
当地时间 6 月 26 日,在上个月的 Google I/O 上首次亮相预览后,谷歌如今正式发布了 Gemma 3n 完整版,可以直接在本地硬件上运行。
“迫不及待地想看看这些 Android 的性能!”正式发布后有开发者说道。
Gemma 系列是谷歌推出的一组开源大模型。与 Gemini 不同:Gemma 面向开发者,可供下载和修改,而 Gemini 是谷歌的封闭专有模型,更注重性能与商业化。
据悉,此次正是发布的 Gemma 3n 现已具备输入图像、音频和视频的能力,支持文本输出,还能在最低 2GB 内存的设备上运行,在编程与推理等任务上据称表现更佳。具体看,主要更新亮点包括:
天生多模态设计:原生支持图像、音频、视频和文本的输入,以及文本输出。
端侧优化设计:Gemma 3n 着眼于运行效率,提供两种基于“有效参数”的尺寸:E2B 和 E4B。虽然其原始参数量分别为 5B 和 8B,但通过架构创新,它们运行时的内存占用量仅相当于传统的 2B 和 4B 参数模型,并且最低仅需 2GB(E2B)和 3GB(E4B)内存即可运行。
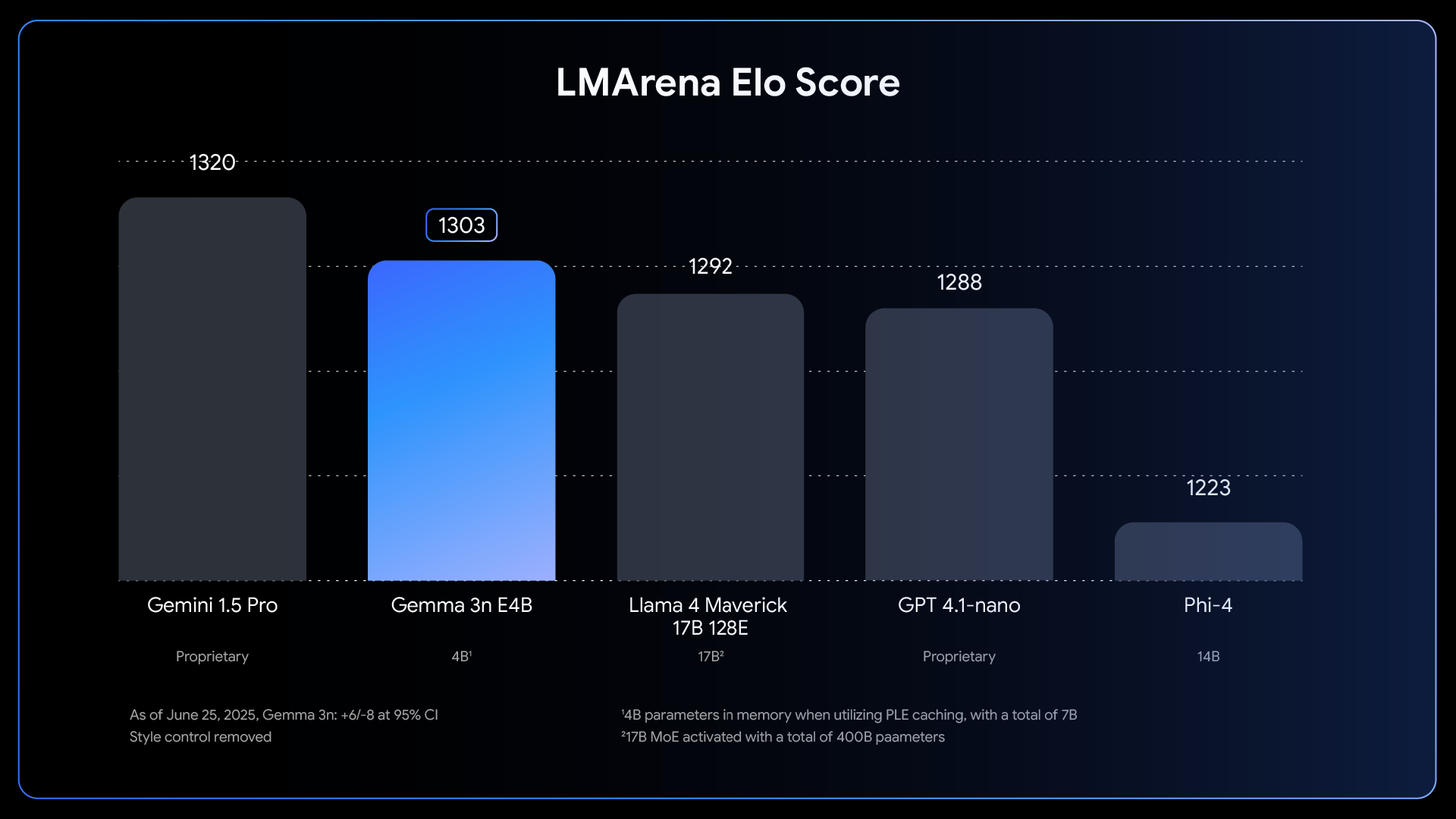
至于基准测试,Gemma 3n 的 E4B 模型成为首个在参数规模低于 10 B 的前提下,LMArena 测评得分突破 1300 的模型,表现优于 Llama 4 Maverick 17 B、GPT 4.1-nano、Phi-4。
效果好不好?
“Gemma 3n 也是我见过的任何模型中首发最全面的:谷歌与“AMD、Axolotl、Docker、Hugging Face、llama.cpp、LMStudio、MLX、NVIDIA、Ollama、RedHat、SGLang、Unsloth 和 vLLM”合作,因此现在有几十种方法可以尝试。”Django Web 联合创建者 Simon Willison 说道。
Willison 在 Mac 笔记本电脑上分别运行了两个版本。在 Ollama 上,4B 型号的7.5GB 版本模型画了这样一幅画:

然后,他使用 15.74 GB 的 bfloat16 版本模型得到了下面的一幅图:
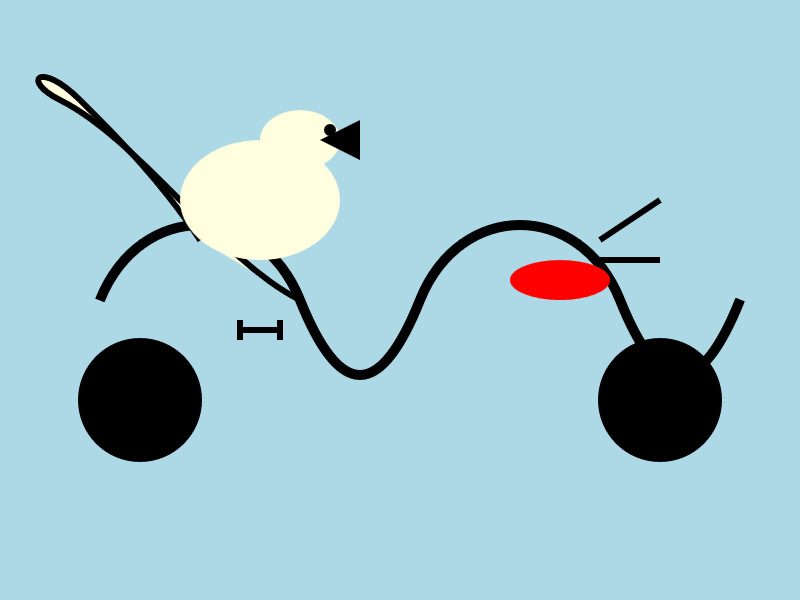
“7.5GB 和 15GB 模型量化之间存在如此显著的视觉差异。”Willison 说道。他还指出,Ollama 版本似乎尚不支持图像或音频输入,但是mlx-vlm版本可以。
但当让模型描述上述图片时,模型误认成了一张化学图:“该图为卡通风格的插图,描绘了浅蓝色背景下的分子结构。该结构由多个不同颜色和形状的元素组成,并通过弯曲的黑线连接起来。”
此外,网友 pilooch 称赞道,该模型完全兼容此前基于 Gemma3 的所有操作。“我将其接入视觉语言模型微调脚本后,程序顺利启动(使用 HF Transformer 代码)。在单 GPU 运行 LoRa 微调时,E4B 模型在批量大小为 1 的情况下仅占用 18GB VRAM,而 Gemma-4B 需要 21GB。DeepMind 推出的 Gemma3 系列真不错,稳居开源视觉语言模型榜首。”
也有开发者表示,“我一直在 AI Studio 里试用 E4B,效果非常好,比 8B 型号的预期要好得多。我正在考虑把它安装在 VPS 上,这样就有了其他选择,不用再使用那些昂贵的 API 了。”
在开发者 RedditPolluter 的测试中,E2B-it 能够使用 Hugging Face MCP,但其不得不将上下文长度限制从默认的“~4000”增加到“超过”,防止模型陷入无限的搜索循环。它能够使用搜索功能获取一些较新型号的信息。
当然,还是比较怀疑小模型的实际用处。“我做过很多实验,任何小于 27B 的模型基本上都用不了,除非当玩具用。对于小模型,我只能说它们有时能给出不错的答案,但这还不够。”
对此,有网友表示,“我发现微型模型(< 5B 参数)的最佳用例是作为没有 WiFi 时的参考工具。我在飞机上写代码时,一直在 MacBook Air 上使用 Qwen 来代替谷歌搜索,它在询问有关语法和文档的基本问题时非常有效。”‘
核心技术能力有哪些?
MatFormer 架构是核心
谷歌特别指出,其高效能的核心就在于全新的 MatFormer (Matryoshka Transformer)架构,这是一种为弹性推理而设计的嵌套式 Transformer。它类似“俄罗斯套娃”:一个较大的模型内部嵌套着一个较小但完整的子模型。这种设计允许一个模型在不同任务中以不同“尺寸”运行,实现性能与资源使用的动态平衡。
这种设计将“套娃式表示学习”(Matryoshka Representation Learning)的理念,从嵌入层扩展到了整个 Transformer 架构的各个组件,大幅提升了模型在不同资源环境下的灵活性与适应性。

在对 4B 有效参数(E4B)模型进行 MatFormer 架构训练的过程中,系统会同时在其中优化一个 2B 有效参数(E2B)子模型,如上图所示。
这项架构设计同时为开发者带来了两大关键能力:
预提取模型,开箱即用。开发者可根据应用场景自由选择完整的 E4B 主模型获得更强性能,也可以直接使用已经预提取好的 E2B 子模型。在保证准确率的前提下,E2B 实现了高达 2 倍的推理速度,尤其适合边缘设备或算力受限场景。
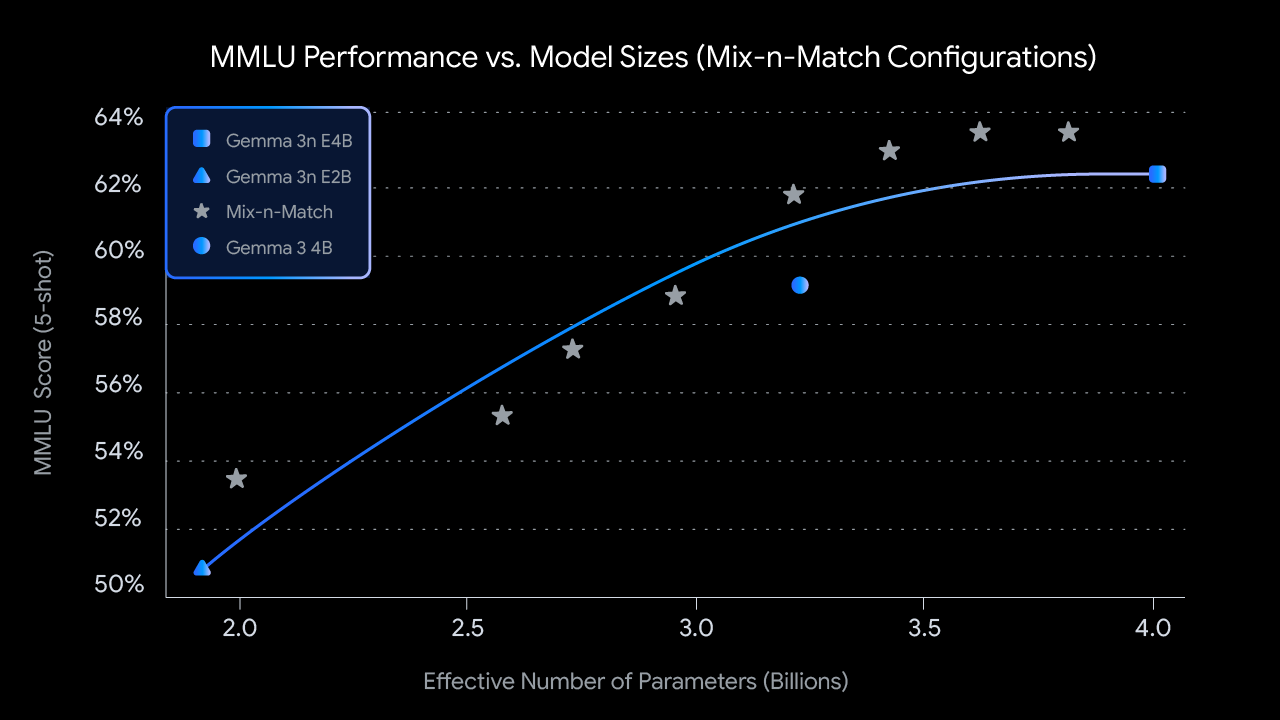
Mix-n-Match 定制模型。针对不同硬件资源的限制,开发者可以通过 Mix-n-Match 方法,在 E2B 与 E4B 之间自由定制模型大小。该方法通过灵活调整每层前馈网络的隐藏维度(如从 8192 调整到 16384),并选择性跳过部分层,从而构建出多种不同规模的模型。
与此同时,谷歌还推出了辅助工具 MatFormer Lab,方便开发者基于多个基准测试结果(如 MMLU)快速挑选并提取出性能最优的模型配置。
谷歌表示,MatFormer 架构还为“弹性推理”奠定了基础。尽管这一能力尚未在本次发布的实现中正式上线,但它的设计理念已初步成型:单个部署的 E4B 模型,未来将能在运行时动态切换 E4B 与 E2B 的推理路径,根据当前任务类型和设备负载,实时优化性能表现与内存占用。
大幅提升内存效率的关键
在最新的 Gemma 3n 模型中,谷歌引入了名为 Per-Layer Embeddings(逐层嵌入,简称 PLE) 的创新机制。该机制专为端侧部署而设计优化,可显著提高模型质量,同时不会增加设备加速器(如 GPU/TPU)所需的高速内存占用。
这样一来,尽管 E2B 和 E4B 模型的总参数数量分别为 5B 和 8B,但 PLE 允许很大一部分参数(即分布在各层的嵌入参数)在 CPU 上高效加载和计算。这意味着只有核心 Transformer 权重(E2B 约为 2B,E4B 约为 4B)需要存储在通常较为受限的加速器内存 (VRAM) 中。

大幅提升长上下文处理速度
在许多先进的端侧多模态应用中,处理长序列输入(如音频、视频流所生成的内容)已成为核心需求。为此,Gemma 3n 引入了 KV Cache Sharing(键值缓存共享)机制,加快了长文本推理中“首个 Token”的生成速度,尤其适用于流式响应场景。
具体而言,KV Cache Sharing 对模型的 Prefill 阶段进行了优化:中间层中,来自局部与全局注意力机制的中间层 Key 与 Value 会直接共享给所有上层结构。与 Gemma 3 4B 相比,这使 Prefill 性能获得高达 2 倍的提升。
全新视觉编码器,提升多模态任务表现
Gemma 3n 推出了全新高效的视觉编码器:MobileNet-V5-300M,来提升边缘设备上的多模态任务表现。
MobileNet-V5 支持多种分辨率(256×256、512×512、768×768),方便开发者根据需求平衡性能与画质。它在大规模多模态数据上进行训练,擅长处理多种图像和视频理解任务。吞吐率方面,其在 Google Pixel 设备上可实现每秒最高 60 帧的实时处理速度。
这一性能突破得益于多项架构创新,包括基于 MobileNet-V4 的先进模块、能高大 10 倍扩的深度金字塔架构,以及多尺度融合视觉语言模型适配器等。相较于 Gemma 3 中未蒸馏的 SoViT,MobileNet-V5-300M 在 Google Pixel Edge TPU 上实现了最高 13 倍速度提升(量化后),参数减少 46%,内存占用缩小 4 倍,同时准确率大幅提升。
支持语音识别与语音翻译
音频处理方面,Gemma 3n 搭载了基于 Universal Speech Model(USM) 的先进音频编码器,可对每 160 毫秒的语音生成一个 token(约每秒 6 个 token),并将其作为输入集成至语言模型中,从而提供更加细致的语音上下文表示,这为端侧应用解锁了语音识别和语音翻译功能。
据悉,Gemma 3n 在英语与西班牙语、法语、意大利语、葡萄牙语之间的转换效果尤为出色。同时,在进行语音翻译任务时,结合“思维链式提示”策略,可进一步提升翻译质量与稳定性。
参考链接:
https://developers.googleblog.com/en/introducing-gemma-3n-developer-guide/




