Ray 由伯克利开源,是一个用于并行计算和分布式 Python 开发的开源项目。本文将介绍如何使用 Ray 轻松构建可从笔记本电脑扩展到大型集群的应用程序。
并行和分布式计算是现代应用程序的主要内容。我们需要利用多个核心或多台机器来加速应用程序或大规模运行它们。网络爬虫和搜索所使用的基础设施并不是在某人笔记本电脑上运行的单线程程序,而是相互通信和交互的服务的集合。
云计算承诺在所有维度上(内存、计算、存储等)实现无限的可扩展性。实现这一承诺需要新的工具进行云编程和构建分布式应用程序。
为什么要使用 Ray?
很多教程解释了如何使用 Python 的多进程模块(https://docs.python.org/2/library/multiprocessing.html)。遗憾的是,多进程模块在处理现代应用程序的要求方面存在严重的短板。这些要求包括以下这些内容:
在多台计算机上运行相同的代码。
构建有状态且可以与之通信的微服务和 actor。
优雅地处理机器故障。
有效处理大对象和数值数据。
Ray(https://github.com/ray-project/ray)解决了所有这些问题,在保持简单性的同时让复杂的行为成为可能。
必要的概念
传统编程依赖于两个核心概念:函数和类。使用这些构建块就可以构建出无数的应用程序。
但是,当我们将应用程序迁移到分布式环境时,这些概念通常会发生变化。
一方面,OpenMPI、Python 多进程和 ZeroMQ 等工具提供了用于发送和接收消息的低级原语。这些工具非常强大,但它们提供了不同的抽象,因此要使用它们就必须从头开始重写单线程应用程序。
另一方面,我们也有一些特定领域的工具,例如用于模型训练的 TensorFlow、用于数据处理且支持 SQL 的 Spark,以及用于流式处理的 Flink。这些工具提供了更高级别的抽象,如神经网络、数据集和流。但是,因为它们与用于串行编程的抽象不同,所以要使用它们也必须从头开始重写应用程序。
用于分布式计算的工具
Ray 占据了一个独特的中间地带。它并没有引入新的概念,而是采用了函数和类的概念,并将它们转换为分布式的任务和 actor。Ray 可以在不做出重大修改的情况下对串行应用程序进行并行化。
开始使用 Ray
ray.init()命令将启动所有相关的 Ray 进程。在切换到集群时,这是唯一需要更改的行(我们需要传入集群地址)。这些过程包括:
有很多 worker 进程并行执行 Python 函数(大概是每个 CPU 核心对应一个 worker)。
用于将“任务”分配给 worker(以及其他计算机)的调度程序进程。任务是 Ray 调度的工作单元,对应于一个函数调用或方法调用。
共享内存对象存储库,用于在 worker 之间有效地共享对象(无需创建副本)。
内存数据库,用于存储在发生机器故障时重新运行任务所需的元数据。
Ray worker 是独立的进程,而不是线程,因为在 Python 中存在全局解释器锁,所以对多线程的支持非常有限。
并行任务
要将 Python 函数 f 转换为一个“远程函数”(可以远程和异步执行的函数),可以使用 @ray.remote 装饰器来声明这个函数。然后函数调用 f.remote()将立即返回一个 future(future 是对最终输出的引用),实际的函数执行将在后台进行(我们将这个函数执行称为任务)。
import rayimport time
# Start Ray.ray.init()
@ray.remotedef f(x): time.sleep(1) return x
# Start 4 tasks in parallel.result_ids = []for i in range(4): result_ids.append(f.remote(i)) # Wait for the tasks to complete and retrieve the results.# With at least 4 cores, this will take 1 second.results = ray.get(result_ids) # [0, 1, 2, 3]
复制代码
在 Python 中运行并行任务的代码
因为对 f.remote(i)的调用会立即返回,所以运行这行代码四次就可以并行执行 f 的四个副本。
任务依赖
一个任务还可以依赖于其他任务。在下面的代码中,multiply_matrices 任务依赖两个 create_matrix 任务的输出,因此在执行前两个任务之前它不会先执行。前两个任务的输出将自动作为参数传给第三个任务,future 将被替换为相应的值。通过这种方式,任务可以按照任意的 DAG 依赖关系组合在一起。
import numpy as np
@ray.remotedef create_matrix(size): return np.random.normal(size=size)
@ray.remotedef multiply_matrices(x, y): return np.dot(x, y)
x_id = create_matrix.remote([1000, 1000])y_id = create_matrix.remote([1000, 1000])z_id = multiply_matrices.remote(x_id, y_id)
# Get the results.z = ray.get(z_id)
复制代码
这里有三个任务,其中第三个任务依赖前两个任务的输出
有效地对值进行聚合
我们可以以更复杂的方式使用任务依赖。例如,假设我们希望将 8 个值聚合在一起。在我们的示例中,我们将进行整数加法,但在很多应用程序中,跨多台计算机聚合大型向量可能会造成性能瓶颈。在这个时候,只要修改一行代码就可以将聚合的运行时间从线性降为对数级别,即聚合值的数量。
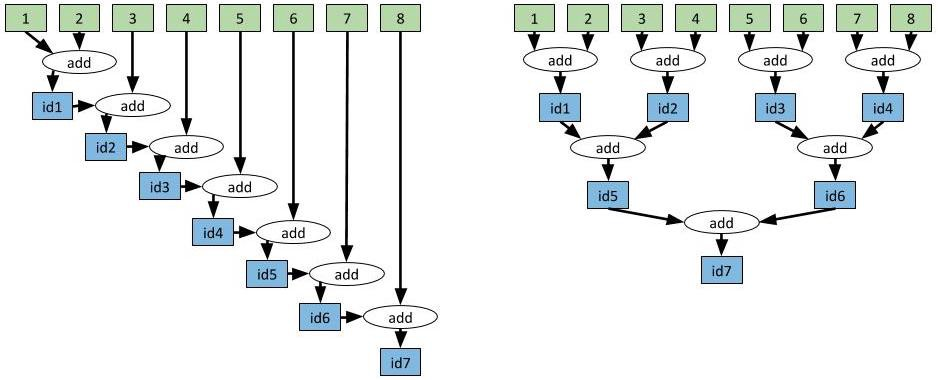
左侧的依赖图深度为7,右侧的依赖图深度为3。计算产生相同的结果,但右侧的依赖图执行得更快。
左侧的依赖图深度为 7,右侧的依赖图深度为 3。计算产生相同的结果,但右侧的依赖图执行得更快。
如上所述,要将一个任务的输出作为输入提供给后续任务,只需将第一个任务返回的 future 作为参数传给第二个任务。Ray 的调度程序会自动考虑任务依赖关系。在第一个任务完成之前不会执行第二个任务,第一个任务的输出将自动被发送给执行第二个任务的机器。
import time
@ray.remotedef add(x, y): time.sleep(1) return x + y
# Aggregate the values slowly. This approach takes O(n) where n is the# number of values being aggregated. In this case, 7 seconds.id1 = add.remote(1, 2)id2 = add.remote(id1, 3)id3 = add.remote(id2, 4)id4 = add.remote(id3, 5)id5 = add.remote(id4, 6)id6 = add.remote(id5, 7)id7 = add.remote(id6, 8)result = ray.get(id7)
# Aggregate the values in a tree-structured pattern. This approach# takes O(log(n)). In this case, 3 seconds.id1 = add.remote(1, 2)id2 = add.remote(3, 4)id3 = add.remote(5, 6)id4 = add.remote(7, 8)id5 = add.remote(id1, id2)id6 = add.remote(id3, id4)id7 = add.remote(id5, id6)result = ray.get(id7)
复制代码
以线性方式聚合值与以树形结构方式聚合值的对比
上面的代码非常清晰,但请注意,这两种方法都可以使用 while 循环来实现,这种方式更为简洁。
# Slow approach.values = [1, 2, 3, 4, 5, 6, 7, 8]while len(values) > 1: values = [add.remote(values[0], values[1])] + values[2:]result = ray.get(values[0])
# Fast approach.values = [1, 2, 3, 4, 5, 6, 7, 8]while len(values) > 1: values = values[2:] + [add.remote(values[0], values[1])]result = ray.get(values[0])
复制代码
更简洁的聚合实现方案。两个代码块之间的唯一区别是“add.remote”的输出是放在列表的前面还是后面。
从类到 actor
在不使用类的情况下开发有趣的应用程序很具挑战性,在分布式环境中也是如此。
你可以使用 @ray.remote 装饰器声明一个 Python 类。在实例化类时,Ray 会创建一个新的“actor”,这是一个运行在集群中并持有类对象副本的进程。对这个 actor 的方法调用转变为在 actor 进程上运行的任务,并且可以访问和改变 actor 的状态。通过这种方式,可以在多个任务之间共享可变状态,这是远程函数无法做到的。
各个 actor 按顺序执行方法(每个方法都是原子方法),因此不存在竞态条件。可以通过创建多个 actor 来实现并行性。
@ray.remoteclass Counter(object): def __init__(self): self.x = 0 def inc(self): self.x += 1 def get_value(self): return self.x
# Create an actor process.c = Counter.remote()
# Check the actor's counter value.print(ray.get(c.get_value.remote())) # 0
# Increment the counter twice and check the value again.c.inc.remote()c.inc.remote()print(ray.get(c.get_value.remote())) # 2
复制代码
将 Python 类实例化为 actor
上面的例子是 actor 最简单的用法。Counter.remote()创建一个新的 actor 进程,它持有一个 Counter 对象副本。对 c.get_value.remote()和 c.inc.remote()的调用会在远程 actor 进程上执行任务并改变 actor 的状态。
actor 句柄
在上面的示例中,我们只在主 Python 脚本中调用 actor 的方法。actor 的一个最强大的地方在于我们可以将句柄传给它,让其他 actor 或其他任务都调用同一 actor 的方法。
以下示例创建了一个可以保存消息的 actor。几个 worker 任务反复将消息推送给 actor,主 Python 脚本定期读取消息。
import time
@ray.remoteclass MessageActor(object): def __init__(self): self.messages = [] def add_message(self, message): self.messages.append(message) def get_and_clear_messages(self): messages = self.messages self.messages = [] return messages
# Define a remote function which loops around and pushes# messages to the actor.@ray.remotedef worker(message_actor, j): for i in range(100): time.sleep(1) message_actor.add_message.remote( "Message {} from actor {}.".format(i, j))
# Create a message actor.message_actor = MessageActor.remote()
# Start 3 tasks that push messages to the actor.[worker.remote(message_actor, j) for j in range(3)]
# Periodically get the messages and print them.for _ in range(100): new_messages = ray.get(message_actor.get_and_clear_messages.remote()) print("New messages:", new_messages) time.sleep(1)
# This script prints something like the following:# New messages: []# New messages: ['Message 0 from actor 1.', 'Message 0 from actor 0.']# New messages: ['Message 0 from actor 2.', 'Message 1 from actor 1.', 'Message 1 from actor 0.', 'Message 1 from actor 2.']# New messages: ['Message 2 from actor 1.', 'Message 2 from actor 0.', 'Message 2 from actor 2.']# New messages: ['Message 3 from actor 2.', 'Message 3 from actor 1.', 'Message 3 from actor 0.']# New messages: ['Message 4 from actor 2.', 'Message 4 from actor 0.', 'Message 4 from actor 1.']# New messages: ['Message 5 from actor 2.', 'Message 5 from actor 0.', 'Message 5 from actor 1.']
复制代码
在多个并发任务中调用 actor 的方法
actor 非常强大。你可以通过它将 Python 类实例化为微服务,可以从其他 actor 和任务(甚至其他应用程序中)查询这个微服务。
任务和 actor 是 Ray 提供的核心抽象。这两个概念非常通用,可用于实现复杂的应用程序,包括用于强化学习、超参数调整、加速Pandas等 Ray 内置库。
英文原文:
https://medium.com/@robertnishihara/modern-parallel-and-distributed-python-a-quick-tutorial-on-ray-99f8d70369b8
















评论