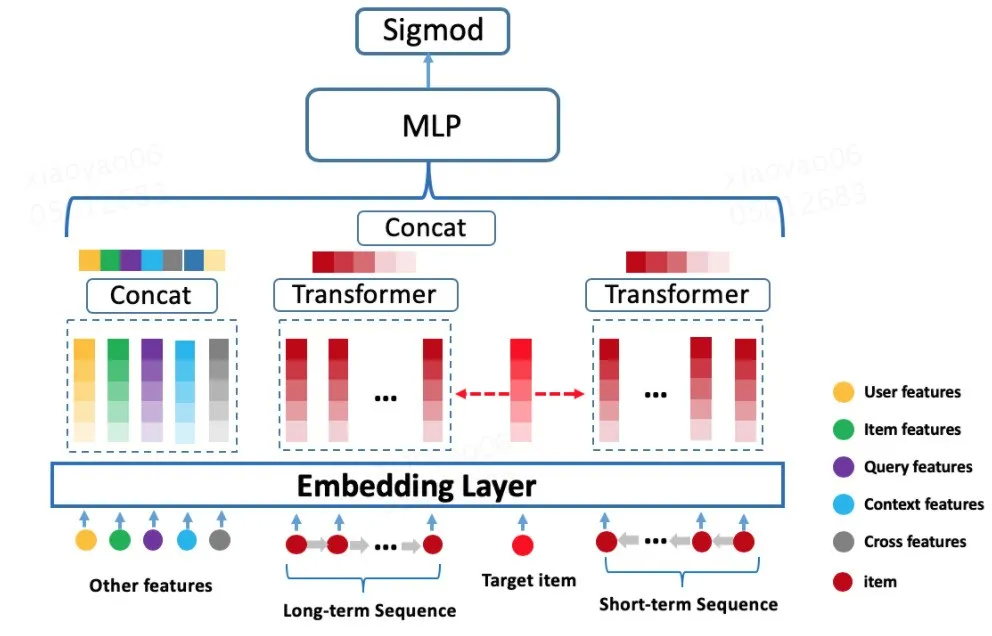
图 4 Transformer 行为序列建模
该版本的离线指标相比线上 Base(行为序列 Sum-pooling) 模型提升,上线发现效果波动,我们仍然没有灰心,继续迭代优化。
第三个版本:和第二个版本一样,同样针对第一个版本存在的对不同 item 打分,用户 Embedding 表示一样的问题,尝试在第一个版本引入 Transformer 的基础上,叠加 DIN[7] 模型里面的 Attention-pooling 机制来解决该问题,其模型结构如图 5 所示:
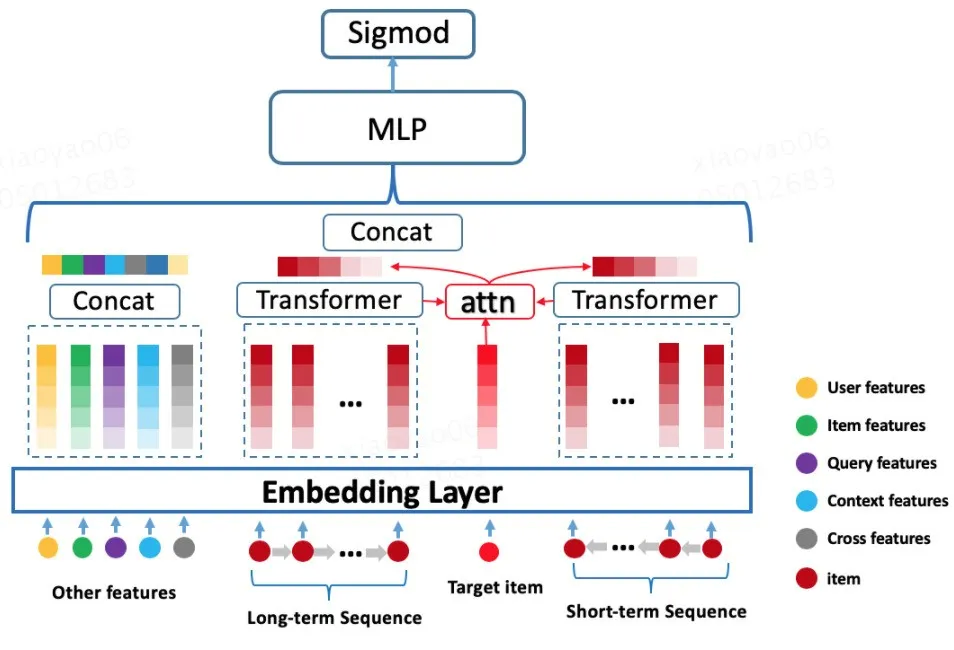
图 5 Transformer 行为序列建模
该版本的离线指标相比第二个版本模型有提升,上线效果相比线上 Base(行为序列 Sum-pooling)有稳定提升。
实践效果及经验
效果:第三个版本(Transformer + Attention-pooling)模型的线上 QV_CTR 和 NDCG 提升最为显著。
经验:
Transformer 编码为什么有效?Transformer 编码层内部的自注意力机制,能够对序列内 item 的相互关系进行有效的建模来实现更好的表达,并且我们离线实验不加 Transformer 编码层的 Attention-pooling,发现离线 NDCG 下降,从实验上证明了 Transformer 编码有效。
Transformer 编码为什么优于 GRU ?忽略 GRU 的性能差于 Transformer;我们做过实验将行为序列长度的上限往下调,Transformer 的效果相比 GRU 的效果提升在缩小,但是整体还是行为序列的长度越大越好,所以 Transformer 相比 GRU 在长距离时,特征捕获能力更强。
位置编码(Pos-Encoding)的影响:我们试过加 Transformer 里面原生的正余弦以及距当前预测时间的时间间隔的位置编码都无效果,分析应该是我们在处理行为序列的时候,已经将序列切割成不同时间段,一定程度上包含了时序位置信息。为了验证这个想法,我们做了仅使用一个长序列的实验(对照组不加位置编码,实验组加位置编码,离线 NDCG 有提升),这验证了我们的猜测。
Transformer 编码层不需要太多,层数过多导致模型过于复杂,模型收敛慢效果不好。
调节多头注意力的“头”数对效果影响不大。
重排序
在引言中,我们提到美团搜索排序过去做了很多优化工作,但是大部分都是集中在 PointWise 的排序策略上,未能充分利用商户展示列表的上下文信息来优化排序。一种直接利用上下文信息优化排序的方法是对精排的结果进行重排,这可以抽象建模成一个序列(排序序列)生成另一个序列(重排序列)的过程,自然联想到可以使用 NLP 领域常用的 Sequence to Sequence 建模方法进行重排序建模。
目前业界已有一些重排序的工作,比如使用 RNN 重排序[10-11]、Transformer 重排序[5]。考虑到 Transformer 相比 RNN 有以下两个优势:(1)两个 item 的相关性计算不受距离的影响 (2)Transformer 可以并行计算,处理效率比 RNN 更高;所以我们选择 Transformer 对重排序进行建模。
模型结构
模型结构参考了 PRM[5],结合美团搜索实践的情况,重排序模型相比 PRM 做了一些调整。具体结构如图 6 所示,其中 D1,D2,…,Dn 是重排商户集合,最后根据模型的输出 Score(D1),Score(D2),…,Score(Dn)按照从大到小进行排序。
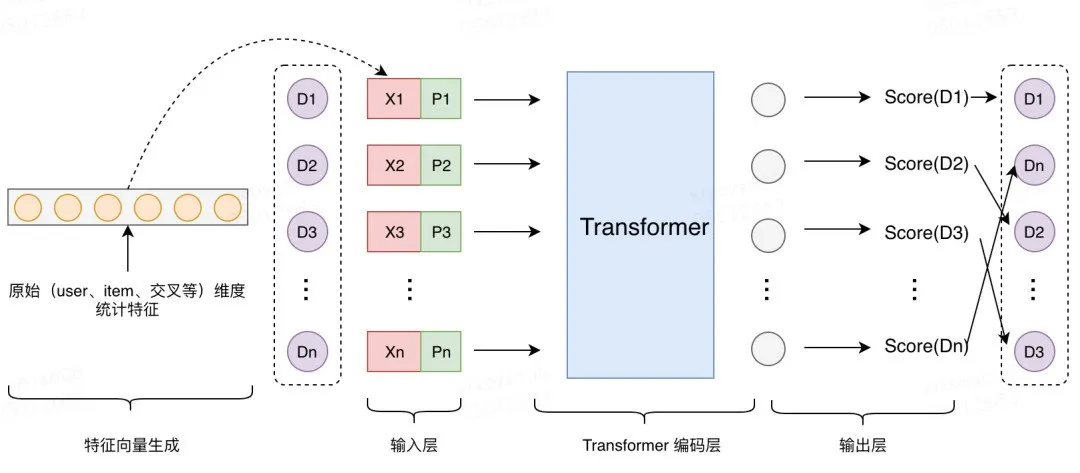
图 6 Transformer 重排序
主要由以下几个部分构成:
特征向量生成:由原始特征(user、item、交叉等维度的稠密统计特征)经过一层全连接的输出进行表示。
输入层:其中 X 表示商户的特征向量,P 表示商户的位置编码,将特征向量 X 与位置向量 P 进行 concat 作为最终输入。
Transformer 编码层:一层 Multi-Head Attention 和 FFN 的。
输出层:一层全连接网络得到打分输出 Score。
模型细节:
特征向量生成部分和重排序模型是一个整体,联合端到端训练。
训练和预测阶段固定选择 TopK 进行重排,遇到某些请求曝光 item 集不够 TopK 的情况下,在末尾补零向量进行对齐。
实践效果及经验
效果:Transformer 重排序对线上 NDCG 和 QV_CTR 均稳定正向提升。
经验:
重排序大小如何选择?考虑到线上性能问题,重排序的候选集不能过大,我们分析数据发现 95% 的用户浏览深度不超过 10,所以我们选择对 Top10 的商户进行重排。
位置编码向量的重要性:这个在重排序中很重要,需要位置编码向量来刻画位置,更好的让模型学习出上下文信息,离线实验发现去掉位置向量 NDCG@10 下降明显。
性能优化:最初选择商户全部的精排特征作为输入,发现线上预测时间太慢;后面进行特征重要性评估,筛选出部分重要特征作为输入,使得线上预测性能满足上线要求。
调节多头注意力的“头”数对效果影响不大。
总结和展望
2019 年底,美团搜索对 Transformer 在排序中的应用进行了一些探索,既取得了一些技术沉淀也在线上指标上取得比较明显的收益,不过未来还有很多的技术可以探索。
在特征工程上,引入 Transformer 层进行高阶特征组合虽然没有带来收益,但是在这个过程中也再次验证了没有万能的模型对所有场景数据有效。目前搜索团队也在探索在特征层面应用 BERT 对精排模型进行优化。
在行为序列建模上,目前的工作集中在对已有的用户行为数据进行建模来理解用户,未来要想更加深入全面的认识用户,更加丰富的用户数据必不可少。当有了这些数据后如何进行利用,又是一个可以探索的技术点,比如图神经网络建模等等。
在重排序建模上,目前引入 Transformer 取得了一些效果,同时随着强化学习的普及,在美团这种用户与系统强交互的场景下,用户的行为反馈蕴含着很大的研究价值,未来利用用户的实时反馈信息进行调序是个值得探索的方向。例如,根据用户上一刻的浏览反馈,对用户下一刻的展示结果进行调序。
除了上面提到的三点,考虑到美团搜索上承载着多个业务,比如美食、到综、酒店、旅游等等,各个业务之间既有共性也有自己独有的特性,并且除了优化用户体验,也需要满足业务需求。为了更好的对这一块建模优化, 我们也正在探索 Partition Model 和多目标相关的工作,欢迎业界同行一起交流。
参考资料
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[2] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv:1810.04805, 2018.
[3] Song W, Shi C, Xiao Z, et al. Autoint: Automatic feature interaction learning via self-attentive neural networks[C]//Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019: 1161-1170.
[4] Chen Q, Zhao H, Li W, et al. Behavior sequence transformer for e-commerce recommendation in Alibaba[C]//Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data. 2019: 1-4.
[5] Pei C, Zhang Y, Zhang Y, et al. Personalized re-ranking for recommendation[C]//Proceedings of the 13th ACM Conference on Recommender Systems. 2019: 3-11.
[6] http://jalammar.github.io/illustrated-transformer/
[7] Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2018: 1059-1068.
[8] Zhou G, Mou N, Fan Y, et al. Deep interest evolution network for click-through rate prediction[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33: 5941-5948.
[9] Feng Y, Lv F, Shen W, et al. Deep Session Interest Network for Click-Through Rate Prediction[J]. arXiv:1905.06482, 2019.
[10] Zhuang T, Ou W, Wang Z. Globally optimized mutual influence aware ranking in e-commerce search[J]. arXiv:1805.08524, 2018.
[11] Ai Q, Bi K, Guo J, et al. Learning a deep listwise context model for ranking refinement[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 2018: 135-144.
作者介绍:
肖垚,家琪,周翔,陈胜,云森,永超,仲远等,均来自美团 AI 平台搜索与 NLP 部。
本文转载自公众号美团技术团队(ID:meituantech)。
原文链接:
https://mp.weixin.qq.com/s/Oixc46P9rQeiMDjI-0j0cw

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论