

刚刚过去的 2020,对蚂蚁自研数据库产品 OceanBase 是一个丰收年。
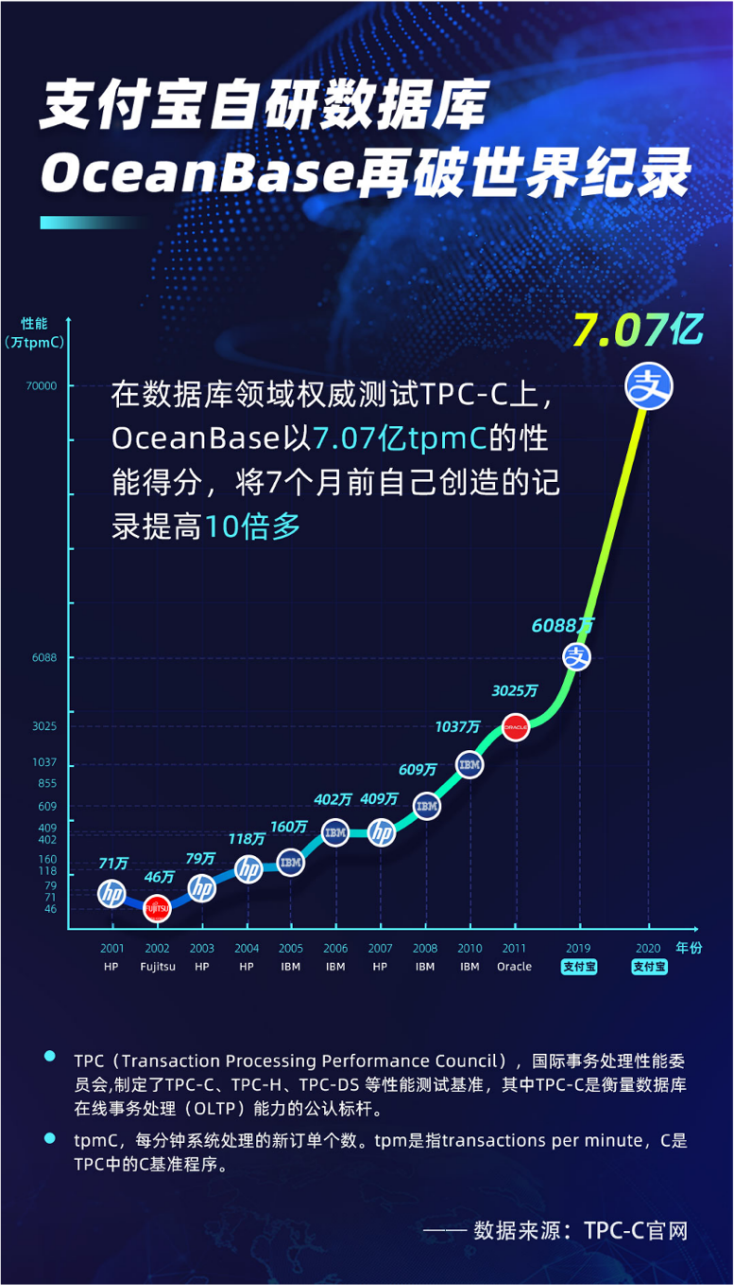
先是在五月,数据库领域最权威的国际机构国际事务处理性能委员会 TPC 在官网发表了最新的 TPC-C 基准测试结果, OceanBase 以 7.07 亿 tpmC 的在线事务处理性能,打破了自己在 2019 年创造的世界纪录,在国内数据库领域可以说是赚足了眼球。
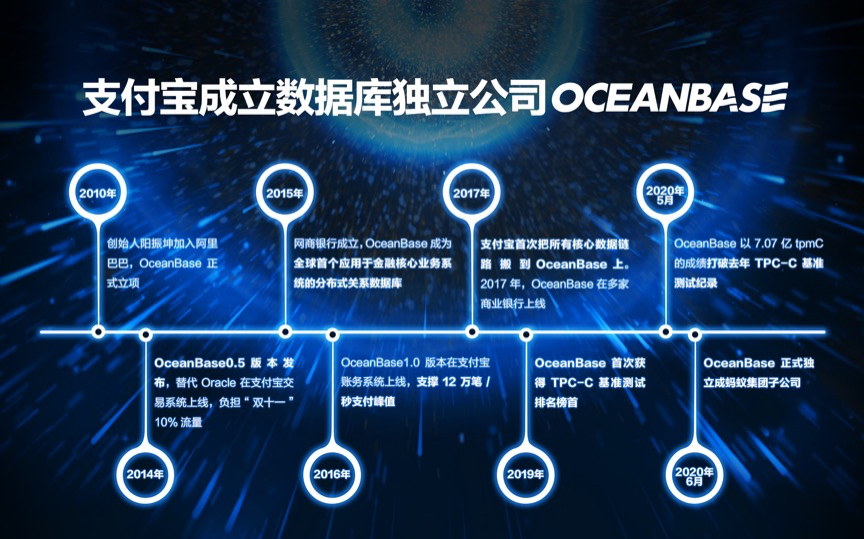
一个月后,蚂蚁集团宣布,将自研数据库产品 OceanBase 独立进行公司化运作,成立由蚂蚁 100% 控股的数据库公司—北京奥星贝斯科技有限公司,并由蚂蚁集团 CEO 胡晓明亲自担任董事长。
工商银行,中石化,太平保险,招商证券,广东顺德农商行,浙江移动,山东移动,福建移动,吉林省大数据局,深圳公积金……去年 6 月,OceanBase 独立公司化运作以来,在短短半年时间,已经拿下数十个标杆客户。
OceanBase 为何选择独立运营?这半年多来,市场对这个数据库领域的“新兵”有什么反应?近期,InfoQ 采访了 OceanBase 市场部总经理刘昕,希望能够以一种全新的视角来呈现最全面的 OceanBase。
认认真真做数据库
OceanBase 是认认真真在做数据库,不是为了资本炒作的概念,而是真正当成一门生意来做,对客户如此,对内部也是如此。
数据库属于基础设施建设部分,是基础软件中的刚需但又很容易被卡脖子的技术。在 2020 年 6 月科技日报发布了制约我国工业发展的 35 项技术,数据库管理系统即名列其中。
在过去,蚂蚁甚至是阿里都遇到过数据库被卡脖子的痛苦。以淘宝、天猫和支付宝等为代表的互联网业务使得关系数据库的并发访问由几百、几千陡增到百万、千万,数据量的增长也同步加重了数据库的性能负荷,来自于容量和成本的挑战远远高于传统业务场景,而传统关系数据库因为水平扩展能力的缺失以及高昂价格,让业务发展和产品迭代无以为继,只能进行自研,这正是 OceanBase 诞生的背景。
从 2011 年承担淘宝收藏夹这一小功能开始,到成功替代 Oracle 在支付宝交易系统上线,支撑起 12 万笔每秒的交易峰值,2015 年 OceanBase 成为全球首个应用在金融核心业务系统中的分布式关系数据库,2017 年支付宝首次将账务库在内的所有核心数据链搬到 OceanBase 上,创造了 4200 万次 / 秒的数据库处理峰值全新记录,再到 2019 和 2020 两次登顶 TPC-C 榜首,OceanBase 走过了艰难但辉煌的旅程,不仅支持了业务发展,也在世界面前证明了自己。
不过,作为此前曾服务于淘宝、天猫和支付宝等业务的数据库,大量内部业务不仅彰显了 OceanBase 的价值,更使得它得到了大量的生产考验,极大地促进了 OceanBase 的稳定和成熟。但是,要想进一步受到外界认可为通用数据库,这就需要一个更复杂多变、更庞大的商业场景来进一步历练。而这个因素,就是市场。
让 OceanBase 蜕变为一个有能力服务全行业、服务全社会的通用关系数据库,蚂蚁集团责无旁贷,独立运营,刻不容缓。
生态:面对客户的第一道难题
当 OceanBase 从对内服务的技术变为对外提供服务的角色时,被挑战的第一个问题就是生态。OceanBase 团队对自己的数据库非常自信,但来自于客户的一个质疑,却成为了团队需要面对的第一道坎。
“我承认 OceanBase 这款数据库很厉害,互联网上最大的交易流量都是在 OceanBase 上跑的。不过这不像 Oracle、MySQL,最初公司里没有人会用啊。”
是的,摆在独立运营的 OceanBase 面前,最紧急的就是生态问题,一款产品再好,也需要有人会用。毕竟使用数据库的是一线技术人员,没有这些使用者,又何来规模化可言。
这是一个非常现实的问题,由于独立运营之前 OceanBase 一直是在为内部提供服务,没有对外开放就难以与外部行业产生技术共鸣,更不要提相关的技术人才。
“为此,OceanBase 投入了巨大的力量在生态层面。”刘昕解释说,OceanBase 的生态分为商业生态、人才生态、开发者生态以及产业链生态这 4 个层面。
产业链生态层面,具体是指行业规范与产业标准,OceanBase 通过与工信部权威机构共同建立分布式数据库的行业标准以及信创标准等方式,来减少上下游能力在数据适配层面上的门槛,引导行业发展的方向。
商业生态层面,商业数据库与开源数据库不同,其要为公司增长负责,因此需要深入到各行各业的真实场景中,形成与各开发商的联合解决方案,这对于完善商业生态来说是重中之重。因为数据库本身是一个被集成的软件,对于企业而言,应用系统背后的数据库是无形的且和业务深度关联的产品,因此数据库需要和应用开发商深度合作以完成联合解决方案,并切实能够解决问题。
人才生态层面,目前 OceanBase 计划在三年内培养五万名分布式数据库的人才,去年 9 月份推出 OceanBase 初级工程师认证,短短两个月时间就有数千人通过了认证。另外长期来看,OceanBase 和华东师范大学、复旦大学、浙江大学、武汉大学等高校都有学研合作,从学生中培养分布式数据库的人才。这种需要花费大量精力以及长期合作的形式,恰恰印证了 OceanBase 对于分布式是未来发展方向的信心。
开发者生态层面,目前 OceanBase 已经对外推出了 OceanBase 开发者版本,开发者可以免费拿到与商业版相似、在笔记本上就可以实现的数据库工具。现在因为疫情的反复,OceanBase 投入了非常多的精力在视频、直播、课程等线上形式,以求尽可能快速触达到广泛的开发者群体。
随后刘昕坦言,OceanBase 成立公司独立运营后,公司内部最大的变化一个是在生态方面强有力的发展,另一个则是公司技术团队的工作习惯变化。
在团队的组织架构层面,公司在规划筹备时就已经发现,由于之前都是服务于内部业务,因此不需要考虑市场、销售、客户等因素,所以公司成立之初基本上是以程序员为主。不过既然决定要做软件生意,在团队生态方面就一定要建制完全。所以 OceanBase 在独立运营之后,以非常快的速度扩充了运营规模,组建了自己的商业化团队。
另一方面,在独立运营了半年多后,这期间所服务的客户比过去几年来所产生的工作强度之和都要大。因为之前都是服务于内部业务,内部相对来说技术需求比较多,并且时间相对充裕,比如双十一的活动形式是怎样的,技术团队提前两三个月就已经知道并开始准备。但是面向外部客户,并不是每个客户都能把技术需求很好的传递过来,因此技术团队的工作节奏与之前相比也变得更加紧凑,并且时间上也相对变得不可控起来。所以对于团队而言,技术团队的变化从之前埋头于代码,现在更多开始向客户支持侧转型,这也从另一个层面代表着公司的转型。
性能:给到客户的核心价值
企业关注的无非是:从 5 秒 1 单到 1 秒千单,从 4 个小时到 6 分钟的进化结果。
数据库作为企业基础设施中的重要组成部分,对于所有用户而言,选择数据库的标准无非就是能否支持高并发、分布式、性能情况、硬件费用成本的高低等等。
但是今天,我们还多了一项所关注的因素,就是未来趋势。目前国内愿意做出改变的企业都相信分布式是未来,国内企业对于“改变”的接受程度较高,且效果明显。集中式架构所带来的效率降低,以及由于业务快速变化与合规要求的矛盾正在越来越明显。
而这种来自于业务上的变化也正在将传统企业与互联网企业更加紧密地联系在一起。传统企业都在做互联网 + 的转型,互联网企业也在结合传统企业能力来做线上 + 线下的转型,这就意味着企业无法使用过去传统集中式的体系来适应这种环境。
若要适应,则必须做出改变。
以中国人保健康为例,保险行业在互联网下的形态就是互联网保险业务。过去人保健康的后台需要离线处理保单,系统效率平均下来每单需要耗费 5 秒的时间。后来开始与支付宝业务进行合作,平台对接后支付宝的流量瞬间冲垮了人保健康传统的集中式系统,同时由于集中式架构横向扩展能力差,难以支撑大数据、人工智能等新兴应用,在业务系统方面则体现为出单时间长、新品上线时间长,服务失效长,带给用户的体验较差。

因此他们开始寻求改造。在以 OceanBase 为核心运算处理 DB 的新型架构下,目前业务日常出单速率在 3400/min 上下。处理能力也从过去的 5 秒 1 单到现在每秒千单,系统保单的处理速度从 4 个小时缩短为 6 分钟,新产品上线时间缩短 80% 以上,外部渠道的接入效率提升了 6 倍有余,目前已经成为人保健康互联网保险云核心业务系统的数据库。
用全新的容灾思路,找回数据库丢失的时间
另外一方面,用户十分在意的就是数据库的灾备问题。
传统的数据库容灾方案一般会部署主备方式工作的两套或多套系统,两地三中心的部署方式在同城的两个机房中部署主备两个系统以及异地一个异步同步的系统来提供数据容灾的体系。这种容灾方式有两个不足,一个是主库的业务可用性和数据保护能力难以兼顾,另一方面业务的恢复时间无法有效保障。
1. 主库的业务可用性和数据保护能力难以兼顾
对于主备这种保护方式而言,数据一致性是确保业务恢复后不造成损失的重要前提。若要保护数据一致性,采用强同步复制方式是可以实现 RPO=0,即可以实现灾难切换后数据无损,切换后立刻开始恢复业务,但这样做会带来另一方面的影响,因为只有当主库和备库同时提交才会被视作为成功,主备之间强依赖于硬件性能和端到端的可用性,对于网络波动和备库故障等所造成的影响会导致主库的性能波动甚至于阻塞,如果因为这些不可控的问题而带来的主库处理阻塞进而影响到正在行进中的业务,这对于企业的关键业务来说是绝对不可接受的。
2. 业务的恢复时间无法有效保障
如果要解决上述的影响,通常会采用异步复制的方式,主库的提交与向备库的同步异步完成,不过这种异步同步是做不到严格的 RPO=0 的,当主库出现问题时,由于可能会缺失部分故障前的数据,恢复过程会非常复杂,这就会拖长业务恢复的时间,不同的应用系统、不同的业务环境,对于数据的敏感度是不同的,体量越大恢复越复杂。比如支付宝这种,一小时的系统不可用,所造成的损失可想而知。这种对于用户和平台来说不可用的时间,是无论如何也弥补不回来的业务损失。
针对这些问题,刘昕解释说,解决上述问题正是分布式数据库的优势所在。Paxos 协议是分布式领域内基于多副本自选主一致性协议的公认标准,OceanBase 数据库正是基于这一协议构建的,因此得以利用原生的多副本特性,只要多数副本确认,事务就可以提交成功,实现对数据 RPO=0 的持续保护,不必担心单个远端机房响应慢的问题,所有组成集群的多副本实质上处于同一个数据库集群中,集群中的分布式事务可以实现多数派强一致提交和主备副本自动切换,通过对数据强一致的充分保障,并且对上层业务保持透明,从而为更低的 RTO 时间提供实现前提。
另外刘昕提到,目前 OceanBase 的灾备能力标准是高于国标灾备等级 6 级的标准,目前 6 级的范围是 RPO 为 0,RTO 数分钟以内。
不断寻找更高的效率,持续突破更快的速度,帮助业务将损失降到最低,弥补对于用户和平台而言那些可能丢失的时间,这就是 OceanBase 的答案。
最 后
技术层面,OceanBase 自然是数一数二,不过 OceanBase 生态也并非完美,它也有着自己的不足。
刘昕认为,OceanBase 目前的不足主要集中在开发者生态和产品行业技术方面。
经过不到一年的发展,尽管目前 OceanBase 已经拥有了数千开发者,但距离大规模扩展还有很长的路要走。另外,当一款产品持续向行业深水区迈进时,会不断发现更多的应用场景、更多的特殊需求以及更多的可能性,而这些都是需要 OceanBase 去服务、去提供的,不过也正是这些不同的诉求,驱使着 OceanBase 需要不断丰富自身技术框架来满足市场。
互联网的海量并发和巨大数据量标志着传统的单机数据库系统走到了尽头,分布式系统成为关系数据库系统的必然选择。经过 OceanBase 以及其它数据库持续不断的市场教育,目前分布式数据库在国内的接受程度已经相当高了,需求方愿意使用分布式数据库,参与分布式生态的共建与打磨的进程中来。需求侧愿意共创,供给侧则愿意持续精进自己的技术能力,国内的数据库市场已经进入到良性发展的状态。
让数据管理和使用更简单,这是 OceanBase 团队的梦想,他们也一直在向着这样的愿景努力。而我们也有理由期待,目前百花齐放的国产数据库市场,正在向着最有未来的方向前进。
受访者介绍:刘昕,北京奥星贝斯科技有限公司市场部总经理 。2011 年加入阿里巴巴,曾负责阿里集团开源项目管理。从 0 到 1 搭建了阿里集团开发运维后端体系、阿里云开发者服务和产品体系。目前负责分布式关系数据库 OceanBase 的市场统筹与管理,以及市场战略的制定。全面主持市场推广、品牌、公关活动、市场合作等工作。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论