

数据已成为推动企业、行业、产业发展的巨大推动力。作为“数据价值提炼者”,数据平台是企业数据体系的关键一环,帮助企业优化数据管理、提供数据分析决策建议,更快实现数据资产化。
从互联网到云再到大模型,一波波技术创新浪潮背后是指数级上涨的数据量,让企业在构建数据平台时需要投入更多的人力成本、时间成本和财务成本,才能跟上业务发展的需求。然而,数据平台架构复杂度高、人力成本高,让企业数据价值最大化、数字化转型进程遇到了瓶颈。数据平台如何降低使用技术门槛、降低企业运营成本,加速数据分析创造更大数据价值是平台从业者面临的核心问题。
7 月 20 日,云器科技举行首次对外的产品发布会,首次推出新一代“多云、一体化”的数据平台云器 Lakehouse,提出增量计算新范式,并基于增量计算构建 “Single-Engine”一体化平台,在湖仓架构之上,实现批、流、交互三种分析模式的统一。为企业提供开箱即用、高性能、低成本的数据平台,帮助企业真正让数据变为生产力,向科技型数字化企业转型。InfoQ 作为战略合作媒体支持了本次发布会的落地。
随着技术不断成熟,一体化、更简单、免运维的商业化数据平台服务已成为企业的主流选择。海外大数据行业的代表企业之一,Snowflake 既是以多云独立、一体化的数据平台和 SaaS 化的业务模式在全球广受认可。由于技术生态、用户生态和市场环境的差异性,国内关于“中国版 Snowflake”的呼声一直存在,云器 Lakehouse 希望成为“中国版 Snowflake”,面向企业需求,以多云独立的一体化 SaaS 化服务,填补国内市场的空白。

云器科技创始人 &CEO 喻思成表示:“多云、一体化是数据架构演进的必然方向。普惠、极致简单、极致弹性的数据平台是当下企业的共性需求。云器科技以‘改变数据的使用方式’为使命,聚集了业内专家成员,历时两年推出完全自主研发的云器 Lakehouse,帮助企业级数字原生客户更灵活、更高效、更安全、更经济地发挥数据的价值。”
打破 Lambda 架构,Single-Engine 统一“离线、实时和交互分析”
大数据的快速发展根源于以 Hadoop 为核心的开源技术。行业早期,因技术生态还未足够成熟,企业往往选择组合不同的开源组件自建数据平台,通常使用 Lambda 架构。
但是,组装式 Lambda 架构一直存在 四大问题亟待解决:
第一,不同组件开发语言不通,带来较高开发门槛,对开发人员不够友好;
第二,多组件,多套元数据,带来大量的计算和存储冗余;
第三,多组件架构复杂,带来极高的运维成本;
第四,缺乏满足业务变化的灵活性。
这些问题困扰业界多年,很多产品和企业也尝试解决这些问题。由于流处理和批处理的计算模型、数据驱动方式以及存储系统设计均不同;批处理和交互分析的计算模型、存储模型、调度模型、资源模型也不同。因此,企业想要统一离线、实时和交互分析变得尤为困难。

基于增量计算新范式的 Single-Engine 数据平台统一流、批、交互三种计算模式
云器科技联合创始人兼 CTO 关涛表示:由于流、批、交互三种计算引擎的计算模型、数据驱动方式、存储系统设计、调度系统设计、资源模型等均不相同。他们都很难覆盖另外两个场景。统一三种计算模式,需要一个新的计算范式,我们提出‘增量计算’。

增量计算指的是将所有计算抽象成增量的形态,实现数据的一次计算、累次使用,节省计算资源同时,能提供灵活调整的“增量时间间隔”,达成批处理或者流处理效果的服务。
“如果将增量时间间隔调整为 0,数据平台将提供实时计算;如果调多增量时间间隔,数据平台将实现离线批处理。”关涛解释道。企业不再需要使用单独的流式开发语言编写增量处理的复杂业务逻辑,复用离线数据加工的处理逻辑即可构建实时任务。
新范式平衡“数据不可能三角”,将控制权交回给企业自己
云器科技联合创始人兼 CTO 关涛表示:”Single-Engine 的核心使用‘增量计算’的新计算范式,在数据新鲜度、查询性能和成本的‘数据不可能三角’上支持多种平衡点,做到了把平衡的控制权交回给企业自己。”
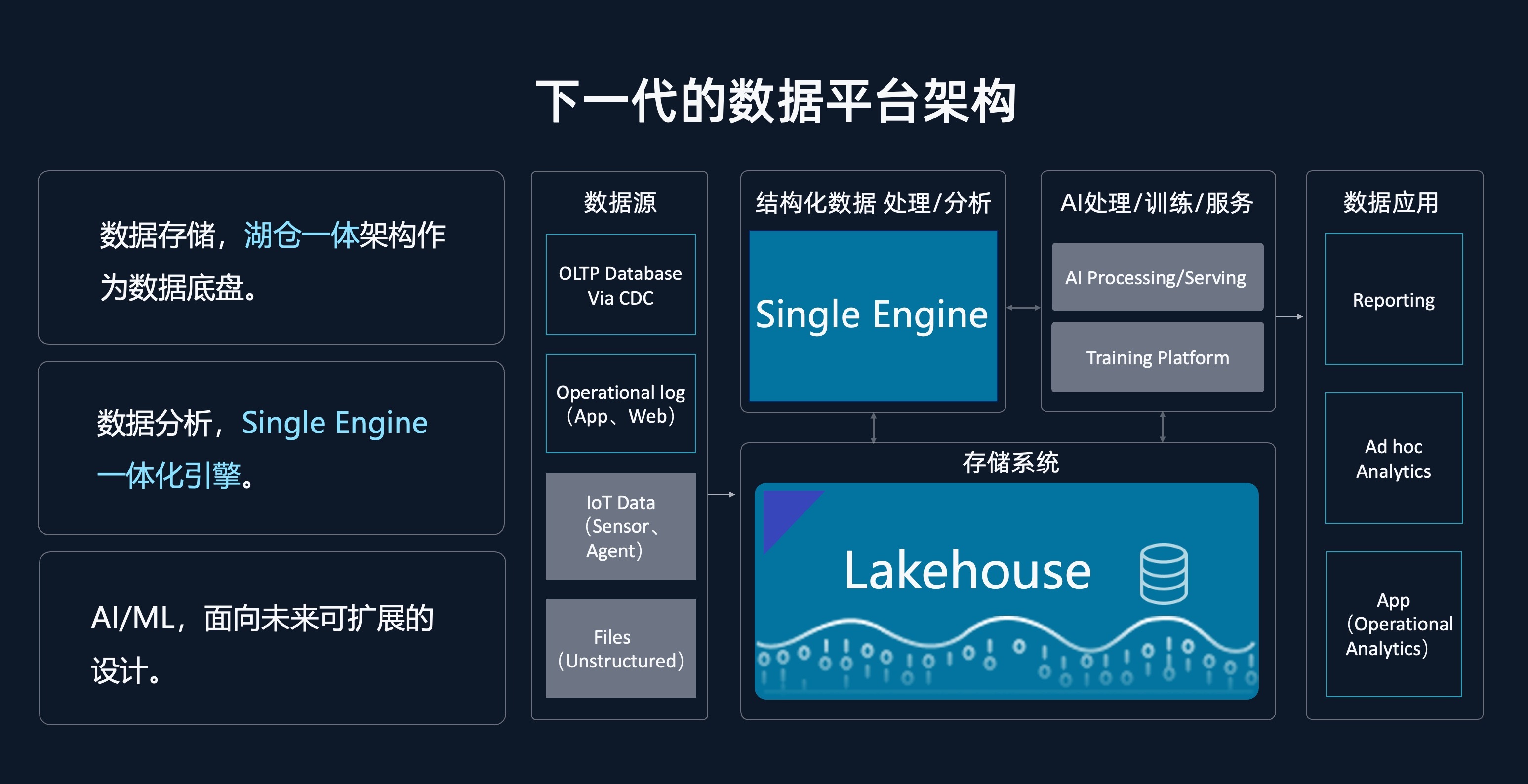
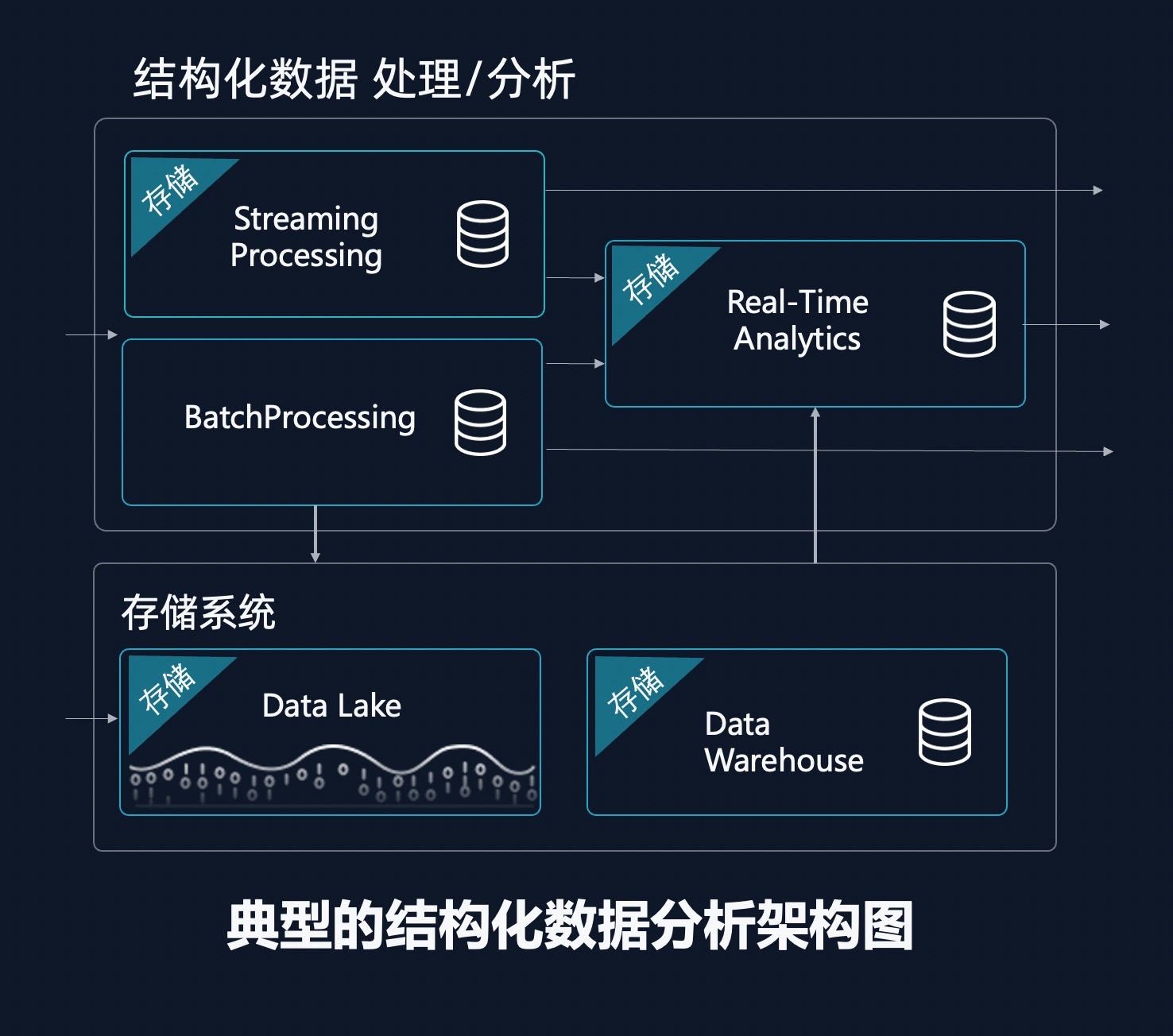
同时,在云器 Lakehouse 数据架构中,底层的湖仓平台真正实现了数据湖和数据仓库的融合(湖仓一体),所有的结构化、非结构化数据统一存储在湖仓架构中,只存一份数据;同时为了支持上层增量计算形态,云器在 Lakehouse 基础上实现了增量存储能力,最终数据底盘实现为“具备增量存储能力的 Lakehouse”。
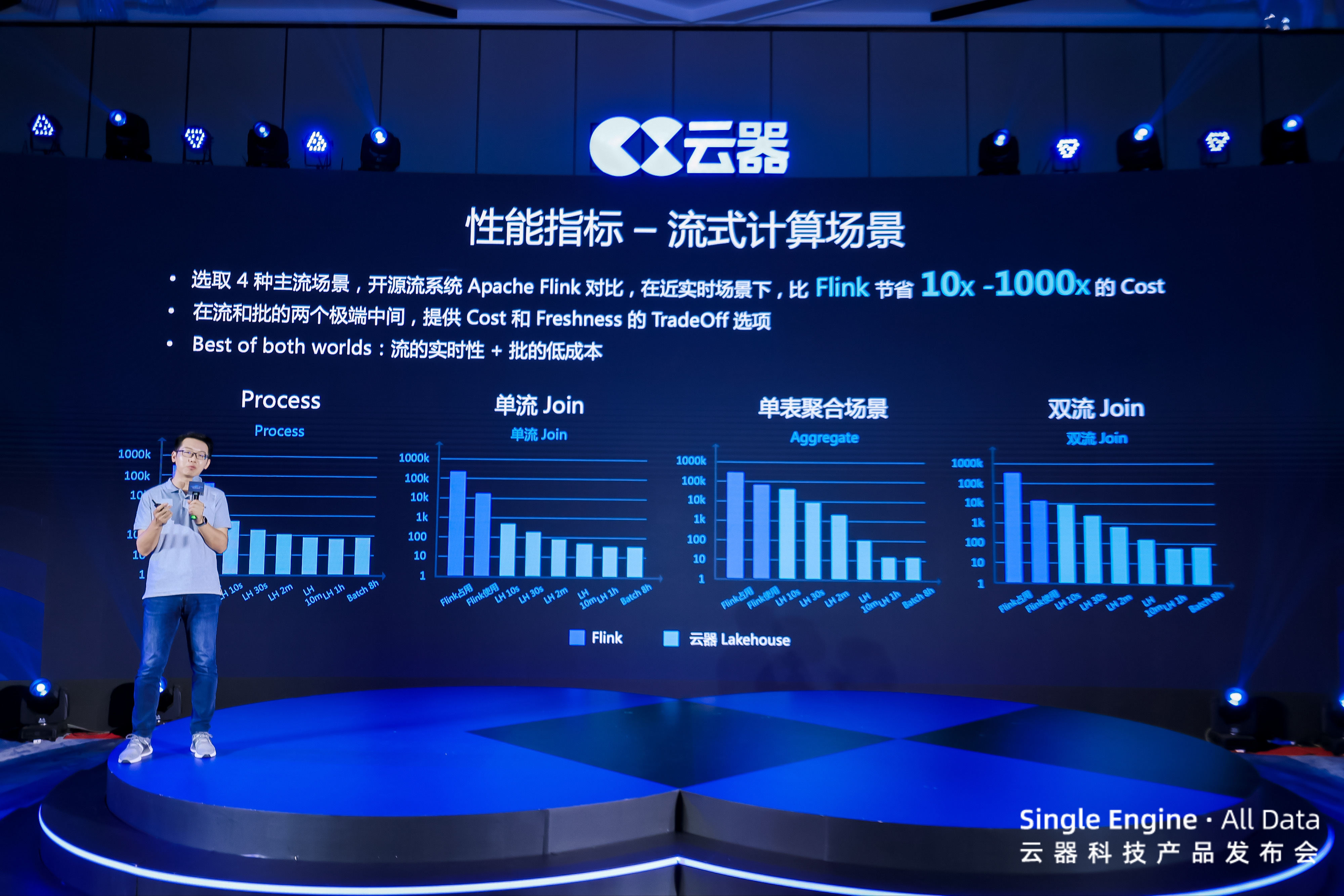
云器 Lakehouse 的 Single-Engine 核心引擎已经展现了卓越的性能。

在批处理和实时分析场景上,云器 Lakehouse 在多种标准 benchmark 上比主流开源和商业产品快 3-9 倍。
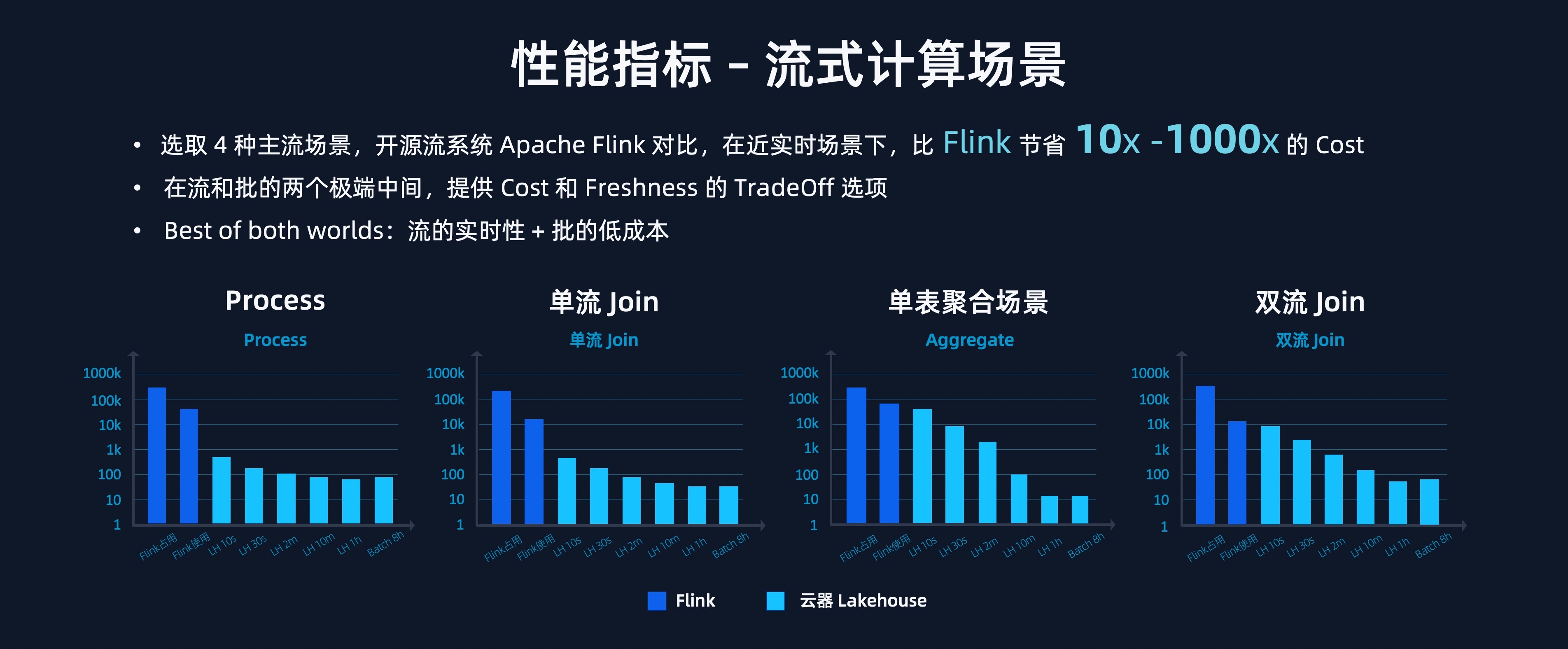
流式计算方面,在 Process、Aggregate、单流 Join 和双流 Join 四种主流场景下,云器 Lakehouse 相比开源流系统 Apache Flink 做到了更灵活的调节能力,并在近实时场景下,比 Flink 有 10 倍—1000 倍的成本节省。
多云、一体化的数据平台帮助企业做到数据使用更简单

云器 Lakehouse 在湖仓一体和 Single-Engine 的基础上,基于弹性虚拟计算(Virtual Cluster)支持离在线的一体化分析,可以实现开箱即用、秒级弹性资源、按量付费。
Single-Engine 一体化设计,发挥了一体化数据平台的“自适应”特性,可以按企业所需支持各阶段的企业级数据应用,替代多种开源组合技术组件,包括常见的 Spark/Presto/Flink/Clickhouse 的平替方案,对初创型企业非常友好。

云器科技联合创始人兼 CPO 七良表示:“一体化是共识的方向,云器选择了自研 Single-Engine 的方式,独特之处在于可以更好地帮助企业平衡:性能、成本、数据新鲜度。使得平台架构和使用更简单。”
一体化数据平台,帮助企业实现 BI 与 AI 共生

云器科技联合创始人兼 CPO 七良表示:“数据不仅仅只是为了 BI 分析。同一份数据能够同时服务于 BI+AI,实现 BI+AI 共生,是云器做 Lakehouse 产品的初心。”
以出行场景为例,出行导航的路况是利用历史路况信息(结构化的数据)+ 车辆轨迹点数据(实时半结构化数据)结合生成的。在车辆少、探测车辆行为异常的道路上,信息不准确的情况一旦出现,车企可以通过行业情报数据比如实时路况图片,通过 AI 模型分析这些非结构化数据,增强已有路况数据的准确性。
云器 Lakehouse 还集成优化了 AI 能力以优化数据链路和降低数据平台使用门槛。当前,行业内存在一个明显的痛点是用户建模和分析业务本身仍然非常复杂,现有的优化方案中依然有大量的人工工作,优化程度远远不够。
因此,在 AI 已经成为计算领域一等公民的今天,云器科技探索推动一个 AI4D(AI for Data)的新方向,通过平台自主学习数据和负载的特性,做基于算法和 AI 的自动化调整,来满足多变的业务需求,让每一位企业人员都能低门槛使用数据平台。AI4D (AI for Data)指的是基于 Learning based 方法和 AI 算法的平台优化方向。

关涛认为:“数据平台能否支持好 AI、并利用好 AI,已经成为衡量新一代数据平台的新标准。”
如今,云器 Lakehouse AI4D 已经实现:打破基于专家经验的优化,利用数据分析,机器学习和 AI 算法优化数据平台;在数据建模场景上,通过 AI“学习”整条 pipeline 和一段时间的历史查询情况,实现自动 MV 抽取,自动预计算,自动性能 / 成本的平衡。
云器使用 AI4D 技术,在标准数据集测试得到了 ~16% 的总资源节省,如通过 MV 转预计算,查询时提升 30%~ 4 倍的性能收益。
在实际客户的数据集中,测试达到了 40% 的资源消耗降低和预计 3 倍的查询性能提升。
云器 Lakehouse 使用体验

星盘起航技术总监欧振聪表示:“作为一家数据原生 SaaS 企业,可能会有人奇怪为什么我们会选择和云器合作。实际上,作为一家初创企业,我们需要根据业务的快节奏灵活、及时调整数据架构,而云器 Lakehouse 一体化数据平台,让我们不必根据不同业务需求比对、整合多家技术产品,很大程度上节省了我们的精力和成本。此外,云器团队高度响应我们业务需求,让我们有限的人员完全投入到业务中。”

作为一家 SaaS 企业的前端技术 & 新技术总监,刘冠邦表示:“云器 Lakehouse 的 AI4D 的能力,可以自动把这历史任务中的大量相同的计算子集优化成共用的 mv,并在之后的任务中直接通过 mv 来获取结果,不再运算每一个 query,最终实现了 2.1 倍 CPU 消耗成本的降低和 5.9 倍的平均任务延迟的缩短,大幅度加速了计算过程并降低了成本消耗,提高了我们公司整体业务流转的效率。”
Single Engine · All Data
“在购买和自建中一旦选择自建,客户的要求必定是用最简单的方式做交付,这是商品化世界的规律。所以我们要 Single Engine · All Data,把复杂留给云器,把简单留给客户。”云器科技创始人 &CEO 喻思成强调。
发布会最后,喻思成宣布云器 Lakehouse 产品试用申请通道正式开启,欢迎企业前往云器科技官网( https://www.yunqi.tech)提交使用申请。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论