

AutoDL 是人工智能中一个极其重要的分支,旨在让人工智能自己去设计模型,通俗来说就是让机器去造机器,如果发展得好,很多模型都可以自动设置,虽然这项技术现在还在发展中,但是已经有很多地方的应用。本期北大 AI 公开课请到了百度大数据实验室主任浣军教授,他将带来 AutoDL 技术的介绍和百度在这项技术上的最新进展。

课程导师:雷鸣, 天使投资人,百度创始七剑客之一,酷我音乐创始人,北大信科人工智能创新中心主任,2000 年获得北京大学计算机硕士学位,2005 年获得斯坦福商学院 MBA 学位。

特邀讲师:浣军,现任百度科学家、百度大数据实验室主任。 历任美国堪萨斯大学电子工程和计算机系 Spahr 讲席终身职正教授、博士生导师。2016-2018 年任职于美国国家科学基金委,任大数据方向学科主任。
北大 AI 公开课第十二讲回顾:阿里达摩院施尧耘:量子计算的潜力和挑战
以下为 AI 前线独家整理的课程内容(略有删减)
非常高兴,也非常荣幸接受雷鸣的邀请来北大跟大家交流,我们目前正在做的是 AutoDL,我们希望能够让天下没有难建的模型。在一开始,我先给大家简单介绍一下百度大脑的 AI 技术。
百度大脑的 AI 布局
在感知层,我们有语音、视觉、增强现实等;在认知层有对语言的梳理,语言是人类自己开发的一种工具;在认知层上面有平台层。
语音识别作为人工智能非常重要的一个方面,它的技术路线经历了从深度神经网络到 LSTM、再到流式的基于注意力机制的对每一个音素进行的识别。说到语音,除了识别还有合成。合成是根据声音进行建模,并更进一步的增加实时性,然后在此基础上把语音一体化。比如大家可能比较熟悉的智能音箱,不管是各个公司,从 Google、Amazon,到国内的 BAT,都在上边发力。
我们现在看一个具体的百度输入法关于中英文混说的视频,这是我们语音总监用东北话演绎的一段中英文混合,它的识别在中英文之间切换是非常新的,因为它在音素级别进行建模。
另外,人工智能涵盖了许多其它重要的技术,例如图像处理、物体检测识别、文字识别、OCR、视频的理解等。我们再看一个照片,这张照片中人的表情、唇型、身影等都是合成出来的,并且人也是合成出来的。
人工智能中非常重要的就是语言和知识,语言是人类创造出来的交互工具,包含分词、句法、对语义、篇章的了解,包括生成。这里面有很重要的知识图谱,来帮助对实体和实体之间的关系进行建模。从搜索来说,搜索公司因为有了知识图谱,并且是比较完整的知识图谱,所以可以对实体之间的关系进行更好的建模。比如百度有亿级的,十亿级和千亿级的关系,以及相关的行业知识、POI 的描述、对事件的建模关注点,当然也包括沃尔森文本文件等信息,这些信息可以很好的帮助建模。
比如,原始文档中患者自述出现了什么症状,经过自然语言梳理、结构化之后,就有了它的属性。比如症状包括发热咳嗽,检查进行了常规和胸部 X 射线,诊断是重症肺炎,这就把无结构化的数据变成了结构化的数据,有利于医生诊断和电子医疗病历自动化诊断。还有一个例子,我们想知道胡歌演的古装剧有哪些?古装剧从端的角度是非常细粒度的概念,你可以把东西放大,从古装剧变成电视剧,然后主角是胡歌,动词是语言,经过这样我们就知道胡歌主要演的古装戏有多少个。
可能大家都听过 Bert,然后百度做了一个 Ernie。中文写作 ,它自动能够填进去这些东西。一些头条或者是百家号上的新闻都是由机器自动写成的,尤其是体育和财经这类非常具有结构化的领域。关于机器翻译,现在给它看一张图片就能理解关系。有些需求理解、智能问答,综合起来形成多模态的语义理解。从看见到看清,从听见到听懂,从能够读到读懂,最后综合跨模态地对语义进行理解。再配合上知识图谱,对视频就有更好的理解。
百度大脑已经开放,里边有语音、人体、人脸、OCR、内容审核、视频处理,自然语言处理等。它还配有开源的框架,有多少同学用过深度学习平台飞桨(PaddlePaddle )?飞桨是美国以外的主流全面的深度学习开源平台,是下面重点介绍的内容。举一个例子,在无人机上面装载一个摄像头,摄像头后面跟着芯片,来运行飞桨,然后它做什么?就是实时检测病虫害的种类和密度,来决定打药的多少,这块田病虫害发生得少,打的药就少,这样一来节省成本,二来降低环境的污染。接下来我们再看最后一个视频,这也是人工智能的一个实际应用。通过这些例子,我想说的就是人工智能正在成为时代的核心驱动力,在改变我们的社会,也在走进每个人的生活,它不再是 Paper 上的技术,也不再是象牙塔内的技术,它正在走向千家万户。
AutoDL:自动化深度学习及其安全性
现在我们就进入到第二个部分,就是 AutoDL: Automated Deep Learning and Its Safety。为什么要讲 AutoDL 呢?大家看到人工智能已经有那么长时间的应用,那么这些模型是如何训练出来的?
SGD 也就是 Stochastic Gradient Descent ,它还有个别名,叫 GSD,就是 Graduate Student Descent,这是什么意思呢?这其实是一个玩笑,说模型需要调参,调参听起来是实习生的事情,但这说明什么呢?这说明人工智能是人工加智能。另外,三大驱动力是大数据、大算力、大模式。大数据需要收集,整合,清洗,做数据分析能够知道,数据预处理最花时间,然后建模的时候,模型结构谁来给你设计?要么请人设计,要么自己设计,模型结构定了以后超参数怎么办?手工调。这无疑需要耗费大量的时间和精力。所以最近百度提出来:人工智能要走向工业化大数据,建模过程要告别手工作坊,要走向工业化大生产,走进模块化、标准化、制度化。我们要人工智能来设计人工智能,降低工程师的劳动成本。
下面介绍一下百度大数据实验室,它建立的时间比较早,是 2014 年由百度与联合国共建的。最早研究时空大数据,尤其是物种迁移。一直到 2017 年主要在研究大数据能做什么?从 2018 年开始,我们最关注的是没有大数据你能做什么?第一阶段我们关注大数据能做什么,第二阶段我们关注没有大数据能做什么?我们的目标就是没大数据也要建立功能强大的模型。
这听起来不太可能,我们看一个例子,大家可能都比较熟悉,横轴是时间,纵轴是错误率,从 2012 年开始,错误率从百分之二十几到百分之十几。当 Deep Learning 出来时,可以看到一下子降了 10%,当时有人打电话说,Hinton 是不是能够事先知道 testing data?你是不是 cheat 了?Hinton 说我干了一辈子了,不能干这种事情。后来 2015 年错误率是 3.57%,为什么 3.57 得出来?人类专家先不说累不累,都是看一百万张图片,差不多是 5%的错误率,深度学习在感知层面是可以超过人类专家,但在认知层面还没有全面超过人类专家,大家要有一个基本的认识。认知层面包括推理逻辑这些,感知层面至少在图像分类上确实超过人类专家。
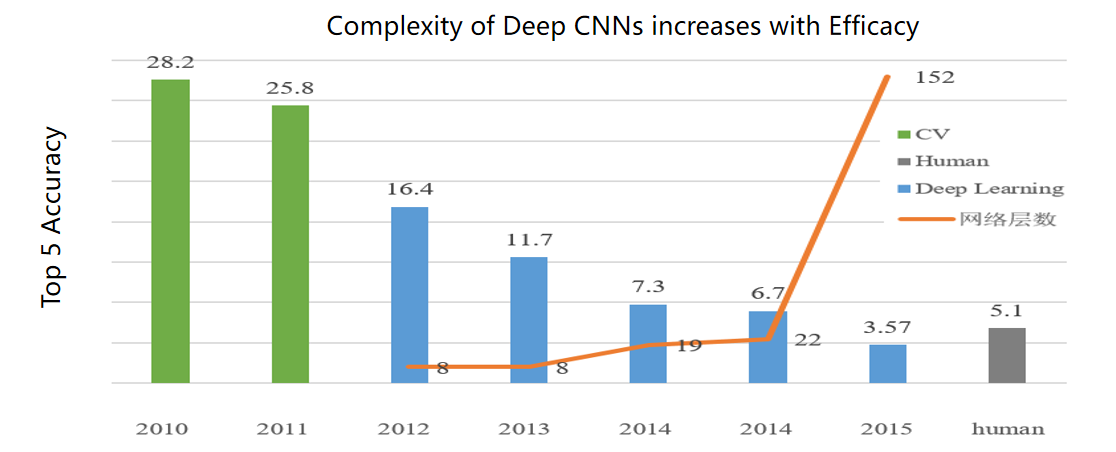
另一方面,从 2012 年开始,变化就很快了。
大家有了解过 Autohep 上的文章每多久翻一番?每多久与 AI 有关的文章翻一倍?有 18 个月,什么意思呢?我们研究生很辛苦地读文献,就算全部读完 AI 有史以来的文献,如果你不停止学习,18 个月后你就只读了一半的文献。当然人不可能把所有文献都流水式的读完。跟 AI 有关的算力是每 3.5 个月翻一倍。模型的层数是可以快速上升的,从几层到十几层,一直到上万层。
这意味着人工智能是人工加智能,需要大量的人工去设计这些模型,去调参,而且设计这些模型的人的训练成本是非常高的。比如百度招人,一百个面试者都跑过 AI 模型,有改过模型经验的只有十个,这十个人中间能够根据特定任务改模型还能告诉你道理的,可能只有两三个,也就是说专家的训练成本也很高。一个 PHD 平均五年,全美国加起来每年毕业的计算机博士生就是一千到两千,而且包括了计算机所有方向的,比如数据库体系结构、芯片、编程语言等。
现在 AI 火了,人数大概只有一半,也就是全美国每年毕业的博士生五百到一千在做人工智能。由此可见,从事人工智能的专业人员数量仍然较少。那么 AutoDL 的作用是什么呢?AutoDL 就是要让人工加智能这种模式走向自主人工智能,就是让深度学习设计自己,从而大大降低建模的成本,极大推进人工智能在各行各业的应用。总结起来就是一句话,开放普惠 AI。中小企业、个人初创企业等不同企业在不同的圈子内,他们可能没有大数据,没有大算力,也没有高质量的 AI 工程师,即使这样 AutoDL 也可以帮助他们建立高质量的模型。AutoDL 是在人工智能迈向工业化大生产之间的重要一环,任何一个东西在我们时代要想成功,它必然有个大规模生产的过程,即标准化、模块化、自动化。
AutoDL 重点解决的就是自动化和模块化,那么它主要有几个 Parts,分别是设计、迁移、适配。首先,设计是什么意思?就是我自动给你设计一个网络结构。我们先说设计和模型,在深度学习时代,模型包括两个方面:网络结构和网络参数。你拿网络结构,经过数据,通过调参得到一个具有参数的网络模型。
其次,迁移是什么?就是我说的,大厂用大数据去契合大模型,中小初创企业或者垂直行业的企业只需要少量的数据去跟随大模型就能达到很好的效果,不需要从头去训练,而且从头去训练的模型效果也很差。迁移学习就是没有大数据也能达到大数据要的效果。
最后,适配是什么意思?现在的模型建完以后一般在服务器端或云端,但是实际上,就像那个无人机想要打药,它把模型加载到一个特定的端上,端可以是一个边缘,也可以是一个特定计算单元,比如说自动驾驶它里面有计算单元。手机就是一个典型的端。实际上端有很多,尤其是视觉方面,比如一个摄像头加上后面的处理芯片。百度最近做了这个项目,一个摄像头加上芯片加上电池,总共成本不到 200 人民币,芯片上你可以载入一个图像分割的模型,你可以载入一个目标检测的模型,你也可以载入一个人脸识别的模型。即可以把训练好的模型部署到无穷无尽的不同的端上面去解决不同的问题和应用。
下面说几个相关的时间点。Google AutoML 是 2018 年的 1 月份提出的,百度 AutoDL1.0 是 2018 年的 7 月份提出的,微软的相关平台是 2018 年的 11 月份提出的,也就是说百度是在 Google 之后微软之前提出了 AutoDL 的平台。百度 2.0 是在 2018 年的 11 月提出的。现在有多个产品已经用上了 EasyDL,EasyDL 是一个免费的公益项目,它是一个免费的在线模型训练平台,提供少量数据就可以帮你构建模型,具有定制化能力而且很快。AI Studio 是一个深度学习的教育平台,如果大家缺乏算力的话可以去 AI Studio。Jarvis 是一个针对中大型企业的私有化部署,包括硬件、软件和自动建模服务,大概一台卖几百万。
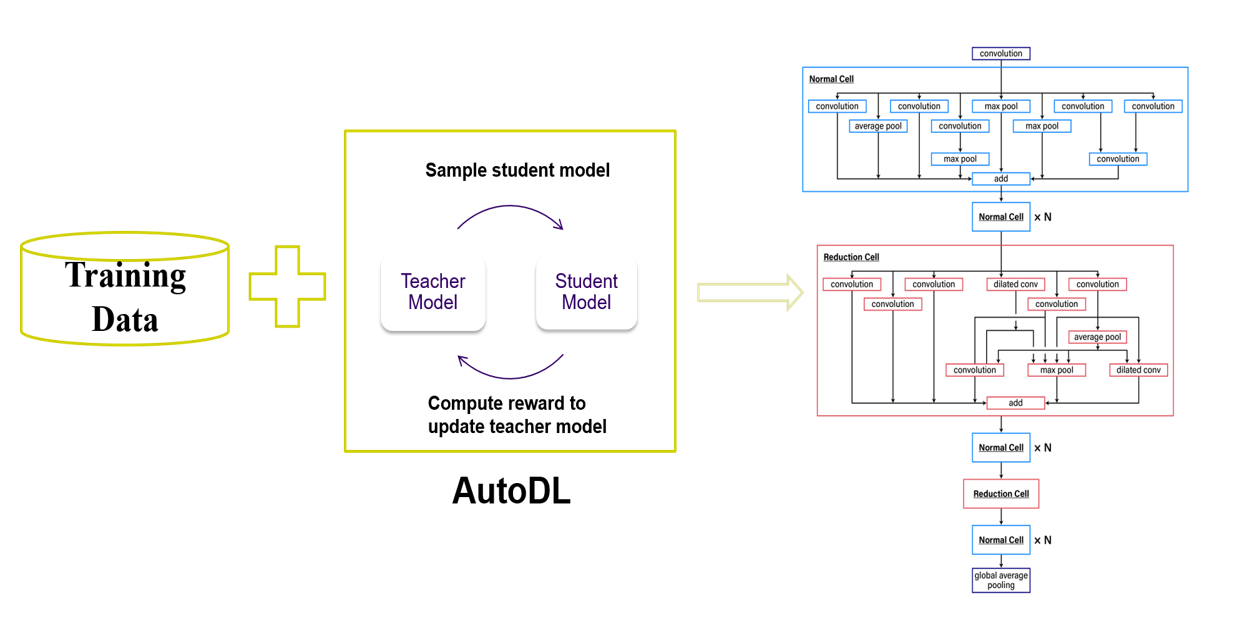
我们先看一下设计,如何设计一个网络?如果你要想设计一个 30 层的跟 VGG、ResNet 相似的网络,每一层大概允许十来种操作,你去选操作的组合就行,它有很多种组合。如果你要优化很大的 Search space,一种解决方案是通过编码器 Teacher Model 和测评器 student Model。编码器把一个网络模型用某种方式编码,测评器拿到网络模型就跑一下,得到中间结果,把中间结果作为奖励函数,反推给编码器,编码器通过特定方式来改进它的编码,就可以用一个简单的编码器同时设计出来十个网络交给不同的测评器去测评,测评以后得到效果并反馈给编码器,再改进。但是这个过程中间,有一个很重要的因素就是过拟合,因为深度学习本身如果层数多了以后就很容易过拟合,尤其模型是在一个大的空间搜出来的,那么为了防止过拟合有很多种所谓政策化的方法约束函数的复杂度,比如 Mix-up、Shake-shake,是非常有效的。我们做得叫 Rademacher,用来约束函数的复杂度。

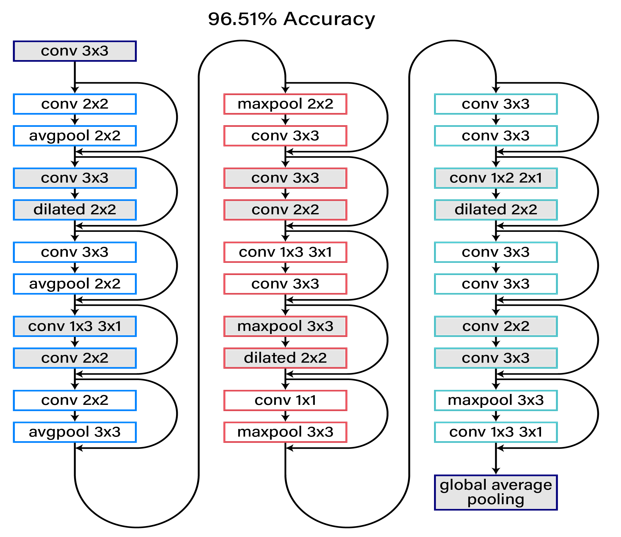
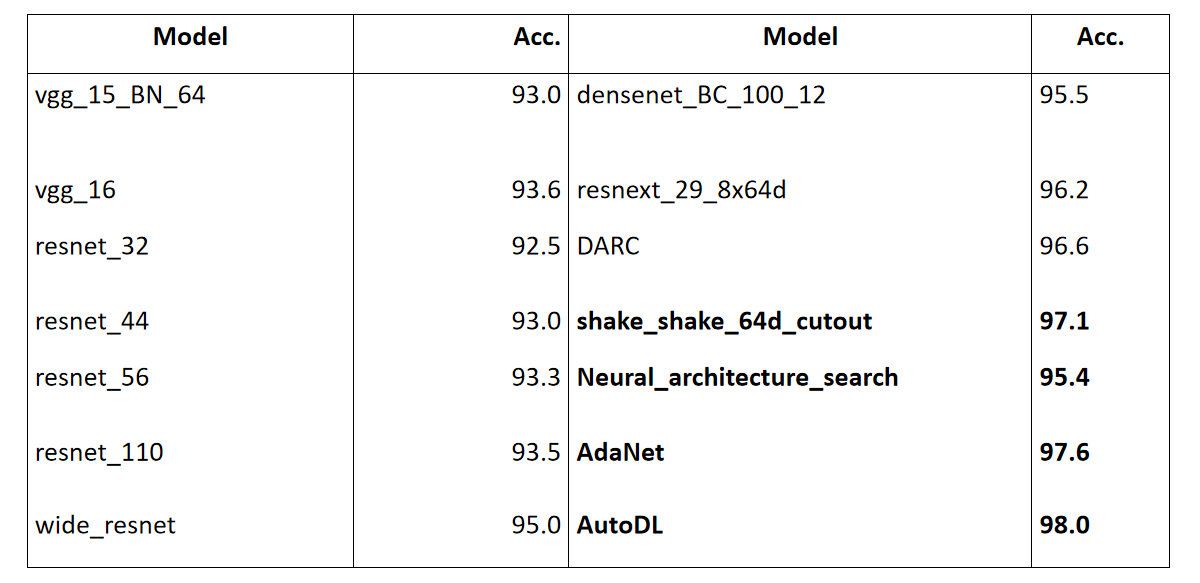
图 4 是一个搜索到的结构,大概是一个 30 层的网络,网络的每层都有具体搜出的操作,大概可以达到 96.5%的准确度,已经超过大部分的人类专家设计的网络。后来我们做进一步的改进。最新的结果就如图 5 所示,横向对应不同的网络结构,纵向对应它们的准确度,这里面有 VGG,ResNet, and DenseNet 等不同的网络结构。那么人类专家最好的准确度可以达到 97.1%,就是通过 shake_shake_64d_cutout 的方法,应该是在 ResNet 上得到的。Google 最早一版的准确度在百分之九十五点几,在去年的 AdaNet 进一步提高到 97.6%;AutoDL 现在最好的结果是第一版的 98.01%,错误率低于 2%,到现在仍保持最好的记录,也就是说我们基本上保持了 6 个月的准确性,可以跟 Google 正面竞争。
下面我跟大家汇报一下深度学习的迁移学习。
迁移学习主要的优势在于,用户只需要提供少量的数据,然后用大量的预训练好的模型,就能得到更好的结果。我们做的一个工作就是基于 Attention(注意力机制)提供一种策略化的方法,接下来谈一下它主要的 Insight。当你用大量的数据训练大模型的时候,比如说你用 ImageNet,有一千类的图像,训练一个模型,要用到一个新的任务上也许就只有十类,原来的模型很多 Channel 在新的模型上面没有用,就不会被 activate,那么这些没有被 activate 的 Channel 就可以重新来用,效果还是不错的。我们今年在 ICLR 发的文章,跟以前的方法比较起来,效果有比较明显的提升。
从另一个角度呢,你可以做 Auto-Reduction,到底图像中间的哪些部分对效果的影响最大,比如说图 6,我们的工作 Delta 发现影响最大的是狗头的部分。而其他的方法有些时候并没有聚焦到真正的对象上面,它也许是用一些背景相关信息来做预测。我们也通过 EasyDL(因为百度的 EasyDL 是个公益项目,给大家免费建模)试着提供了 8 个用户实际的案例,通过这些案例可以看出它实际上应用范围非常广,有家具风格的分类、鸟类的分类、疾病像牛皮癣的分类、车系的分类等等。事实上各类应用基于 AutoDL 来优化都能得到更好的效果,在所有的 Task 上平均提高 5%,所以现在服务的用户超过一万人,月调用量达到好几百万。

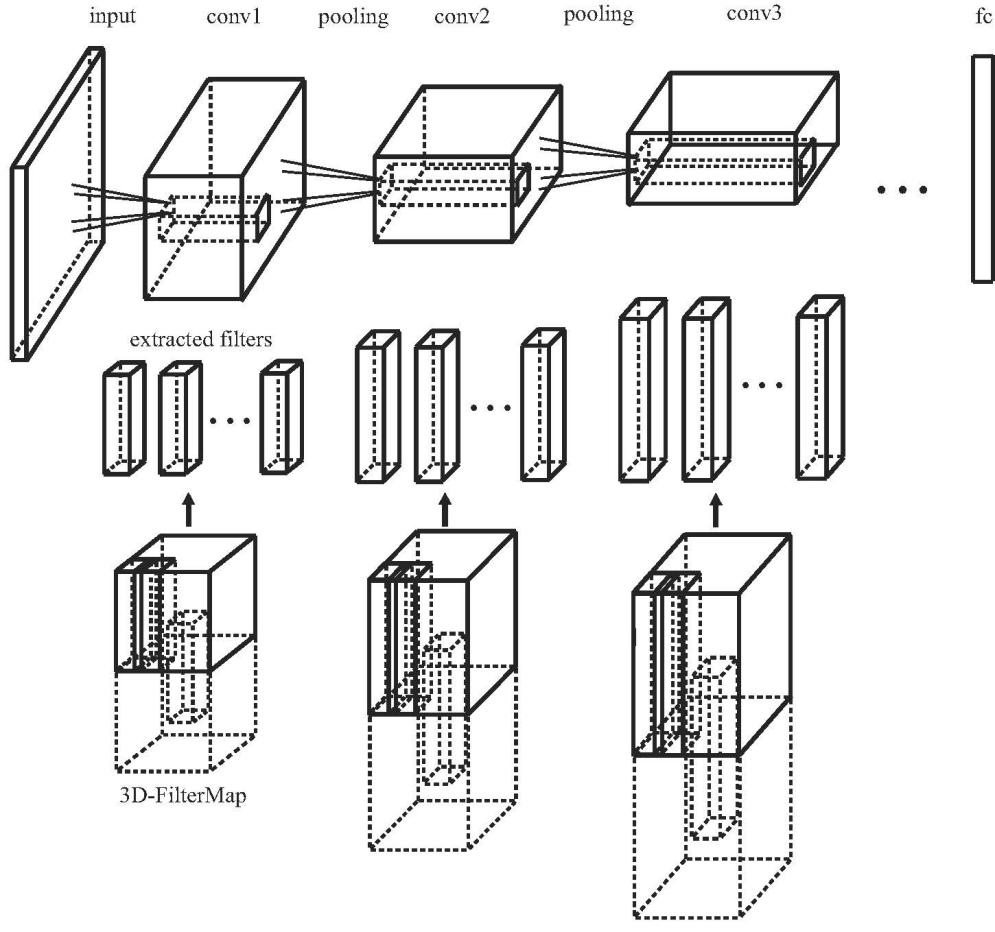
接着就是压缩,压缩现在进展非常快,你也可以做剪枝,可以做量化,可以做蒸馏等等。我们自己的方法叫 3D-Filtermap,就是说任何一个 CNN 的层都是一个 4d 的张面,如果能找到一个小的 dictionary,这样原来的那些 4d container 里面的每一个 factor 都是 dictionary 的线性组合,就会大大降低模型的大小。一般来说,可以降低能耗,提高效率。最近我们也用 Neural Architecture Search 来进一步优化压缩,提高压缩比,这里我们就看 ResNet 的一个例子。
ResNet-10 原始模型是 42 兆,正确率是 95.6%,压缩以后可以达到一点几兆,从几千万的参数到几百万的参数,模型的准确率几乎不变,压缩比大概是 30 倍。你甚至可以从几千万的参数压到十万的参数,那么模型的准确度也就跌了 1.5 个百分点,压缩率增加三百多倍。如果模型大小是 0.1 兆,基本上不管多么特殊的硬件都能装进去,那种非常小的芯片也能装进去。
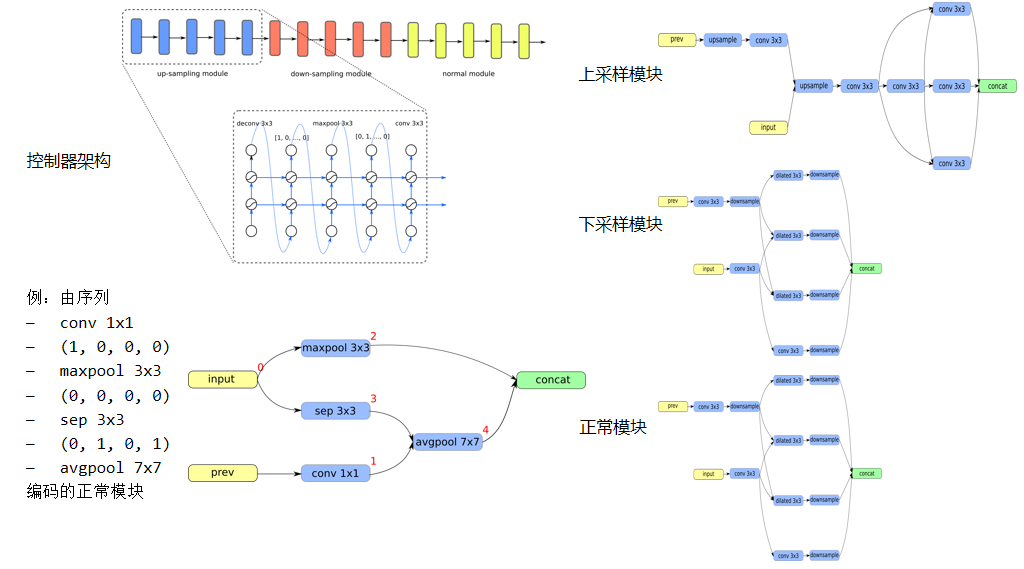
另外,如何用 NAS 做生成模型 (GAN)?从文献上来看,还没有看到任何相关的报道。我们的文章正在审,就是用 NAS 做生成模型的优化。生成模型包括生成器和判别器,生成器中间有一个从噪音到图像,噪音进,图像出,上采样的这么一个过程,那么你同样可以利用刚才说的自动搜索的办法来进行设计,比如它设计出来的上采样结构和已知的上采样结构是非常不一样的。
虽然 GAN 发展地非常快,但实际上我们梳理一下,它所有上采样部分基本上是两类,那么应该说生成模型设计出来了一个完全不同的上采样部分。效果的话, Inception Score 超过同等大小的其它类型的 GAN,超过了人类专家手工设计的效果。这里做了一下分析,发现上采样部分它用的主要是这种 3×3 的 conv,或者先过一个 1×3 的 conv,然后过一个 3×1 的 conv,下采样的部分采用 3×3 的 conv 和 dilated3×3 的 conv。dilated 就是说它取样的时候,中间隔了一个或者几个空。
然后还有一个叫做正常模块,它常用的操作跟其它的完全不一样,比如 avgpooling,或者 5×5 的卷积,那么这是 GAN 的一种生成模型。还有另外一种生成模型,它有一个 Autodecoder,有编码器和解码器。我们最近做 StyleNAS,就是用 Neural Architecture Search 做的风格迁移,即用 NAS 优化风格迁移?现在用的 Autodecoder 是这样做得,即通过层叠 VGG 来生成图像。先是下采样,然后再把 VGG 倒过来,最后是一个上采样的过程。它有一个特征抽取的过程,有一个图像生成的过程。里面每一步的计算开销都比较大。最后我们用 NAS 来解决这个问题,即用深度学习来设计这个深度学习模型。结果发现整个模型可以大大简化,VGG 是十多层的 VGG,搜完结果发现,这里用两三个操作,那里用三四个操作,就是把原来十几层的网络通过几层取代,效果几乎保持不变,时间大大缩短了。
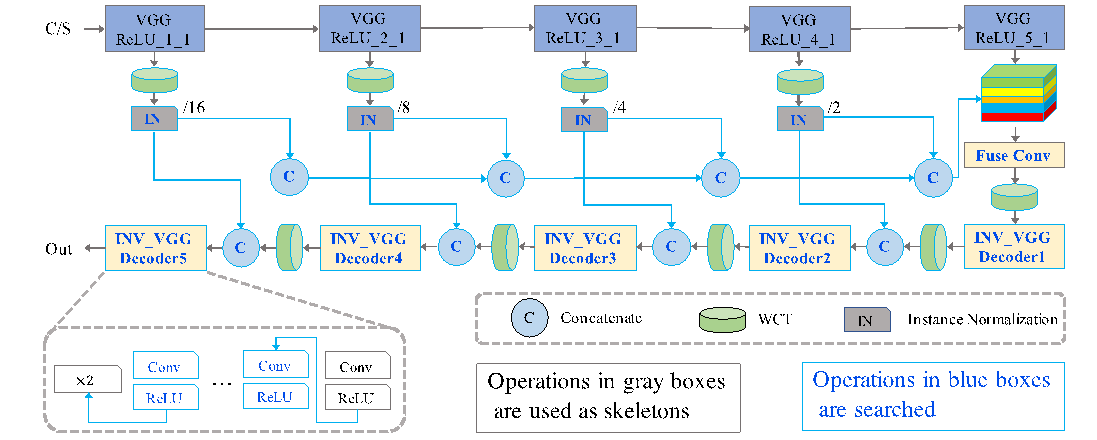
举个例子,图 10 包括内容和风格,也就是 content 和 Style。Photo WCT 是 2017 年研发的,它大约 60 几秒做出来一幅图片,这肯定是做不到实时的,在手机上谁也不会为了看到新的效果而等上一分多钟。那么用 NAS 优化 decoder,只用非常少的 Operation,用了 0.15 秒,图像细节保留的还更多。这里面迁移是什么意思呢?就是从春天的绿迁移到秋天的黄这么一个过程。然后也有一些量化的比较,比如说 FID,是越降越好,TVscore 是越升越好。通过深度学习设计深度学习,通过 Neural Architecture Search,就能简化所需要的操作,而且保持质量几乎不变,甚至于提高,同时大大降低计算量。

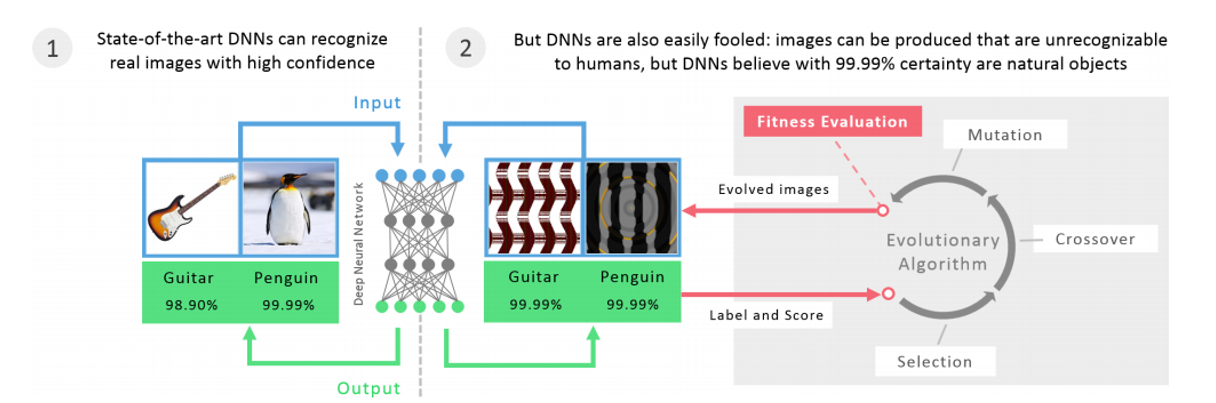
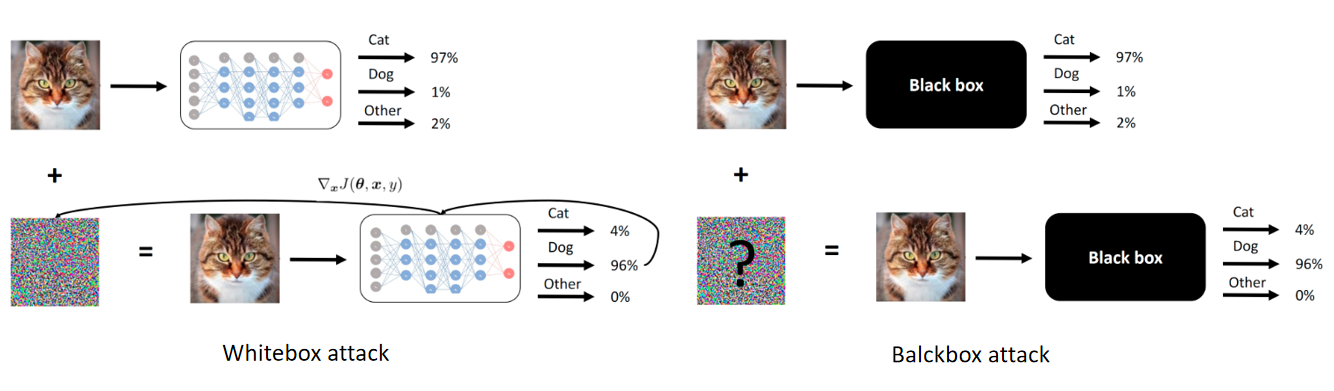
另外,非常重要的一部分就是关于安全。大家也都了解,深度学习的模型是很容易被欺骗的,比如说图 11,左边可以把吉他和企鹅识别出来,人和机器都能做这样的识别。右边就会骗过机器,它会认为这还是吉他和企鹅,你可能觉得很不可思议。
但是现在有大量的这种研究表明,在图片中间加一点点噪音就能够破坏计算机原来的识别,AutoDL 在这里面起到什么作用呢?先从白盒攻击和黑盒攻击说起。计算机视觉发展非常快,工业应用基本上不管是什么应用,图片分类,分割,各式各样的应用,很多时候它用的主干网络都是 Imagenet 预训练好的模型,意味着什么呢?从黑客的角度上来说,他知道网络的结构,也知道参数,还知道训练过程,他知道很多信息,那么这种情况下,就是一个白盒攻击,非常容易攻击,很容易欺骗你。
如果你用 AutoDL 设计网络,相当于千人千面,而且这种网络的企业结构是别人不知道的,它训练的方法是特殊的,它很有可能是 Imagenet 预训练好的,这就从白盒变成了黑盒,我们跟百度的安全实验室一起合作,也确实发现这样是能够大大的提高攻击的难度。
那么我想我跟大家汇报的内容就差不多是这样,做一个简短的总结吧。我们现在应该说还处在第四次工业革命的早期阶段,这一次的工业革命,中国从工业化、信息化、自动化走向智能化,智能化会对我们的社会生活产生巨大的影响。我在前半段给大家介绍了一下百度 AI 的一些进展,后半段我们讲了一下自动建模 AutoDL。AutoDL 的初心就是开放普惠 AI,大大降低建模的成本,使建模本身走向工业化大生产,走向标准化、模块化、自动化,这是一个宏伟的目标,需要很多人一起努力。那么大家有问题的话欢迎跟我联系,谢谢大家!
对话浣军
雷鸣:非常感谢浣军老师,讲的非常好。因为 AutoDL 概念相对于计算机视觉的大数据分析应该新一些,很多人没有真正的接触过,这也是在机器学习里面一个相对年轻的领域,但是逐渐的在发挥越来越重要的作用。刚才也举了几个例子,像网络的自动设计、迁移以及压缩,都有很多有意思的应用,那么我想展开一些探讨。大家有个问题,人工设计相对于人去设计网络,因为我们人花了很长时间,很多的脑细胞设计一个网络,自己设计网络显然是有代价的。你刚才讲到 VGG 视觉的网络。一个视觉的网络,我们用一个很大的数据训练它,用 GPU hour 概念去讨论一下,假如说一个 ResNet 在 ImageNet 训练一下,我要训练多久?比如我们就讲一个单位时间,我们叫一个 GPU hour,训练一个刚才说的 ResNet 模型,在经典数据集上,如果你用 AutoDL 训练一个跟 ResNet 相当的模型,会用多少 GPU hour?
浣军:雷老师问的问题很好。最早 Google 他们用 Neural Architecture Search 在 CIFAR10 数据集上做,用了几百块 GPU 跑了将近一个月。当时按普通方式训练一个模型大概是几个 GPU,NAS 却用了几百块 GPU 跑了 30 天。如果是 200 块 GPU 跑 30 天,就是 6000 个 GPU hour,多了几千倍。现在不管是算法,策略快速迭代,我们看到最新的结果都可以在一天内搜索到较好的结构。强化学习结合参数共享,或者用可微的方式来搜索能大大提高搜索的效率。
雷鸣:你是用搜索方法设计网络,设计出来它到底好不好,你是不是还得拿些数据来训练网络,训练出来了再测,然后证明它的效果。起码来讲,你至少得是“数次”单独训练模型,现在这个“数次”,假如说成 N,它有多大?几十?几百?
浣军:以前“数次”是几千,现在能做到 10 以内。我搜的时候,不是把模型训到头,而是训一步再回过去,把模型结构改一改,再训一步,再把模型改一改。
雷鸣:也就是说只实现搜索的感觉,往前走走,发现不对,效率不够,再退回来试别的,而不是一条路走到黑,到尽头再从零做一遍。另外,AutoDL 最后搜出来一个模型,我们就以模型设计为例子,那它的初始模型是谁?是一个全链接网络吗?到底从什么模型开始的?
浣军:这里有几种模式。第一种就是说,结构大体上已经安排好了,就像一个 ResNet,它有 15 层或者 20 层,每一层都有不同的操作,可以是 3×3,也可以是 5×5,skip connection 可以 I 和 I 加 3 之间,或者和 I 加 4 之间,不一定是 I 和 I 加 2 之间,这样就是宏观搜索,这种情况下大体上的结构是知道的。第二种,它有一个叫做模块的概念,搜出来的不是一个 30 层的整个网络,而是一个模块,然后把多个搜索到的模块拼接起来,得到最终的结构。这样它对模块也需要模板,比如说是一个 7 个结点的模块。有这么一个模板,在模板上进行优化,优化完了以后,得到一个模块的结果,再把多个模块拼起来,得到最终的结果。第三种就比较小众一点,就是从 ResNet 开始,进行局部修改,比如将某一层 split 成两层,或者把两层合并成一层,或者把一层的操作换掉,通过这种操作逐渐得到一个比较优化的结果。
雷鸣:我大体上感觉一下,第一种就是说,它一开始还是有一个基础结构的,并不是从荒地里开始的。它已经有一个比如说 ResNet 经典结构,或者是初始的,但是初始的结构,你不训它,听起来也可以把很多问题解决,但是可能不好,之后开始一些优化的道路,第一种听起来像模型上,但具体还是不太清楚;第二种是模板化,比如说我们弄一个汽车,我换个发动机试试,换模块试试,它是模块化的替换;第三种相当于这汽车买回来之后,你看着哪不顺眼换掉,或者把轮胎换掉,或再加点机油什么的,一些局部的细化,那第一种具体是什么?
浣军:第一种,比如说车,首先有个大体上的框架,车必须要有这么几个部件,每一个部件都有几种选择,比如说发动机有五种选择,轮子有三种选择,门有四种选择,然后我就往里面填东西,看看东西的组合,但大框架是定下来的。一和二的差别,二里边车可能不是一个特别好的例子,因为车里面没有一个可重复的东西,比如说一列货车,它的车厢有一定的重复性,一个车厢是用运煤的,另一个车厢是运油的,根据特点再进行组合。
学习资料
点击这里,即可观看本期公开课视频。
在 AI 前线微信公众号(ID:ai-front)后台回复关键词“北大 AI 公开课”,可获取往期课程文字材料 + 视频回顾等学习资料。


中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论