
Datadog 将事故管理应用程序中的结构化元数据与 Slack 消息相结合,开发了一个由大语言模型驱动的功能,旨在帮助工程师撰写事后分析报告。在开发这一解决方案的过程中,Datalog 面临在交互式对话系统之外应用 LLM 的挑战,还要确保能够生成高质量的内容。
为了提升事后分析报告的编写效率,Datadog 决定采用大语言模型来生成报告的各个部分。工程师们随后将对这些部分进行审查和个性化调整,形成最终的报告。开发这一功能的团队耗时超 100 个小时,精心微调结构和 LLM 指令,应对多样化输入并获得理想的结果。
团队对不同的模型进行了深入研究,包括 GPT-3.5 和 GPT-4,评估它们在成本、速度和质量方面的表现,并发现这些会因模型版本的不同而有显著差异。例如,工程师们注意到,GPT-4 虽然能产生更准确的结果,但速度远慢于 GPT-3.5,且成本更高。基于实验结果,工程师们决定根据内容的复杂程度,为不同部分选择不同的模型,以实现成本、速度和准确性之间的最佳平衡。此外,报告的构建采用了并行处理的方式,将总时间从 12 分钟大幅缩短至不到 1 分钟。
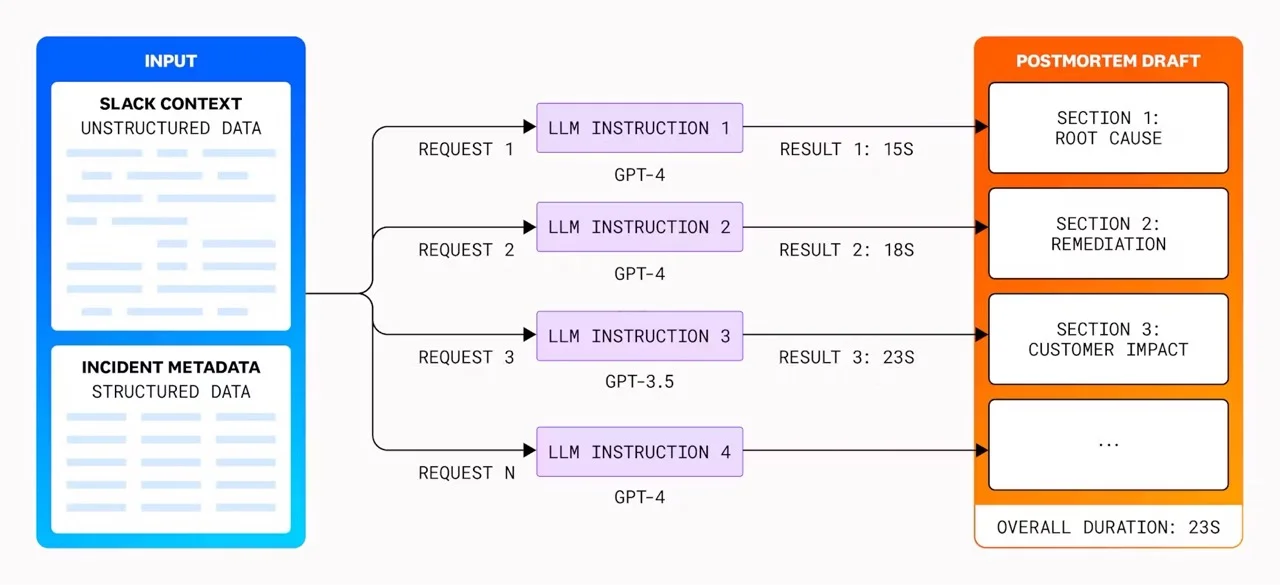
在撰写事后分析报告的过程中,将人工智能与人工输入相结合时的一个关键问题是信任和隐私。团队明确标识出由人工智能生成的内容,避免人类读者(包括审阅者)不加鉴别地将其视为终稿。同时,工程师们还确保在将数据输入到大语言模型之前移除所有敏感信息和机密内容,并用占位符进行替换。Datadog 的工程师们解释了他们如何解决数据安全问题:
鉴于技术性事故的敏感性,保护机密信息就变得至关重要。作为数据摄取 API 的一部分,我们实现了机密扫描和过滤机制,在将数据输入 LLM 之前会清除并替换潜在的机密信息。等到人工智能生成好结果,就用实际内容替换占位符,确保整个过程的隐私和安全。
作为人工智能增强解决方案的一部分,事后分析报告的编写者可以自定义报告各部分所使用的模板。这些模板中还包含了清晰的 LLM 指令,旨在增强对系统的信任和透明度,并允许用户根据需要调整 LLM 指令。
事后分析报告部分(来源:Datadog 工程博客)
在开发由大语言模型驱动的功能后,Datadog 团队认为,尽管 LLM 能够辅助运维工程师创建事后分析报告,但目前还不能完全取代人类。然而,增强型人工智能产品可以显著提升工作效率,并为人类工程师在处理事件报告时提供一个良好的起点。在开发这一功能的过程中,团队积累了丰富的经验,并计划在生成事后分析内容时扩大 LLM 可访问的数据源,包括内部维基百科、RFC 和系统信息。此外,团队还将探索利用 LLM 生成不同版本的事后分析报告,如定制版和公开版。
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】
查看英文原文:https://www.infoq.com/news/2025/04/datadog-postmortem-llm-genai/




