

Linux 具有功能丰富的网络协议栈,并且兼顾了非常优秀的性能。但是,这是相对的。单纯从网络协议栈各个子系统的角度来说,确实做到了功能与性能的平衡。不过,当把多个子系统组合起来,去满足实际的业务需求,功能与性能的天平就会倾斜。
容器网络就是非常典型的例子,早期的容器网络,利用 bridge、netfilter + iptables (或 lvs)、veth 等子系统的组合,实现了基本的网络转发;然而,性能却不尽如人意。原因也比较明确:受限于当时的技术发展情况,为了满足数据包在不同网络 namespace 之间的转发,当时可以选择的方案只有 bridge + veth 组合;为了实现 POD 提供服务、访问 NODE 之外的网络等需求,可以选择的方案只有 netfilter + iptables(或 lvs)。这些组合的技术方案增加了更多的网络转发耗时,故而在性能上有了更多的损耗。
然而,eBPF 技术的出现,彻底改变了这一切。eBPF 技术带来的内核可编程能力,可以在原有漫长转发路径上,制造一些“虫洞”,让报文快速到达目的地。针对容器网络的场景,我们可以利用 eBPF,略过 bridge、netfilter 等子系统,加速报文转发。
下面我们以容器网络为场景,用实际数据做支撑,深入分析 eBPF 加速容器网络转发的原理。
网络拓扑
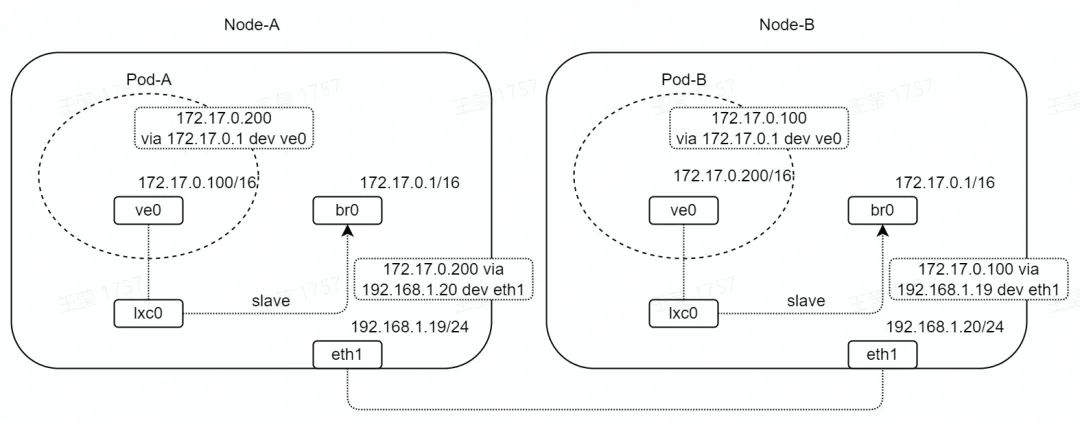
如图,两台设备 Node-A/B 通过 eth1 直连,网段为 192.168.1.0/24。
Node-A/B 中分别创建容器 Pod-A/B,容器网卡名为 ve0,是 veth 设备,网段为 172.17.0.0/16。
Node-A/B 中分别创建桥接口 br0,网段为 172.17.0.0/16,通过 lxc0(veth 设备)与 Pod-A/B 连通。
在 Node、Pod 网络 namespace 中,分别设置静态路由;其中,Pod 中静态路由网关为 br0,Node 中静态路由网关为对端 Node 接口地址。
为了方便测试与分析,我们将 eth1 的网卡队列设置为 1,并且将网卡中断绑定到 CPU0。
bridge
bridge + veth 是容器网络最早的转发模式,我们结合上面的网络拓扑,分析一下网络数据包的转发路径。
在上面网络拓扑中,eth1 收到目的地址为 172.17.0.0/16 网段的报文,会经过路由查找,走到 br0 的发包流程。
br0 的发包流程,会根据 FDB 表查找目的 MAC 地址归属的子接口,如果没有查找到,就洪泛(遍历所有子接口,发送报文);否则,选择特定子接口,发送报文。在本例中,会选择 lxc0 接口,发送报文。
lxc0 口是 veth 口,内核的实现是 veth 口发包,对端(peer)的 veth 口就会收包。在本例中,Pod-A/B 中的 ve0 口会收到报文。
至此,完成收包方向的主要流程。
当报文从 Pod-A/B 中发出,会先在 Pod 的网络 namespace 中查找路由,假设流量从 Pod-A 发往 Pod-B,那么会命中我们之前设置的静态路由:172.17.0.200 via 172.17.0.1 dev ve0,最终报文会从 ve0 口发出,目的 MAC 地址为 Node-A 上面 br0 的地址。
ve0 口是 veth 口,和收包方向类似,对端的 veth 口 lxc0 会收到报文。
lxc0 口是 br0 的子接口,由于报文目的 MAC 地址为 br0 的接口地址,报文会经过 br0 口上送到 3 层协议栈处理。
3 层协议栈会查找路由,命中我们之前设置的静态路由:172.17.0.200 via 192.168.1.20 dev eth1,最终报文会从 eth1 口发出,发给 Node-B。
至此,完成发包方向的主要流程。
上面的流程比较抽象,我们用 perf ftrace 可以非常直观地看到报文都经过了哪些内核协议栈路径。
收包路径
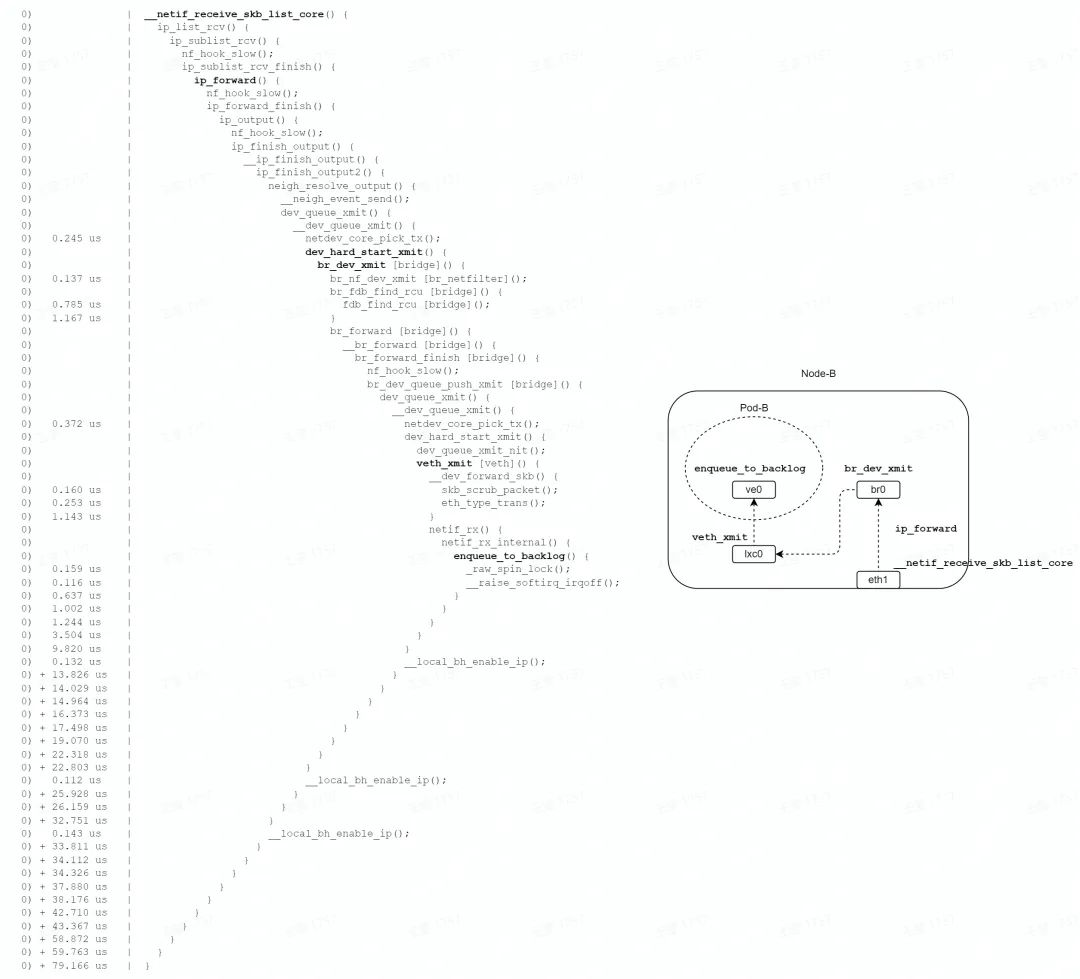
如图,收包路径主要经历路由查找、桥转发、veth 转发、veth 收包等阶段,中间多次经过 netfilter 的 hook 点。
最终调用 enqueue_to_backlog 函数,数据包暂存到每个 CPU 私有的 input_pkt_queue 中,一次软中断结束,总耗时 79us。
但是报文并没有到达终点,后续软中断到来时,会有机会调用 process_backlog,处理每个 CPU 私有的 input_pkt_queue,将报文丢入 Pod 网络 namespace 的协议栈继续处理,直到将报文送往 socket 的队列,才算是到达了终点。
综上,收包路径要消耗 2 个软中断,才能将报文送达终点。
发包路径
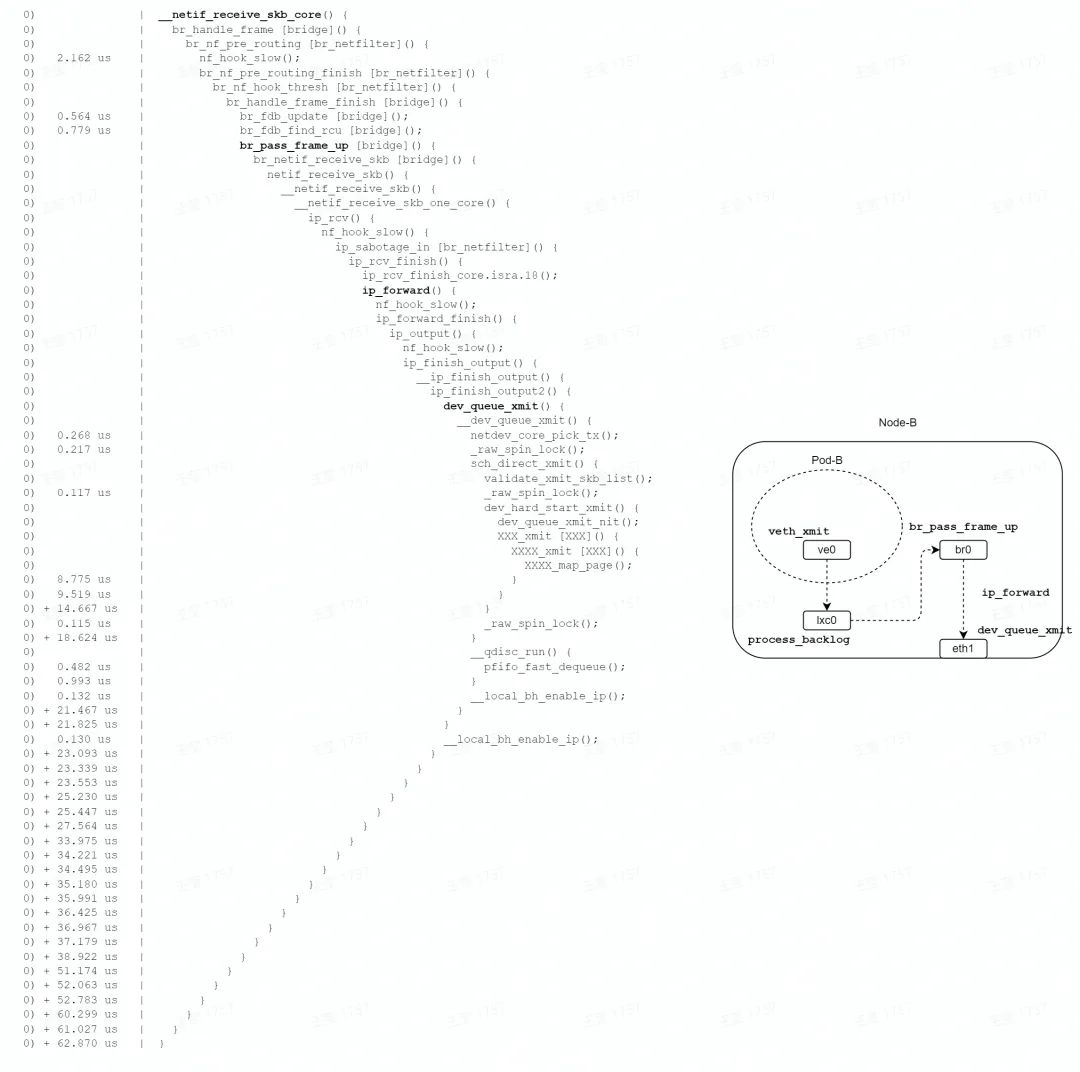
如图,发包路径主要经历 veth 收包、桥上送、路由查找、物理网卡转发等阶段,中间多次经过 netfilter 的 hook 点 。
最终调用网卡驱动发包函数,一次软中断结束,总耗时 62us。
分析
由 perf ftrace 的结果可以看出,利用 bridge + veth 的转发模式,会多次经历 netfilter、路由等子系统,过程非常冗长,导致了转发性能的下降。
我们接下来看一下,如何用 eBPF 跳过非必须的流程,加速网络转发。
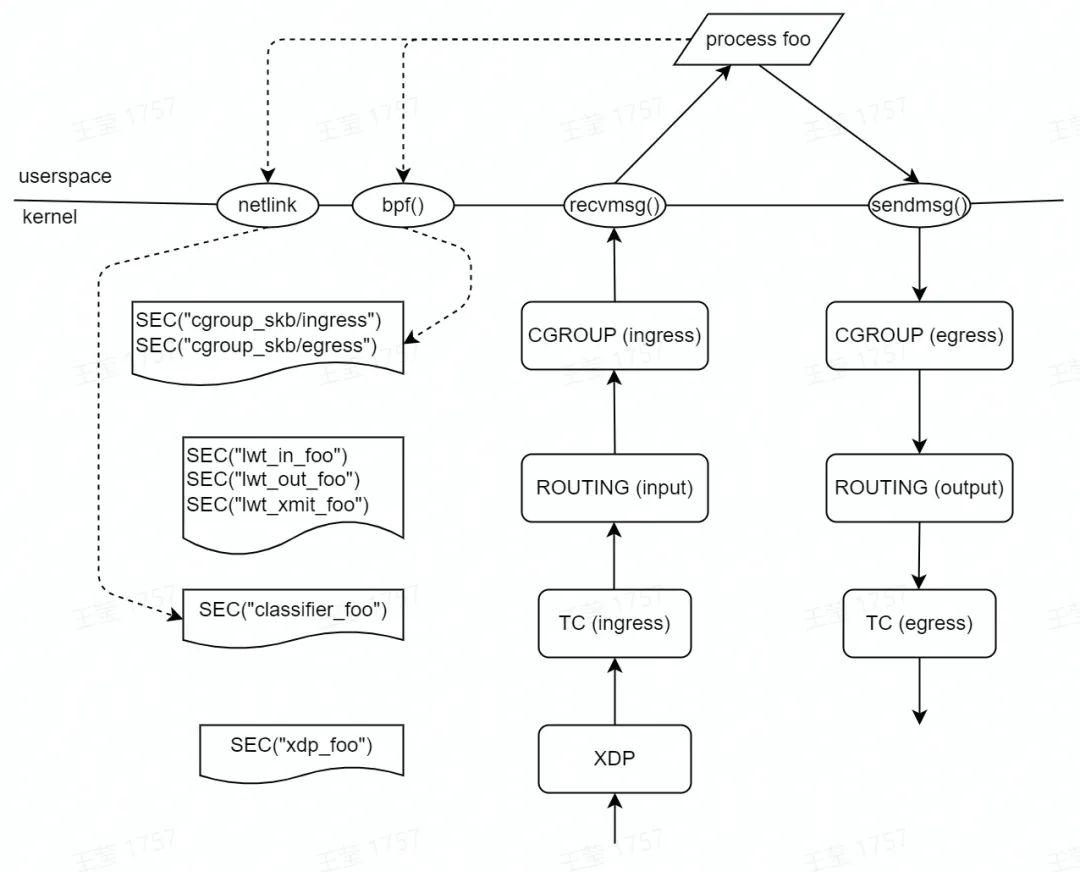
首先,我们先看一下内核协议栈主要支持的 eBPF hook 点,在这些 hook 点我们可以注入 eBPF 程序,实现具体的业务需求。
我们可以看到,与网络转发相关的 hook 点主要有 XDP(eXpress Data Path)、TC(Traffic Control)、LWT(Light Weight Tunnel)等。
针对于容器网络转发的场景,比较合适的 hook 点是 TC。因为 TC hook 点是协议栈的入口和出口,比较底层,eBPF 程序能够获取非常全面的上下文(如:socket、cgroup 信息等),这点是 XDP 没有办法做到的。而 LWT 则比较靠上层,报文到达这个 hook 点,会经过很多子系统(如:netfilter)。
加速收包路径
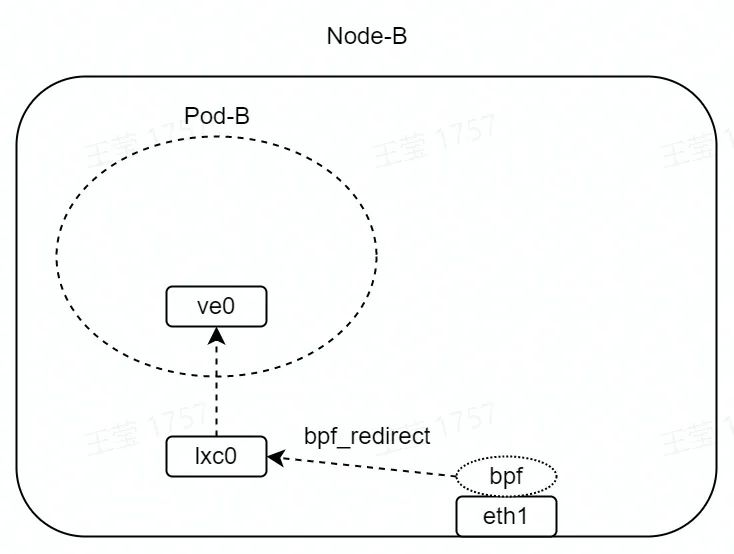
如图,在 eth1 的 TC hook 点(收包方向)挂载 eBPF 程序。
eBPF 程序如下所示,其中 lxc0 接口的 index 为 2。bpf_redirect 函数为内核提供的 helper 函数,该函数会将 eth1 收到的数据包,直接转发至 lxc0 接口。
加速发包路径
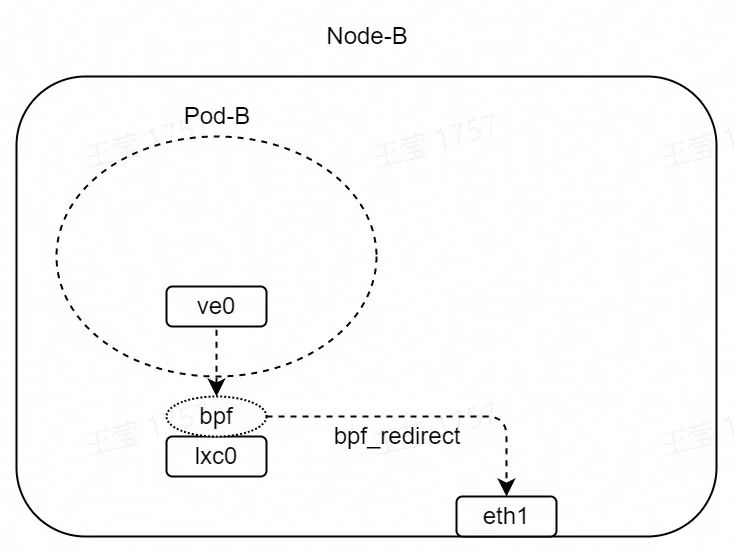
如图,在 lxc0 的 TC hook 点(收包方向)挂载 eBPF 程序。
eBPF 程序如下所示,其中 eth1 接口的 index 为 1。bpf_redirect 函数会将 lxc0 收到的数据包,直接转发至 eth1 接口。
分析
由上面的操作可以看到,我们直接跳过了 bridge 的转发,利用 eBPF 程序,将 eth1 与 lxc0 之间建立了一个快速转发通路。下面我们用 perf ftrace 看一下加速效果。
收包路径
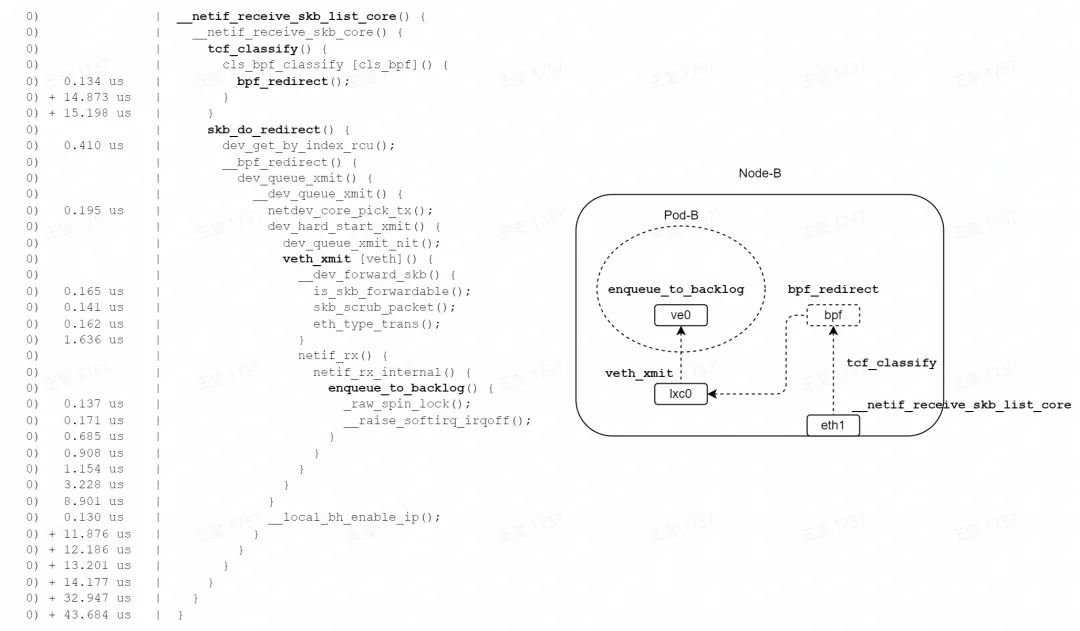
如图,在收包路径的 TC 子系统中,由 bpf_redirect 函数设置转发信息( lxc0 接口 index),由 skb_do_redirect 函数直接调用了 lxc0 接口的 veth_xmit 函数;略过了路由、bridge、netfilter 等子系统。
最终调用 enqueue_to_backlog 函数,数据包暂存到每个 CPU 私有的 input_pkt_queue 中,一次软中断结束,总耗时 43us;比 bridge 转发模式的 79us,耗时减少约 45%。
但是,收包路径仍然要消耗 2 个软中断,才能将报文送达终点。
发包路径
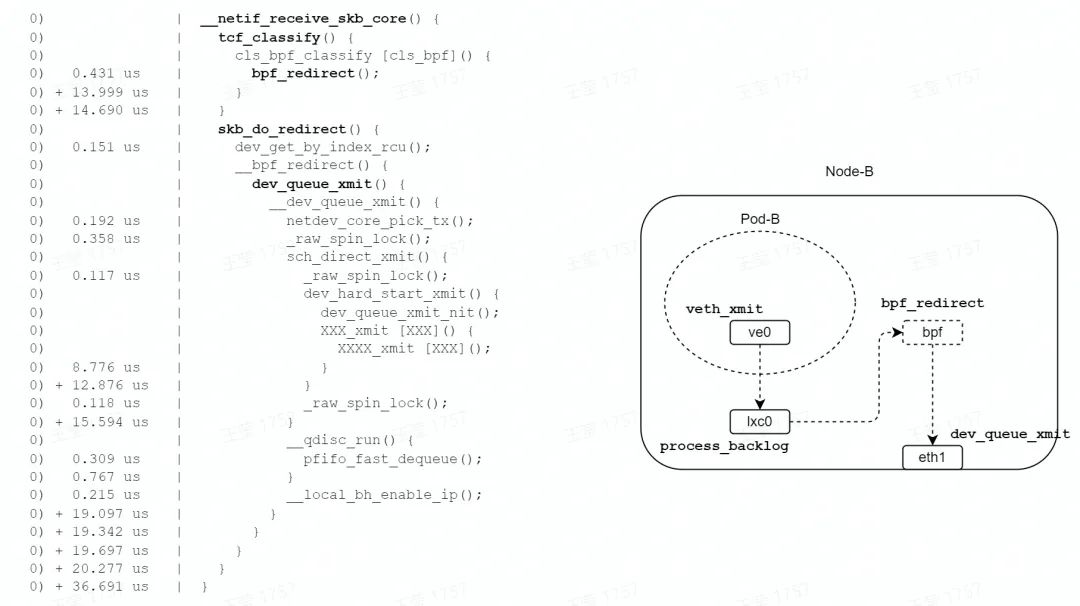
如图,在发包路径的 TC 子系统中,由 bpf_redirect 函数设置转发信息( eth1 接口 index ),由 skb_do_redirect 函数直接调用了 eth1 接口的 xmit 函数;略过了路由、bridge、netfilter 等子系统。
最终调用网卡驱动发包函数,一次软中断结束,总耗时 36us,相比 bridge 模式 62us,耗时减少了约 42%。
小结
由 perf ftrace 的结果可以看出,利用 eBPF 在 TC 子系统注入转发逻辑,可以跳过内核协议栈非必须的流程,实现加速转发。收发两个方向的耗时分别减少 40% 左右,性能提升非常可观。
但是,我们在收包路径上面仍然需要消耗 2 个软中断,才能将报文送往目的地。接下来我们看,如何利用 redirect peer 技术来优化这个流程。
TC redirect peer
加速收包路径
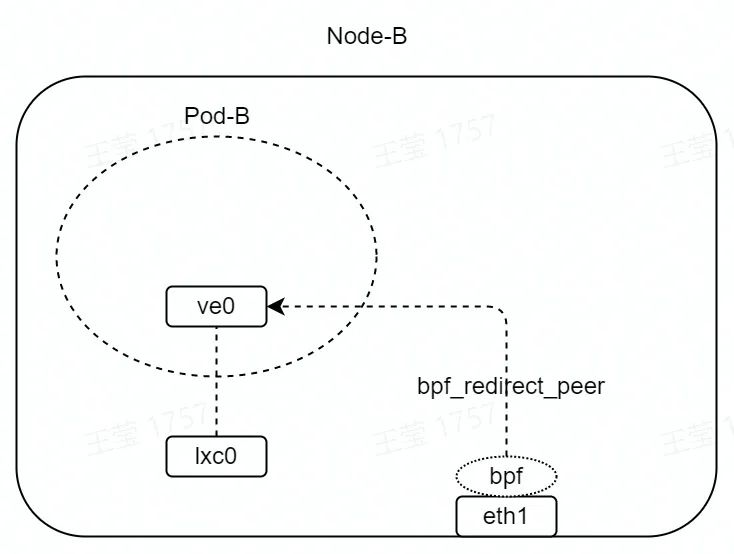
如图,在 eth1 的 TC hook 点(收包方向)挂载 eBPF 程序。
eBPF 程序如下所示,其中 lxc0 接口的 index 为 2。bpf_redirect_peer 函数为内核提供的 helper 函数,该函数会将 eth1 收到的数据包,直接转发至 lxc0 接口的 peer 接口,即 ve0 接口。
分析
由于 bpf_redirect_peer 会直接将数据包转发到 Pod 网络 namespace 中,避免了 enqueue_to_backlog 操作,节省了一次软中断,性能理论上会有提升。我们用 perf ftrace 验证一下。
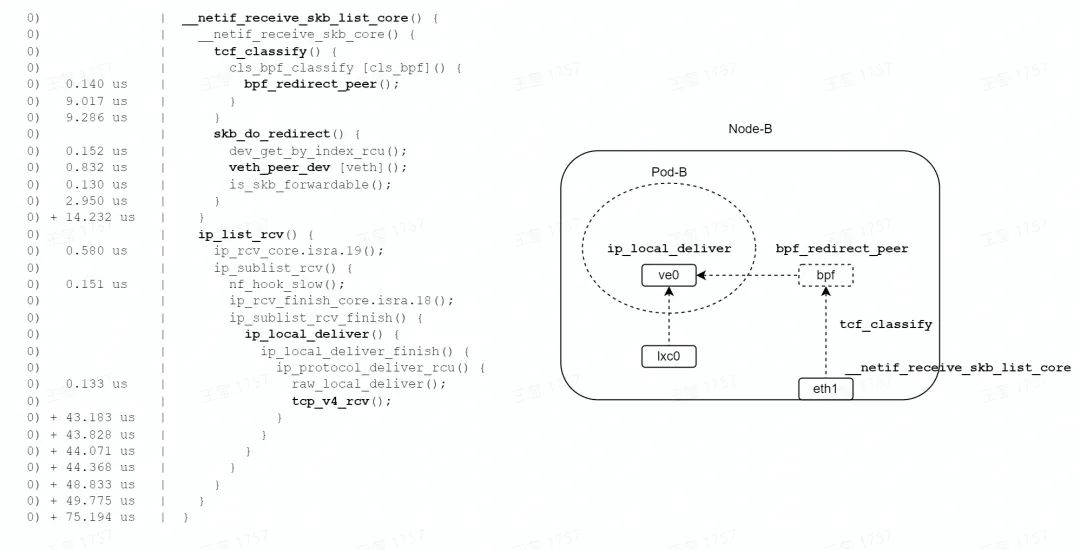
如图,在收包路径的 TC 子系统中,由 bpf_redirect_peer 函数设置转发信息( lxc0 接口 index),由 skb_do_redirect 函数调用 veth_peer_dev 查找 lxc0 的 peer 接口,设置 skb->dev = ve0,返回 EAGAIN 给 tcf_classify 函数。
tcf_classify 函数会判断 skb_do_redirect 的返回值,如果是 EAGAIN,则触发 __netif_receive_skb_core 函数伪递归调用(通过 goto 实现)。这样,就非常巧妙地实现了网络 namespace 的切换(在一次软中断上下文中)。
最终,通过 tcp_v4_rcv 函数到达报文的终点,整个转发流程耗时 75us。从上面的函数耗时可以看到,ip_list_rcv 函数相当于 Pod 网络 namespace 的耗时,本文描述的 3 种转发模式,这段转发路径是相同的。所以,将 ip_list_rcv 函数耗时减去,转发耗时约为 14us(这里还忽略了 2 次软中断调度的时间)。比 TC redirect 模式的 43us、bridge 模式的 79us,转发耗时分别减少为 67%、82%。
总 结
本文以容器网络为例,对比了 3 种容器网络转发模式的性能差异。通过 perf ftrace 的函数调用关系以及耗时情况,详细分析了导致性能差异的原因。我们演示了仅仅通过几行 eBPF 代码,就可以大大缩短报文转发路径,加速内核网络转发的效率,网络转发耗时最多可减少 82%。
目前 eBPF 技术在开源社区非常流行,在 tracing、安全、网络等领域有广泛应用,我们可以利用这项技术做很多有意思的事情。感兴趣的朋友可以加入我们,一起讨论交流。
作者简介:
王栋栋,字节跳动系统技术与工程团队内核工程师,10 年系统工程师工作经验,关注 Linux networking、eBPF 等领域。目前在字节跳动,主要负责 eBPF、内核网络协议栈相关的开发工作。
今日好文推荐
“羊了个羊”背后公司清仓式分红10亿元;Meta元宇宙部门今年已亏94亿美元;微软称GitHub年收入10亿美元|Q资讯
全面审查Twitter代码、当场炒掉CEO等众多高管:马斯克正式入主Twitter

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论