
在最近的几年中,人工智能随着神经网络的突破,得到了巨大的发展,特别在图像、分析、推荐等领域。
在人工智能快速发展的同时,计算规模不断扩大、专家系统过于单一、神经网络模型的灵活性、应用领域的复杂行等问题,也在不断升级。在这样的环境下,分布式人工智能的发展被研究机构和大型企业提上日程。
分布式人工智能,可以解决集中化人工智能的几个主要问题:
规模化的计算问题。
计算模型的拆分训练。
多智能专家系统的协作。
多智能体博弈和训练演化,解决数据集不足的问题。
群体智能决策和智能系统决策树的组织,适应复杂的应用场景,比如工业、生物、航天等领域。
适应物联网和小型智能设备,联合更多的计算设备和单元。
针对现有的分布式人工智能组件和框架的研究,可以看下几个主流框架的方案。
Tensorflow 的分布式方案
Tensorflow 底层数据是高性能的 gRPC 库,分布式集群的组件主要是三个部分:client、master、worker process。运用它的组件,可以形成两种主要的分布式部署模式:单机多卡(single process)和多机多卡(multi-device process)。方案出于 Martin Abadi、Ashish Agarwal、Paul Barham 论文《TensorFlow:Large-Scale Machine Learning on Heterogeneous Distributed Systems》。
它的部署和运作模式,如图 1-1 所示:
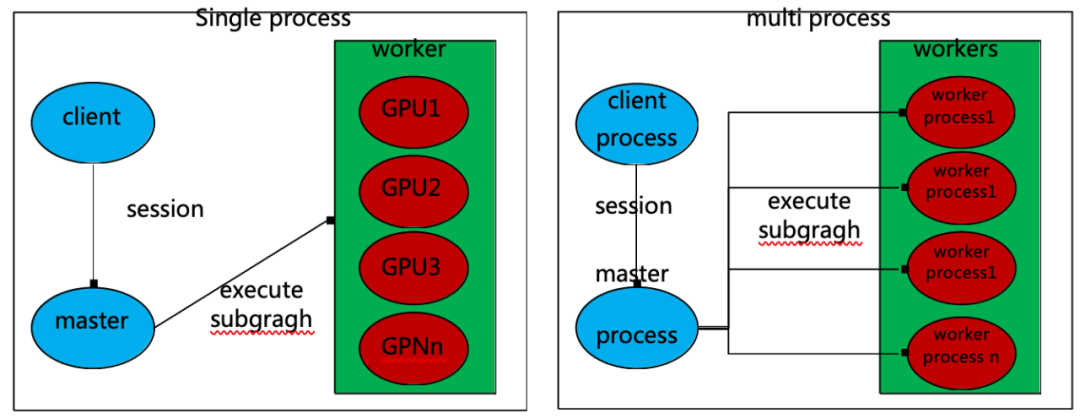
图 1-1 Tensorflow 单机单卡与多级多卡部署模式
对于普通的机器学习,单机单卡就可以进行运算,在运算规模不断升级的时候,就需要
对 tensoflow 的训练设计分布式结构。
机器学习在的参数训练,主要是两大过程:
使用卷积参数训练梯度
根据梯度再优化更新参数
在大规模的计算过程中,就需要进行集群计算,在小型规模的时候,可以使用单个机器,多个 CPU/GPU 来进行计算,在规模越来越大的时候,可以使用多个机器进行并行计算。
在 tensorflow 中分布式集群定义为一个“集群任务”(tf.train.ClusterSpec),将任务分布在不同的“服务器”(tf.train.Server)中,服务器中包含了“master”运行进程和”worker“计算进程。在分布式集群运算中,主要有以下结构:
Task:分布式中的计算任务,每个 job 结构中,每个任务拥有唯一索引。
Job:每个 Job 表示了一个完整的训练目标,其中的 Task 都有唯一的目标,为同一个训练目标进行任务拆分。
Cluser:集群集合,其中管理了多个 Job,一般一个集群对应了一个专门的神经网络,其中不同的 job 负责了不同的目标,比如梯度计算、参数优化、任务训练等。
Tensorflow Server:处理服务节点过程,并且对外提供 master server 和 worker server 的接口服务。
Master Server:和远程分布式设备进行交互的服务,协调多个 worker server 工作。
Worker Service:Tensorflow 图计算过程中,任务进程处理的服务,单独运行各自的任务。
Client:客户端,用来管理和启动 AI 工作,与远程服务集群交互。
Tensorflow 的多机多卡分布式模式,主要有以下几种:
In-graph 模式:在多机多卡的模式下,各自的节点和运算服务,都通过单一的节点进行数据分发,拥有集中化的管理方式,最终数据归并到统一的节点上。
Between-graph 模式:训练的数据保存在各自的节点上,不进行分发。每个节点的权重都是平等的,当计算节点各自计算完以后,需要告诉参数服务器,并且更新优化参数,是比较推荐的分布式方式。
根据 Tensorflow 的分布式机器学习方案,我们可以总结它存在的一些缺点,如下所示:
Tensorflow 在分布式的计算方式中,分为了训练和参数更新服务,极大得扩展了规模化的计算能力,但是在数据归并和多级分层上,并没有提供非常好的解决方案。没有较好的计算模型,去提供多层次的分布式结构。
Tensorflow 在分布式的计算模型中,主要分为了训练任务、梯度计算、参数更新等,但是确没有提供一个较好的计算模型构造方式,去提供分布式 AI 所需要的任务分发、数据归并、模型更新等能力。
Tensorflow 在分布式的组织方式上,更像是一个平级层次的分布式,最终统一归并成为一个最终模型,它最终完成的是一个集中化的单一专家系统,无法提供群体智能能力,也无法形成多群体博弈对抗的协调决策,无法支持多专家系统的兼容和协调。
Tensorflow 需要运行在高性能计算机,高性能的 GPU 下,很难支持小型设备、物联网等多设备的边缘化集群计算。
Spark 分布式机器学习
上面提到,Tensorflow 在机器学习并行计算的多层结构上,没有较好的解决方案,Spark 根据它在大数据领域的分布式框架,很好的解决了分层任务划分的处理。
在 Spark 中,计算模型可以设计成为有向无环图 DAG,无环图的顶点是 RDD,它是 Spark 的核心组件。RDD 是一种弹性的分布式数据集,它可以支持多个 RDD 分片的依赖、变换(transformation)和动作 (action),它可以从从 RDD A 变换成为 RDD B,这个 transformation 就是 DAG 无环图的边。通过 DAG 的表示方法,表示计算模型,并且编译成为 Stage。这个模型的表示,如图 1-2 所示:
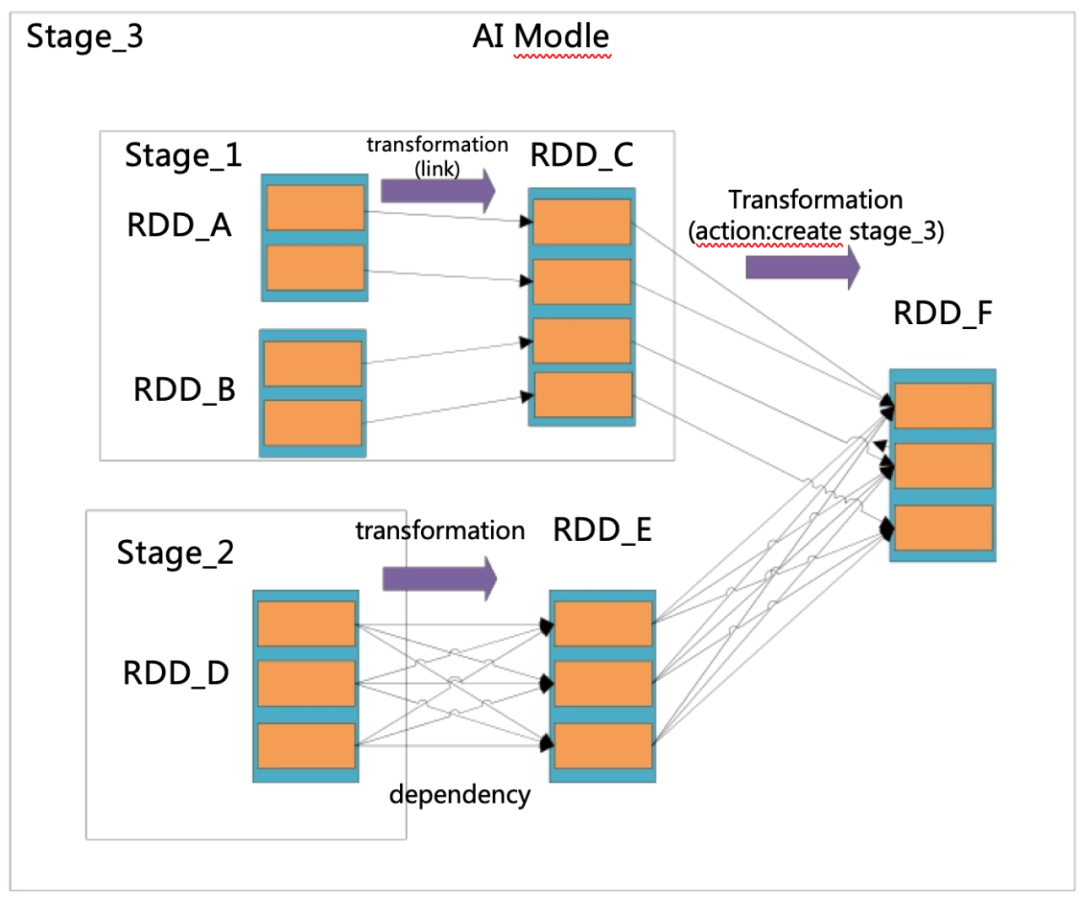
图 1-2 Spark 计算模型和 Stage 形成的 DAG 图
Spark 运用它的分布式机制,可以支持多个 Stage 并行计算,也能支持 Stage 下属 Stage 模型分层结构。Spark 基于它的 master-worker 架构,可以将 DAG 中的 stage 分割,指定到不同的机器上面执行任务。它的驱动器 driver 负责协调任务和调度器组件 scheduler,调度器分为 DAG 和 Task 调度器,用来分配 Task 到不同的运算单元。它的分布式并行运算流程,如图 1-3 所示:
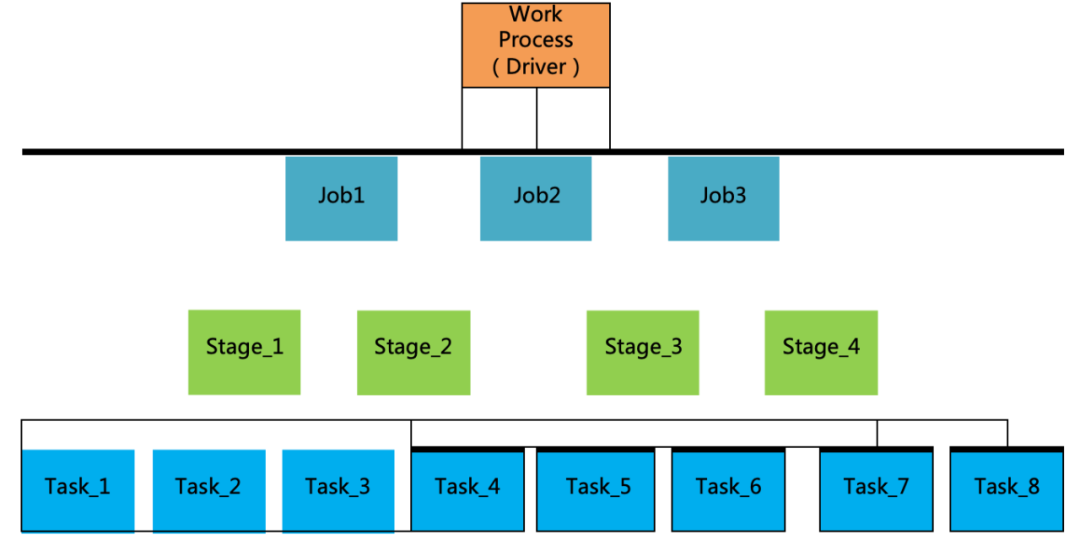
图 1-3 Spark 分布式并行计算分层
上图表示了在分布式 AI 的训练环节,通过 Driver 规划整体模型,通过节点 Executor 端分别计算,再回归汇总给 Driver,它们的具体要点如下所示:
一个具体的 AI 系统总结为一个工作流 Work Process,其中包含了许多 action 算子操作。
action 算子将不同的工作类别划分为不同 Job。
Job 根据模型的宽以来,划分给不同的 Stage 小模型。
Stage 的内部也可以再划分成为多个小型的 Stage 模型,如图 1-2 所示。
Stage 将功能相同的,DAG 中的边运算归纳为不同的 Task。
Task 可以提交 Executor 做最小运算单元的运算,最终反馈给 Driver 进行模型更新和存储。
通过 Spark 的分布式计算框架与机器学习 caffe 运算库进行结合,伯克利大学 Michael I. Jordan 组发布了论文《SparkNet: Training Deep Network in Spark》,他们开发了 SparkNet 库,它是基于 Spark 的深度神经网络架构,主要能力如下所示:
提供易用的,用于神经网络的接口,可以快速访问 RDD。
提供 Scala 的接口,可以与 caffe 进行交互。
提供轻量级的卷积 tensor 库。
提供简单的并行机制和通讯机制。
即插即拔,易于部署。
兼容现有的 caffe 模型。
根据 Spark 的分布式机器学习机制,我们可以总结它存在的一些缺点,如下所示:
Spark 支持大规模的模型计算分层,但是计算消耗较大,不适合用在较小规模的分布式方案。
Spark 在节点和节点之间的数据路由不是非常灵活。
Spark 难以在小型化设备进行联合学习运算,无法部署在小型化设备之上。
Spark 的框架是一个并行计算框架,它的模式是任务确认调度-模型划分-分片计算-归并总结,更适合大数据集的机器学习,不适合多节点博弈等强化学习方法。
Google 联合学习方案
针对小型化设备,google 在一篇文章《Federated Learning: Collaborative Machine
Learning without Centralized Training Data》中,提出了联邦联合学习的概念。
它的工作原理如下所示:
手机或者其他小型设备,下载云端的共享模型。
每个小型设备的用户,通过自己的历史数据来训练和更新模型。
将用户个性化更新后的模型,抽取成为一个小的更新文件。
提取模型的差异化部分,进行加密,上传到云端。
在云端将新用户的差异化模型和其他用户模型,进行 Average 平均化,然后更新改善现有共享模型。
这样工作的好处有如下部分:
聚合了边缘的小型化设备(比如手机),增加了 AI 的数据来源和计算能力来源。
在机器学习的模型结果上,更加适应广泛用户的行为数据模型。
不同群体之间,可以产生博弈和不断强化的模型结果,模型可以在广泛的分布式基础下,不断迭代更新。
本文转载自:金科优源汇(ID:jkyyh2020)
原文链接:三种分布式人工智能主流框架方案对比




