

大数据时代的互联网应用产生了大量的数据,这些数据就好比是石油,里面蕴含了大量知识等待被挖掘。深度学习就是挖掘数据中隐藏知识的利器,在许多领域都取得了非常成功的应用。然而,大量的数据使得模型的训练变得复杂,使用多台设备分布式训练成了必备的选择。
Tensorflow 是目前比较流行的深度学习框架,本文着重介绍 Tensorflow 框架是如何支持分布式训练的。
分布式训练策略
模型并行
所谓模型并行指的是将模型部署到很多设备上(设备可能分布在不同机器上,下同)运行,比如多个机器的 GPUs。当神经网络模型很大时,由于显存限制,它是难以完整地跑在单个 GPU 上,这个时候就需要把模型分割成更小的部分,不同部分跑在不同的设备上,例如将网络不同的层运行在不同的设备上。
由于模型分割开的各个部分之间有相互依赖关系,因此计算效率不高。所以在模型大小不算太大的情况下一般不使用模型并行。在 tensorflow 的术语中,模型并行称之为“in-graph replication”。
数据并行
数据并行在多个设备上放置相同的模型,各个设备采用不同的训练样本对模型训练。每个 Worker 拥有模型的完整副本并且进行各自单独的训练。
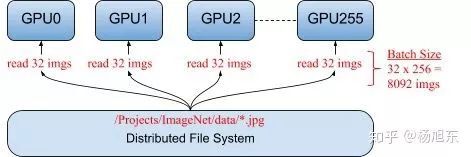
图 1. 数据并行示例相比较模型并行,数据并行方式能够支持更大的训练规模,提供更好的扩展性,因此数据并行是深度学习最常采用的分布式训练策略。
在 tensorflow 的术语中,数据并行称之为“between-graph replication”。
分布式并行模式
深度学习模型的训练是一个迭代的过程,如图 2 所示。在每一轮迭代中,前向传播算法会根据当前参数的取值计算出在一小部分训练数据上的预测值,然后反向传播算法再根据损失函数计算参数的梯度并更新参数。在并行化地训练深度学习模型时,不同设备(GPU 或 CPU)可以在不同训练数据上运行这个迭代的过程,而不同并行模式的区别在于不同的参数更新方式。
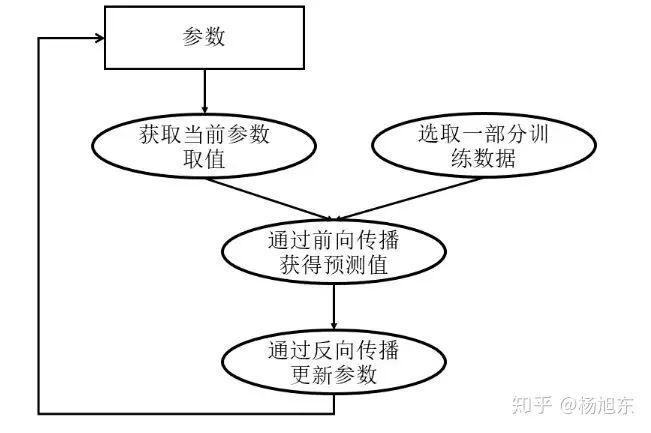
图 2. 深度学习模型训练流程图数据并行可以是同步的(synchronous),也可以是异步的(asynchronous)。
异步训练
异步训练中,各个设备完成一个 mini-batch 训练之后,不需要等待其它节点,直接去更新模型的参数。从下图中可以看到,在每一轮迭代时,不同设备会读取参数最新的取值,但因为不同设备读取参数取值的时间不一样,所以得到的值也有可能不一样。根据当前参数的取值和随机获取的一小部分训练数据,不同设备各自运行反向传播的过程并独立地更新参数。可以简单地认为异步模式就是单机模式复制了多份,每一份使用不同的训练数据进行训练。
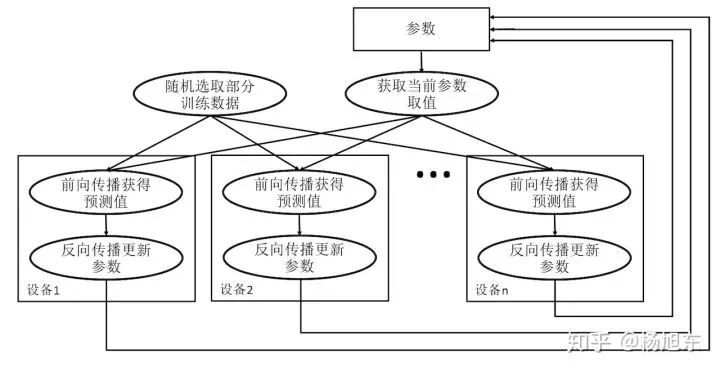
图 3. 异步模式深度学习模型训练流程图
异步训练总体会训练速度会快很多,但是异步训练的一个很严重的问题是梯度失效问题(stale gradients),刚开始所有设备采用相同的参数来训练,但是异步情况下,某个设备完成一步训练后,可能发现模型参数已经被其它设备更新过了,此时这个设备计算出的梯度就过期了。由于梯度失效问题,异步训练可能陷入次优解(sub-optimal training performance)。
图 4 中给出了一个具体的样例来说明异步模式的问题。其中黑色曲线展示了模型的损失函数,黑色小球表示了在 t0 时刻参数所对应的损失函数的大小。假设两个设备 d0 和 d1 在时间 t0 同时读取了参数的取值,那么设备 d0 和 d1 计算出来的梯度都会将小黑球向左移动。假设在时间 t1 设备 d0 已经完成了反向传播的计算并更新了参数,修改后的参数处于图 4 中小灰球的位置。然而这时的设备 d1 并不知道参数已经被更新了,所以在时间 t2 时,设备 d1 会继续将小球向左移动,使得小球的位置达到图 4 中小白球的地方。从图 4 中可以看到,当参数被调整到小白球的位置时,将无法达到最优点。
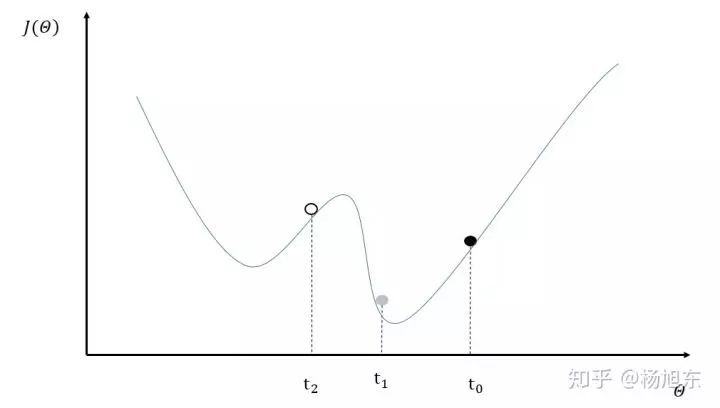
在 tensorflow 中异步训练是默认的并行训练模式。
同步训练
所谓同步指的是所有的设备都是采用相同的模型参数来训练,等待所有设备的 mini-batch 训练完成后,收集它们的梯度后执行模型的一次参数更新。在同步模式下,所有的设备同时读取参数的取值,并且当反向传播算法完成之后同步更新参数的取值。单个设备不会单独对参数进行更新,而会等待所有设备都完成反向传播之后再统一更新参数 。
同步模式相当于通过聚合多个设备上的 mini-batch 形成一个更大的 batch 来训练模型,相对于异步模式,在同步模型下根据并行的 worker 数量线性增加学习速率会取得不错的效果。如果使用 tensorflow estimator 接口来分布式训练模型的话,在同步模式下需要适当减少训练步数(相对于采用异步模式来说),否则需要花费较长的训练时间。Tensorflow estimator 接口唯一支持的停止训练的条件就全局训练步数达到指定的 max_steps。
Tensorflow 提供了 tf.train.SyncReplicasOptimizer 类用于执行同步训练。通过使用 SyncReplicasOptimzer,你可以很方便的构造一个同步训练的分布式任务。把异步训练改造成同步训练只需要两步:
1. 在原来的 Optimizer 上封装 SyncReplicasOptimizer,将参数更新改为同步模式;
2. 在 MonitoredTrainingSession 或者 EstimatorSpec 的 hook 中增加 sync_replicas_hook:
小结
下图可以一目了然地看出同步训练与异步训练之间的区别。
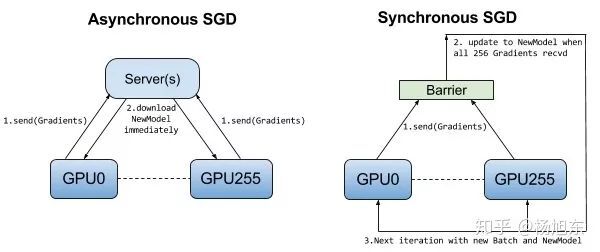
同步训练看起来很不错,但是实际上需要各个设备的计算能力要均衡,而且要求集群的通信也要均衡,类似于木桶效应,一个拖油瓶会严重拖慢训练进度,所以同步训练方式相对来说训练速度会慢一些。
虽然异步模式理论上存在缺陷,但因为训练深度学习模型时使用的随机梯度下降本身就是梯度下降的一个近似解法,而且即使是梯度下降也无法保证达到全局最优值。在实际应用中,在相同时间内使用异步模式训练的模型不一定比同步模式差。所以这两种训练模式在实践中都有非常广泛的应用。
分布式训练架构
Parameter Server 架构
Parameter server 架构(PS 架构)是深度学习最常采用的分布式训练架构。在 PS 架构中,集群中的节点被分为两类:parameter server 和 worker。其中 parameter server 存放模型的参数,而 worker 负责计算参数的梯度。在每个迭代过程,worker 从 parameter sever 中获得参数,然后将计算的梯度返回给 parameter server,parameter server 聚合从 worker 传回的梯度,然后更新参数,并将新的参数广播给 worker。
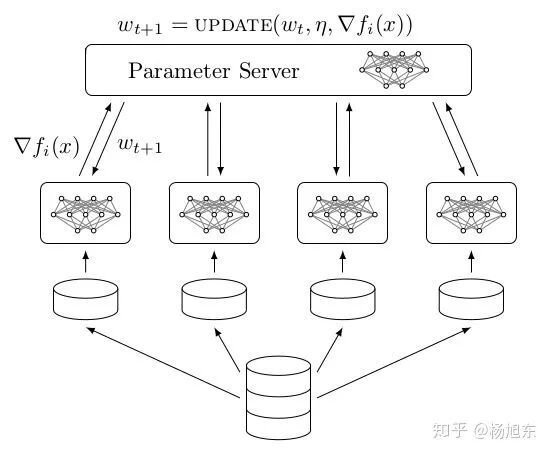
图 7. Parameter Server 架构
Ring AllReduce 架构
PS 架构中,当 worker 数量较多时,ps 节点的网络带宽将成为系统的瓶颈。Ring AllReduce 架构中各个设备都是 worker,没有中心节点来聚合所有 worker 计算的梯度。Ring AllReduce 算法将 device 放置在一个逻辑环路(logical ring)中。每个 device 从上行的 device 接收数据,并向下行的 deivce 发送数据,因此可以充分利用每个 device 的上下行带宽。
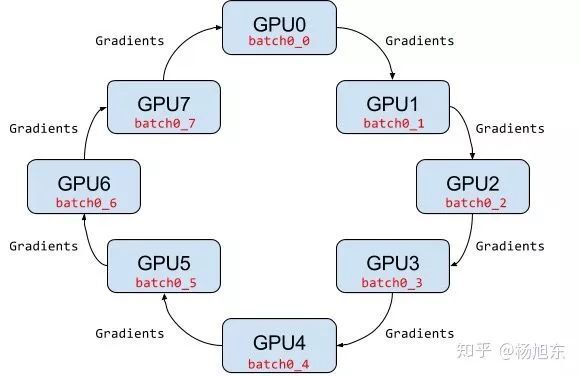
图 8. Ring AllReduce 架构示例使用 Ring Allreduce 算法进行某个稠密梯度的平均值的基本过程如下:
将每个设备上的梯度 tensor 切分成长度大致相等的 num_devices 个分片;
ScatterReduce 阶段:通过 num_devices - 1 轮通信和相加,在每个 device 上都计算出一个 tensor 分片的和;
AllGather 阶段:通过 num_devices - 1 轮通信和覆盖,将上个阶段计算出的每个 tensor 分片的和广播到其他 device;
在每个设备上合并分片,得到梯度和,然后除以 num_devices,得到平均梯度;
以 4 个 device 上的梯度求和过程为例:
ScatterReduce 阶段:
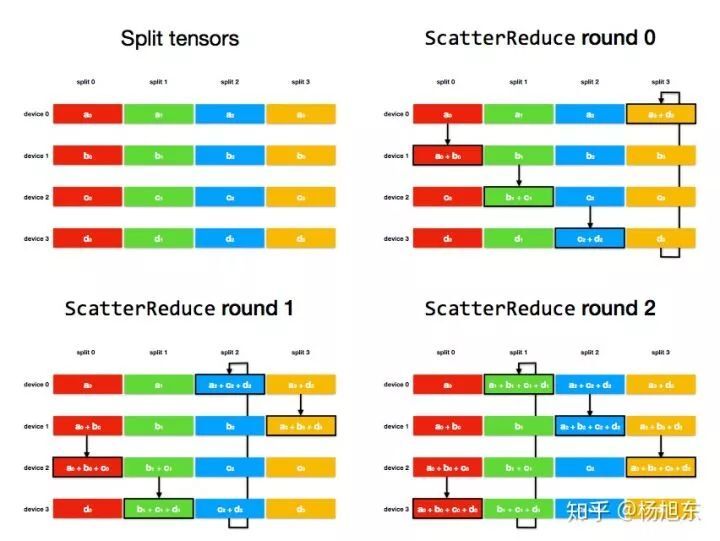
图 9. Ring-AllReduce 算法的 ScatterReduce 阶段经过 num_devices - 1 轮后,每个 device 上都有一个 tensor 分片进得到了这个分片各个 device 上的和;
AllGather 阶段:
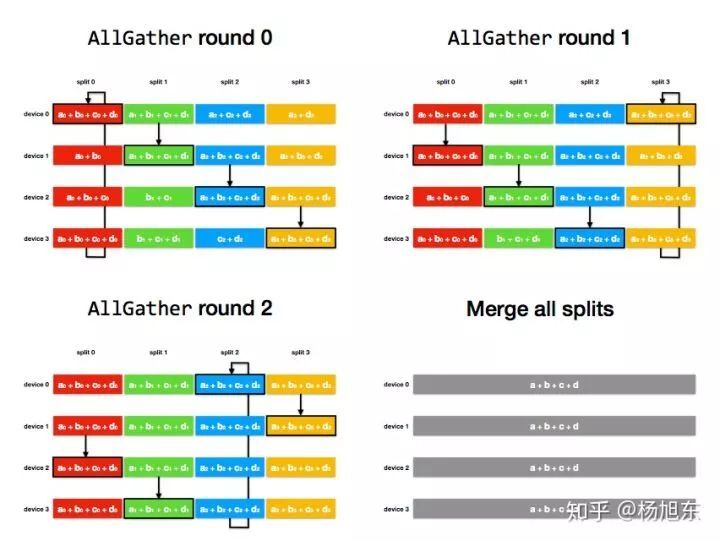
图 10. Ring-AllReduce 算法的 AllGather 阶段经过 num_devices - 1 轮后,每个 device 上都每个 tensor 分片都得到了这个分片各个 device 上的和;
由上例可以看出,通信数据量的上限不会随分布式规模变大而变大,一次 Ring Allreduce 中总的通信数据量是:

相比 PS 架构,Ring Allreduce 架构是带宽优化的,因为集群中每个节点的带宽都被充分利用。此外,在深度学习训练过程中,计算梯度采用 BP 算法,其特点是后面层的梯度先被计算,而前面层的梯度慢于前面层,Ring-allreduce 架构可以充分利用这个特点,在前面层梯度计算的同时进行后面层梯度的传递,从而进一步减少训练时间。Ring Allreduce 的训练速度基本上线性正比于 GPUs 数目(worker 数)。
2017 年 2 月百度在 PaddlePaddle 平台上首次引入了 ring-allreduce 的架构,随后将其提交到 tensorflow 的 contrib package 中。同年 8 月,Uber 为 tensorflow 平台开源了一个更加易用和高效的 ring allreduce 分布式训练库 Horovod。最后,tensorflow 官方终于也在 1.11 版本中支持了 allreduce 的分布式训练策略 CollectiveAllReduceStrategy,其跟 estimator 配合使用非常方便,只需要构造<span>tf.estimator.RunConfig</span>对象时传入 CollectiveAllReduceStrategy 参数即可。
图 11. 使用 CollectiveAllReduceStrategy 的伪代码
分布式 tensorflow
推荐使用 TensorFlow Estimator API 来编写分布式训练代码,理由如下:- 开发方便,比起 low level 的 api 开发起来更加容易
可以方便地和其他的高阶 API 结合使用,比如 Dataset、FeatureColumns、Head 等
模型函数 model_fn 的开发可以使用任意的 low level 函数,依然很灵活
单机和分布式代码一致,且不需要考虑底层的硬件设施
可以比较方便地和一些分布式调度框架(e.g. xlearning)结合使用
要让 tensorflow 分布式运行,首先我们需要定义一个由参与分布式计算的机器组成的集群,如下:
集群中一般有多个 worker,需要指定其中一个 worker 为主节点(cheif),chief 节点会执行一些额外的工作,比如模型导出之类的。在 PS 分布式架构环境中,还需要定义 ps 节点。
要运行分布式 Estimator 模型,只需要设置好<span>TF_CONFIG</span>环境变量即可,可参考如下代码:
定义好上述环境变量后,调用 tf.estimator.train_and_evaluate 即可开始分布式训练和评估,其他部分的代码跟开发单机的程序是一样的,可以参考文献中的资料[1]。
参考
1. https://zhuanlan.zhihu.com/p/38470806
2. Distributed TensorFlow
3. Goodbye Horovod, Hello CollectiveAllReduce
4. Overview: Distributed training using TensorFlow Estimator APIs
5. How to customize distributed training when using the TensorFlow Estimator API
本文授权转载自知乎专栏“深度推荐系统”。原文链接:https://zhuanlan.zhihu.com/p/56991108

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论