OpenAI o1 和 o3 模型的发布证明了强化学习能够让大模型拥有像人一样的快速迭代试错、深度思考的高阶推理能力,在基于模仿学习的 Scaling Law 逐渐受到质疑的今天,基于探索的强化学习有望带来新的 Scaling Law。
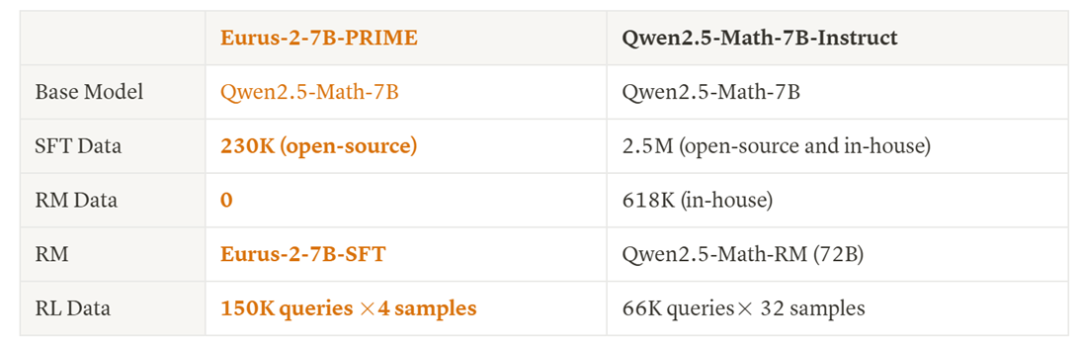
近日,清华大学 NLP 实验室联合上海 AI Lab,清华大学电子系及 OpenBMB 社区提出一种新的结合过程奖励的强化学习方法—— PRIME(Process Reinforcement through IMplicit REwards),采用 PRIME 方法,研究人员不依赖任何蒸馏数据和模仿学习,仅用 8 张 A100,花费一万块钱左右,不到 10 天时间,就能高效训练出一个数学能力超过 GPT-4o、Llama-3.1-70B 的 7B 模型 Eurus-2-7B-PRIME。
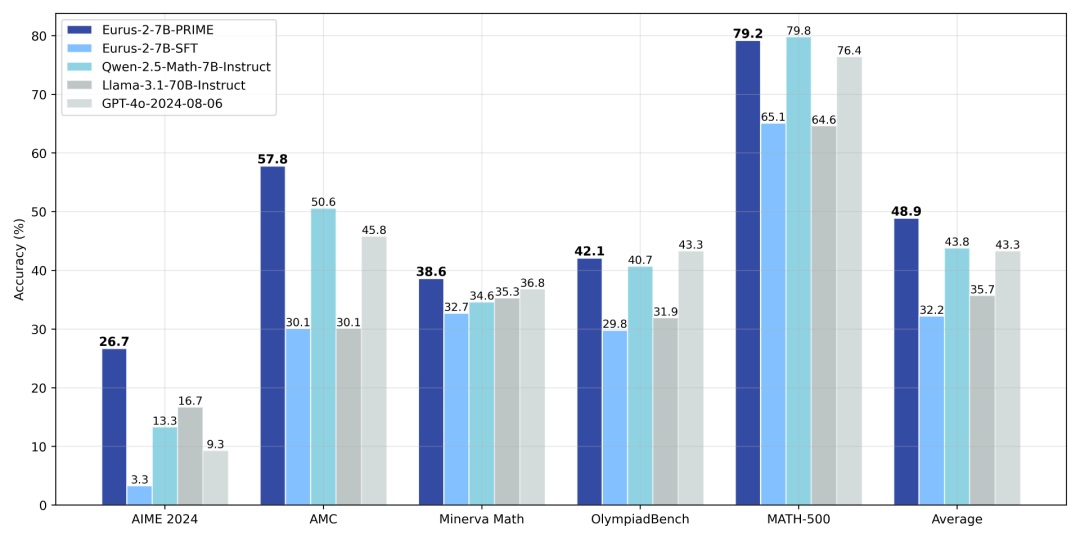
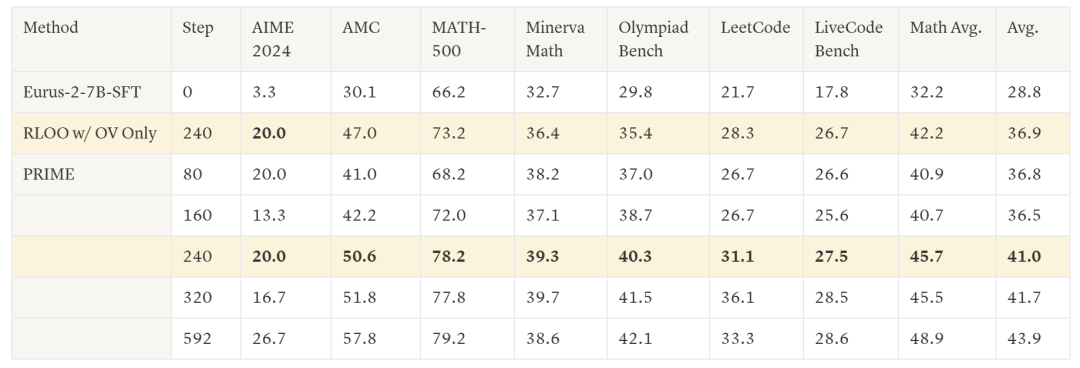
具体而言,研究人员利用 Qwen2.5-Math-7B-Base 作为基座模型,训练出了新模型 Eurus-2-7B-PRIME ,并在美国 IMO 选拔考试 AIME 2024 上的准确率达到 26.7%,大幅超越 GPT-4o,Llama3.1-70B 和 Qwen2.5-Math-7B-Instruct,且仅使用了 Qwen Math 数据的 1/10。其中,强化学习方法 PRIME 为模型带来了 16.7% 的绝对提升,远超已知的任何开源方案。
该项目一经开源就在海外 AI 社区爆火,短短几天 Github 取得 400+ star。
未来,基于 PRIME 方法和更强的基座模型有潜力训练出接近 OpenAI o1 的模型。

_GitHub 链接:_https://github.com/PRIME-RL/PRIME
PRIME 方法介绍
长久以来,开源社区严重依赖数据驱动的模仿学习来增强模型推理能力,但这种方法的局限也显而易见——更强的推理能力需要更高质量的数据,但高质量数据总是稀缺,使得模仿和蒸馏难以持续。虽然 OpenAI o1 和 o3 的成功证明了强化学习有着更高的上限,但强化学习有着两个关键挑战:(1)如何获得精准且可扩展的密集奖励;(2)如何设计可以充分利用这些奖励的强化学习算法。
PRIME 算法从隐式过程奖励(implicit process reward)的思想出发解决这两个问题。隐式过程奖励模型可以仅在输出奖励模型(outcome reward model, ORM)的数据,即答案的最终对错上进行训练,而隐式地建模过程奖励,最终自动训练出一个过程奖励模型,这整个过程都有严格的理论保证。
_详细推导见:_https://huggingface.co/papers/2412.01981
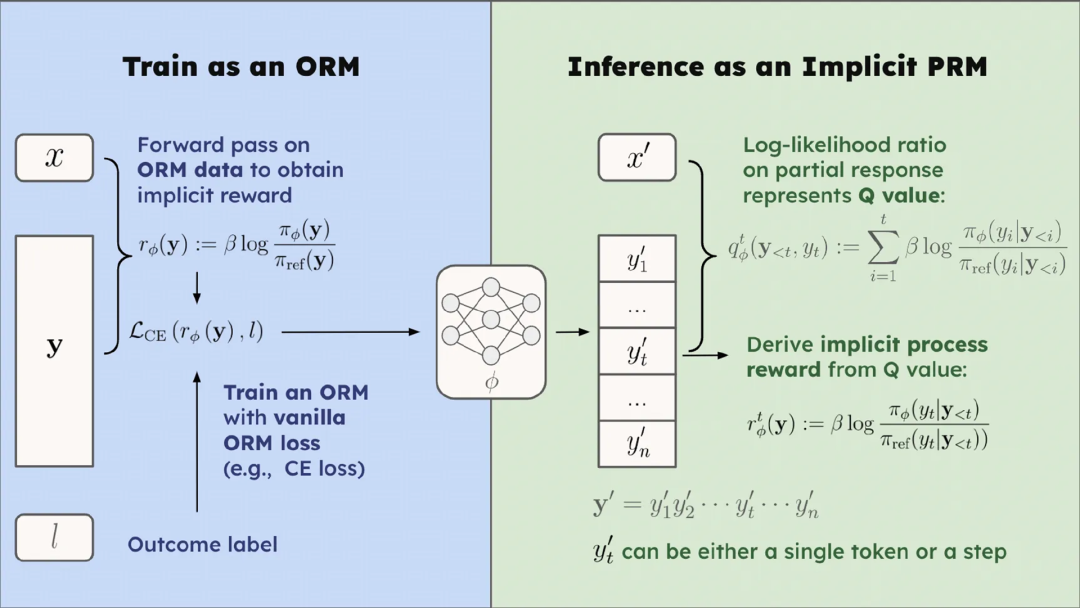
基于隐式过程奖励模型的这种性质,研究人员指出将其应用于强化学习有三大优势:
过程奖励:隐式过程奖励模型能够为每个 token 提供价值估计,在提供过程奖励的同时无需训练额外的价值模型(value model)
可扩展性:隐式过程奖励模型只需结果标签即可在线更新。所以,我们可以结合策略模型采样与结果验证器来直接更新 PRM,有效缓解分布偏移与可扩展性问题。
简洁性:隐式过程奖励模型本质上就是一种语言模型。在实践中,研究人员发现可以直接用初始的策略模型初始化 PRM。
隐式过程奖励解决了 PRM 在大模型强化学习中怎么用,怎么训,怎么扩展的三大问题,甚至不需要训练额外的奖励模型就可以开始强化学习,易用性和可扩展性极佳。
具体的 PRIME 算法流程如下图所示,它是一种在线强化学习算法,能够将每个 token 的过程奖励无缝应用于强化学习流程中。
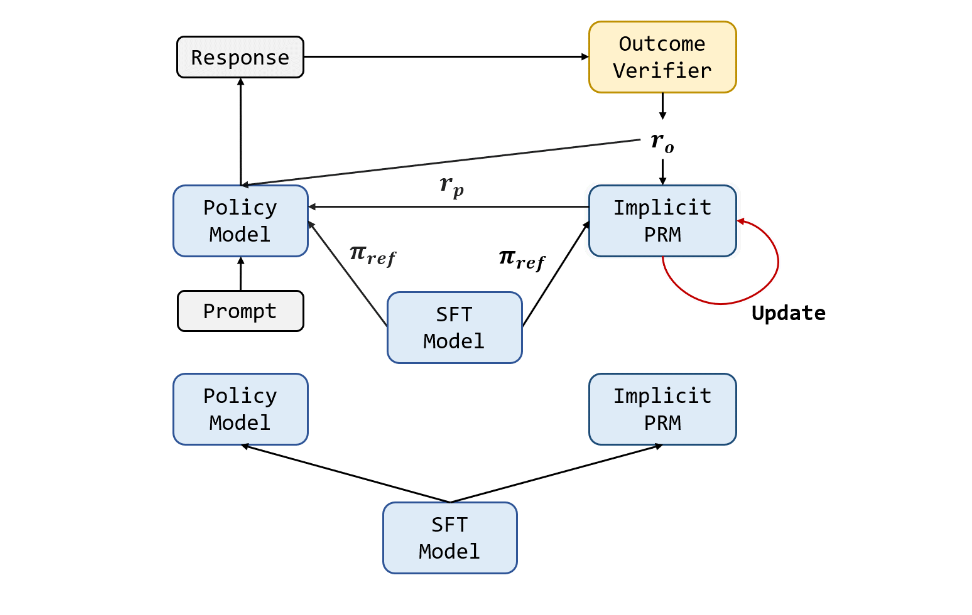
实验结果
研究人员详细比较了 PRIME 算法和基线方法
相比于仅用结果监督,PRIME 有着 2.5 倍的采样效率提升,在下游任务上也有着显著提升。
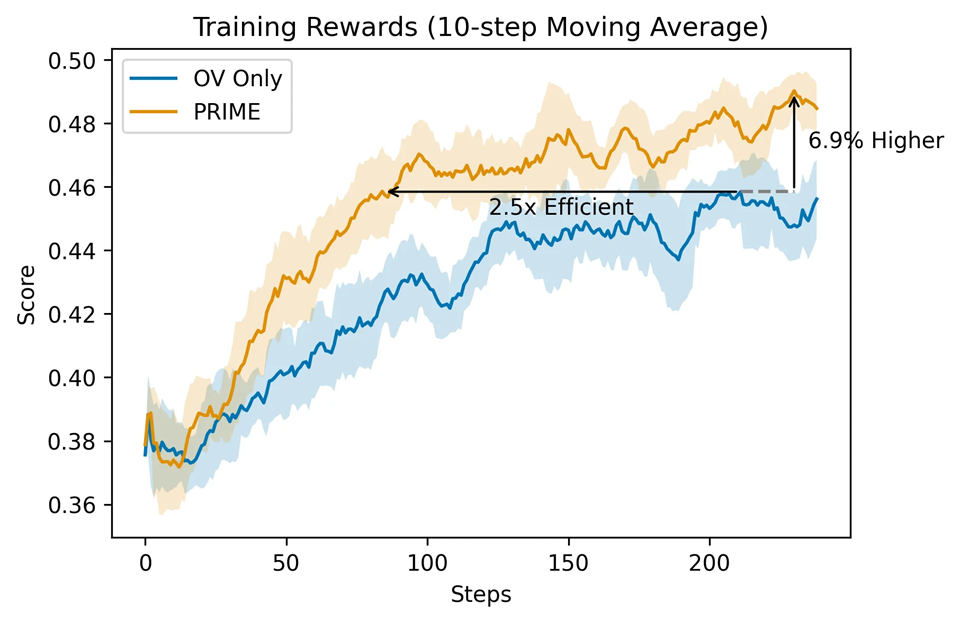
研究人员还验证了 PRM 在线更新的重要性,可以看到,在线的 PRM 更新要显著优于固定不更新的 PRM,这也证明了 PRIME 算法设计和合理性
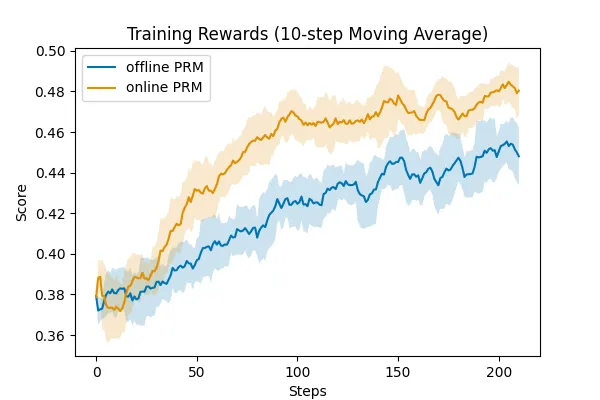
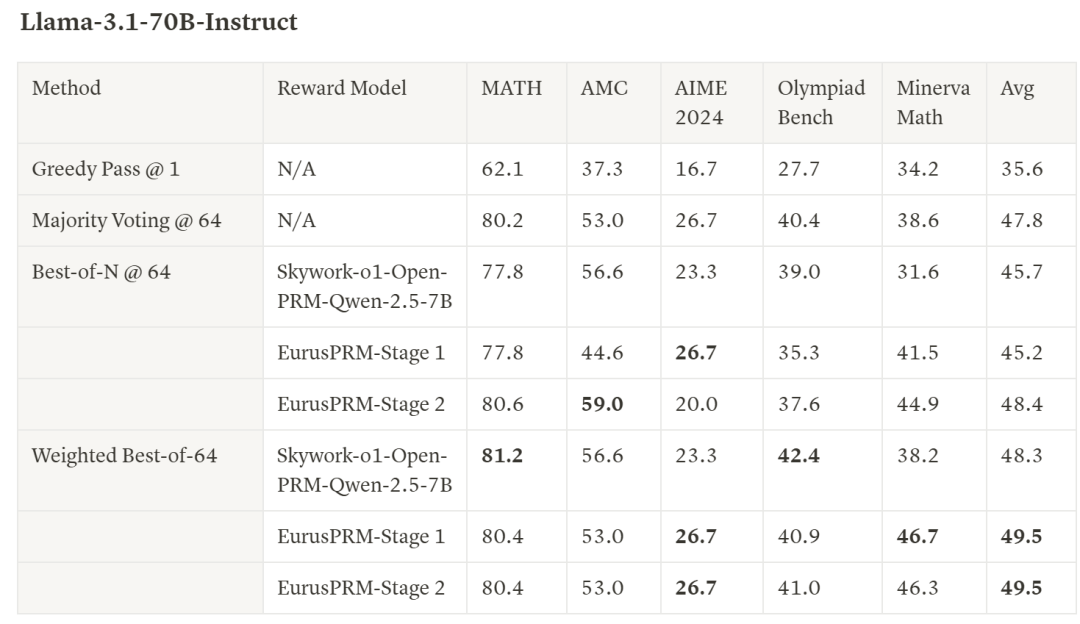
此外,研究人员还额外收集数据,基于 Qwen2.5-Math-Instruct 训练了 SOTA 水平的 EurusPRM,能够在 Best-of-N 采样中达到开源领先水平
showcase 演示
Question (AIME 2024 试题,Claude-3.5-Sonnet 做错)

Answer

Question
Which number is larger? 9.11 or 9.9?
Answer

强化学习是连接已有智能体(大模型)和现实世界(世界模型,具身智能)的桥梁,以及将世界反馈内化为模型智能的路径,将在下一代人工智能的发展中起到重要作用。PRIME 算法创新性地将隐式过程奖励与强化学习结合,解决了大模型强化学习的奖励稀疏问题,有望推动大模型复杂推理能力的进一步提升。
该工作在海外 AI 社区受到了很大欢迎: