

前不久举办的 Kylin 五周年庆典中,热度最高的非这场“圆桌会谈”莫属。来自 Spark,Hudi,Clickhouse 以及 Kylin 等开源社区的大佬,来了一场跨越时差,跨越区域的“云”上对谈。
下一代云上数据分析产品的趋势都有哪些?他们都看好什么关键性技术呢?你想知道的都在本文啦!
热点问题
湖仓一体和 Lakehouse 到底是什么?
计算和存储分离已是大势所趋?
到底是公有云,私有云还是混合云?
数据上云,多云管理有何难点?
数据治理,数据安全如何实现?
👏一起来看看都有哪些大佬👏
主持人|李扬 :Kyligence CTO,Apache Kylin PMC member
李潇 :Databricks Spark 研发总监
郭炜 :易观数科 CTO,负责 ClickHouse 华人社区和 Apache DolphinScheduler 的运营
李少锋 :Apache Hudi Committer & PPMC
史少锋 :Apache Kylin PMC Chair

会议全程视频回顾看这里👇
快来一起看看全文高能的会议实录吧!
李扬:我们知道最近有很多新的概念,比如 Databricks 提出的 Lakehouse,阿里讲的湖仓一体,又比如 ClickHouse 代表的矢量计算优化等,大方向上面,最近的变化和趋势很多,请各位老师从自己的角度谈一谈,你看好的数据分析的发展趋势有哪些?
李潇 :在 2019 年底,我们公司 Databricks 就已经在推出所谓的湖仓一体,我们称为 Lakehouse 的这个概念。
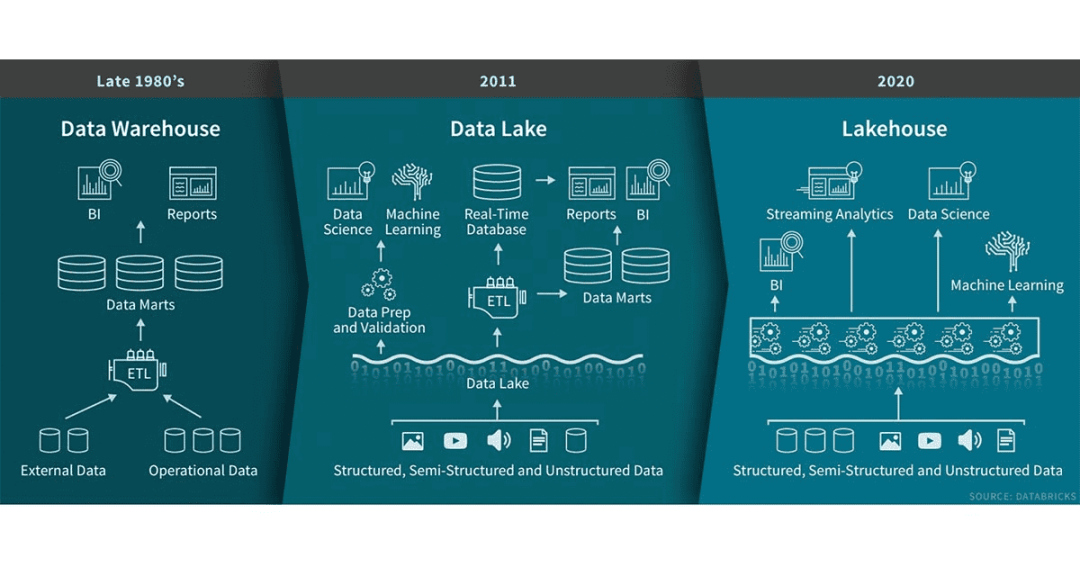
Lakehouse 的概念的引入,其实是在一个大的背景下,就是数据仓库和数据湖边界越来越模糊,尤其是在云原生这种环境中,大家基本上新的平台,数据处理平台,或者说数据架构,一般都不会原封不动地去复制之前的数据仓库或者数据湖的架构。原因是它们现有的或者已有的架构,实际上是存在很多缺陷,并且缺陷明显。当重新去创建一套新架构的时候,基本上算是取其精华,去其糟粕。这就是为什么 Lakehouse 整个概念的提出。当然,这是一个方向性的,有很多需要不断去创新,不断去重建。尤其是在当前公有云的重新框架下。
比如说 Object Store 这种廉价可靠的存储模式,还有 Lakehouse,Warehouse 这么几十年的这种开发、研发的经验积累和技术吸取,我们相信会有越来越多新的项目产生。包括了我们公司的 Delta Lake,也包括了 Hudi 这边不断的努力。这是我对数据湖和湖仓一体的观察。
李扬:从 Lakehouse 的角度来说,它对于用户产生的价值,和之前相比,最大的区别是什么呢?
李潇: 其实最大的区别应该是从两个方面最明显。
第一就是它和原有的数据仓库,一般数据仓库的主要的接口是 SQL,而数据湖这边千奇百怪,什么语言都有。那么 Lakehouse 基本上就是响应这种所谓的多源支持,再按照用户需求,比如说需要支持 AI 或者 BI 的系统,我们都要提供对应他们生态圈的这种语言,而不是强迫用户去把它产生 SQL,或者是扩展 SQL 标准。
另外一点就是数据拷贝,如果使用数据湖或者数据仓库,同时使用的话,我们同一份 Data 需要多份拷贝,这实际上是对一整套,不管是存储费用,实时性、一致性、正确性、准确性,或者是安全性,都是一个很大的挑战。并且存储和计算分离,也是一个明显的趋势。湖仓一体必然是走这条道,而不是重新再走原来的老路。
李扬:请问一下郭炜老师,从你看数据分析的趋势是有怎样的变化?
郭炜 :目前 ClickHouse 其实在做一些大量的,底层的 CPU 整级的一些优化。
其实从整个趋势来看,原来大家都会觉得大数据是一个应用层,其实现在大数据慢慢是往下面发展越来越多。特别在最近,我们看到社区也好,还有企业应用也好,它的趋势都变为我们需要去和现有的,也许是硬件,像 ClickHouse,那么也许是和云,现在像云原生的大数据来去结合。其实这中间就有不少的难点。云原生很早以前,跟 Databricks 一起在 AMP lab,当时就出的 Mesos,为什么到现在我们还没觉得没有特别火呢?其实是我们有几个比较大的技术门槛。
一个是过去在做的,CPU 在计算的时候我们都是叫预分配的制度。一个 job 起来,我们大概给这些分多少的 CPU、内存,这些都先分好,然后去进行计算。但是其实真的云原生在做的时候,它往往是动态的,可能是跟着你现在的整体运行情况,可以动态加减。我认为这个对于大数据来讲,不像这种应用级的,我们看 SpringCloud 这些,其实没那么容易扩展和缩小,对于我们来讲,这个是存在一定困难的。
第二个是过去在做存储的时候,大家都叫 share nothing,大家讲的存储和计算是在一起的,大家相互不要去做太多的工作,每个都是小的做完,最后再做 shuffle。但其实现在在做云原生的时候,都变成是一个 storage,就像刚才李潇老师提到的,它底下也许是湖仓一体,也许廉价的冷存,也许是快速的热存,怎么能更快地去跑起来。
第三个就是刚才提到的,底层的 CPU 指令级级别的高速运算,也许是矢量计算,也许是关于云原生的某些结合或者云原生包装后的 CPU 的计算。我以上提到的这些,对于大数据圈,大家奔着云原生去的时候,其实有三座大山摆在大家的面前。整体来讲,对于企业来说,未来 5 年肯定会越来越多的企业,无论是私有云还是公有云,会选择把过去这些硬件的 CPU,包括存储,都集中化以后再分配,这些都是未来几年,我们要去攻克的事情。
看到有些开源的项目,像 Ozone, Alluxio,包括 Kylin 这次我看也都在做类似的一些工作。我相信未来这几年,一定会有特别好的项目出来。
李扬:让我们一起期待。请问一下李少锋老师,从你的视角,或者从你的社区,会怎么来看数据分析的趋势呢?
李少锋 :我接着李潇老师的讲 Lakehouse 和湖仓一体。Lakehouse 是之前 Databricks 提的,和阿里云提的湖仓一体相比,虽然有相似,但我认为还是有一些不同。
Databricks 提出的 Lakehouse,主要解决什么问题?数据的重复性,对事务的支持,以及在同一份数据存储上面对接不同的工作负载,并且可以端对端的支持报表。但是湖仓一体,更多的是说无缝打通湖和仓的元数据,然后对于湖仓有比较统一的一种开发体验。阿里的湖仓一体可能更多的视角是从项目(共享元数据)这个层面去出发的,而 Databricks 的 Lakehouse,更多是说从架构以及一些特性去定义,其实两者我个人理解还是有一些区别的。
要实行一个 Lakehouse 架构,可能是基于 Delta 还有 Hudi 这一套, Databricks 借助三个架构就实现 Lakehouse。但是对于湖仓一体来说的话,可能不需要借助这三个来去做。
比如说阿里云的 MaxCompute 里面去访问 OSS,湖里面的数据,可能在更后端,就是湖仓一体。对于 Lakehouse,可能更强调在前端的架构。但其实也是一个比较新的架构。
目前 Hudi,包括我在的团队,也在做 Lakehouse 相关的事情。我们也是在不断摸索,因为现在还没有哪个企业真正把 Lakehouse 架构落地,目前,包括阿里云也是,还处于探索阶段。我认为这是一个不错的方向,后面可以去服务阿里云上的一些客户,目前接触的客户很多有 Lakehouse 这方面的需求,这也是一个趋势。
李扬:这个非常有意思。其实我也是从不同的渠道听到, Lakehouse 比较早是 Databricks 先提出来的,后来我也从一些渠道听到阿里提湖仓一体。当时觉得这两个词是中英文的翻译吗?今天听到大家的解释,有一种豁然开朗的感觉。从大家的角度来看,虽然这两个词很像,而且可能实际上解决同一个问题。但是从技术角度来说,它们的出发点和架构设计都是不一样的。
前面听到李潇老师强调的是,从用户视角如何统一,各种 AI、BI 工具融合的使用,以及到数据是一份,是共享。李少锋老师更多说到是从元数据视角,把湖和仓有机统一起来。
现在请教一下史少锋老师,从你的角度怎么来看数据发展的趋势呢?
史少锋 :刚才李扬提到,可能湖仓一体最早是由 Databricks 提出来的。的确,Databricks 提出 Lakehouse 让大家耳目一新,或者说开始真正地去审视这个趋势。 但是回顾历史,我觉得可能最早去践行这个趋势的可能是 Snowflake,大概是从 2014 年、2015 年就开始在架构他的云上数据仓库。 并且他这个数据仓库是完全基于云的这么一套架构和技术来设计的。回过头来看,其实跟我们在做的湖仓一体还有 Lakehouse,或者说各个技术流派在做的非常的相似,或者说吻合。
这些都是架构在云上,公有云的数据湖上,然后再引入一些,实现 ACID,实现 snapshot,实现批流融合的这么一个轻的存储层,然后再实现存算分离的架构,使得存储和计算可以分别去 Scale,实现动态的资源分配的同时,还实现 workload 之间的隔离,从而也支持多租户等等的。
现在很高兴看到,不只一家厂商,更多的厂商,包括 Databricks,阿里云,华为等,大家都在做 Lakehouse,或者湖仓一体的分析。对于 Kylin,我们也感到这个趋势非常明显。今天我们越来越多用户,希望让 Kylin 能够直接对接到他们云上的存储,最好是类似于 Hudi 还有 Delta Lake,过去可能主要是 hive 这样相对来说比较静态的存储。
分析方面,Kylin 目前主要是服务于 BI 的分析,所以暂时 AI 的分析可能还接入不进来,但是 BI 的需求一直是存在的,即使未来走到 Lakehouse 的趋势,Kylin 依然是有生存的空间。 以 Kylin 的高性能和高并发来解决业务人员对这个数据探查的需求。万变不离其宗,我认为底层无论是 Data Warehouse 还是 Lakehouse,上层的话依然需要像 Kylin 这么一个 Datamart 的存在。
李扬:我们前面聊了一些大家看好的大趋势。大家其实也很关心,在这个大趋势下面,你觉得哪些是关键技术,能够支撑到这些大趋势,或者是它价值的转换,我觉得这可能是更多技术人员关心的问题。请问李潇老师,从你的角度来看,对于 Lakehouse,或者是别的趋势而言,你觉得下一个关键技术又是什么呢?
李潇 :这里面实际上从我或是我们团队的角度来看,分析技术的趋势,或者是当前架构方面,大家好像某种程度上已经形成了一个共识。
首先就是, 未来的大趋势会在公有云上面,不管是从私有云迁移,还是产生新的数据,这会是一个总体的方向。 在公有云上面,不管开源还是闭源,就像史少锋老师说闭源的 Snowflake 其实在很早之前就已经开始在向这个方面努力。
所以这方面我们相信, 开源,尤其在存储架构层面的开源是一个大势所趋。因为它有诸多好处,尤其是对用户可以更容易地实现数据迁移,或者是更容易去让外部的这些应用,尤其是生态圈里各种各样第三方的库去访问,去使用这些数据。 这也就是为什么某种程度上来说,为了支持这种 AI 的场景,而不仅仅是 SQL 语言。我们可以看到像 Snowflake,据传他们正在做一些尝试,比如说批流一体。因为他们也想要支持流处理。而流处理,如果仅是用 SQL 语言去做扩展,那么生态圈的融合和数据的使用,就变得异常艰难了。
如果做 SQL,大家会发现,实际上 SQL 虽然是一个标准,但是最新的 SQL 标准,并没有多少厂家是支持的,并且对流也没有存在各种各样的标准。其它方面,比如说 AI,如何去接入 python,如何去和生态圈的融合目前是空白的,而且这个标准的制定,周期也特别长,我们相信这种语言的使用,是拥抱用户的,而不是基于厂商来定义的。
至于计算和存储的分离,我们也相信两者应该是分离的,而不是绑定的。这个趋势目前也是非常明显。当然闭源这边,比如说 Snowflake 的计算和存储目前是捆绑的,我们也无法知道他们计算上是如何去分割。但是计算引擎方面,我们也相信像 Vectorized Engine 也是一个好的方向,开源这边有 ClickHouse 这边在做 Vectorized Engine,我们这边内部非开源的 Delta Engine,也是一个 Vectorized Based 处理引擎。并且不是 JVM 写的,是 C++ 写的。我们相信这种系统级别的软件,C++ 是一个更好的语言或者是更稳定的一套实现的方式。
李扬:前面提到流式分析是从用户视角,很需要的一种分析能力。但从消费方来说,可能 SQL 语言又不是很合适。从您的角度,哪一种用户接口或者是语言来消费流式分析的数据是更合适的呢?
李潇 :我个人看法是,这一点应该取决于生态圈,我们看到现在整套数据架构里面基本上有两个大的方向,一个是 AI,一个是 BI。 那么 AI 这边,我们看到的最流行的语言是 Python,并且可以看到语言层面的用户的 adopotion 和 community 基本上 Python 是一家独大,并且增长速度可以说是火箭级的,连国内的房地产商都在学 Python ,可以想象它的这种简单易用性,大量的库函数。即使是流跟这个 Python 本质来说是没有关系的,任何语言包括 Scala,Java 都可以,但是从数据方的角度,怎么把这个数据送到使用方,我们相信 Python 将会是一个大势所趋,如何去拥抱 Python,我们 spark 社区在 3.0 release 的时候,也特别强调了 SQL 和 Python。我们也相信这是两个主流语言。
李扬:因为其实流式是一个数据的 processing,它是一种处理方式,与消费其实还并不是有什么直接耦合的关联。但是李潇老师指出的非常有道理,如果从用户视角来看,易用性和可接入性才是第一位的。郭老师,从您的角度来看,在这个趋势下,哪一些是更容易发光发亮的技术点?
郭炜:第一个像刚才说的,云原生。这个和李潇老师略有不太一样,我觉得不一定是公有云,云原生可能是混合云,也可能是私有云。 因为现在特别是中国的一些企业,它其实全面上公有云,还要很长一段时间才能够去做的,但是它的私有云建设,比如内部的云原生,和内部的类似 K8S 这样的私有云,反而是越来越激进了。 所以我觉得未来的这种大数据研发,可能是公有云、私有云都能够去跨的这种融合的方式。
就像大家说的,Snowflake 最近特别火,它是跨公有云的方式,如何变得既有公有云还有私有云,我觉得这个技术将来还蛮多挑战,但是这会是一个趋势。
因为现在云原生的这些大数据,全都是存储和计算分离的,最终你的存储在哪里?其实我觉得并不重要,将来的网络带宽肯定是越来越好的,那么如何在中间能更好地安全、加密,这我觉得是第一个跟云原生相关的技术点。
第二个,在大数据领域,特别是在座各位都是来自开源社区的, 我觉得其实通过开源的打法来去诉求到最后的云原生的一些服务,这个也是未来很重要的趋势 。通过开源能找到更多的用户场景,以及更多的一些潜在的用户,最终通过商业的这种服务,或者商业上面产品的提升,来去获得最终企业的商业价值,我觉得未来一段时间,特别像我们在座的这些大数据的,和开源社区的小伙伴,这会是一个很好的路径。
第三个,其实跟技术点略有不同。现在对于企业,特别将来咱们做的,刚才大家提到湖仓一体,包括我刚才说的云原生这些,其实还有很重要的一点,就是数据治理相关的东西。我挺赞同李少锋老师刚才说的, 其实现在很多时候,阻碍企业去大面积使用云原生,或者是 Lakehouse 这样的东西,往往不是由于技术原因,而是在于它的数据管理能不能够做的更好 ,这个数据能不能更快去做相关的融合,中间再出现各种各样新型的数据源。最近像我们易观在做的用户行为,这些点击流,相信将来还会有线下 IoT 这些物联网的数据上来,每次有新的这些数据进来以后,怎么能用更好的技术方式,把它描述好,然后融合到现有的 Data Warehouse,或者是自己的大数据平台里,或者是将来 Lakehouse 里,我觉得这个的挑战不亚于技术本身的挑战。
所以我觉得这三个方面,都是未来我们这些从事数据的人员要去攻克的。云原生、开源,以及这种业务相关的数据治理的平滑过渡,这个是有挑战的。
李扬:云原生开源和数据治理,其实前面两位老师都提到了一点点流,和 IoT 这个大趋势也有关系。那从 IoT 的角度,就是数据流的角度,您觉得这里的治理技术,可能目前还比较模糊,对于数据治理,大概有哪些技术在这个方向上是有潜力的?
郭炜 :IoT 的数据,因为当年从传统的,我们自己的这种结构化数据到大数据,就是点击流的时候,中间它的数据更加的稀疏了,到 IoT,数据就更加稀疏了,里面我们叫做有数据熵的这些数据,其实它变得更加稀少。
在我看来,有几个会要去做的,第一点就是 IoT 数据虽然种类繁多,但是针对每一个 IoT,它的行业,再抽象到概念模型,我觉得是很重要的。如果不抽象成概念模型统一起来,就会迷失在大量的 IoT 各种各样的繁复数据里面,你存了很多数据,可能不是大数据,那是“大垃圾”,因为数据太多了,里面没有什么能用的。你首先预定义一些,你想到的,根据这个行业,甚至某种类型设备里面的概念数据模型,在这个数据模型之上,再通过批流一体的方式,其实不是所有的数据都要进入到最后的这个 Lakehouse 也好,数据仓库也好。 它其实通过边缘计算,在你的边缘端,就做了一部分数据的整理。那么其实不会把所有数据全都放到云端来浪费网络,浪费存储。
怎么去表现这件事情,我觉得就是刚才说第三点,数据治理。对于不同的业务,不同的行业,再到你去要哪些对你数据有价值的这些东西的时候,可能要有一些预先的想法,至少你的概念模型得想好。才能通过边缘计算和其它方式,把这些这么大量的数据,能够有效地进行预处理,再有效地进行存储,我觉得这个是对 IoT 数据的一些处理方法吧。
李扬:李少锋老师这边,从阿里或者 Hudi 社区的角度,你是怎么来看下一轮的一些闪亮的技术点?
李少锋 :从我目前工作和社区来看,有以下几点。
第一个就是数据组织技术的发展,比如 Delta、Hudi、Iceberg 就是有代表性的开源数据组织技术。数据存储,HDFS,数据的 Ozone,以及云上的对象存储等,其实数据就是底层存储不断发展,所以越来越廉价。对于上层的,比如像 spark,Flink 这种计算引擎也是在不断发展。但是对于数据组织的发展还是比较少的,比如说现在三个开源框架,对于 time travel 以及各种各样的 snapshot,ACID 等。就现在这三个框架出来之后,也会引起一波热潮。可以基于这几个框架去做到我们 ACID,也就是说对于数据服务层的一个统一,就是摒弃之前比较繁琐的这种 Lambda 架构。这个对于很多企业来说,还是很有吸引力的。就是企业可以基于一套数据库,去替换之前他们的架构,支持流批统一。
然后数据通过数据组织层,落到了数据存储,比如说现有的云上存储,我们怎么去对它进行一个数据的访问,从我这边来出发,其实还是用的 Presto 这种引擎,也就是 SQL 引擎去访问 OSS 上用户的数据,这边的发展开始直接去拉用户在 OSS 上的数据,后面也会遇到一些问题。
比如,我们去拉用户的一些热数据,有时会有受访问速度的限制,受 Query 查询不够快的影响,后面如何去平衡本地存储以及云存储,会在中间去架设一个缓存区,因为 Alluxio 这边和社区合作的一个项目,来加速一些用户的 Query 查询。那么怎么去融合本地存储,或者说内存存储以及云端的冷数据和热数据的融合。目前我们这边做的还是不错的,可以平衡这两部分的存储。
如果用户需要他的数据更快速,可能需要增加一些成本。如果没有太多考虑,可以直接从对象存储拉数据,不需要进行一个加速。
还有一点,我对郭老师在数据安全的观点也比较赞同。目前对大部分开源社区来说,其实安全这一块做的还是比较少的,就是数据端到客户端的安全。现在我们本身的一些产品,其实也没有太多考虑安全方面,我觉得这一方面也是后面需要着重去建设的。开源社区如果有一些比较好的安全方案可以融入到 Lakehouse 里面。
主要是三点,第一个是数据组织层面的发展,比如 Delta、Hudi、Iceberg。第二个是本地端的缓存,就是云端和本地缓存怎么去做一个融合以及平衡。第三个就是刚刚郭老师说的安全方面,端到端的安全,我认为这三个方面未来有较大的发展空间。
李扬:多谢李少锋老师,也提到 Lakehouse 和湖仓一体,以及数据一致性问题。又牵涉到数据的 ACID 的能力,又说到存算分离,还有遇到数据访问速度的问题,所以一般在计算层贴近的地方,都有一层数据缓存,包括 Snowflake 架构上面也是有这一层。前面提到的 Alluxio 也是这方面很好的开源。对技术感兴趣的同学,可以参考李少锋老师说的这些关键字,可以自己来学习一下,相信都会很有帮助。
请到另外一位少锋,史少锋老师。从你的角度来看,有意思的技术点可以跟大家分享两个吗?
史少锋 :前面说是追随湖仓一体的有哪些关键技术需要突破,我这里总结了三点。
站在 Kylin 的角度,以后如果要把 Kylin 变成一个云原生的数据仓库或者说数据分析引擎的话,主要面临这三个方面的挑战。
第一个方面,怎么样让它更好适应云原生这么一个环境。 不仅包括存储、计算,还有安全,还有各种稳定性、可靠性、资源的有效利用。过去,因为 Kylin 直接是一个 Hadoop 原生的应用,所以这些方面不存在太大问题。比方说 HDFS 是主要的存储,它的访问性能很不错,它的原子性、一致性也是有保证的。计算我们就充分使用 Spark,使用 on Yarn 的模式,或者说 MapReduce,它们也是非常的成熟和稳定。
安全方面的话,因为它是一个 totally private 的 deployment,所以安全在过去也并不是太大的一个考虑。但是,如果说我们要把它发展成一个云上的应用的话,那么所有的这些几乎都是要推倒重来。因为我们知道存储计算在云上和在 Hadoop 上都会不一样,这是云原生的第一个方面的挑战。
第二个方面,就是一个数据融合的挑战。 未来我们也看到 Lakehouse,它上面处理的数据将是来自于多种数据源,除了一些交易系统,或者说一些 Tracking 的这种埋点系统,还有包括郭老师提到 IoT 的系统,各种源头的数据,甚至说这些数据它可能是异构的,不仅仅是关系数据,还有一些半结构化的数据,比如说 json 的数据,xml 数据,甚至说有一些其它的图像的数据等等。
过去很多这些数据是在以一种批处理的方式,或者说 T+1 的,按天或者按小时的接入,那么未来很大的一个趋势就是实时的接入,希望能把这个数据的延迟,减小到更低。这也对我们的数据融合带来挑战。怎样的一个数据分析引擎,可以 handle 多源的数据,异构的数据,还能实现它们实时和历史混合的分析。
前面李少锋老师提到,他们目前可能采用一些像 Presto 这样的引擎来做跨源、跨数据的访问。未来是不是还有一些 Spark,在这方面也能够有一些更大的突破。
今天我们是使用 Spark 作为主要的计算和加工的引擎,我们希望它也能够在这方面有进一步的发展,对于我们来说就可以继续在这条路上走下去。
第三方面,很大的一个挑战就是多云的挑战。 今天,经常大家去讲,要使用云原生,或者说要上云,但是我们看到云,其实它是一个非常割裂的技术。除了有公有云,还有私有云,混合云。在国外的话,美国主要是三朵公有云,私有云可能都不太多。 作为一个技术厂商的话,主要对接这三朵云,就已经能够把 70%、80% 的用户吃下来。但是在国内的话,我们看到这个情况是不一样的。
公有云,可能面向的主要还是中小企业。在这些大的金融机构,他们都在建立自己的私有云,或者说行业云,以及一些混合云。而它们背后云的技术也是五花八门。对于像 Kylin,Kyligence 这样的厂商,我们想要基于这个开源技术来提供大数据分析的服务,在上云的时候也是面临很大的矛盾。一方面我们想 keep 一套完整的技术体系或者是架构。另外一方面,我们却面临分别不同的云。怎样的设计或者架构,能够适用到多个云上来,会是一个非常考验我们的挑战。
李扬:史少锋老师说得很全面,其实前面有一个对立的观点,不知道大家注意到没有,还挺值得聊一聊。
从李潇老师以及美国目前情况来看,是公有云为主,但是郭老师,包括史少锋老师都说到了,国内显而易见是混合云,私有云跟公有云是交错生长的状态。 我们面临的挑战是,怎样的一套技术架构,能够在多云环境下面都能成立的?那史少锋老师在这个方向上,会看好哪样的技术能够支撑到这一点呢?
史少锋 :这个问题也是我今天挺想跟各位探讨的。特别李潇老师,因为 Databricks 在上云这条路上走的比较领先。我们过去还在 Hadoop 上跑这个 Spark,主要是在 Yarn 上面做资源分配。现在上云的话,特别是还要适应多云的话,我们就发现,如果推倒 Hadoop 这套复杂的技术体系来看,要想把 Spark 这个通用的,分布式的大数据的体系运行的好,可能要引入像 Kubernetes 抽象的一个资源调度的平台。我想请教李潇老师,从你的经验来看,Kubernetes 是不是真的适合做这个大数据的处理和分析,Databricks 是不是后台用 Kubernetes 来运行 Spark 的任务,如果不是的话,你们倾向的这么一套架构,或者说调度方式是什么样的?

李潇 :我这边来回答几点。
第一,我们还是坚信公有云,这个坚信是从 7 年前,8 年前就一直走到现在。8 年前在美国也是私有云、公有云混合,而且私有云绝大多数,公有云其实是很小一部分。但是今年的冬天,我不知道大家有没有留意到新闻,美国的信用卡巨头 Capital One,关掉了它们所有的数据中心,全部进入了公有云,这是一个指标性的事件,就是银行都可以完全进入公有云。我们相信未来公有云会是大势所趋。
第二,资源调度系统,我们因为是 Spark 的原创团队创建的公司,所以我们是 scheduler 完全自己重写,基于 Standalone 做了很多扩展。但是我们也相信,如果 7 年前,我们再重新做这个决定,当时 Kubernetes 不存在,也可能存在,但是只是在 Google 里,那么我们可能就不一定会自己重写。
但是我也可以分享一些从我们社区来的信息。像 Apple,原来主要用 Mesos,今年应该是已经进入了产品化,就是 Spark on Kubernetes。所以它们在社区的很多贡献,也是围绕着 Kubernetes 的支持。我们也相信 Kubernetes 也是一个大势所趋。我们公司内部使用大量的 Kubernetes,虽然没有把它作为资源调度,但是部署各方面都有,而且 Kubernetes 社区生态等各个方面都做的很好。我们相信它未来能够可持续地发展,也是值得我们继续深入投入的。
史少锋 :谢谢李潇老师,这样我们更加有信心了。
李扬:我觉得这样的讨论最有趣的就是在同一个问题上,我们能看到不一样的观点。也许美国今年的今天,就是中国两三年以后的未来也不一定,可能最后都是对的,但是在时间点方面,现在哪一个是更适合的,才是各个公司,开源社区需要去考虑,需要去适应。
史少锋 :大家都知道郭大侠在国内技术圈非常活跃,他组织了 ClickHouse 中国社区,有上千人的用户和组织者。我们也对 ClickHouse 这个技术非常感兴趣。因为在我看来,它其实是一个跟 Spark、Presto 这些引擎不太一样的引擎。前面也提到这是一个 share nothing 的架构,着重使用机器的硬件,还有本地的数据存储来提升分析效率,而且分布式部署也是不太一样的。
我看到它也有一些上云的打算,也在对接一些分布式的存储,像 S3 等。从郭大侠的角度来看,比如把 ClickHouse 真的变成一个云上的,非常动态的分析引擎,到底是不是一个可行的方案?或者说你在社区里有没有见过一些人,真的把它跑在 Kubernetes 上,然后结合云的存储,能够做到一个高可应用、高性能的数据分析。
郭炜:首先我可以透露一下本身的 ClickHouse 原创团队是俄罗斯的 Yandex 团队,他们在公司内部是在做一些上云的项目。在他们的 roadmap 远期规划里,因为所有的公司到他这个体量和规模的时候上云或者说云原生是一个趋势。但是云原生是不是用 K8S,现在他们还在讨论,他们自己内部也有俄罗斯自己的科技来做。
但对于国内来讲,我举一个例子,就是阿里云。现在阿里云上面其实就是有 ClickHouse 服务的,那么它的底层在做存储融合的时候,其实做了一些事情,只不过这个效率,各方面和原来 Standalone 在机器上跑还是有差距的。但是对于云来讲,其实可能规模效应要比这种追求每一台机器的性能极致还是不一样的。所以在我看来,ClickHouse 将来肯定会,也是作为云原生的一种大数据,只不过它将来走向哪一个云社区,或者哪种云架构,现在还没有定下来。但我觉得这是一个趋势。
从原创团队到现在周边的这些生态合作伙伴,其实都是会走向云端的,这是个大趋势,所以不用太担心,将来它上不上云,一定会上,只不过上哪种框架的云。
本文转载自公众号 apachekylin(ID:Apachekylin)。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论