

引言
「快页面」是知乎内部一个快速搭建后台管理页面的平台,使用者仅用半小时即可将一个常规复杂度的后台页面开发完成。
「快页面」平台的基石是它的「渲染器」,一个能将 JSON 配置渲染成页面的 React 组件。
这篇文章将会提供一种配置化渲染器实现思路。
不过在开始介绍原理之前,想先对这类工具的存在价值做一个简单的分析评估,搞明白我们为什么要做它。
核心目标 - 提升开发效率
一些质疑
一开始产生做「快页面」这个平台的想法时,我也在怀疑这样的东西真的能提高效率吗? 它所带来的学习成本难道不会实际上高过它带来的收益吗?
其实配置化页面渲染是一个非常老旧的话题了,因为一般情况下,一个十几人规模的前端团队,只要不断接到大量高度相似的管理后台需求,内部都会催生出一个这样的页面配置化工具。
只是如今社区内也并没有诞生出一个已经被广泛使用的类似工具,大多只是作为各公司内部系统内部使用。
在「快页面」平台内部上线一年后的今天,我能确定它真的能提高开发效率。
许多项目一期的后台需求都很简单,一个表单用于创建和编辑,一个表格用来查询,然后在表格上加个公开按钮,这种需求使用快页面开发,平均每个页面用半小时,最多一小时就完成上线了。
不过同时无法忽视的一点是,为了抵消它所带来的学习成本,必然需要做很多文档,智能编辑器,版本管理等辅助性工作。 这将经历一个比做出渲染器和专属组件更为漫长和曲折的过程。
效率提升关键点
其实这类工具提升效率的关键点各不相同,「快页面」则是通过以下三点提高效率:
约束需求范围,约定优于配置
省去构建部署环节,快速上线
非前端参与前端页面开发成为可能
约束需求范围,约定优于配置
把页面从用代码表达改为用配置表达,相当于创建了一种 DSL,省去了 import 语句,对效率的提升有限。
提升效率的关键是分析高频业务需求,简化成固定流程,限制需求范围,要放弃支持过于灵活的需求。
比如通用的表单需求,我们把它拆解成以下几个部分:
「请求数据」→「设置初始值」→「指定 POST 地址」→「用户与表单交互」→「校验」→「提交」→「成功后跳转」
其他细枝末节的比如「提交按钮放哪」「提交按钮文案」等低频需求不考虑。
一些难以用配置表达的需求,比如「拿到请求数据后先处理下对象结构」「提交的时候发两个接口」「提交的时候删除一些字段」等等,它们其实是一种回调函数,变化多端,无穷无尽,除非是高频需求,否则尽量放弃支持。
我们抽象了高频需求中的公共部分,用一目了然的配置表达,放弃了灵活性,得到了效率的提升。 这就是「约定优于配置」。
省去构建部署环节,快速上线
我们的配置是以 JSON 的形式存在的,区别于 js 代码,它的好处在于简短,可通信,可存储。
既然一份 JSON 对应一个页面,如果把它存到数据库中,用接口读取和修改,再做一个在线编辑器,应该就能脱离项目的构建,部署流程,做到开发完成后立刻上线了。
「快页面」省去了构建和部署流程,实际上,在本项目中,也就是省去了原本每次代码合并后所需要的 10 分钟以上的等待时间,间接省去了 git clone 代码,安装依赖,启动项目等等开发前的必要工作。
非前端参与前端页面开发成为可能
有了在线智能编辑器和文档,后端也能照着其他页面的配置样例,快速开发一个常规复杂度的前端页面了。
如果这个在线智能编辑器更强大一些,摆脱了对编辑 JSON 的依赖,转为可视化交互,它就能成为一个草图编辑器,从而使得更多的人参与到前端页面的开发过程中去。
当后端能借助在线智能编辑器独立完成前端页面开发时,这其中的沟通联调成本也就大大降低了。
配置样例
这是一个简化的表格查询需求配置样例
如样例所示,用 component 字段表示要使用的组件,组件嵌套组件形成一份能表达整个页面内容的 JSON 配置。
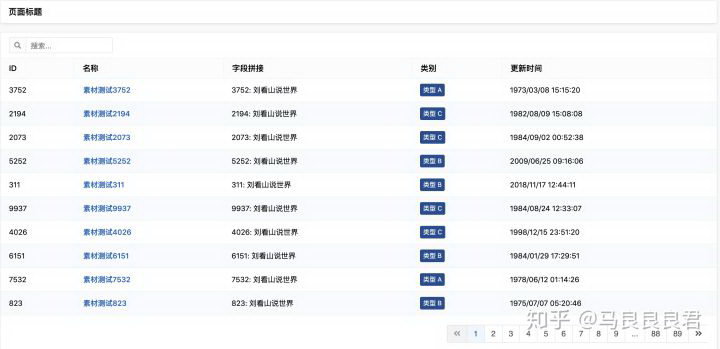
页面渲染结果
注意到配置中有些值含有「双花括号」,如 {{record.id}}: {{record.community_name}}
这种格式表示它们是动态变化的,让组件具备随状态变化显示不同 UI 的能力,支持表达式计算。 文章后面会详细介绍这一功能。
这个样例中的组件树可简化为下图(仅显示有 component 的部分)
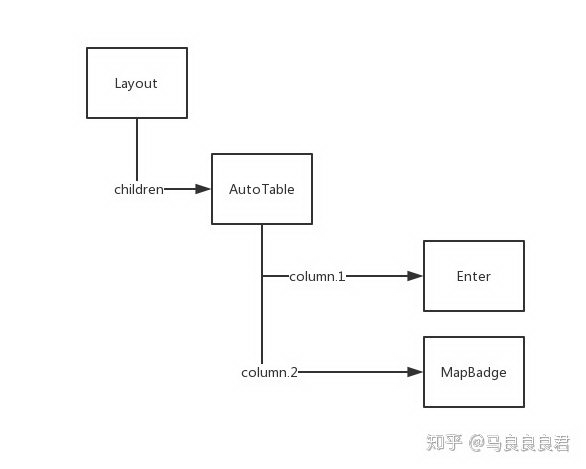
组件树
其中 Layout 影响页面的标题,边距;
AutoTable 是强大的表格组件,负责发请求,表格分页等逻辑;
Enter 是一个链接按钮;
MapBadge 常用于显示各种状态或类型,在 UI 上比普通文字更醒目一些。
这份 JSON 很精炼地表达了一个页面的内容,Layout(页面布局) AutoTable(表格),Enter 和 MapBadge(表格中的两列,一列是链接,一列是类型),比起原先 JSX 的写法,代码量大大减少了。
渲染流程
我们可以把渲染流程粗略地分为「React 组件渲染」和「双花括号表达式渲染」
React 组件渲染
配置单元
仔细观察配置结构可以发现,嵌套的关键是 component,与 component 同级的那些字段将会作为组件的属性传入,即
我们把含有 component 的 Object 叫做一个「配置单元」,就像 React 组件可以自由作为其他组件的任意属性传入一样,「配置单元」之间也可以作为对方的一个属性形成嵌套。
那么对每一个配置单元的基本操作就是,调用 React.createElement() 将其实例化为 React Element。
自底向上
当我们对一个有两层嵌套的配置单元尝试 React.createElement() 时便会发现,我们好像需要确定一个渲染顺序。
这个顺序就是自底向上。 以上面的 Layout - AutoTable 为例:
假设是自顶向下,那就是
其实 Layout 就是个简单 UI 组件,没有任何复杂逻辑,会把外界传给它的 children 原封不动地传给 React 的 API,这时毫无疑问会报错。
回过头来看,其实自底向上的顺序理是所当然的,因为 JSX 转译出来的 JS 代码本来就是自底向上的,想想「函数执行栈」就明白了。
因此渲染顺序是: 自底向上。
深度优先遍历
知道了渲染顺序,知道了每一层都是在执行 React.createElement(),接下来写一个深度优先遍历就行了。 代码简化如下:
常见的递归遍历而已,通过 dfs 收集到一个遵循组件自底向上顺序的数组,接下来对其中元素逐个执行 React.createElement() 并替换即可。
其中 getComponentByName 是根据组件名找到组件的方法,也就是接下来要说的。
根据组件名找到组件类
先实现一个组件引用缓存管理器
接着注入所有组件
根据组件名取用组件
都是非常简单直白的逻辑
到这里,一个基本的静态配置渲染流程已经实现了,如果我们的页面是像写静态 HTML 标签一般没有任何动态需求,这样就足够了。
但后台需求不会这么简单,实际使用后我们会发现,比起写 JSX,这种 JSON 配置有一个致命的缺陷,那就是数据在被传给 UI 组件前,我们连对它进行一点点计算都做不到,也没法写回调函数。 因此就需要下面这第二部分「双花括号表达式渲染」」。
双花括号表达式渲染
表达式扮演什么角色
首先要明白,「双花括号表达式」在页面配置中究竟扮演了一个什么样的角色,我们能在传统写 JSX 的过程中,找到与之对应的角色吗?
在本项目中,「双花括号表达式」满足了
对数据的计算处理的需要
实现部分的回调函数的需要
对数据的计算处理
最常见的例子,往往页面中表单请求的 HTTP 接口地址,需要受页面当前路由的影响
比如我们要在 https://example.xxx.com/projects/:id 这个页面中请求 https://api.xxx.com/projects/:id 这个接口地址
很明显接口地址中的参数 id 是从页面路由中得到的
那么写成「双花括号表达式」就是 ‘https://api.xxx.com/projects/{{match.params.id}}’
这类计算逻辑很常见,非常重要, 而「双花括号表达式」就可以满足这类需求。
部分的回调函数
JSON 配置中只能写数字,字符串,布尔值这些简单类型,不能写函数。
那通过 eval 生成函数行不行呢? 在 JSON 中就以字符串的形式存在。
这个思路被我们放弃了,因为它过于复杂,过于灵活了。
我们依然是只针对高频需求做支持
不过这意味着我们需要做一些特殊组件,将原本需要传入回调函数才能实现的逻辑变成仅需一小段 JSON,比如点击按钮后弹框填写表单,或要求用户确认危险操作等等
表达式计算的实现
实现表达式计算靠 eval 生成一个立即执行函数就可以了,这里需注意几个关键点:
屏蔽全局变量
eval 生成的函数变量命名空间与全局变量可能有交集
全局变量中可能有变量名并不符合标识符命名规则
打印计算过程中的报错
屏蔽全局变量
这里的全局变量其实指的就是 window 对象上的属性,由于我们利用了立即执行函数的闭包特性,因此它在执行过程中会受到 window 对象上属性的影响,导致奇怪的计算结果。
这种情况一旦发生,不容易发现原因,安全起见还是屏蔽掉的好。
屏蔽的方式就是循环枚举出 window 上的属性,然后执行。
eval 生成的函数变量命名空间与全局变量可能有交集
表达式的数据源中可能与全局变量有同名属性,就不能和上面一样赋为 undefined 了,举例:
全局变量中可能有变量名并不符合标识符命名规则
某些第三方库可能会在 window 上注入它自定义的标识变量,但却没有遵循变量命名规则,使用了诸如「减号 -」等特殊符号。
这种标识符可能会让屏蔽全局变量的语句报错,所以记得过滤下。
打印计算过程中的报错
表达式计算是非常有可能失败的,比如下面这个报错大家肯定见的太多了。
TypeError: Cannot read property ‘someProp’ of undefined
通过 try catch 捕获到并打印出来,可以极大地帮助使用者调试。
计算表达式时的数据来源
我们的「双括号表达式」要影响的是 UI,
而在 React 中,能够即时影响 UI 的数据只有三种来源,state,props 和 context。
state
state 是组件的一些内部属性,比如表格的分页,是由表格内部自行管理的。
props
props 是我们给组件传入的属性,其实就是「配置单元」里写死的。
context
借助一些状态管理库,如 redux + react redux,context 就变成了组件的 props。
这三种数据源只有在组件的 render 方法中可以全部拿到,并且还能随数据的变化立即影响 UI。
自底向上的局限
仍是以上面展示的样例为例,假设目前 JSON 配置中组件树的结构有如下三层。
Layout
|-- AutoTable
|-- Enter ( href = https://example.xxx.com/resources/{{record.id}} ) // record 是表格任意一行的数据
表达的意思很简单,页面中有个表格,表格中有一列要放个链接入口。
按照自底向上的顺序,应当是先执行 createElement(Enter) ,再执行 createElement(AutoTable)
可我们给 Enter 传入的 href 属性是一个「双花括号表达式」,表达式中依赖的 record 是自身所处表格那一整行的数据,属于 AutoTable 组件私有的变量。
我们原先的自底向上流程无视了私有关系,在尝试计算表达式时发现缺少了一些私有变量。
这就是原先自底向上的局限,看来,想要支持表达式计算,渲染流程还需要再改进。
自底向上流程之间的接力
既然那些变量是私有的,那就应该在遵循私有关系的前提下进行自底向上的渲染。
怎么遵循呢? 那就是在自底向上的过程中,忽略一些组件的子级配置,由该组件自己负责子级配置的自底向上渲染。
这样一来,原本只有一次的自底向上渲染,由于 AutoTable 组件的存在,这个流程被分割成了两次,好像两次接力一般。
我们把那些类似 AutoTable 这种负责接力的组件称作「接力组件」。
仍是以上面的 Layout - AutoTable - Enter 为例
在这个流程中,由于有一个「接力组件」AutoTable 存在,需要两次自底向上的渲染
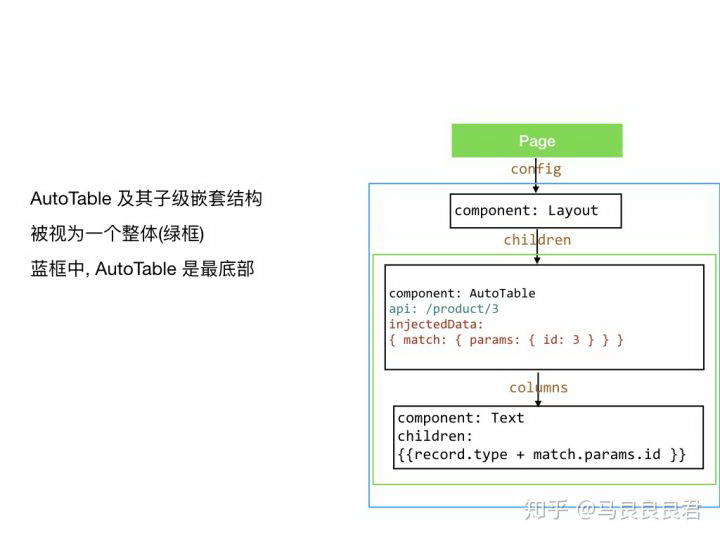
第一次自底向上把 AutoTable 及其所有子级字段视为一整个配置单元,这样 AutoTable 便成了最底部的那个「配置单元」。
第二次自底向上由 AutoTable 接力,对其所有子级字段进行自底向上的渲染。
以此类推。 即使有更多「接力组件」,流程都是一样的。
本文最后会有图片形式的流程详细介绍。
接力组件
哪些组件是接力组件
主要是那些需要提供私有变量给「双花括号表达式」的组件,比如表格需要提供表格每一行的数据,表单需要提供表单当前值,等等其他有类似需求的组件。
渲染器怎样知道当前组件是不是「接力组件」
白名单是个办法,但这样做的话,每新增一个「接力组件」,都需要更改白名单,渲染器和组件之间存在耦合。
所以更好的办法是做个 HOC
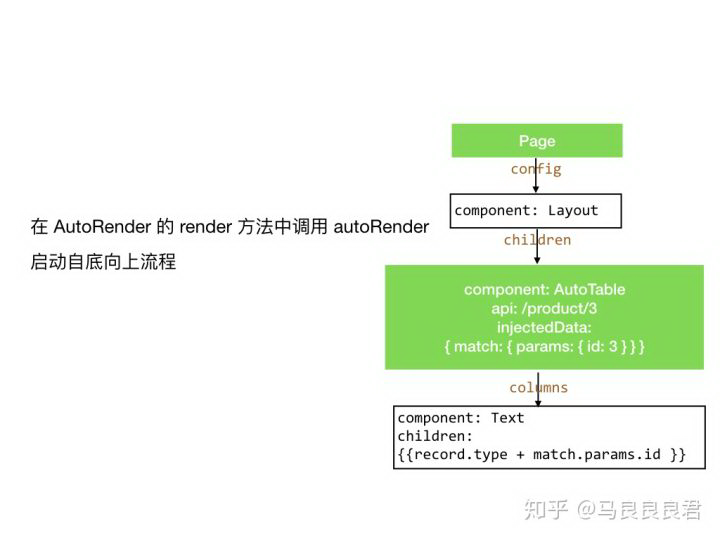
我们把「遍历计算并替换双花括号表达式」「自底向上调用 React.createElement」两个公共逻辑合并成一个方法抽象出来,就叫它 autoRender 吧。
做一个 HOC,它有两个功能:
标记被包装的组件是一个「接力组件」
提供上面提到的 autoRender 方法给被包装的组件,由被包装组件使用 autoRender 渲染剩下的配置完成接力
这样一来,做一个「接力组件」就变得很简单,只要拿这个 HOC 包装一下,然后在被包装的组件中随自己想法调用 HOC 提供的 autoRender 方法即可。
渲染器和组件之间实现了解耦。
形如闭包的表达式变量作用域
既然「接力组件」拥有一些私有变量,那么符合直觉的作用域应该是:
父级不能读取「接力组件」子级的变量,但「接力组件」可以使用父级的变量。
就像闭包的作用域一样,当前函数可以使用外层函数的变量,外层函数却不可以使用当前函数的变量。
这个的实现也不难, 一句话概括就是: 每个「接力组件」向它子级的所有「接力组件」注入数据。
所谓注入数据就是给子级的「接力组件」添加一个特定字段,比如 __injectedData
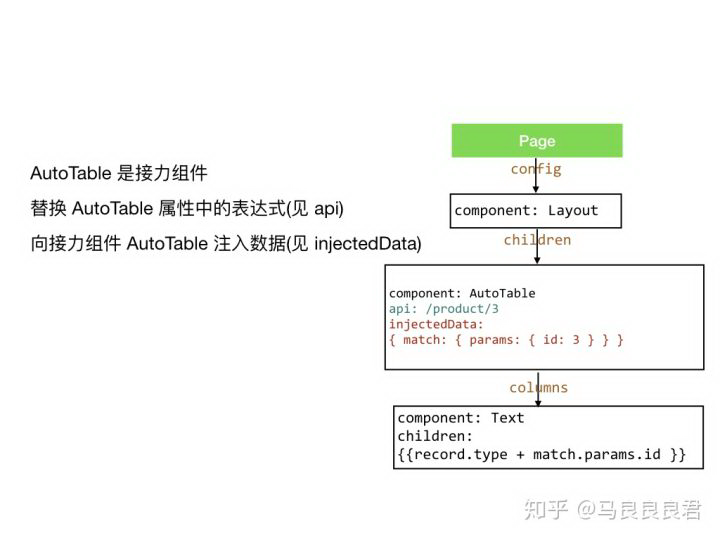
在本例中,就是要向 AutoTable 这个「接力组件」注入 __injectedData,内容是页面的路由信息等数据。
(假定页面路由中参数 id 为 20) 注入后变为
之后 AutoTable 使用 autoRender 方法时便会把这份被注入的数据和自身私有的数据合并,来渲染子级配置中的「双花括号表达式」
流程图解
上面纯文字描述很不直观,下面是一个图片形式的完整流程。
在这个例子中,共存在两个「接力组件」: Page 和 AutoTable
Page 可以为表达式提供页面路由数据,包括参数匹配结果,即 match。
假设页面路由中存在参数 id,值为 3,即 match.params.id = 3。
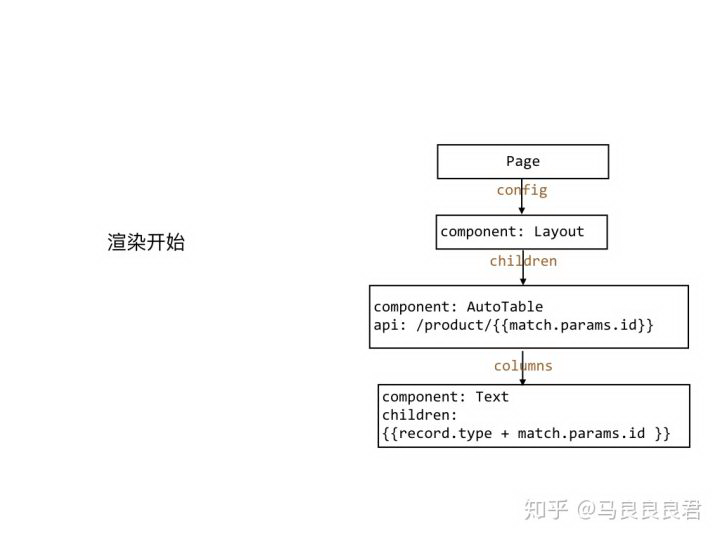
开始
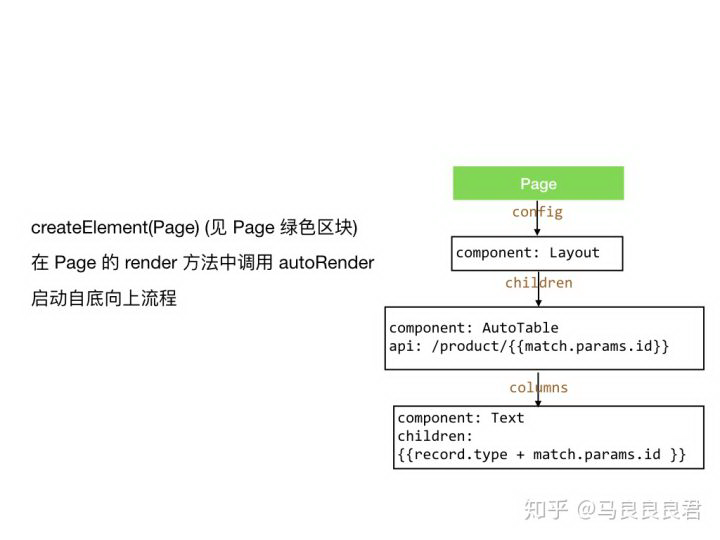
启动渲染
计算表达式,注入数据
接力组件被视为一个整体
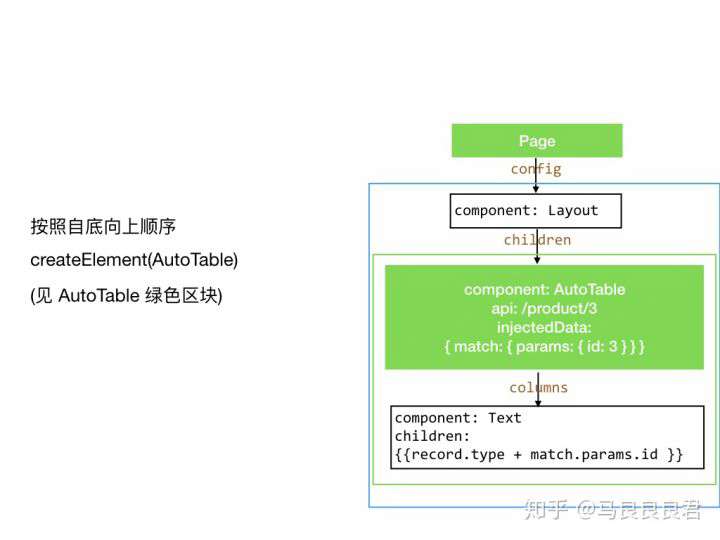
createElement(AutoTable)
开始接力
Text 组件的 children 属性的值是一个表达式,表达式中使用了 record 和 match 两个变量
record 是表格中每一行的数据,由 AutoTable 提供,假设 record.type = ‘typeA’
match 是页面路由参数匹配结果,显然 AutoTable 本身无法提供 match 数据
但之前 Page 已向 AutoTable 注入了 injectedData,其中含有 match 变量
因此 Text 组件的 children 属性表达式可以计算出结果
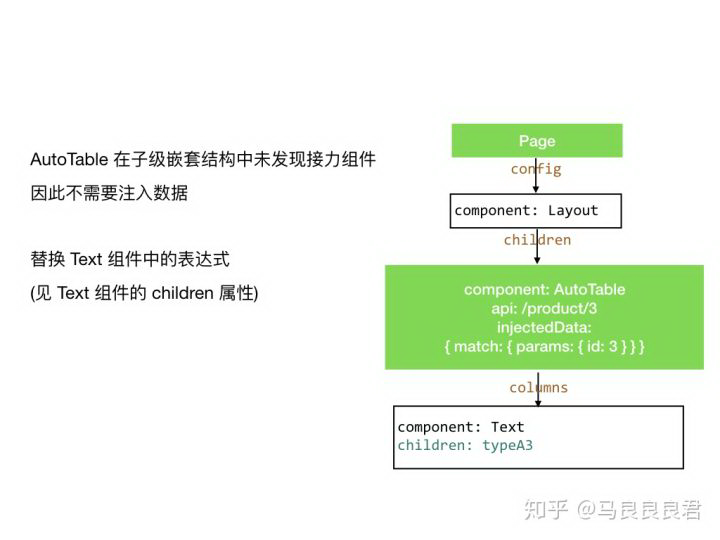
计算表达式
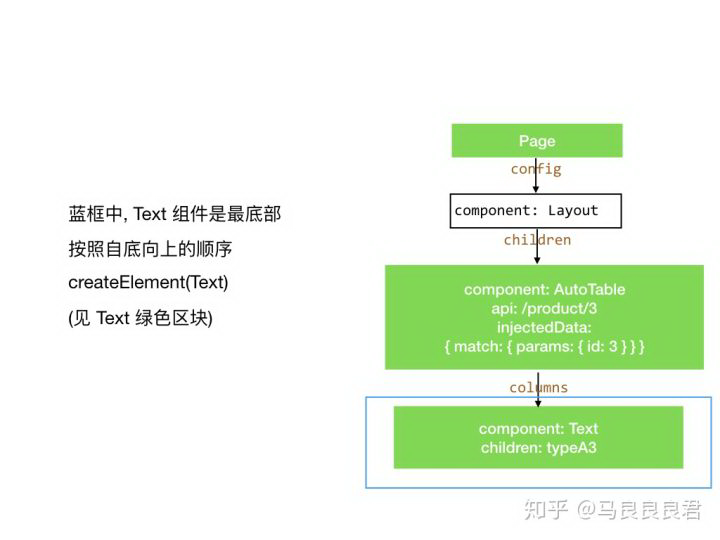
createElement(Text)
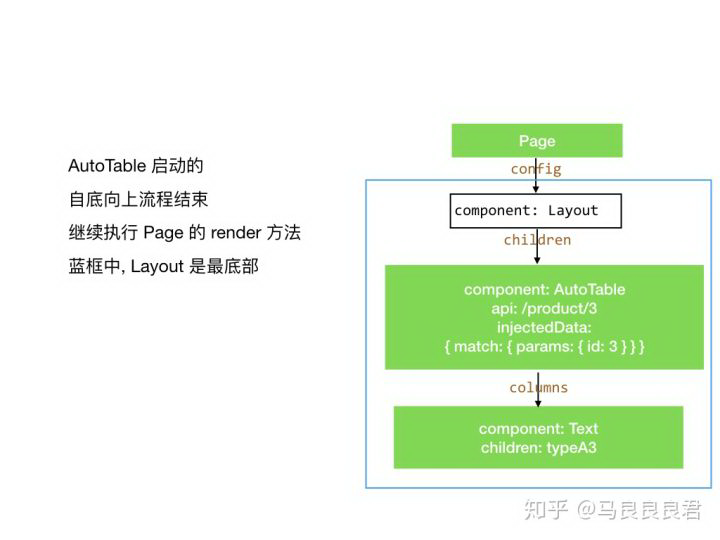
AutoTable 已被实例化,只剩 Layout
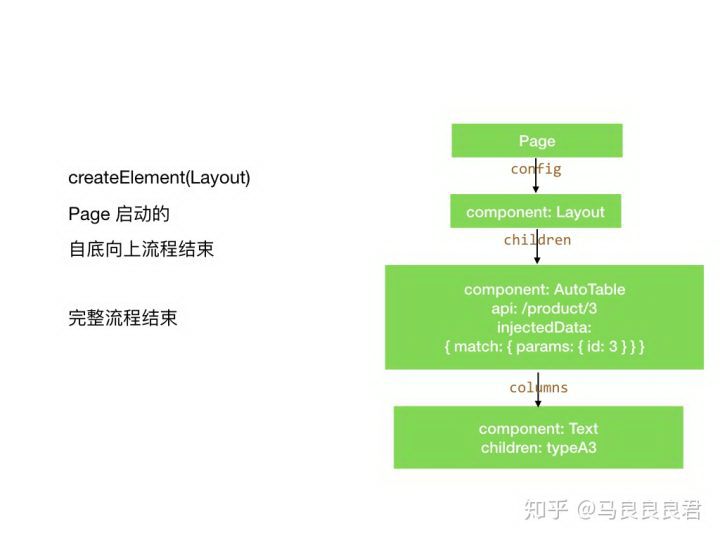
createElement(Layout),流程结束
总结
本篇文章介绍了知乎内部一个后台页面搭建平台「快页面」,主要内容是渲染器的实现原理。
在介绍原理之前,首先对这类工具的存在意义做了一些初步的分析;
随后以一份配置样例为例,介绍了渲染器的实现原理,包括「React 组件渲染」和「双花括号表达式渲染」两部分。
每一个配置化工具应该都是深度结合了业务方向,项目基础,团队投入等实际情况得到的结果。
因此理论上,在业界,同类工具应该有很多,所以本文也只是一种实现思路。
欢迎对这类工具感兴趣的小伙伴在评论区交流。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论