

一、背景
随着不断加快的国际化步伐,携程逐渐开始在海外开展一系列的市场营销布局。搜索引擎广告作为海外营销的重要组成部分,携程也开始在海外各个搜索引擎上投放广告。
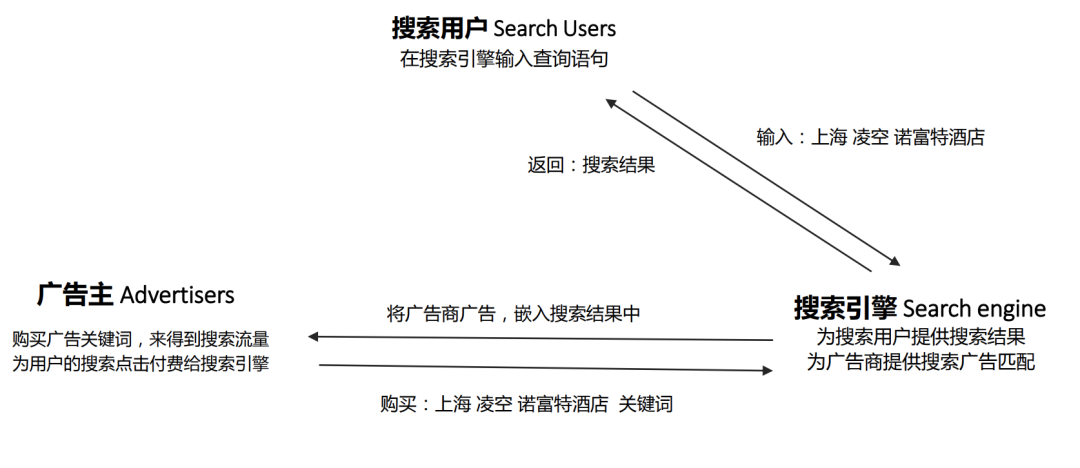
一个搜索引擎广告生态,通常有三个参与方:广告主、搜索用户以及搜索引擎。搜索引擎广告是指广告主根据自己的产品或服务的内容、特点等,确定相关的关键词,撰写广告内容并自主定价在搜索引擎端投放的广告。当用户在搜索引擎上搜索到广告主投放的关键词时,相应的广告就会展示,并在用户点击后对广告主进行收费。
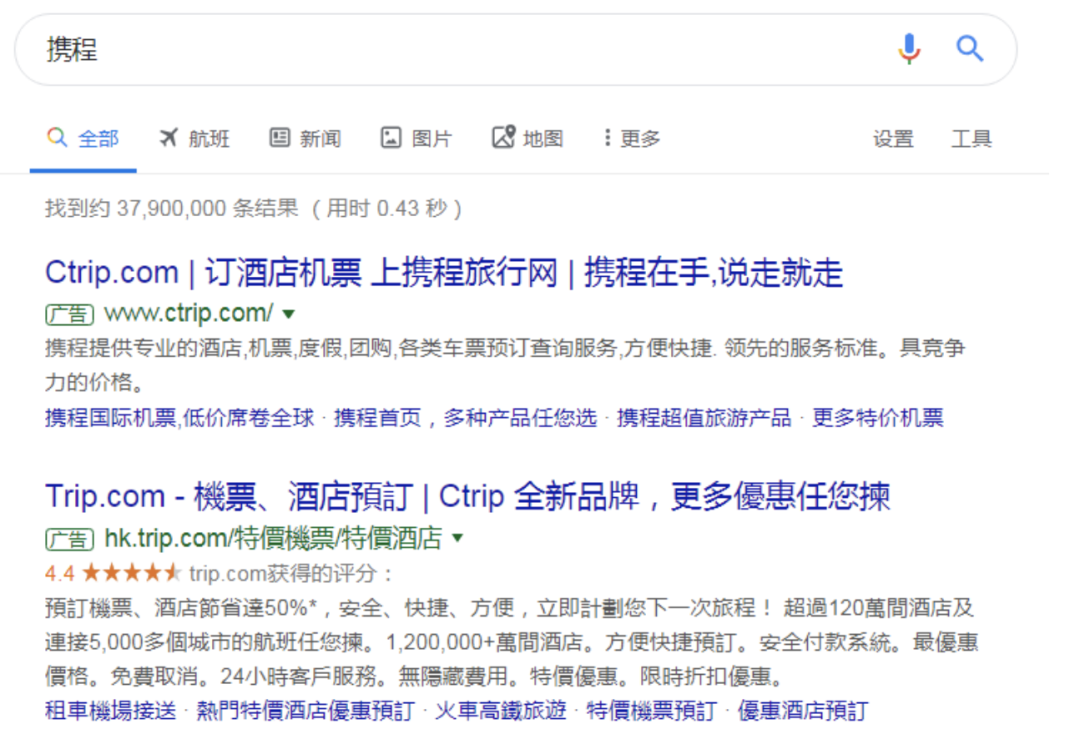
下图为携程在谷歌搜索引擎上购买“携程”广告关键词后,在搜索结果会展现相关的广告截屏。
许多 OTA(Online Travel Agency)都会投入大量资金进行搜索引擎广告的投放,来获得旅游相关需求的搜索流量,以提高订单量和公司收入,比如 booking.com 在 18 年单季度在谷歌上投放广告就达 10 亿美元。
因此对于有搜索引擎投放需求的公司来说,提升搜索引擎广告效果是一件重要的事情。搜索引擎效果提升主要是要选对合适的关键词、选择合适的广告定价和设计好的广告创意来吸引用户。本文着眼于能自动化生成高质量广告关键词来减少人力运营成本,提高搜索引擎流量的质量,进而提高投入产出比。
传统的搜索引擎关键词生成方法都以人工运营为主,比如有如下两种:
(1)拓词:人工头脑风暴思考整理出关键词生成规则,然后基于这些关键词生成规则来构建关键词。
(2)捞词:从已有的搜索语句中,找到还未购买过的部分,人工与广告主的产品/服务与落地页进行匹配,来构建关键词。
这些传统方法的痛点在于:
(1)需要业务每日投入精力进行固定操作,人力成本比较高。
(2)无法做到精细化地投放一些广告关键词。
因此,我们基于这两种传统方法的思路,并针对相关痛点,来构建了广告关键词智能生成方法。接下来将对这个智能广告关键词生成方法进行阐述,并就其中分词与词性标注、搜索意图识别等核心模块用到的算法进行介绍。最后还将介绍一些其他探索与尝试过的广告关键词智能生成方法。
二、拓词智能化
拓词的智能化,也就是自动总结关键词生成规则来构建关键词,能体现人主观角度对用户搜索习惯的理解与归纳。在对这种传统方法智能化的过程中,一方面我们对归纳用户搜索习惯进行了自动化,同时为了能更精细化地生成符合用户搜索习惯的关键词,还增加了对产品名的解析模块,并且添加了消除关键词歧义的步骤,使得获得的广告流量用户搜索意图更加纯粹,提高期望转化率。
具体框架如下:
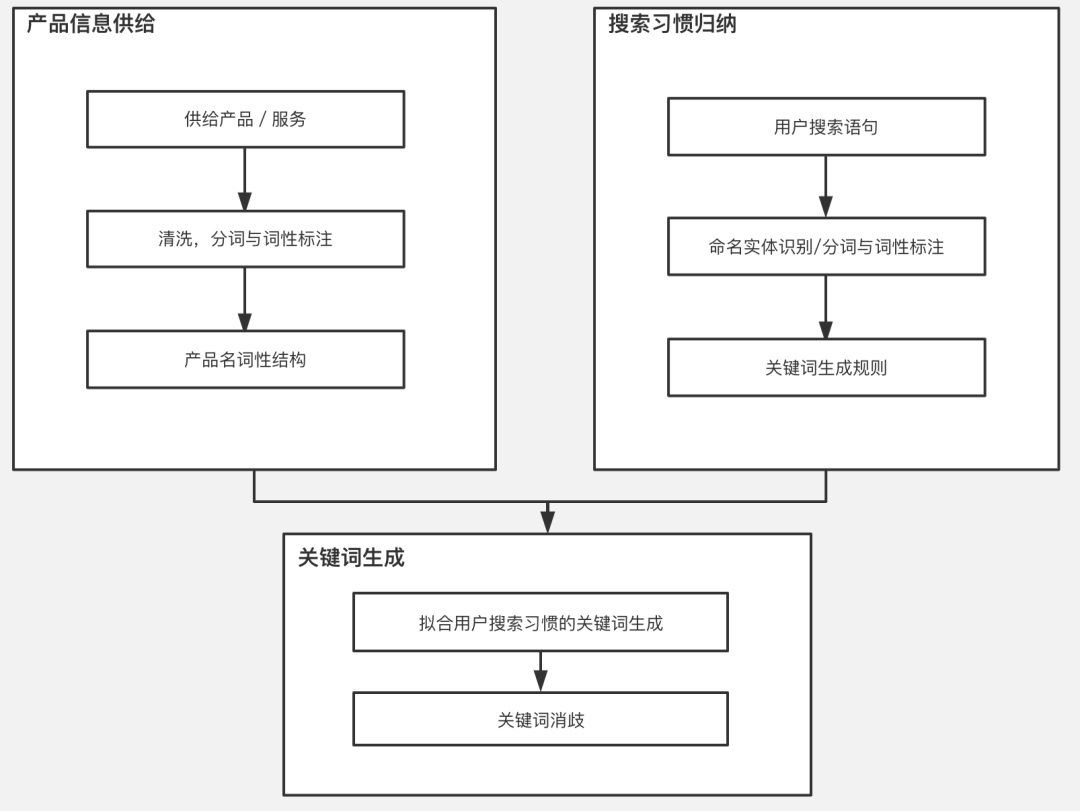
以下会阐述各个模块的一些细节:
2.1 产品信息供给模块
产品信息供给模块一方面负责存储可以在搜索引擎上投放的产品或者服务的相关数据。具体对于 OTA,可以有城市住宿供给产品、酒店住宿供给产品、航线类机票供给产品等。同时,这个模块也对产品名称进行了清洗、分词与词性标注,方便后续结合关键词生成规则进行关键词生成。以下以住宿产品为例,阐述模块的细节。
分词与词性标注例子:
(1) 虹桥火车站 ——> {地理兴趣点}
(2)青城山小天井客栈 ——> 青城山 + 小天井 + 客栈 ——> {地理兴趣点} + {酒店名} + {住宿需求词}
(3)Americinn by Wyndham Northfield ——> Americinn by Wyndham + Northfield ——> {酒店名} + {城市名}
针对分词与词性标注的方法如下:
以酒店为例。首先,对于酒店名分词这种细分分词场景,类似于地址解析的场景,是一个词性结构一致性较强并且与地理实体强相关的场景,基于词典的分词与词性标注方法已经有比较高的效果,但仍存在一些问题。这里针对两种问题进行了一定的处理来提高分词与词性标注的准确性。
(1)应对地理歧义的问题,采用地理结构化词典的方法
华盛顿既可能是酒店连锁品牌名称,也可能有美国首都“华盛顿”的含义。虹桥既可能是一家酒店的酒店名,也可能有上海”虹桥“这个地理兴趣点的含义。在英文产品名称的词性标注中,这种情况存在更多,因为国外很多地方存在重名的现象,比如 Victoria(维多利亚)这个单词,在几十个国家都有相应的建筑、街道或者酒店名包含单词 Victoria,因此很难正确地对类似存在歧义的词语进行词性标注。
针对这种地理实体的歧义性,采用基于 Geohash 的地理结构化词典来处理这种问题。Geohash 的原理就是将一个地理位置的经纬度,转化为一个 Hash 值,从而达到一个地理分区域的效果。对地理实体进行 Geohash 后,地理实体被分到各个区域内,对酒店名进行解析时,只使用关联区域内的词典,从而大大减少了地理歧义性问题导致的错误。
(2)应对词典质量不足的问题,采用数据增强+BILSTM-CRF 的方法
基于词典与规则的方法强依赖于词典的质量,公司内部的地理词典基本涵盖了基本的城市、地理兴趣点信息,但仍有部分地理实体仍未包含,比如一些道路名称、山名、村名等。针对这种情况,我们使用深度学习模型来处理这种情况,我们希望能让模型学习到 xx 路,xx 山,xx 村,xx 学校等这样的语言结构是一个地理兴趣点,从而弥补词典质量不足的问题。
具体的,采用了数据增强+BILSTM-CRF 模型的方法来处理。
采用随机生成拼接的方式,生成大量有效的正确标注数据,让模型能学到更多信息。比如由于道路名的缺乏,导致“成都米果文创民宿东安南路店”、“佳木斯小时光民宿育新街分店”中的“东安南路”、“育新街” 无法被正确标注,我们随机生成各种包含 {城市名} + {酒店名} + {住宿需求}+xx 路/xx 街+店/分店/旗舰店/二店/三店等人造酒店名。
增加了这部分数据后,开始进行分词与词性标注算法的训练。常见的分词与词性标注算法,有 CRF、HMM、RNN、BILSTM-CRF 等。BILSTM-CRF 在多个自然语言序列标注问题(NER、POS)上都表现优秀。这里采用 BILSTM-CRF 模型。
具体 BILSTM-CRF 模型如下:
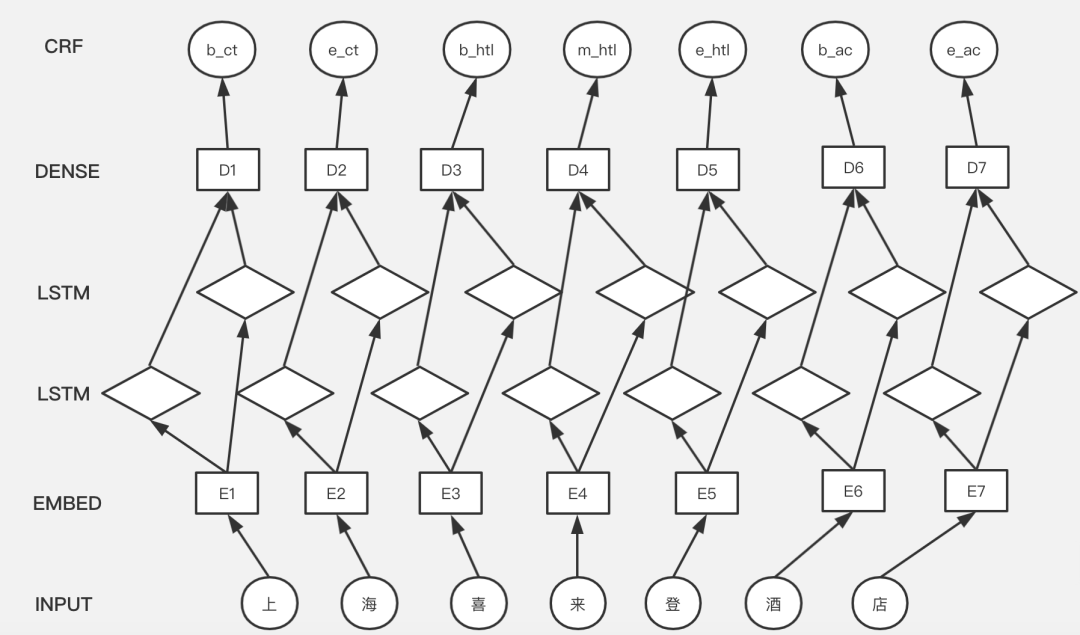
第一层为 Embedding 层,输入文本转化为向量表示。第二层为 BILSTM(双向 LSTM)层,相比单向的 LSTM,BILSTM 能同时学到句子从前到后,以及从后到前的信息。第三层为一个全连接层。第四层为一个 CRF 层。
通过以上一些方法,我们完成了对中英住宿产品名称的解析,基于中英文解析结果,我们使用了翻译、平行语料词对齐算法实现跨语言的分词与词性标注(Cross-lingual NER)。
2.2 搜索习惯归纳模块
这个模块通过对用户搜索语句进行解析,归纳得到用户搜索语句的常见搜索习惯。
具体搜索语句的解析方法有如下:
(1)基于命名实体识别的解析方法
对搜索语句进行命名实体识别,从而得到搜索语句的解析结果。
例子:
上海酒店住宿 ——> 上海 + 酒店住宿 ——> {城市名} 酒店住宿
虹桥机场宾馆优惠 ——> 虹桥机场 + 宾馆优惠 ——> {地理兴趣点名称} 宾馆优惠
Beijing family accomodation ——> Beijing + family accomodation——> {城市名} family accomodation
具体方法为:
在搜索引擎搜索语句的场景,从搜索引擎广告平台拿到的用户搜索语句是会与一个产品落地页一一对应的,因此直接基于广告落地页相关实体信息构建命名实体识别规则就有比较好的效果,也免除了耗费大量的精力在构建训练集上。
(2)基于分词与词性标注的解析方法
对搜索语句进行分词与词性标注,从而得到搜索语句的词性结构。
例子:
建滔诺富特酒店 ——> 建滔诺富特 + 酒店 ——> {酒店名} + {住宿需求词}
淞虹路地铁站携程美居 ——>淞虹路地铁站 + 携程美居 ——>{地理兴趣点} + {酒店名}
上海住宿 ——> 上海 + 住宿 ——>{酒店名} + {住宿需求词}
具体方法为:基于词典来进行分词与词性标注。
2.3 关键词生成模块
此模块主要进行关键词生成。从产品供给模块抽出需要进行投放的产品,并基于一定规则从关键词生成规则模块中抽取相应规则进行关键词生成,并匹配相应的产品落地页与广告物料信息。
在生成关键词之后,因为生成的关键词的用户意图仍存在可能性会指向多个供给产品,因此会对生成后的关键词进行歧义性判断,过过滤掉其中存在歧义性的关键词。
消歧具体方法为:
(1)基于字符串匹配
如果不同产品生成相同关键词或者关键词存在不同产品名里,那么这个关键词会被过滤。
(2)基于搜索点击数据的分布结果
如果一个关键词,在搜索点击数据里,发现点击分布在多个搜索结果上,那么这个关键词会被过滤。
(3)基于搜索点击数据,构建语义匹配模型
如果一个关键词,与多个产品的语义匹配分数够高,那么这个关键词会被过滤。这里我们采用了 DSSM 模型。DSSM 是一个 2013 年的一个 query/doc 的相似度计算模型,被广泛运用于广告召回、排序场景中。DSSM 的核心思想就是将不同对象映射到统一的语义空间中中,利用该空间中对象的距离计算相似度。
三、捞词智能化
捞词智能化,指自动从用户住宿搜索语句中挖掘出能进行广告投放的搜索语句,并匹配相应的产品与广告落地页来生成新的广告关键词。这个场景可以视为一个用户意图识别的场景,即能对收集到的用户搜索语句的搜索意图进行识别并和广告主的供给产品或服务进行匹配,从而构建搜索广告关键词。
从 OTA 的角度,无论是公司内部收集的网页端或者 APP 端收集到的用户搜索语句还是搜索引擎广告平台拿到的用户搜索语句,都是旅游领域的用户搜索行为(Travel Domain Userintent)。
因此项目里对这样的旅游领域的搜索意图大致分为了如下四大类搜索意图以及 12 小类搜索意图:
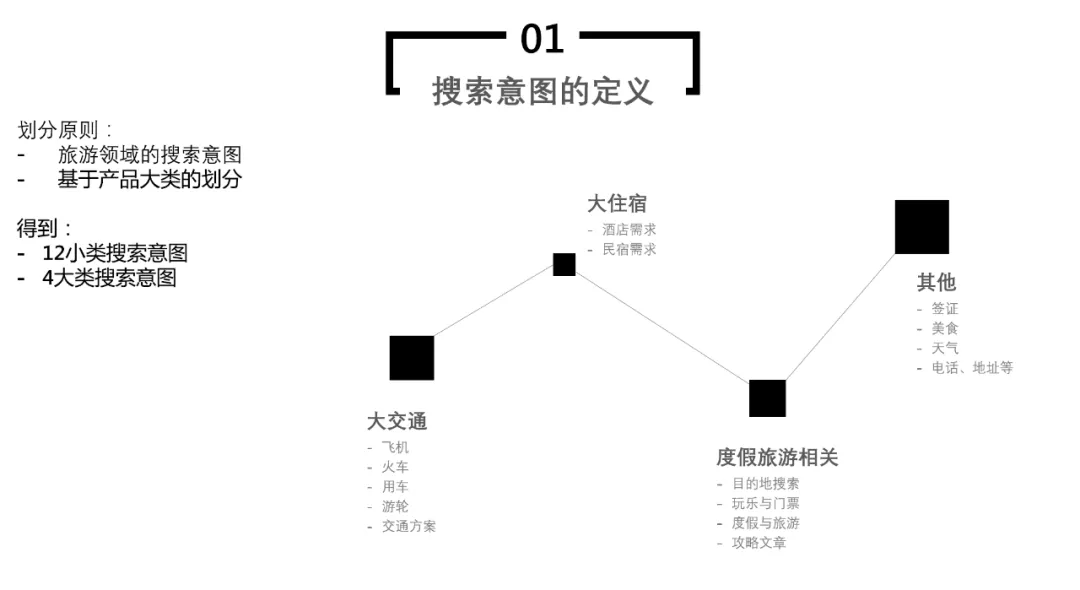
以下阐述一下具体在酒店搜索方面,捞词智能化的实现框架:

下面我们逐一地来看看模块 A (是否住宿相关),模块 B (酒店住宿意图识别) 的内部细节。
1)模块 A (判断是否住宿相关)
我们将这个问题视为文本二分类的场景来处理,并基于 Bert 预训练做 fine-tuning 来构建分类模型。Bert 是 2018 年提出的一个 NLP 预训练模型,Bert 的预训练过程能学到强大的语义表征能力,同时 google 发布了中文的预训练模型,使得我们用有限的样本,做 fine-tune 即可在一些场景获得不错的效果。
具体训练集我们使用了基于 OTA 平台的搜索点击数据,如果一个搜索语句大概率点击的是住宿相关的搜索结果,那么就生成一条住宿相关的搜索语句正样本。相应的,如果一个搜索语句大概率点击的是非住宿相关的搜索结果,那么就生成一条非住宿相关的搜索语句正样本。分类为住宿相关,并且概率大于一定阈值的搜索语句会进入住宿意图识别模块。
2)模块 B (酒店住宿意图识别)
我们将这个问题视为一个语义匹配的场景来处理,传统的语义匹配场景有类似于 query-query 相似性算法、query-document 相似性算法,这里我们可以视作为 query-product 相似性算法。
具体数据集为:
基于搜索点击数据
如果一个关键词,在搜索点击数据里,发现大概率点击在某一个搜索结果(某旅游产品)上,那么这个关键词会被定义语义指向这个产品。反之,则说明这个关键词不指向这个产品。
基于产品别名数据
产品的别名与该产品的正式名称会被视作是语义一致的。
但由于 OTA 搜索端和搜索引擎搜索端场景的不同,用户的搜索习惯也会有很大的差异,比如搜索引擎端的搜索语句的长度通常要比 OTA 搜索端长度长很多,也更复杂。比如搜索引擎端,用户可能会搜索“静安寺 携程住宿 优惠券”,而在 OTA 搜索端,很难见到用户有这样的搜索行为。因此,我们构建了一些同义改写方法进行 query rewriting,使得训练集与真实场景更加贴合。
语义匹配采取的方案是基于 DSSM+BERT fine-tuning。采用 DSSM+BERT 的组合,是因为 Bert 的语义匹配精度更高,DSSM 的语义匹配性能好。DSSM 可以离线计算好产品的向量表示,可以做到语义匹配快速粗召回。因此设计为基于 DSSM 作意图语义召回,再针对召回的结果再用 Bert 进行一一匹配,使得在保证方案性能的情况下提高匹配准确率。
四、其他方法
除了以上两种方法,我们也探索和尝试了其他的广告关键词智能化生成思路,以下进行简单介绍:
4.1 基于搜索联想(query suggestion)的广告关键词生成
当我们在搜索引擎里进行搜索时,搜索引擎通常会在下拉框或者搜索结果页推荐给我们给我们一些搜索语句联想(query suggestion)。
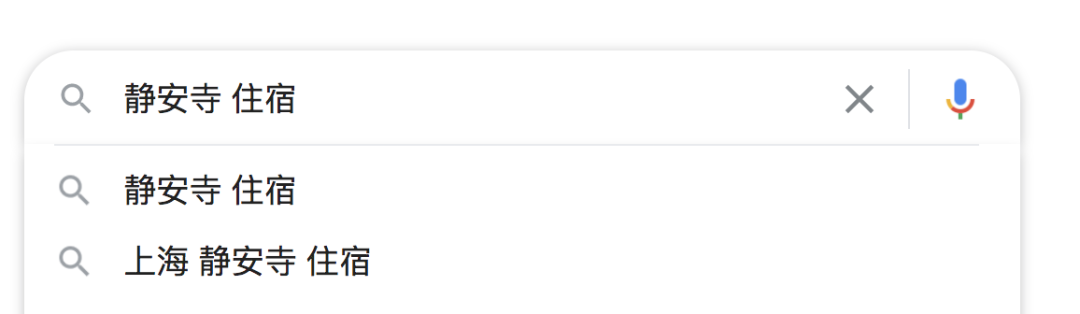
通过对搜索引擎搜索联想一些方法的研究,我们可以得知搜索联想背后的算法通常会考虑:
(1)Popularity: 这个搜索联想的结果搜索次数较多
(2)Relevence: 这个搜索联想的结果与原搜索语义相关
(3)Diversity:在 Relevence 的基础上,搜索联想会尽量考虑更多样化的联想结果,给用户更好的搜索体验。
Popularity 和 Relevence 的特性表示搜索联想结果是一个优质的搜索广告关键词来源,因为搜索联想的结果通常会有较高的流量并且语义相似性较高。Diversity 的特性则有利有弊,好的方面在于多样化能带来更多样更长尾的流量(长尾的流量通常更便宜,因此 ROI 更高),然而多样化也可能带来不可控的劣质流量。
4.2 基于同义改写的广告关键词生成
对于一些有有优异表现的广告关键词,对其进行同义改写可以得到更多相似的优质的广告关键词。具体的方法可以有:
(1)基于用户搜索查询重写的同义改写 (Query Rewriting Approach)
(2)基于用户搜索点击图谱的同义改写(Click Graph Approach)
(3)基于同义语法替换的同义改写
五、总结
以上阐述我们 SEM 搜索引擎广告关键词智能化生成的几种方法,主要介绍了两种传统关键词生成方法的智能化思路。
对于未来的规划与展望可能主要有两个方向:
(1)从中英日韩到更多小语种语言:现在主要做的还都是中英日韩广告关键词的相关工作,对小语种广告关键词进行了一定的探索与开发,以后会更多的往这方向拓展。
(2)从人的理解到机器理解:现在的方法生成的关键词大多数都是人可理解的,比如分词、词性标注等,都是从人的角度可解释的,但没有很多尝试基于机器理解的思路。在 SEM 的框架内,都是程序在运行,因此可能存在一些语法无法解释的关键词却会有更好的表现的情况,这可能是一个可以琢磨的方向。
作者介绍:
遥新,携程高级数据分析师,热爱用数据解决实际问题。
本文转载自公众号携程技术(ID:ctriptech)。
原文链接:
https://mp.weixin.qq.com/s/OB2r761_8xcR2CXKS3JwYQ

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论