

来自伯克利的人工智能研究团队提出了一种基于群体的数据增强算法(PBA),这是一种能快速有效地学习最新方法来增强神经网络训练数据的算法。PBA 的输出结果足以与之前 CIFAR 和 SVHN 数据集上的最佳成绩匹敌,但前者的计算量只有千分之一,从而使研究者和从业者使用单颗工作站 GPU 就能有效地学习新的增强策略。用户可以在众多场景中使用 PBA 来提升图像识别任务中的深度学习性能。
作者在近期发布的一篇论文中探讨了 PBA 的表现(https://arxiv.org/abs/1905.05393.pdf),并介绍了在 Tune 框架(https://ray.readthedocs.io/en/latest/tune.html)上对新数据集使用 PBA 算法的简单步骤(https://github.com/arcelien/pba)。
为什么要关注数据增强?
近年来深度学习模型的发展主要归功于这些年收集到的庞大而多样的数据。数据增强是一种策略,使从业者无需收集新数据就能显著提升已有数据的多样性,从而更好地服务训练模型。诸如裁剪、填充和水平翻转等数据增强技术通常用于训练大型神经网络。然而,神经网络训练中使用的大多数方法只用到了基本的增强技巧。虽然神经网络体系结构的研究愈加深入,但业界开发更强大的数据增强技术,探索能够捕获数据不变属性的数据增强策略的步伐却非常缓慢。

一张数字”3“的原始图像与应用基础数据增强算法之后的结果。
最近,谷歌通过 AutoAugment(https://arxiv.org/abs/1805.09501)这种新的自动数据增强技术提升了 CIFAR-10 等数据集的精确度。之前的数据增强只使用水平翻转或填充和裁剪等一组固定的转换,而 AutoAugment 的成果表明这种老式算法有很大的改进潜力。AutoAugment 引入了 16 种几何和基于颜色的转换,并制定了一种新的增强策略,可以对每批数据应用最多两个有一定幅度级别的转换。训练模型会直接用数据强化学习这些性能更高的增强策略。
有什么成果?
AutoAugment 是一种成本高昂的算法,它需要训练 15,000 个模型才能收敛,才能为基于强化学习的策略生成足够的样本。样本之间不共享计算过程,学习 ImageNet 数据集的增强策略需要 15,000 个 NVIDIA Tesla P100 GPU 小时,学习 CIFAR-10 需要 5,000 GPU 小时。举例来说,如果使用谷歌云的 P100 GPU 按需服务,学习 CIFAR 策略将花费大约 7,500 美元,而 ImageNet 策略需要 37,500 美元!因此在培训新数据集时,更常见的用例是使用公开发布的,展示出比较好效果的策略。

对图像应用基于群体的增强的效果,按照训练度百分比分类
基于群体的数据增强
伯克利团队提出的数据增强策略名为基于群体的增强(PBA),其在各种神经网络模型上实现的测试准确度与谷歌方案接近,但需要的计算量少了三个数量级。团队在 CIFAR-10 数据集上训练几个小型模型副本来学习增强策略,使用 NVIDIA Titan XP GPU 时只需要 5 个小时就能学成一个策略。之后迁移到大型模型体系和 CIFAR-100 数据集上从头开始训练时,该策略表现出了强大的性能。
与训练大型 CIFAR-10 网络需要花费的几天收敛时间相比,预先运行 PBA 的成本很低,却能显著改善结果。例如,在 CIFAR-10 上训练 PyramidNet 模型时,使用 NVIDIA V100 GPU 需要 7 天以上,而学习 PBA 策略只会增加 2%的预计算训练时间开销。对于 SVHN 来说这种开销甚至更低,少于 1%。
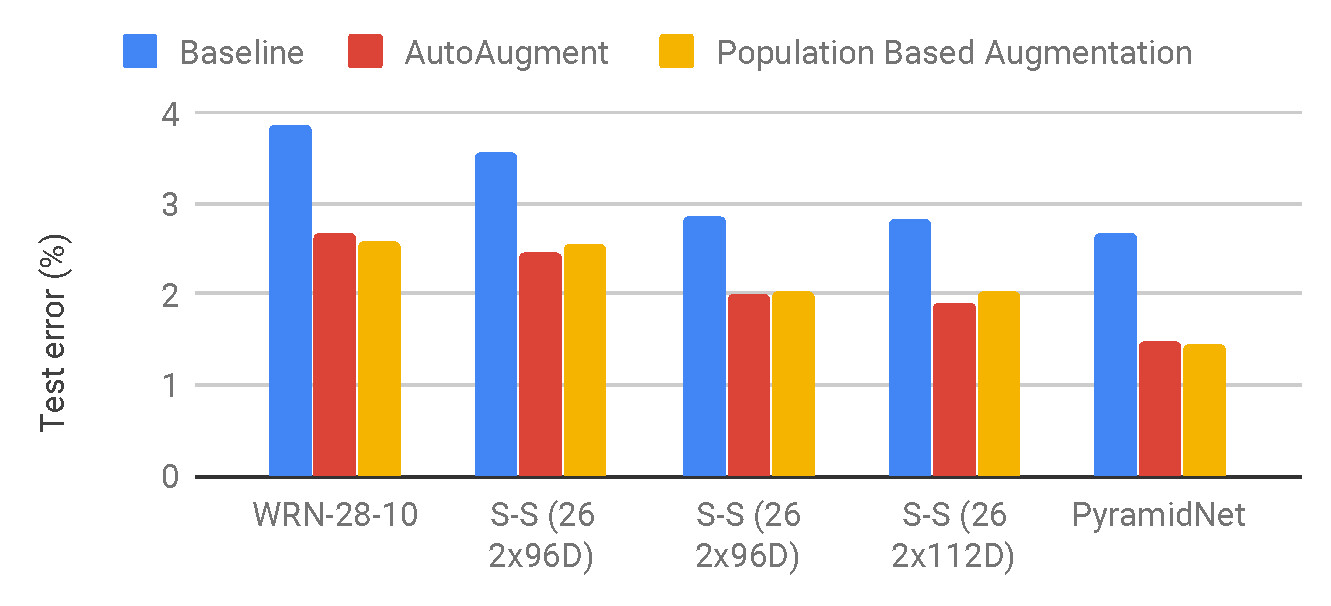
在 WideResNet、Shake-Shake 和 PyramidNet + ShakeDrop 模型中,PBA、AutoAugment 和仅使用水平翻转,填充和裁剪的基础策略之间的 CIFAR-10 测试错误对比。PBA 明显优于基础策略,与 AutoAugment 相当。
PBA 利用基于群体的训练算法(https://deepmind.com/blog/population-based-training-neural-networks/)来生成增强策略调度,该调度可以基于当前的训练 epoch 做调整。这与固定增强策略正好相反,后者对不同的 epoch 都使用相同的转换。
这样一来,单机工作站用户就可以很容易试验不同的搜索算法和增强操作。一个有意思的用例是引入新的增强操作,这些操作可能针对特定的数据集或图像模态,并能够快速生成定制的,高性能的增强调度。伯克利通过变量控制研究方法发现,学习的超参数和调度顺序都显著影响结果质量。
增强调度是怎样学习的?
伯克利团队使用 16 个小型 WideResNet 模型作为群体进行基于群体的训练。群体中的每个 worker 都将学习自己的候选超参数调度。之后团队用性能最佳的调度迁移到大型模型上开始从头训练,从中得出测试误差指标。
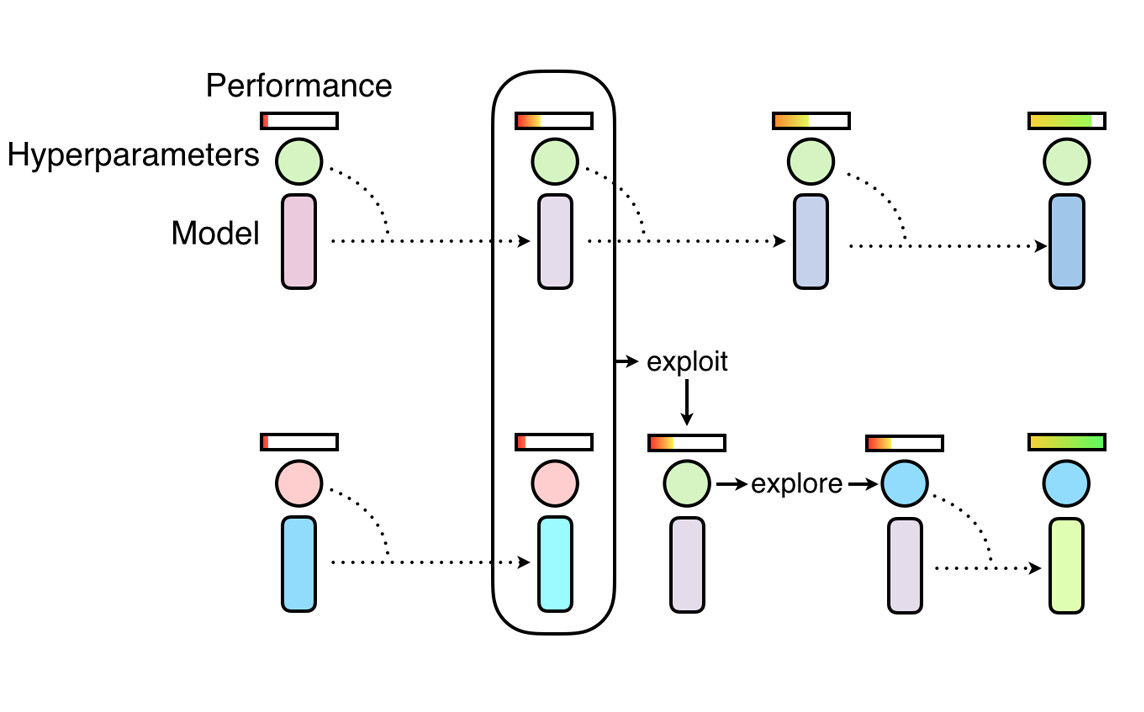
基于群体的训练框架。通过训练一群神经网络来找出超参数调度。它结合了随机搜索(发现)和复制高性能的 worker 模型权重(利用)两种手段。
群体模型在目标数据集上训练时,一开始所有的增强超参数都设置为 0(未应用增强)。“利用和发现”过程会频繁将高绩效 worker 的模型权重复制到低绩效 worker 来“利用”前者,然后扰乱 worker 的超参数来“探索”。这个过程能够在 worker 之间共享大量计算过程,并针对不同的训练区域使用不同的增强超参数。因此,PBA 用不着训练几千个模型才收敛,用很少的计算量就能获得很高的性能。
示例和代码
利用 Tune 内置的 PBT 实现就可以直接使用 PBA 了。
这里用自定义探索函数调用 Tune 的 PBT 实现。这将创建 16 个 WideResNet 模型的副本并同时训练它们。每个副本使用的策略调度都会保存到磁盘,并可在训练结束后迁移到新模型训练中。
可以参考这里的说明(https://github.com/arcelien/pba)运行PBA。在Titan XP 上,只需要一个小时即可学到 SVHN 数据集上的高性能增强策略调度。在自定义数据集上也可以轻松使用 PBA:只需定义一个新的 dataloader 即可。


腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论