

近日,华为诺亚方舟实验室的一篇论文被 CVPR 2020 接受,该论文提出了一种新型的端侧神经网络架构 GhostNet,该架构在同样精度下,速度和计算量均少于 SOTA 算法。
该论文提供了一个全新的 Ghost 模块,旨在通过廉价操作生成更多的特征图。基于一组原始的特征图,作者应用一系列线性变换,以很小的代价生成许多能从原始特征发掘所需信息的“幻影”特征图(Ghost feature maps)。该 Ghost 模块即插即用,通过堆叠 Ghost 模块得出 Ghost bottleneck,进而搭建轻量级神经网络——GhostNet。在 ImageNet 分类任务,GhostNet 在相似计算量情况下 Top-1 正确率达 75.7%,高于 MobileNetV3 的 75.2%。
论文链接:https://arxiv.org/abs/1911.11907
开源地址:https://github.com/huawei-noah/ghostnet
引言
卷积神经网络推动了计算机视觉诸多任务的进步,比如图像识别、目标检测等。但是,神经网络在移动设备上的应用还亟待解决,主要原因是现有模型又大又慢。因而,一些研究提出了模型的压缩方法,比如剪枝、量化、知识蒸馏等;还有一些则着重于高效的网络结构设计,比如 MobileNet,ShuffleNet 等。本文就设计了一种全新的神经网络基本单元 Ghost 模块,从而搭建出轻量级神经网络架构 GhostNet。
在一个训练好的深度神经网络中,通常会包含丰富甚至冗余的特征图,以保证对输入数据有全面的理解。如下图所示,在 ResNet-50 中,将经过第一个残差块处理后的特征图拿出来,三个相似的特征图对示例用相同颜色的框注释。 该对中的一个特征图可以通过廉价操作(用扳手表示)将另一特征图变换而获得,可以认为其中一个特征图是另一个的“幻影”。因为,本文提出并非所有特征图都要用卷积操作来得到,“幻影”特征图可以用更廉价的操作来生成。
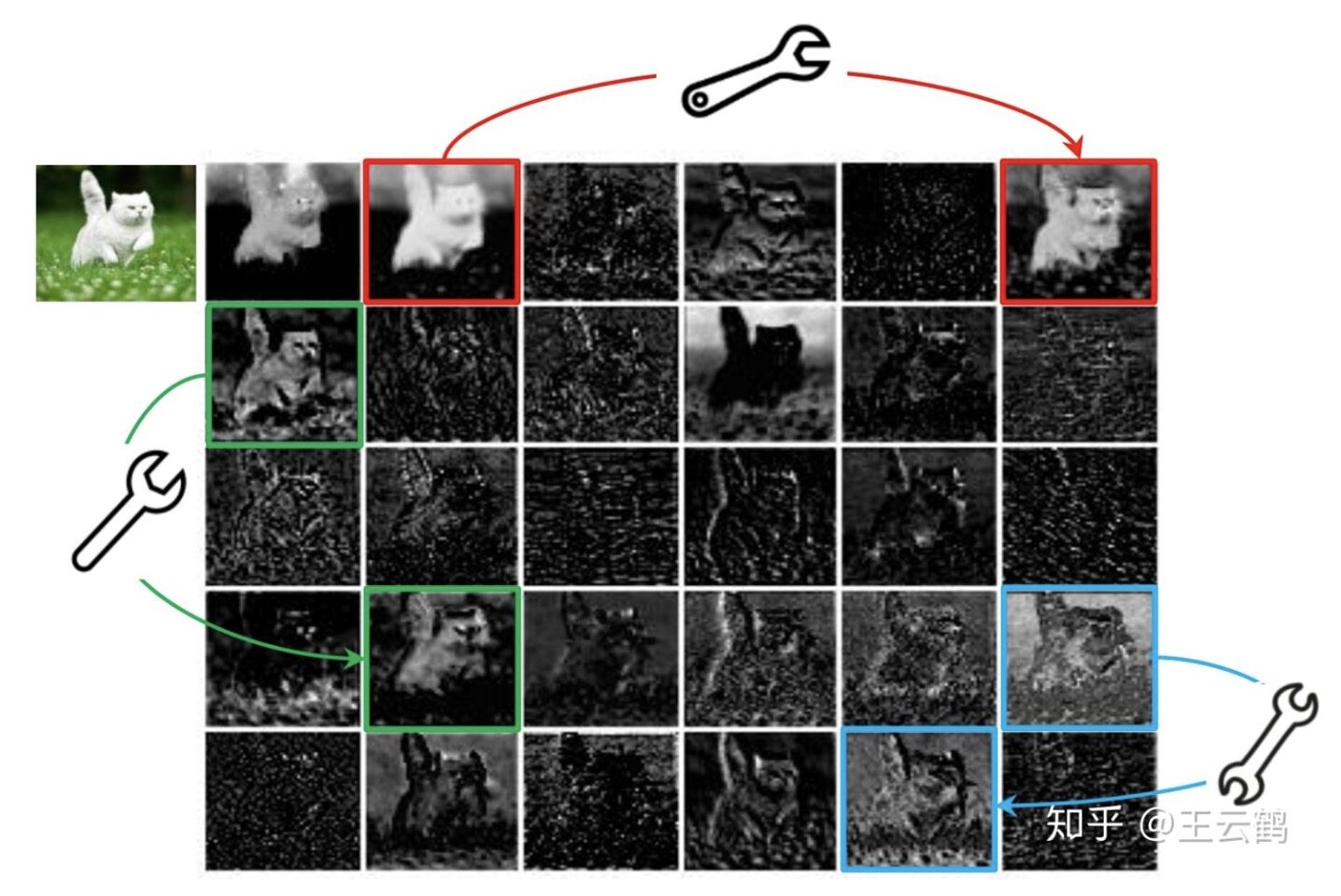
图 1 ResNet50 特征图可视化
在本文中,作者提出了一种新颖的 Ghost 模块,可以使用更少的参数来生成更多特征图。具体来说,深度神经网络中的普通卷积层将分为两部分。第一部分涉及普通卷积,但是将严格控制它们的总数。给定第一部分的固有特征图,然后将一系列简单的线性运算应用于生成更多特征图。与普通卷积神经网络相比,在不更改输出特征图大小的情况下,该 Ghost 模块中所需的参数总数和计算复杂度均已降低。基于 Ghost 模块,作者建立了一种有效的神经体系结构,即 GhostNet。作者首先在基准神经体系结构中替换原始的卷积层,以证明 Ghost 模块的有效性,然后在几个基准视觉数据集上验证 GhostNet 的优越性。实验结果表明,所提出的 Ghost 模块能够在保持相似识别性能的同时降低通用卷积层的计算成本,并且 GhostNet 可以超越 MobileNetV3 等先进的高效深度模型,在移动设备上进行快速推断。
方法
Ghost 模块

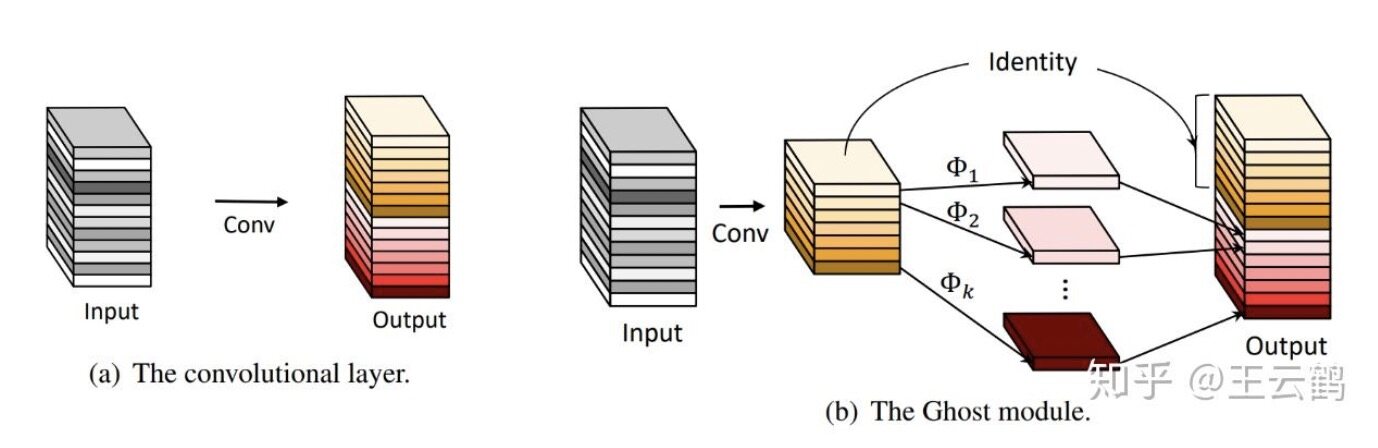
图 2 (a) 普通卷积层 (b) Ghost 模块

复杂度分析

构建 GhostNet
Ghost Bottleneck:利用 Ghost 模块的优势,作者介绍了专门为小型 CNN 设计的 Ghost bottleneck(G-bneck)。如图 3 所示,Ghost bottleneck 似乎类似于 ResNet 中的基本残差块(Basic Residual Block),其中集成了多个卷积层和 shortcut。Ghost bottleneck 主要由两个堆叠的 Ghost 模块组成。第一个 Ghost 模块用作扩展层,增加了通道数。这里将输出通道数与输入通道数之比称为 expansion ratio。第二个 Ghost 模块减少通道数,以与 shortcut 路径匹配。然后,使用 shortcut 连接这两个 Ghost 模块的输入和输出。这里借鉴了 MobileNetV2,第二个 Ghost 模块之后不使用 ReLU,其他层在每层之后都应用了批量归一化(BN)和 ReLU 非线性激活。上述 Ghost bottleneck 适用于 stride= 1,对于 stride = 2 的情况,shortcut 路径由下采样层和 stride = 2 的深度卷积(Depthwise Convolution)来实现。出于效率考虑,Ghost 模块中的初始卷积是点卷积(Pointwise Convolution)。
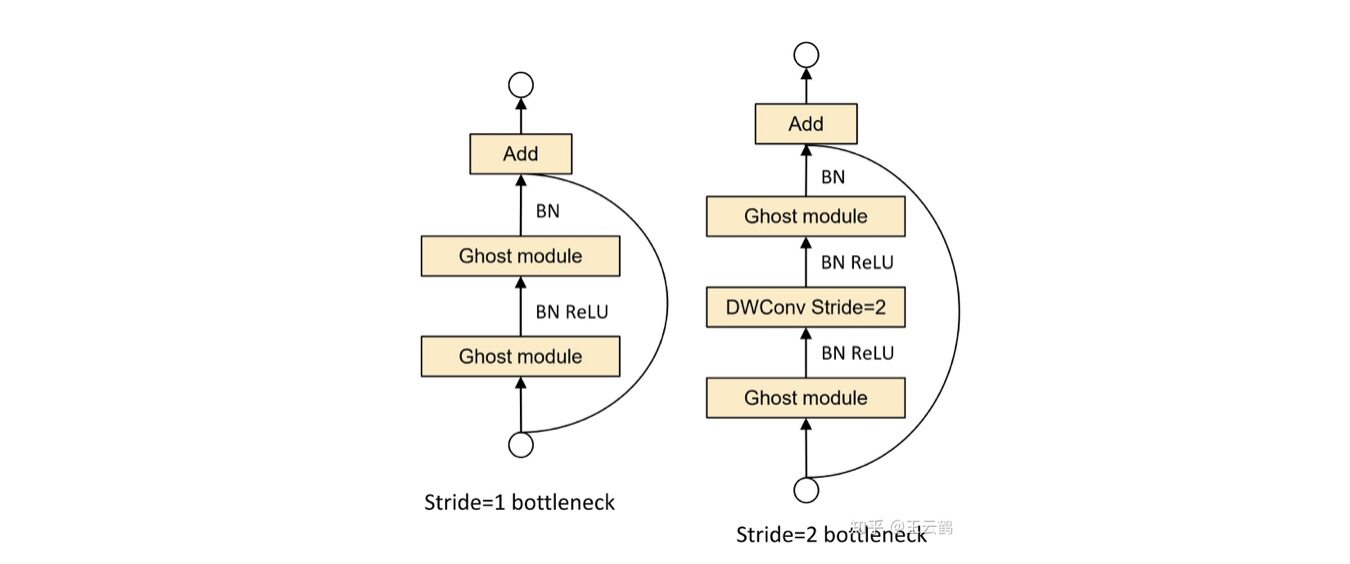
图 3 Ghost bottleneck
GhostNet:基于 Ghost bottleneck,作者提出 GhostNet,如表 1 所属。作者遵循 MobileNetV3 的基本体系结构的优势,然后使用 Ghost bottleneck 替换 MobileNetV3 中的 bottleneck。GhostNet 主要由一堆 Ghost bottleneck 组成,其中 Ghost bottleneck 以 Ghost 模块为构建基础。第一层是具有 16 个卷积核的标准卷积层,然后是一系列 Ghost bottleneck,通道逐渐增加。这些 Ghost bottleneck 根据其输入特征图的大小分为不同的阶段。除了每个阶段的最后一个 Ghost bottleneck 是 stride = 2,其他所有 Ghost bottleneck 都以 stride = 1 进行应用。最后,利用全局平均池和卷积层将特征图转换为 1280 维特征向量以进行最终分类。SE 模块也用在了某些 Ghost bottleneck 中的残留层,如表 1 中所示。与 MobileNetV3 相比,这里用 ReLU 换掉了 Hard-swish 激活函数。尽管进一步的超参数调整或基于自动架构搜索的 Ghost 模块将进一步提高性能,但表 1 所提供的架构提供了一个基本设计参考。
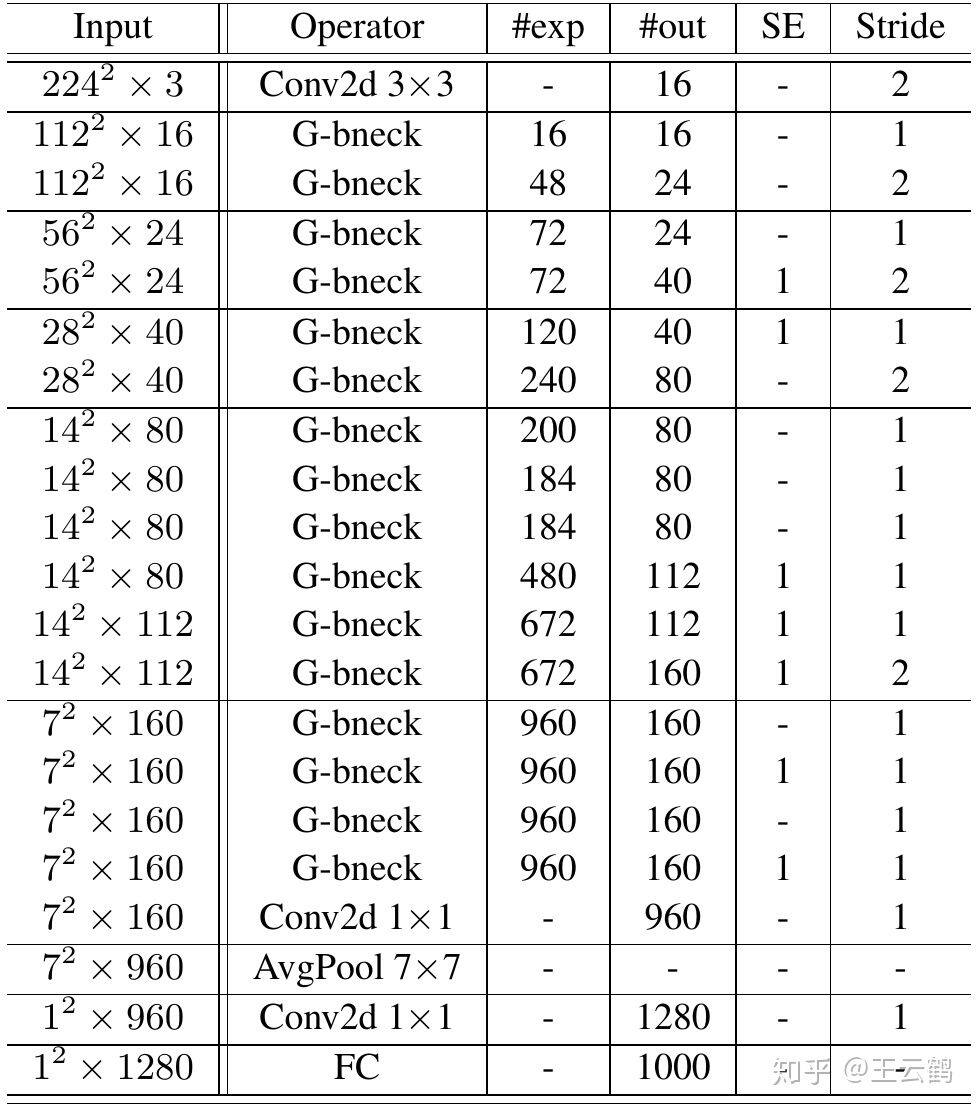
表 1 GhostNet 网络架构
实验
Ghost 模块消融实验
如上所述,Ghost 模块具有两个超参数,也就是,s 用于生成 m=n/s 个内在特征图,以及用于计算幻影特征图的线性运算的 d*d (即深度卷积核的大小)。作者测试了这两个参数的影响。
首先,作者固定 s=2 并在{1,3,5,7} 范围中调整 d,并在表 2 中列出 CIFAR-10 验证集上的结果。作者可以看到,当 d=3 的时候,Ghost 模块的性能优于更小或更大的 Ghost 模块。这是因为大小为 1X1 的内核无法在特征图上引入空间信息,而较大的内核(例如 d=5 或 d=7)会导致过拟合和更多计算。因此,在以下实验中作者采用 d=3 来提高有效性和效率。
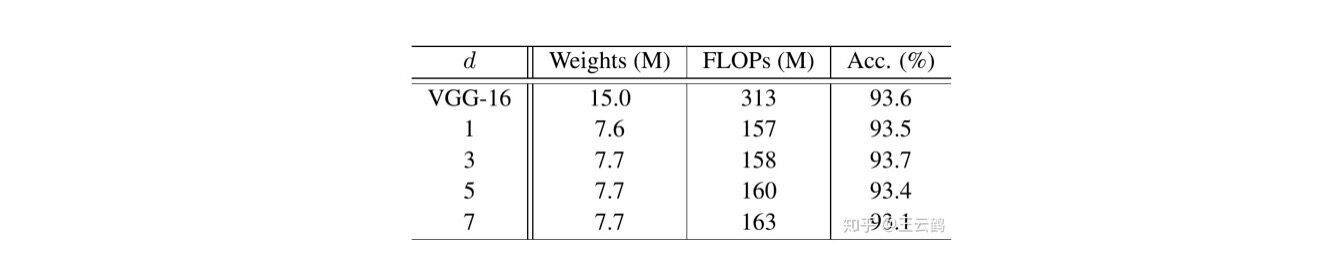
表 2 超参数 d 的影响
在研究了内核大小的影响之后,作者固定 d=3 并在{2,3,4,5} 的范围内调整超参数 s。实际上, s 与所得网络的计算成本直接相关,即,较大的 s 导致较大的压缩率和加速比。从表 3 中的结果可以看出,当作者增加 s 时,FLOP 显着减少,并且准确性逐渐降低,这是在预期之内的。特别地,当 s=2 ,也就是将 VGG-16 压缩 2x 时,Ghost 模块的性能甚至比原始模型稍好,表明了所提出的 Ghost 模块的优越性。

表 3 超参数 s 的影响
作者将 Ghost 模块用在 VGG-16 和 ResNet-56 架构上,然后和几个代表性的最新模型进行了比较。Ghost-VGG-16 (s=2)以最高的性能(93.7%)胜过竞争对手,但 FLOPs 明显减少。 对于已经比 VGG-16 小得多的 ResNet-56,基于 Ghost 模块的模型可以将计算量降低一半时获得可比的精度,还可以看到,其他具有相似或更大计算成本的最新模型所获得的准确性低于 Ghost 模型。
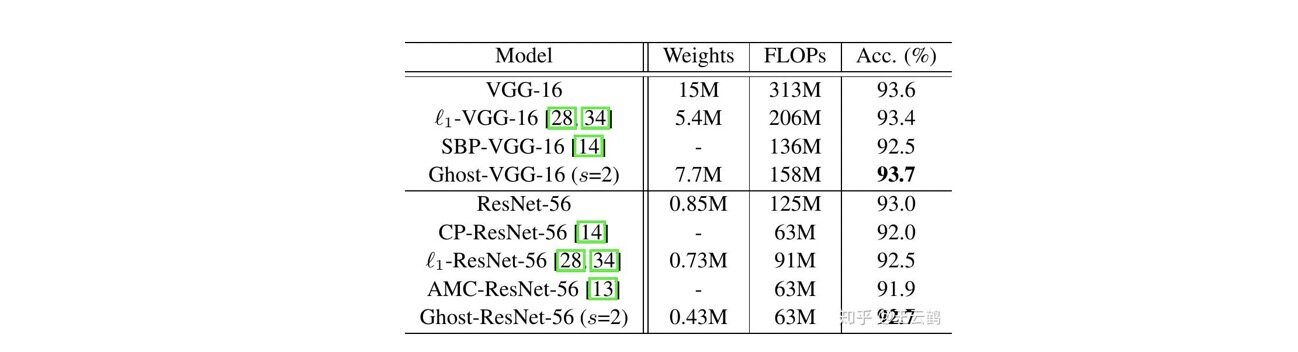
表 4 在 CIFAR-10 数据集和 SOTA 模型对比
特征图可视化
作者还可视化了 Ghost 模块的特征图,如图 4 所示。 图 4 展示了 Ghost-VGG-16 的第二层特征,左上方的图像是输入,左红色框中的特征图来自初始卷积,而右绿色框中的特征图是经过廉价深度变换后的幻影特征图。尽管生成的特征图来自原始特征图,但它们之间确实存在显着差异,这意味着生成的特征足够灵活,可以满足特定任务的需求。

图 4 Ghost-VGG-16 的第二层输出特征图可视化
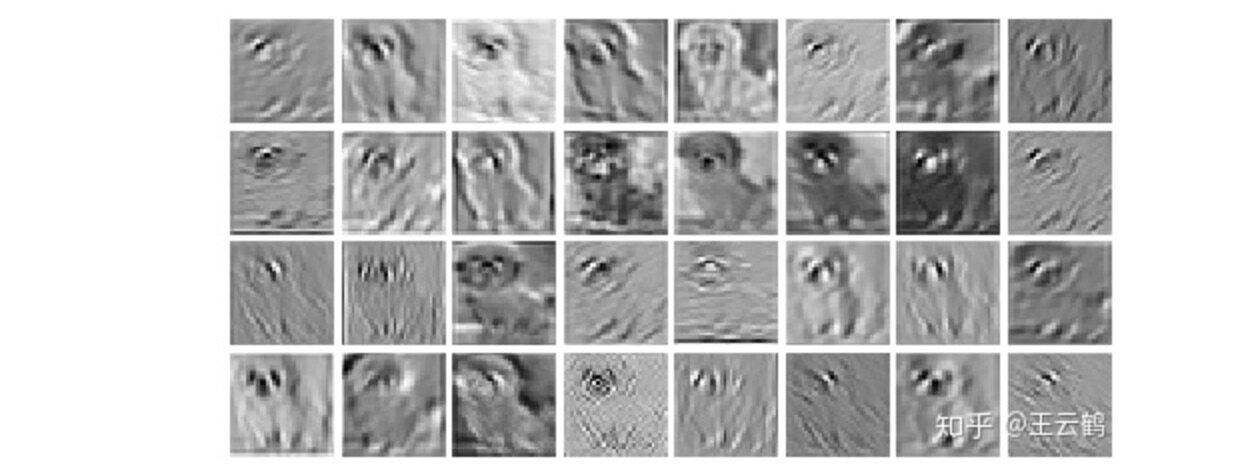
图 5 原始 VGG-16 的第二层输出特征图可视化
GhostNet 性能
ImageNet 分类数据集:为了验证所提出的 GhostNet 的优越性,作者对 ImageNet 分类任务进行了实验。在 ImageNet 验证集上报告的所有结果均是 single crop 的 top-1 的性能。对于 GhostNet,为简单起见,作者在初始卷积中设置了内核大小 k=1,在所有 Ghost 模块中设置了 s=2 和 d=3 。作者和现有最优秀的几种小型网络结构作对比,包括 MobileNet 系列、ShuffleNet 系列、IGCV3、ProxylessNAS、FBNet、MnasNet 等。结果汇总在表 5 中,这些模型分为 3 个级别的计算复杂性,即~50,~150 和 200-300 MFLOPs。从结果中我们可以看到,通常较大的 FLOPs 会在这些小型网络中带来更高的准确性,这表明了它们的有效性。而 GhostNet 在各种计算复杂度级别上始终优于其他竞争对手,主要是因为 GhostNet 在利用计算资源生成特征图方面效率更高。
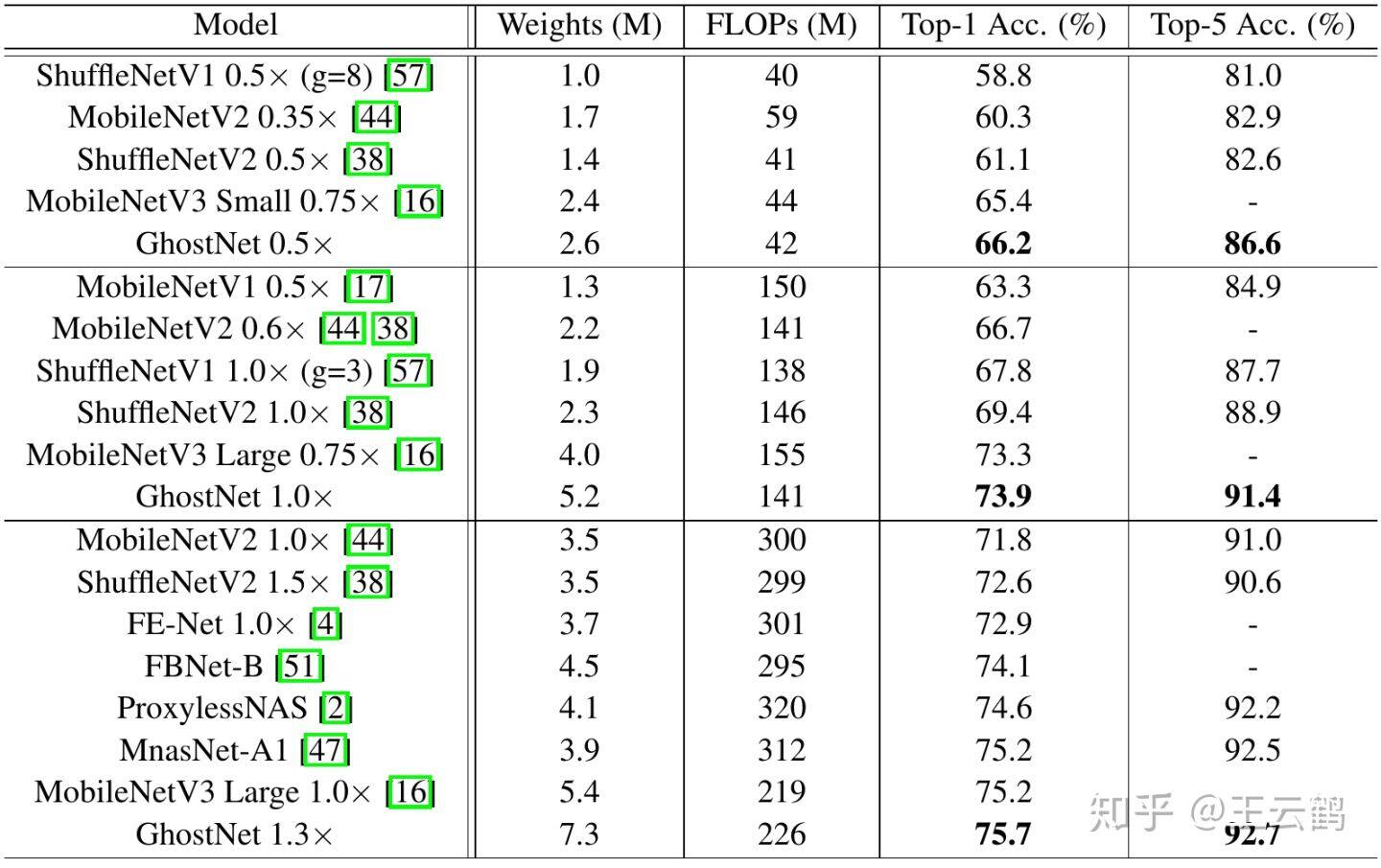
表 5 GhostNet 在 ImageNet 数据集的表现
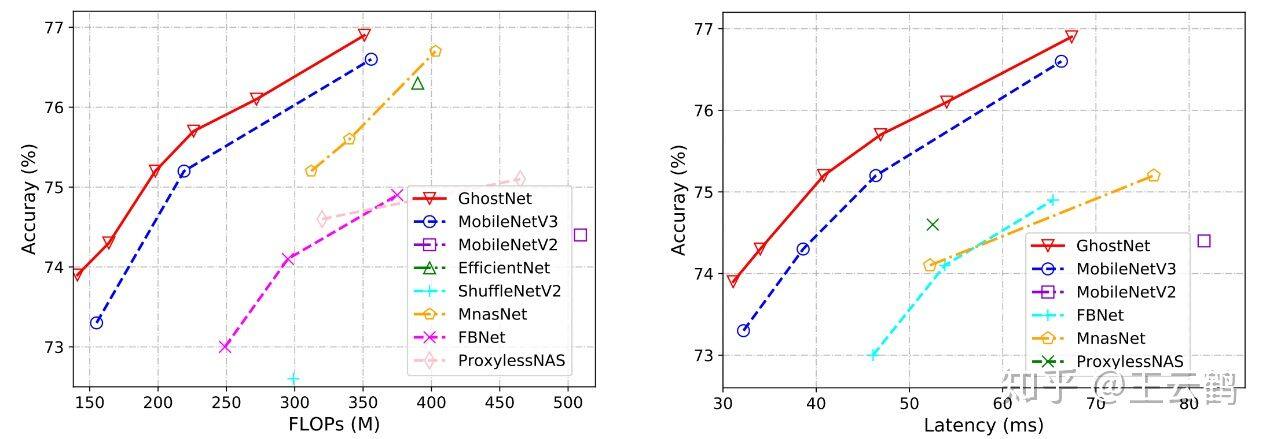
硬件推理速度:由于提出的 GhostNet 是为移动设备设计的,因此作者使用 TFLite 工具在基于 ARM 的手机华为 P30Pro 上进一步测量 GhostNet 和其他模型的实际推理速度。遵循 MobileNet 中的常用设置,作者使用 Batch size 为 1 的单线程模式。从图 6 的结果中,我们可以看到与具有相同延迟的 MobileNetV3 相比,GhostNet 大约提高了 0.5%的 top-1 的准确性,另一方面 GhostNet 需要更少的运行时间来达到相同的精度。例如,精度为 75.0%的 GhostNet 仅具有 40 毫秒的延迟,而精度类似的 MobileNetV3 大约需要 46 毫秒来处理一张图像。总体而言,作者的模型总体上胜过其他最新模型,例如谷歌 MobileNet 系列,ProxylessNAS,FBNet 和 MnasNet。
值得指出的是,华为内部开发了一款神经网络部署工具 Bolt,对 GhostNet 实现做了进一步优化,速度相比其他框架如 NCNN、TFLite 更快。感兴趣的读者可以参考:
https://github.com/huawei-noah/bolt
COCO 目标检测数据集:为了进一步评估 GhostNet 的泛化能力,作者在 MS COCO 数据集上进行了目标检测实验。具有特征金字塔网络(FPN)的两阶段 Faster R-CNN 和单阶段的 RetinaNet 作为 baseline,而 GhostNet 用于骨干网络做特征提取器。表 6 显示了检测结果,其中 FLOPs 是使用 [公式] 输入图像计算的。通过使用显着降低的计算成本,GhostNet 可以在单阶段的 RetinaNet 和两阶段的 Faster R-CNN 框架上达到和 MobileNetV2 和 MobileNetV3 类似的 mAP。

表 6 GhostNet 在 COCO 数据集的表现
总结
为了减少最新的深度神经网络的计算成本,本文提出了一种用于构建高效的神经网络结构的新型 Ghost 模块。Ghost 模块将原始卷积层分为两部分,首先使用较少的卷积核来生成原始特征图,然后,进一步使用廉价变换操作以高效生产更多幻影特征图。在基准模型和数据集上进行的实验表明,该方法是一个即插即用的模块,能够将原始模型转换为更紧凑的模型,同时保持可比的性能。此外,在效率和准确性方面,使用提出的新模块构建的 GhostNet 均优于最新的轻量神经网络,如 MobileNetV3。
作者介绍:
王云鹤 华为诺亚,深度学习边缘计算
原文链接:
https://zhuanlan.zhihu.com/p/109325275
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

InfoQ 主编

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论