

这篇文章是我在 2018 年 PyBay 大会上演讲的版本。所以非常非常抱歉发这么晚,你可以看这部分内容的视频。所有的示例代码都在附带的Github仓库里面。
如果你听说过 Serverless 的话,你可能会把它当做一种云架构模式,可以将一个应用程序所需要的、长期维护的基础设施数量降到比较低的水平。在某些场景下,这种方式可以节省很多成本。而且也确是是这样的。但是在这篇文章里面,我会在一个新的场景下,介绍相关的应用程序:高度并行的函数计算程序和生产环境下的机器学习系统。
如果你只是一个数据科学家的话,你可能不太了解什么是 serverless。我们将会以 serverless 最常用的应用场景—— Web 业务内容作为开篇。不过值得注意的是,如果你受限于计算资源的话,serverless 是一个轻量级的替代方案,可以帮助你搭建类似于 Spark 集群一类的内容。在没有运维团队的帮助下,就可以很轻松的将你的简单示例发布到生产环境上面。
Serverless 的争议
大多数的数据科学家对运维都不是很感兴趣,但这也是一个好的场景,能显示出 serverless 的与众不同,请耐心的听我说。
人们普遍认为计算机的这种理念并不是很好。
云环境里最棒的一件事情就是,你不需要关心硬件相关的问题。你只需要付费给微软、谷歌、亚马逊一类的云平台,让他们帮助你来处理。他们在这方面做的真的很好,以至于让你忘记还有硬件这件事。
但向云端迁移会带来成本的变化。最基本一项就是金钱。主要是因为,尽管我们利用了云环境的伸缩与拓展的能力,但我们还是不可避免地为一些未被充分利用的云资源,进行长期的付费。
虽然云成功地将硬件抽象化,我们还是需要安装、配置、安全认证,和维护操作系统或数据库等等。对于我们中的许多人来说,这是一种耻辱,因为这并不是我们想花费时间去做的事。对于大多数的雇主来说,他们并不能从中获得收益,因为他们主要还是通过部署业务逻辑来盈利。

那么,怎么样既能摆脱物理设施的束缚,又能忽视下一层——例如操作系统或者容器相关的内容?如果能做到这一点的话,我们就可以全身心地专注于业务逻辑。
这就是 serverless 的目标。
什么是 serverless
我们来考虑部署一个简单的 Serverless 程序,实现两数相加的逻辑。首先,请求会访问到某一个网关服务中。这个例子中的请求的内容为 2+2。实际上,网关会传输数据到某一台机器,并把该应用部署到那台机器上。新机器做出响应后返回结果,然后停止退出。
另一个请求(37+5)过来的时候,也会发生同样的事情:网关会创建一个全新的机器(并不会复用使用上一个实例的机器),该机器会在运算后就停止退出。至关重要的是,两数相加的应用程序,并没有实际的基础设备。
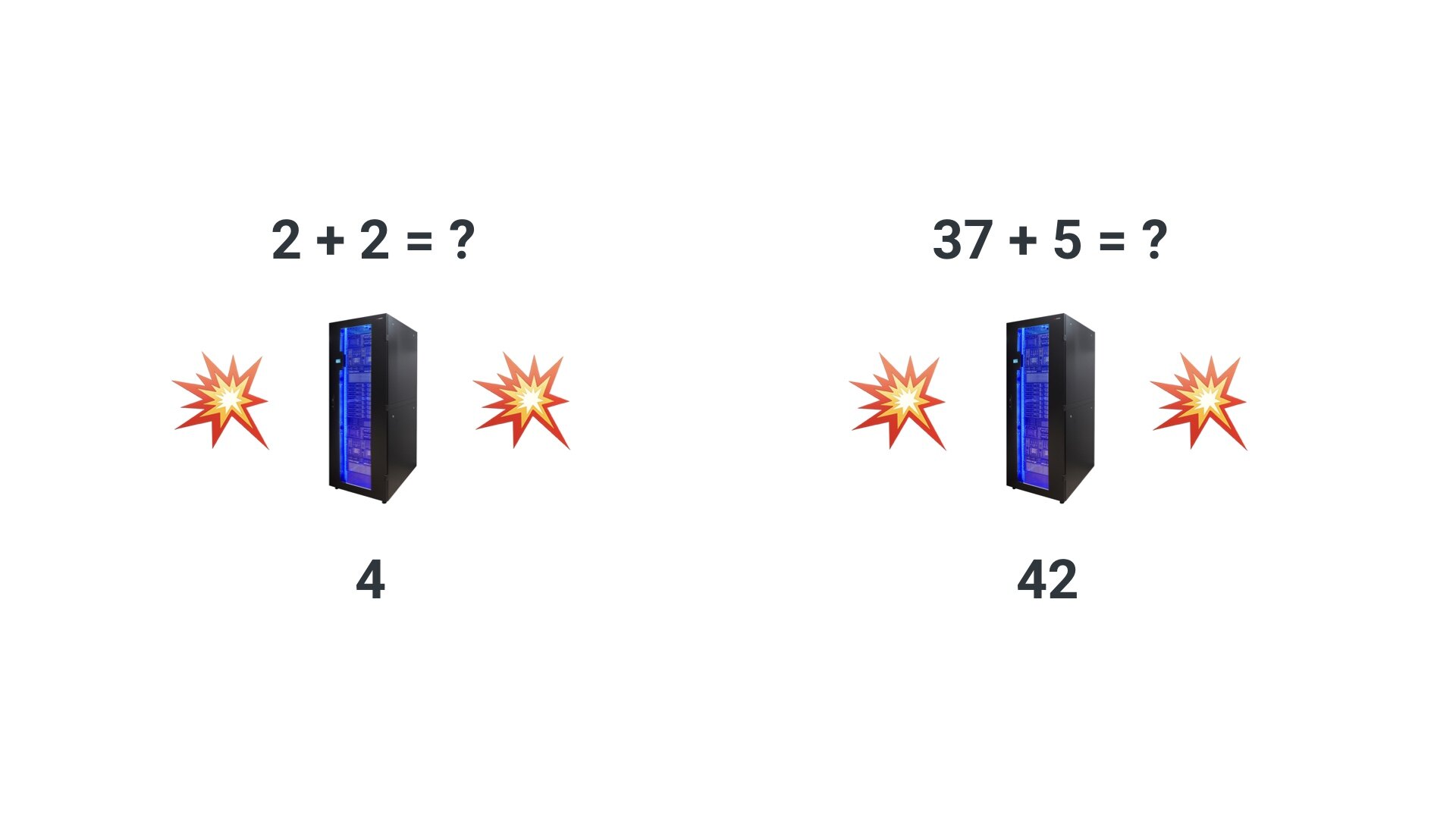
通常来说,你可以理解为基础设施的数量与利用率成线性关系,而且截距为 0(这有助你让你理解为什么 Serverless 的这个很便宜)
这种描述有点与众不同。的确也省略了一些工程上的细节内容,不过作为 Serverless 的新用户而言,很大程度上可以忽视掉这些内容。
顺便提一下,“Serverless”这个单词并不是一个很好地名称,理论上你还是有服务器的。不过实际上,你的服务器数量是无穷多个(从某种意义上来说,有点像非参数统计,这里非参数其实是指你有非常多的参数,并不是传统意义上的“非”。不过实际上而言,你并没有)。
用 AWS Lambda 和 Zappa 进行 serverless 部署
总的来说,为了使 Serveless 的利益最大化(例如,让别人来帮你进行运维的工作),你需要为使用 Serverless 平台支付给云平台一定的费用。你可以在 AWS Lambda,Google Cloud Fuctions 和 Azure Functions 里进行选择。这些服务会创建、销毁并以其他方式来管理大型的短生命周期机器池(像以上我们用于计算 2+2 和 35+7 那样)。
为了演示在 AWS Lambda 上的部署,让我们用一个简单的 Python Flask 应用程序来显示当前时间:
如果你之前没有了解过 Flask,这里有模板可供你参考,但重点是 time 函数(返回时间)以及它前面的装饰器。如果有人访问/time 路径,它会告诉 Flask 返回函数的结果。
你可以通过运行 python app.py 在本地“部署”这个应用:
当你访问 127.0.0.1:5000/time 的时候,你将看到当前时间:
如果笔记本电脑被合理地设置了防火墙,偶尔会进入睡眠状态,那么在本地长时间部署这个应用就不是很合适。现在我们把它部署到 AWS Lambda 上面。
这会涉及到大量的手动的工作,不过好消息是可以通过使用命令行工具来帮助我们完成任务。我推荐Zappa. 之所以喜欢它,是因为它是用 Python 写的,至少在原则上,它不会关注你往哪个 serverless 平台上发布。至于其它的工具,我了解的,是名字很容易混淆的Serverless和 AWS 的Chalice.
以下是如何使用 Zappa 发布上面的 time 应用。首先你要创建并激活一个新的虚拟环境,然后在里面安装相关的依赖库。像上面的例子,就需要安装 Flask 和 Zappa。 在相同的路径下,复制上面的 app.py 文件,然后运行 zappa init:
zappa init 会快速引导你处理一些相关的问题。这个简单的小例子中,你接受默认的设置就可以了。以下是生成的配置文件:
然后执行 zappa deploy,这时 Zappa 的作用就显现出来了:
他帮助我们处理了很多复杂的内容。最值得注意的是,它创建了一个包含应用程序和其依赖项(默认情况下是根据虚拟环境的安装内容来进行的)Zip 文件,并将其复制到 AWS 上面。在输出内容的最后,你会发现一个 URL,你可以用它来替换之前使用的 localhost。
该 URL 不会长期有效(因为我运行了 zappa undeploy),但请相信我,此刻的结果是这样的:
大体上,对 URL 进行请求和响应的全过程如下:
一个计算机凭空出现了。
跟 Zappa 一起被上传的应用程序和依赖项会被部署到这台新的计算机上。
新计算机接受请求。
计算并返回响应。
该计算机被毁掉。
每次访问这个 URL 的时候都会发生同样的事情。(实际上,AWS 会对实例进行缓存,来保证请求可以正常响应。但从概念上说,每个请求都会创建新的实例,并在执行结束后销毁。)
关键的一点是,这个相当复杂的过程意味着,你的应用程序正处于生产环境中,是可以公开访问的,而且在不使用她的时候,你就不用支付任何费用。
我已经把这篇文章中所有的代码都放在Github仓库里了。其中我也演示了如何升级已发布的应用程序,传递时区作为 URL 的参数。Zappa 让升级变得很容易(通过执行 zappa update 命令即可),并提供了很方便的 zappa tail 命令,在你的笔记本终端,从已发布的应用程序组件中整合日志和错误信息。如果你部署出现了问题或者正在运行的应用抛出异常(例如,用户提供了无效参数),调试会更容易些。一般情况下,你甚至可以使用 serverless(尤其是带有 AWS Lambda 的 Zappa)配置 cron 任务,使其在 serverless 执行器上运行。举个例子,请看我的报告天气的Twitter机器人。
Serverless 的优势与限制
serverless 的普遍优点在于,它能让你更专注于业务逻辑,并且在部署时有无限的可扩展性。另一方面,一些人认为 serverless 与微服务架构(例如,复杂性方面)以及云部署(例如,供应商对资源锁定的风险)有着相同的缺点。个人工程师购买的范围各异,当然这跟我们这篇文章中的数据科学部分(即将要讨论的)并没有太大的关系,所以不想在这做过多解释。
对于数据科学用例来说,serverless 最明显的优势就是成本:因为我们只在代码运行的时候付费,没有未使用资源浪费的问题,支付的费用与使用量成正比,往往很便宜。比如说,Postlight 的 Readability API 每个月在 EC2 上的费用是 10000 美元,转移到AWS Lambda后,现在每月费用仅为 370 美元。
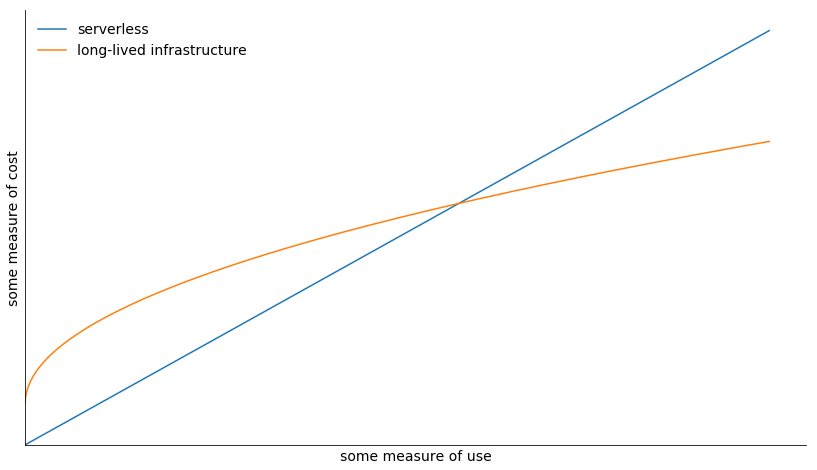
但事实上,说 serverless 贵也是无可厚非的。考虑一下上面的图(很简略)。serverless 的成本与利用率呈线性关系且截距为 0。通常情况下,这要比小型部署的其他方案便宜。而且对于计算使用量很大的情况,它可能更便宜。但如果每秒要处理数千个请求,那么所需要的成本可能会在交叉点之后,这样的话,非 serverless 所需的成本反而会更低一些。
可能 serverless 和传统部署模式之间最根本的区别在于机器的性质,他们会随时消失或者出现(与其说是缺点,不如说是 serverless 一系列固有的限制)。到目前为止,我对他们也是一直很模糊。某种程度上,对他们工作方式的理解还是很有限的。但我要把我知道的都告诉你。
这些机器都是动力不足的。对于AWS Lambda,写入时的 RAM 不足 3GB,本地存储也相对较小(75GB)。他们是靠借来的时间过活。函数必须在 15 分钟内执行完毕。那些条件很随意又多变(就在前不久,Lambda 的限制变为 1.5GB、500MB 和 300 秒!)
但不可避免的限制就是,这些段生命周期较为短暂的机器是无状态的,这是 serverless 的固定的前提条件,并且不会改变。之前的实例都是没有历史记录的。他们甚至不能直接与其他运行在 serverless 上的实例进行通信。因此,除去发 Twitter 或写入数据库这类的消息之外,serverless 的实例只支持能有输入和返回值的纯函数。没有全局状态。
说实话,这时候你可能会想:哇,serverless 听起来好可怕。继续跟我往下看。
AWS Lambda 和 pywren 的参数映射函数
因此,会有这样的机器:
没有内在状态。
也不是很快。
但实际上,
这样的机器有很多。
并且只需在使用时付费。
这大大提升了数据科学家对此感兴趣的可能性!本文其余部分会介绍这部分内容,以及名为Phwren的概念验证工具,最早是在“占领云:99%的分布式计算”中被提及。尽管你之前可能没读过 CS 论文(或者读过一点儿),不过我强烈推荐这篇文章(或者早报的评论)。
下面是一张数据科学的图片,预示着我们即将进入本文的另一个新部分。

Pywren 是一个以 Lambda 作为计算后端,跨参数访问函数的工具。在 Python2 中,大概是这样:
map 函数调用了另一个函数(该例子中为 square 函数)以及函数所需要的参数,并返回这些程序的结果列表。在 Python3 中,由于 map 的计算速度比较慢(也就是,返回一个生成器,你可以立即使用,也可以稍后再用),这最终变得更加冗长。如果你没遇到这个问题,那就不用担心(其实我们还是需要担心的是,2019 年底,Python2 将不再被支持使用)。
如果你是 JS 或 Haskell 以及其他语言的程序员的话,可能对 map 不陌生。但如果你是一个 Python 程序员,可能对 map 函数一无所知。在 Python 的世界里面,更贴近的是 list 的结构内容,可以帮助你理解,表面看上去不一样,但基本的思想都是相同的:
Pywren 为 Python 的内置 map 函数提供了一个(几乎)直接的替代,对每个应用函数的参数都使用了一个独立的 AWS Lambda 实例,来替代本地机器。其语法如下:
其实,它也并不完全是 map 的直接替代品,因为它返回的是 futures 对象列表,而不是结果。但或多或少,你也可以从中得到一些信息。
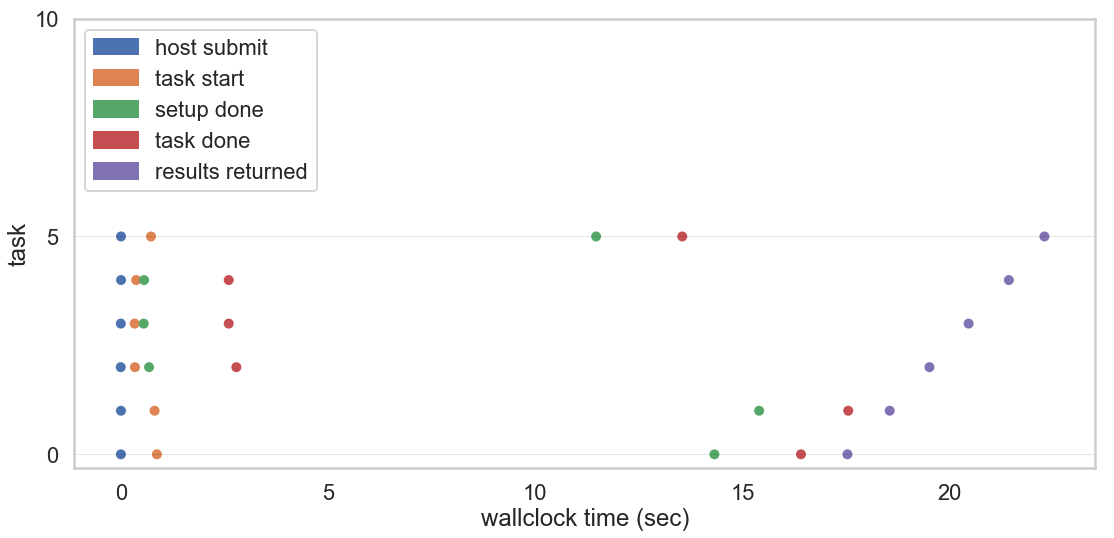
当我们使用 Pywren 的时候都发生了什么?以下是我的理解:
Pywren 将函数进行序列化并放到 S3 上,并引入 Lambda(上图中的“host submit”)。
Lambdas 开始工作(上图中的“task start”)。
他们需要做一些设置,包括从 S3 上提取和反序列化 job,以及安装 Anaconda Python 运行时机制(上图中的“setup done”)。
计算结果并写入 S3(“task done”),等待我们调用 result 方法。
当我们调用这个方法时,会把下载的结果返回给客户端(“result returned”)。
注意,顺便说一下,X 轴上的刻度。是的,我们并行做了很多事,但相对任务来说,开销(约 20 秒!)是巨大的。我们回过头再来讨论这个问题。
高度并行计算和胡萝卜问题
由于高度并行计算问题,square 函数只能作为 Pywren 的候选方案。这是为什么呢?
想象一下有一片胡萝卜地。总共 8 行,每行 10 个。你有一台收割机,每秒可以摘 1 根胡萝卜。那么,收割所有的胡萝卜需要用 80 秒。
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜
🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
如果有 2 台收割机会怎么样呢?他们可以独立工作,用一半的时间就可以收割这些胡萝卜。
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜
🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜
🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
🥕🥕🥕🥕🥕🥕🥕🥕🥕🥕
那么,要是有 8 台收割机,10 秒就能收割整片地。
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜
🥕🥕🥕🥕🥕🥕🥕🥕🥕🚜
因为拖拉机可以独立工作,速度与工人数量成正比。这个过程与共同编写一本书还是有差异的,因为两个作者需要经常交流,告诉对方各自到目前为止都完成了什么。但拖拉机是完全独立的。没有员工之间的交流。这就是并行。
在 Python 中,通常你会把它实现成列表的形式,就跟我们描述的典型问题一样。for 循环虽有副作用,但并不会引发高度并行问题。但如果把循环转换成我们理解的那样,那么也会有高度并行问题。
高度并行的 Pywren 示例:
现在,将前 6 位数进行平方计算是一件很酷的事,真实的工作原理又是怎样的呢?让我们看以下几个例子:
1. 网站检索
我想从某个会议网站上搜集成千上万的机器学习论文的摘要。因为我是一次性把它们都抓取出来,这样在我自己的电脑上会花费很长的时间。本来可以通过并行 CPU 上的任务来加快这个进程,但仍会受到网络连接速度带来的限制。
通过使用 pywren,将此场景转换为 lambda 的话,就可以并行工作//RH:我能够并行工作吗?同时,也得益于 AWS 更快的网络连接!代码大致如下:
这种情况下,将所有的论文列表都收集到一个论文上,并没有通过方法进行映射。相反地,我可以通过函数进行映射,该函数将一批文件剪贴到一批文件的列表上。我这样做是因为,处理一篇论文的速度相对比较快。那么如果每次处理一篇论文,这就意味着,主要的开销转嫁到设置 Lambda 的实例数量上面去了。不断在增加论文的数量,直到 20 秒左右的执行时间即可,最大限度地提高了速度。
以上是伪代码。如果感兴趣的话,完整的代码(以及生成的数据集)在GitHub上。
2. 布莱克-斯科尔斯方程
布莱克-斯科尔斯方程是描述股票期权演化的偏微分方程。布拉德福德·林奇解决数百万种构型的问题。每个解都是一个相当复杂的数值计算,需要几十秒。如果没有并行化,这项任务将在一台机器上执行 3 天的时间。在使用 pywren 的 AWS lambda 上,只需要 16 分钟。
3. 视频编码
视频编码算法的某些部分是高度并行的方式,因为它们一次只能执行一帧。“编码,快和慢:使用数千个小线程的低延迟来进行视频处理”一文中,描述了类似于 Pywren 的方法在这个问题上的应用。
比较有趣的是,因为在视频编码中有一个非常重要的速度阈值:你能以每秒 24(或 60)帧的速度编码吗?除此之外,你还处于实时视频编码领域,这将打开新型的用例。这一点也很有趣,因为与 Pywren 不同,这种方法并不会对单个批处理执行单个 lambda 提交;作者为正在进行的视频提供了一个长期存在的管道。Serverless 数据工程!
4. 超参数优化
一般来说,机器学习算法很难并行化。例如,在开始讨论分布的系统问题之前,分布式梯度下降就是一个著名的算法问题。
但是,ML 工作流中的一部分,非常适合 Pywren,即超参数优化。
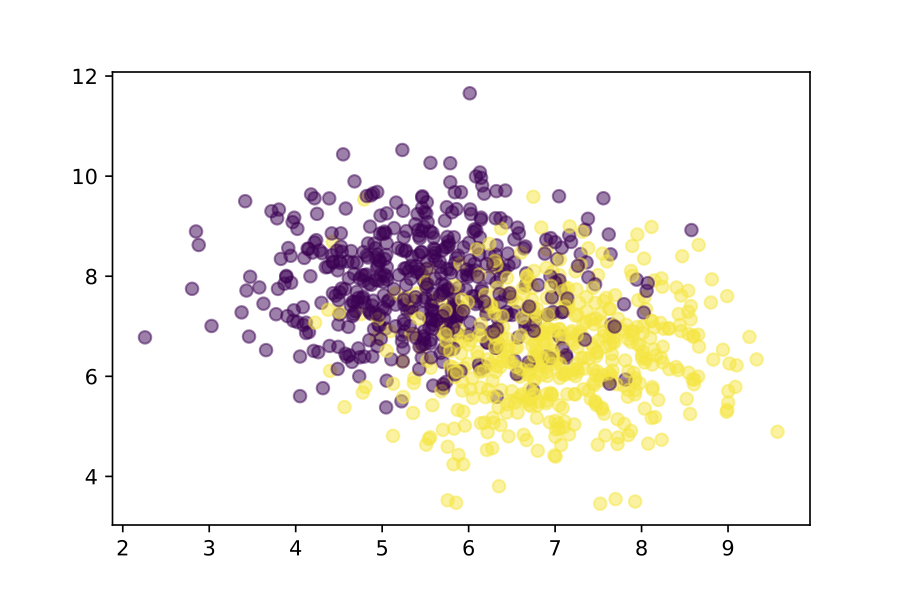
假设我们有一些训练数据,有两个类(黄色和紫色)和两个特性。我们可以使用 scikit-learn 在本地训练此数据模型。这是用来说明这个想法的幼稚的假设。不要纠结在这个验证的结果,想象一下这个场景背后的问题!
这里,n_neighbors 是一个“超参数”——ML 算法需要一个神奇的数字,你必须根据当前的问题逐层分析。在这种情况下,我们需要选择有多少的附近训练样本,来决定下一步的权重问题。
通常的方法是用一个简单的搜索方式:尝试所有可能的方法,并选择一个给出最精确模型。这是典型的高度并行的例子,所以我们可以使用 pywren!我们需要一个 n_neighbors 的值列表供我们测试,以及一个能返回经过训练的模型并映射到列表上的函数:
现在,我们可以将这个内容发送到 AWS lambda:
值得注意的是,pywren 不仅发送例如数字这种简单的结果。它还可以返回具有属性和方法的 Python 对象(在本例中,是经过训练的 SciKit 学习分类器)。这使我们能够使用本地测试集来计算每个模型的精度,并从笔记本电脑中,设置并选择最好的一个。
serverless 的机器学习活动
假设我们序列化最佳模型(显然 n_neighbors=7),并将其上传到到公共的 S3 中。这样我们就可以做最后的操作了!
还记得 Zappa 吗,我在本文开头演示的 CLI,可以帮助我们部署 flask 的应用。如果使用 zappa 来部署这个 Flask 应用程序,那么你在生产环境中,就可以进行机器学习了!
如果你不相信我的话,请访问已经部署的应用程序,更改 URL 参数尝试一下。
有一个完整的创业公司的具体实践,该方法通过 serverless 的基础设施,将机器学习引入到生产环境。在这里比上面的十几行 python 代码更加健壮和复杂。
更多的相关限制
文章开始的时候,我们谈及对 serverless(复杂性、锁定、成本)的工程性评论及其局限性(无状态、有限的 RAM 和生存周期)。
在结束之前,我想在数据科学的讨论内容中,添加一些内容。
首先,让我们解决一些对 lambda 实例规范的基本限制。如果单个函数应用程序花费的时间超过 900 秒,那么除非您将其分解为较小的原子任务,否则 AWS lambda 将无法发挥其作用。这可能很棘手。Lambda 实例没有 GPU,这限制了他们深度学习的效果。
其次,让我们更深入地来讨论一下算法。实际上 Pywren 只适合解决高度并行的问题。虽然 MapReduce 的工作是高度并行的,但他们大多数都会有重组的过程,这个过程里面,结果会被聚合在一起并分发出去,方便进一步处理。Pywren团队和其他人士已演示了将中间结果写入 S3 的解决方案。但此时,pywren 不再是 python map 函数的内置替代品。你需要更仔细地考虑将要并行化的算法结构。
幸运的是,在线性代数方面,Pywren 团队通过发布numpywren,为我们解决了一些问题。它听起来就像:从用户角度来看,一个与 numpy 非常相似的线性代数库。后端使用 AWS Lambda 来进行计算,但通过处理业务流程和所需的通信,将最快的算法应用于 serverless 的线性代数上,这远远超越了 Pywren。
结论
所以,你已经了解了 serverless 在网站部署和运行 cron 作业上的优点。最后你看到了,它在某一种计算上是很有优势的,也就是高度并行化的东西。你甚至可以结合这些思想,想象一个工作流:使用pywren在AWS lambda上运行超参数优化,然后使用zappa将最佳模型部署到AWS lambda上。serverless 在这些方面是很有优势的,因为它相对容易设置,并且使用起来很便宜。
它之所以便宜(不考虑本文中的高级原则),是因为这些应用程序有着共同点:它们都是突发式数据。有的时候他们需要大量资源,在这种情况下,lambda 可以通过扩展来容纳这些资源。但有时候,它们几乎或者完全不需要任何资源。你的 web 产品是新的,你的 cron 作业没有启动,或者你正在做交互式的工作,或者正在盯着笔记本,试图找出这结果意味着什么。这时如果你用了 serverless,你就不必再为这段时间花钱。
所以:serverless 的优势不在于你用它的时候它是多么强大(尽管扩张能力很强),而是在你不用它的时候。
AWS 不是为你使用的东西付费,而是为你忘记关掉的东西付费。-DeadProgrammer(@DeadProgrammer)2019年4月24日
还记得 Pywren 论文被称为“99%的分布式计算”吗?1%的数据科学在从事数据科学的组织中运作,其规模总是需要一些计算资源的,全球各地都在使用,所以几部不存在不使用的情况,又或者是他们的使用量非常大,相比较而言,购买集群机器更加合适(译者注:前提提到的曲线交点,超过交点,使用 Serverless 反倒费钱)。假如数据科学家有数据工程学、工具和维护团队,来处理这些长期使用的资源。本文中描述的 serverless,并不是为上述的这种数据科学家所准备的。
但是,如果你是独立运营的,并且没有资金和工程学支持的团队,或对重量级解决方案没有什么兴趣,那么就了解一下 Zappa、Pywren 和 serverless 生态系统吧。
感谢大家来参加我的 TED 演讲。
英文原文:
serverless-for-data-scientists

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论