

本文最初发表于 Kdnuggets 网站,经原作者授权,InfoQ 翻译并分享。
在本文中,我们将继续解释 2020 年人们应知必会的人工智能、机器学习、数据科学的术语,这些术语都很重要,包括双下降(Double Descent)、人工智能伦理、可解释性(可解释人工智能)、全栈数据科学、地理空间、GPT-2、自然语言生成(Natural Language Generation,NLG)、PyTorch、强化学习和 Transformer 架构。
本文是《2020 年,人工智能、数据科学、机器学习必知的 20 个术语》的下篇。
这些定义是由 KDnuggets 的编辑 Matthew Dearing、Matthew Mayo、Asel Mendis 和本文作者 Gregory Piatetsky 编著的。
在本文中,我们将解释:
双下降(Double Descent)现象
人工智能伦理
可解释性(可解释人工智能)
全栈数据科学
地理空间
GPT-2
自然语言生成(Natural Language Generation,NLG)
PyTorch
强化学习
Transformer 架构
双下降(Double Descent)现象
这是一个非常有趣的概念,顶级的人工智能研究人员 Pedro Domingos 称之为 2019 年机器学习理论中最重要的进展之一。这种现象如图 1 所示:
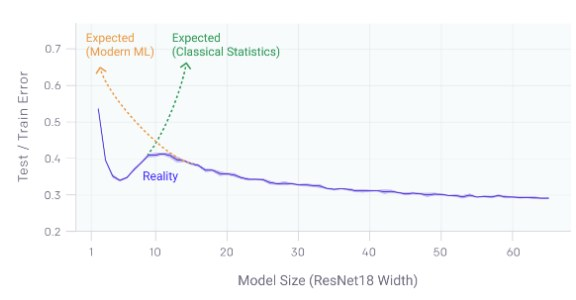
图 1:测试 / 训练误差与模型大小(来源:https://openai.com/blog/deep-double-descent/)
误差先随着模型的增大而减小,然后随着模型开始过拟合而增大,但随着模型大小、数据大小或训练时间的增加,误差又会再次减小。
经典的统计理论认为,过大的模型会因为过拟合而变得更糟。然而,现代机器学习实践表明,一个非常大的深度学习模型通常要比一个较小的模型更好。
OpenAI 博客指出,这种情况发生在 CNN、ResNet 和 Transformer 中。OpenAI 研究人员观察到,当模型不够大,还无法适应训练集时,较大的模型会有较高的测试误差。然而,在超过这个阈值之后,拥有更多数据的大型模型开始表现得更好。
请阅读 OpenAI 的博客原文,以及 Rui Aguiar 更详细的解释。
人工智能伦理
人工智能伦理关注的是实用人工智能技术的伦理学。
人工智能伦理是一个非常广泛的领域,包含了各种各样看似非常不同的伦理关注方面。对人工智能的应用,以及所有类型的技术的担忧,更广泛地说,只要这些技术最初被构想出来的时候,就一直存在。然而,考虑到最近人工智能、机器学习和相关技术的爆炸式发展,以及它们越来越快地被广泛采用和融入社会,这些伦理问题已经上升为人工智能领域内外许多人关注的焦点。
虽然深奥和当前抽象的伦理问题(如有情感的机器人未来的潜在权利),也可以纳入人工智能伦理的框架之中,但眼下更为紧迫的问题,如人工智能系统的透明度、这些系统的潜在偏见,以及在所述系统的工程中包含所有类别的社会参与者的代表性,对大多数人来说,可能是更重大、更直接的问题。人工智能系统是如何作出决策的?这些系统对世界和其中的人们做出了什么样的假设?这些系统是由一个占主导地位的多数阶级、性别和整个社会的种族所构建的吗?
美国旧金山大学(University of San Francisco)应用数据伦理中心主任 Rachel Thomas 就人工智能伦理的工作做了如下阐述,它超越了与人工智能系统的底层创建直接相关的问题,并考虑到了众所周知的更广阔的前景:
创办科技公司,以合乎道德的方式打造产品;
倡导和推动更加公正的法律和政策;
试图追究不良行为者的责任;
以及该领域的研究、写作和教学。
自动驾驶汽车的出现,带来了与人工智能伦理相关的其他具体挑战,还有潜在的人工智能系统武器化,以及日益加剧的国际人工智能军备竞赛。与某些人要我们相信的相反,这些问题并非注定会出现在反乌托邦的未来,但这些问题需要一些批判性的思考、适当的准备、以及广泛的合作。即使我们认为已经充分考虑到了这一点,人工智能系统仍然可能被证明是独特的,存在地方性的问题,而人工智能系统的意外后果,人工智能伦理的另一个方面,还需要加以考虑。
可解释性(可解释人工智能)
随着人工智能和机器学习在我们生活中占据越来越大的比重,智能手机、医疗诊断、自动驾驶汽车、智能搜索、自动信贷决策等都应运而生。有了人工智能做出的决策,这个决策的一个重要方面就随之出现了:可解释性。人们通常可以解释他们基于知识的决策(这种解释是否准确,是一个单独的问题),这有助于其他人对此类决策的信任。人工智能和机器算法能够解释它们做出的决策吗?这对于下面很重要:
提高对决策的理解与信任;
确定责任或不利因素,以防万一;
在决策中避免歧视和社会偏见。
我们注意到,GDPR 需要某种形式的可解释性。
随着美国国防部研究计划局(Defense Advanced Research Projects Agency,DARPA)在 2018 年启动 XAI 计划,可解释人工智能(Explainable AI,XAI)日渐成为一个主要领域。
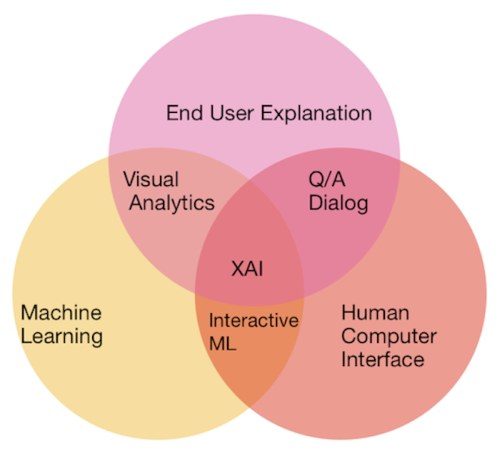
图 2:可解释人工智能文氏图(Venn Diagram)。来源:https://www.kdnuggets.com/2019/01/explainable-ai.html
可解释性是一个涵盖了多方面的主题。它既包含单个模型,也包含整合它们的更大的系统。它不仅涉及模型输出的决策是否可以解释,而且还涉及围绕模型的整个过程和意图是否能够得到适当的解释。其目的的是在正确性和可解释性之间进行有效的权衡,同时提供一个良好的人机界面,帮助将模型转化为最终用户可理解的表示。
可解释人工智能的一些比较流行的方法包括 LIME 和 SHAP 等。
Google(可解释人工智能服务)、IBM AIX360 和其他供应商现在都提供了可解释性工具。
另请参见 KDnuggets 博文:Preet Gandhi 写的《可解释人工智能》(Explainable AI)和论文《可解释人工智能(XAI):概念、分类、机遇、负责任的人工智能面临的挑战》(Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI)(arxiv 1910.10045)。
全栈数据科学
全栈数据科学家是数据科学独角兽的缩影。全栈数据科学家具备以下技能:统计学家,能够对现实生活中的场景进行建模;计算机科学家,能够管理数据库并将模型部署到 Web 上;商业人士:能够将洞察力和模型转化为可操作性的洞察力,提供给最终用户,而最终用户通常是不关心后端工作的高级管理人员。
下面是两个非常棒的演讲,可以让你了解端到端数据科学产品的不同细微之处。
Emily Gorcenski 的《全栈数据科学:使用技术准备》(Going Full Stack with Data Science: Using Technical Readiness)

视频地址:https://youtu.be/huqpXMNFD54
视频:DataCamp 的 #42《全栈数据科学》(与 Vicki Boykis 合作)。请阅读此视频的文字版。

视频地址:https://youtu.be/EICvvS6MUt8
地理空间
地理空间是一个术语,指的是任何具有空间 / 位置 / 地理组成部分的数据。由于追踪用户行动轨迹并作为副产品创建地理空间的技术的出现,地理空间分析越来越受欢迎。用于空间分析的最著名的技术,称为地理信息系统(Geographic Information Systems,GIS),产品有 ArcGIS、QGIS、CARTO 和 MapInfo 等。
为了追踪当前新型冠状病毒的流行情况,约翰·霍普金斯大学(Johns Hopkins U.)系统科学与工程中心开发了 ARCGIS 仪表板 。
地理空间数据可用于从销售预测建模到评估政府资助计划的应用。因为数据是针对特定位置的,所以我们可以收集到很多见解。不同国家记录和测量其空间数据的方式不同,程度也不同。一个国家的地理边界是不同的,必须作为每个国家特有的边界来对待。
GPT-2
GPT-2 是 OpenAI 创建的基于 Transformer 的语言模型。GPT-2 是一种生成语言模型,这意味着它是基于模型以前学到的知识,通过逐字预测哪个词在序列中出现在下一个词来生成文本。在实践中,向模型展示用户提供的提示,然后生成后续单词。通过训练,GPT-2 可以用来预测大量(高达 40 GB)互联文本中的下一个单词,并且完全使用 Transformer 解码器块(这与 BERT 形成对比,BERT 使用编码器块)。有关 Transformer 的更多信息,请参见下面的内容。
GPT-2 并不是一项特别新颖的项目;然而,它与类似模型的区别在于,它可训练参数的数量,以及这些训练参数所需的存储大小。尽管 OpenAI 最初发布的是缩小版的训练模型——因为出于担心该模型可能会被恶意使用——但整个模型仍然包含了高达 15 亿个参数。这个 15 亿个可训练参数模型就需要 6.5 GB 的训练参数(与“训练模型”同义)存储。
GPT-2 一经发布,就引起了大量的炒作和广泛的关注,这在很大程度上是由于它所附带的一些精选的例子,其中最著名的例子是,记录了在安第斯山脉发现一头讲英语的独角兽的新闻报道,该报道可以在这里阅读。GPT-2 模型的一个独特应用以 AI Dungeon 的形式出现,AI Dungeon 是一个在线文本冒险游戏,将用户提供的文本作为输入到模型中的提示,生成的输出用于提升游戏和用户体验。你可以在这里试试 AI Dungeon。
尽管通过下一个单词预测生成文本是 GPT-2 和解码器块 Transformer 的主要功能,但它们在其他相关领域也显示出了潜力,比如语言翻译、文本摘要、音乐生成等等。有关 GPT-2 模型的技术细节和更多信息,请参阅 Jay Alammar 制作的 GPT-2 图解,实在太棒了。
自然语言生成
在自然语言理解方面取得了重大进展:使计算机能够解释人类的输入并提供有意义的回应。许多人每天都通过个人设备享受着这项技术,比如 Amazon Alexa 和 Google Home。不出所料,孩子们真的很喜欢听笑话。
这里的技术是,机器学习的后端进行各种输入的训练,例如“请给我讲个笑话”,它就可以从规定的可用响应列表中选择一个。如果 Alexa 或 Google Home 可以讲一个原创的笑话,一个基于人类编写的大量笑话的训练而即兴创造出来的笑话,那会怎么样呢?这就是自然语言生成。
原创的笑话只是一个开始(经过训练的机器学习模型甚至可以变得很有趣吗?)。作为强大的应用程序自然语言生成正在开发,用于生成人类可理解的数据集摘要的分析。你还可以通过自然语言生成技术来探索计算机的创造性方面,这种技术可以输出原创的电影脚本,甚至是 David Hasselhoff 主演的电影脚本,以及基于文本的故事,类似于你可以学习的长短期记忆网络的教程,它是一种带有反馈的递归神经网络架构,这是今天的另一个热门研究课题。
虽然计算机生成语言的商业分析和娱乐应用可能很有吸引力,而且会改变文化,但在伦理方面的担忧已经开始升温。自然语言生成自动生成并散布的“虚假新闻”的能力正在引起人们的不安,即使它的意图并非出于邪恶。例如,OpenAI 一直在小心翼翼地发布他们的 GPT-2 语言模型,研究表明,该模型可以生成令人信服的文本输出,很难被发现是人工合成的,并且可以进行微调以防止滥用。现在,他们正在利用这项人工智能发展的研究,以更好地了解如何控制这些令人担忧的偏见和恶意使用文本生成器的可能性,人工智能可能会给人类带来麻烦。
PyTorch
Torch 包于 2002 年首次发布,并在 C 语言中实现,它是一个张量库,使用了一系列的算法开发,以支持深度学习。Facebook 人工智能研究室很喜欢 Torch,并在 2015 年初对该库进行了开源,该库还整合了许多机器学习工具。次年,他们发布了该框架的 Python 实现,名为 PyTorch,针对 GPU 加速进行了优化。
随着强大的 Torch 工具现在可供 Python 开发人员使用,许多主要参与者将 PyTorch 集成到他们的开发技术栈中。如今,这个曾经是 Facebook 内部的机器学习框架已经成为最常用的深度学习库之一,越来越多的企业和研究人员成为 PyTorch 用户,OpenAI 就是其中新进者之一。Google 在 2017 年发布的与之竞争的软件包 TensorFlow,从一开始就主宰了深度学习社区,但现在,显然有可能在 2020 年晚些时候被 PyTorch 赶超。
如果你正寻找你的第一个机器学习包来学习,或者你是一个经验丰富的 TensorFlow 用户,你可以从 PyTorch 开始,自己找出最适合你的开发需求的框架。
强化学习
与监督学习和无监督学习一样,强化学习(Reinforcement Learning,RL)是机器学习的一种基本方法。其基本思想是一种训练算法,为尝试执行某些计算任务的试错决策“智能体”提供奖励反馈。换句话说,如果你在院子里扔一根棍子让名为 Rover 的狗子去取回来,而你的新狗子决定将棍子还给你作为奖励,那么下一次它将会更快、更有效地重复同样的决定。这种方法令人兴奋的特点是,无需标记数据,该模型就可以探索已知的和未知的数据,并通过编码的奖励引导来找到最优解决方案。
强化学习是国际象棋、视频游戏中令人难以置信的、破纪录的、战胜人类的竞赛之基础,也是 AlphaGo 的致命一击,AlphaGo 在没有任何指令硬编码到算法中情况下就学会了下围棋。然而,尽管人工智能超能力的这些发展意义重大,但它们都是在定义明确的计算机表示中执行的,比如规则不变的游戏。强化学习并不能直接推广到现实世界的混乱状态,就像 OpenAI Rubik 的 Cube 模型可以在模拟中解决难题一样,但是当通过机械臂进行迁移时,人们花了很多年才看到结果远非完美。
因此,在强化学习领域还有很多有待开发和改进的地方,人们在 2019 年见证了一个潜在的复兴正在进行。将强化学习扩展到现实世界,将是 2020 年的热门话题,重要的实现已经正在进行中。
Transformer
Transformer 是一种基于自我注意力机制的新型神经网络架构,特别适合用于自然语言处理和自然语言理解。它是由 Google 人工智能研究人员在 2017 年的论文《注意力就是你所需要的一切》(Attention Is All You Need)中提出的。Transformer 是一种在编码器和解码器的帮助下将一个序列“转换”为另一个序列的架构,但它并不使用递归网络或长短期记忆网络。相反,它使用注意力机制,允许它查看输入序列中的其他位置,以帮助改善编码。
这里有一个例子,Jay Alammar 解释得很好。假设我们想翻译这句话:
“The animal didn’t cross the street because it was too tired”
这句话中的 “it” 是指什么呢?人们明白 “it” 指的是 “the animal”,而非 “street”,但这个问题,对计算机来说却很难。当对 “it” 一词进行编码时,自我注意力机制将注意力集中在 “The animal” 上,并将这些单词与 “it” 联系起来。

图 3:当 Transformer 对 “it” 一词进行编码时,注意力机制的一部分集中在 “The Animal” 上,并将它的表示与 “it” 的编码联系起来。来源:https://jalammar.github.io/illustrated-transformer/
Google 报告称,Transformer 在翻译任务方面明显优于其他方法。许多自然语言处理框架都使用了 Transformer 架构,比如 BERT(取自 Bidirectional Encoder Representations from Transformers 的首写字母)及其后代。
如果你想看很棒的、可视化的图解,请查看 Jay Alammar 绘制的《Transformer 图解》(The Illustrated Transformer)。
作者简介:
Gregory Piatetsky,博士,KDnuggets 总裁,也是大数据、数据挖掘和数据科学领域的领军人物。它是领先的数据挖掘和数据科学研究会议 KDD 的联合创始人,也是 ACM SIGKDD 的联合创始人和前任主席。曾在两家初创公司担任首席科学家。
原文链接:
https://www.kdnuggets.com/2020/03/ai-data-science-machine-learning-key-terms-part2.html
相关阅读:
2020 年,人工智能、数据科学、机器学习必知的 20 个术语(上)

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论