

机器学习模型正在被越来越多地部署在任务关键型系统中,比如自动驾驶汽车。然而,这些模型可能会因为各种复杂的原因失效,应用程序开发人员必须找到调试这些模型的方法。我们建议在 ML 模型调试任务中使用软件断言。有了模型断言,ML 开发人员就可以为模型输出指定特定的约束。模型断言可以是确定性的或者“模糊的”,即概率性的。我们提出了几种在 ML 调试中使用模型断言的方法,包括运行时监控、执行纠正动作,或进行“硬采样”,通过人为标记和弱监督学习进一步训练模型。在视频分析任务中,我们发现简单的断言可以有效地发现错误,而且纠正规则可以有效地纠正模型输出(分别高达 100%和 90%的准确性)。另外,我们还收集和标记了部分会触发断言的视频,并发现这个过程可以将模型性能提高 2 倍。
机器学习在现实世界中已经得到了越来越广泛的应用,比如在自动驾驶汽车或医疗保健领域。然而,ML 模型可能会失败,而且失败的方式混乱而复杂。我们认为,开发可靠的工具来确保模型质量和不断改进模型是至关重要的,特别是当 ML 被部署在关键型任务系统中时。
机器学习质量保证的前期工作主要集中在训练数据验证和清理、训练数据可视化和形式验证等方面。
这篇文章将介绍如何通过软件断言来监控 ML 模型和收集数据,并以此来改进 ML 模型。与以前的工作相反,模型断言允许领域专家在不了解 ML 模型内部结构的情况下指定模型输出的结构约束。
与 ML 类似,传统软件也可能很复杂,它们可能已经被成功地部署在医疗设备和宇宙飞船等关键型任务系统中。这些成功的部署在一定程度上要归功于严格的质量保证工具——包括断言、单元测试、冒烟测试和回归测试。这篇文章将着重介绍如何在 ML 应用程序中使用模型断言,包括在部署阶段监控模型,以及在训练阶段改进模型。
什么是模型断言
模型断言将传统的程序断言应用在 ML 部署中。传统的程序断言(例如,assert(len(array) > 0))可以用来检查程序状态的不变性。它们是传统软件的第一道防线,可以显著减少 bug 的数量。相反,模型断言允许领域专家为机器学习模型指定输入和输出约束。与使用传统断言的方式类似,我们可以使用模型断言来监控模型。此外,还有一些用于在 ML 上下文中使用断言的方法,通过主动学习和弱监督来提高模型精度。
示例
在视频分析场景中,用户可能会运行预训练的对象检测模型(如 SSD)来识别实体(如汽车)。这些模型存在常见的闪烁问题,即模型可能会看到对象在连续帧之间消失了,导致结果不精确。下面的视频就演示了这个问题,汽车周围的边框在连续的帧之间忽明忽暗:

虽然模型的内部很复杂,但对模型的输出进行简单的断言可以很容易地检测出这个错误。对象检测模型会在每帧输出一个边框列表。如果在第 n 帧出现了一个边框,断言需要检查最近的帧中是否也出现了边框,以及预测中是否出现了空白。下面的 Python 伪代码展示了如何通过编程检查不正确的闪烁行为:
这里使用了一个原型断言系统实现了闪烁检查。除了识别闪烁之外,还有检查其他不正确行为的断言,比如多个对象的重叠或嵌套。
如何使用模型断言
以下是在运行阶段和训练阶段使用模型断言的四种方法。
运行时监控:模型断言可以被用在分析管道中,用来收集与不正确行为相关的统计信息,以便确定模型可能会出现哪些类别的错误。
纠正动作:在运行时,如果发生模型断言,就会触发纠正动作,例如将控制权返回给人类操作员。
主动学习:可以通过断言找到导致模型失败的输入。分析人员可以找出触发闪烁断言的帧,对它们进行人工重新标记,然后使用这些帧重新训练模型。
弱监督:如果进行人工标记的成本很高,可以将断言与简单的自动纠正规则关联起来,这些规则会自动重新标记不正确的模型输出。对于闪烁问题,纠正规则可以通过在相邻帧之间插入边框来填充缺少的边框,如下图所示。这些被自动标记的帧可以用来重新训练模型。

通过断言来改进模型质量
上面的内容已经评估了使用断言来改进对象检测模型的有效性。要对结果进行更全面的评估,还需要断言的准确性,具体请参阅研讨会论文(https://ddkang.github.io/papers/2018/omg-nips-ws.pdf)。
数据集包含了怀俄明州一个十字路口安全摄像头拍摄的数天视频数据。为了评估模型断言,我们使用断言来训练 SSD,并对 MS-COCO 进行预训练。通过与 Mask-RCNN(https://arxiv.org/pdf/1703.06870.pdf)进行比较,我们获得了再训练模型相对于基线预训练模型的准确性。
我们基于第一天的视频数据运行预训练模型,并将其作为基线。然后,我们针对这些输出运行断言,以便捕获触发这些错误的帧。在主动学习实验中,我们使用事实数据重新标记了这些帧。在弱监督实验中,我们构造了一个纠正规则,在缺失边框的相邻帧中插入边框,并基于该规则对不正确帧进行重新标记。然后,我们使用这些重新标记的帧对基线模型进行再训练,以此来改进基线模型。
定量改进
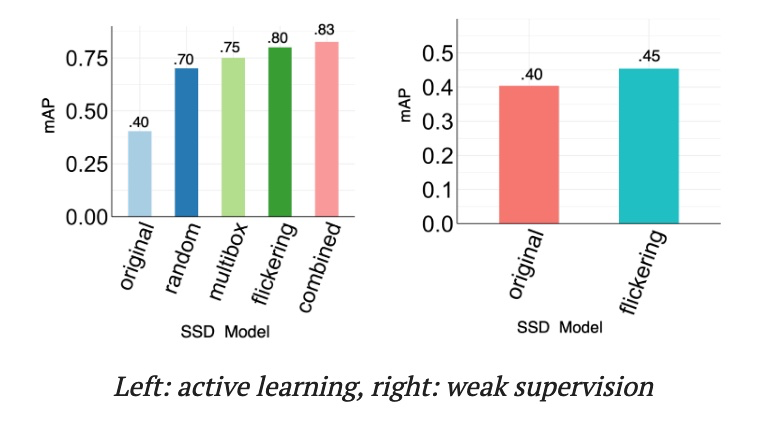
下图显示了主动学习和弱监督对提高模型精度的作用。基线模型达到了 0.4 mAP,这是用来判断目标检测模型精度度的一个常用指标。
主动学习:对于主动学习,我们还将随机采样帧作为简单基线与再训练进行比较。我们发现,使用触发每个断言的帧进行再训练,并结合使用两个断言,可以在 mAP 方面获得比预训练模型和随机基线更大的改进。
弱监督:如果使用事实标签的成本非常高,可以使用闪烁断言和相关的纠正规则对模型进行再训练,这样也可以改进 mAP。
为了了解使用模型断言作为主动学习或弱监督的形式是否可以改进模型性能,我们收集了 9 小时视频中每个触发断言的帧和随机帧作为训练数据。我们精挑细选了以下的 SSD 变种,在 MS-COCO 上使用 2000 帧进行预训练:
使用 1000 个触发闪烁断言的帧和 1000 个随机帧训练 SSD,并通过弱监督进行标记。
使用 2000 个随机帧训练 SSD,并通过主动学习进行标记,作为基线。
使用 1000 个触发闪烁断言的帧和 1000 个随机帧训练 SSD,并通过主动学习进行标记。
使用 600 个触发多边框断言的帧和 1400 个随机帧训练 SSD,并通过主动学习进行标记。
使用 1000 个触发闪烁断言的帧、600 个触发多边框闪烁断言的帧和 1000 个随机帧训练 SSD,并通过主动学习进行标记。

各种 SSD 的性能比较。可以看到,弱监督和主动学习都可以提高 SSD 的性能,而基于断言的主动学习要优于随机标记。
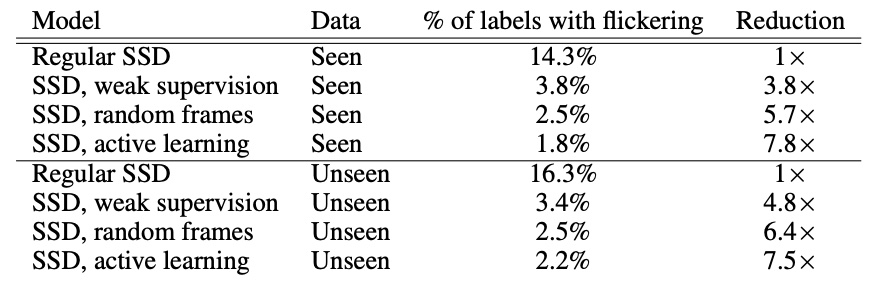
各种 SSD 出现的闪烁帧数。可以看到,经过重新训练,闪烁的帧数减少了,而且基于断言的主动学习要优于随机标记。
定性改进
下面的两个视频分别展示了基线预训练模型(上)和最佳再训练模型(下)。再训练模型使用了两个断言进行主动学习再训练,并标记了视频的一个片段。我们可以看到,再训练的模型错误更少,它不会产生闪烁或者不会包含不正确的重叠边框。

如果你也遇到了模型质量问题或希望尝试用模型断言方法改进模型,可以发送电子邮件至 modelassertions@cs.stanford.edu 与研究团队联系!
研究论文链接:
https://ddkang.github.io/papers/2018/omg-nips-ws.pdf
英文原文:
https://dawn.cs.stanford.edu//2019/03/11/modelassertions/

暂无签名

中国开源发展研究分析 2022
本次报告为开发者,技术管理者,开源社区运营、市场,开源办公室工作人员带来信息上的增量以及对开源趋势、...










评论 1 条评论