

针对日益远程化世界的高效大数据解决方案
Pinterest 拥有超过 3000 亿的 Pins,而这一数字背后是一个不断增长的独特数据集,通过数据映射无数人的兴趣、想法和意图。作为一家数据驱动的公司,Pinterest 使用数据洞察和分析技术来做出产品决策和评估,为超过 4.5 亿的月活用户改善 Pinner 的体验。为了持续做出这些改进,尤其是在今天这个日益远程化的世界中,与过去相比,团队更需要进行查询、创建分析并彼此高效协作。今天我们正在使用 Querybook,这是我们实现更高效、更协作的大数据访问的解决方案,我们还在向社区开源这一项目。
无论在 Pinterest 上发起任何分析,一个常见起点是可以在 SparkSQL、Hive、Presto 集群或任何 Sqlalchemy 兼容引擎上执行的即席查询。我们构建了 Querybook 来为此类分析提供一个响应快速且简单的 WebUI,以便数据科学家、产品经理和工程师发现正确的数据、构建他们的查询并分享他们的成果。在本文中,我们将讨论构建 Querybook 的动机,其特性、架构以及我们将项目开源的工作。
旅程
创建 Querybook 的提议始于 2017 年,它一开始是一个内部项目。在那时,我们使用的是一个供应商提供的 Web 应用程序作为查询 UI。用户经常抱怨该工具的 UI、速度和稳定性、缺乏可视化、难以分享等缺陷。不久之后,我们意识到人们非常需要一个更好的查询界面。
在确定技术细节时,我们开始采访数据科学家和工程师,咨询他们的工作流程的细节。不久,我们意识到大多数人是在官方工具之外组织他们的查询,很多人使用 Evernote 之类的应用。虽然 Jupyter 有自己的笔记本用户体验,但它需要使用 Python/R,而且它缺乏表元数据集成的问题劝退了很多用户。基于这一发现,我们的团队决定 Querybook 的查询界面将是一个文档,用户可以在该文档中通过搭配元数据和一个简单的笔记应用,一站式完成查询构建和编写分析任务。
Querybook 于 2018 年 3 月在内部发布,成为了 Pinterest 上查询大数据的官方解决方案。如今,Querybook 平均有 500DAU 和 7k 的每日查询运行。它的内部用户评级为 8.1/10,是 Pinterest 内部评级最高的工具之一。
特性亮点
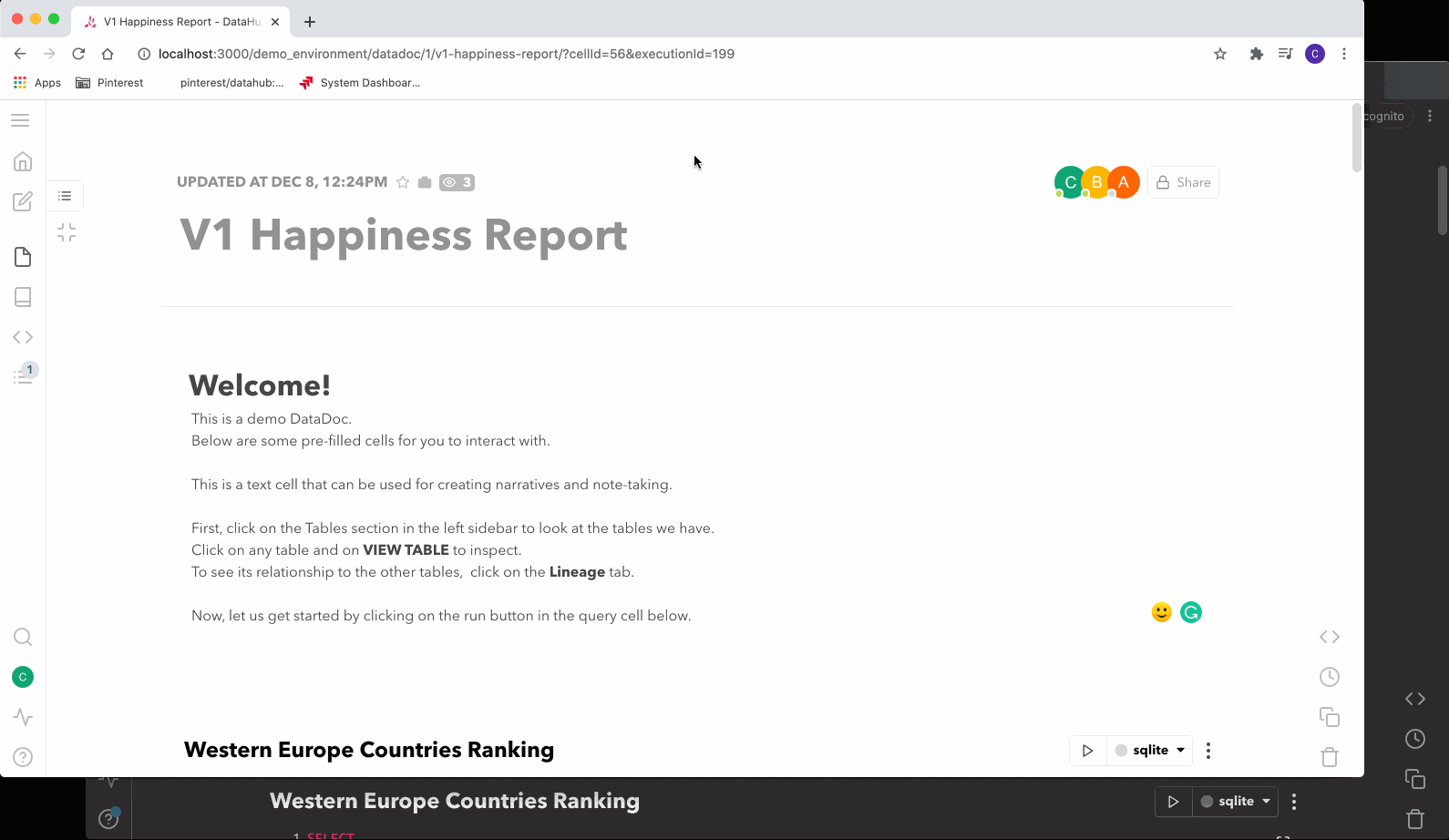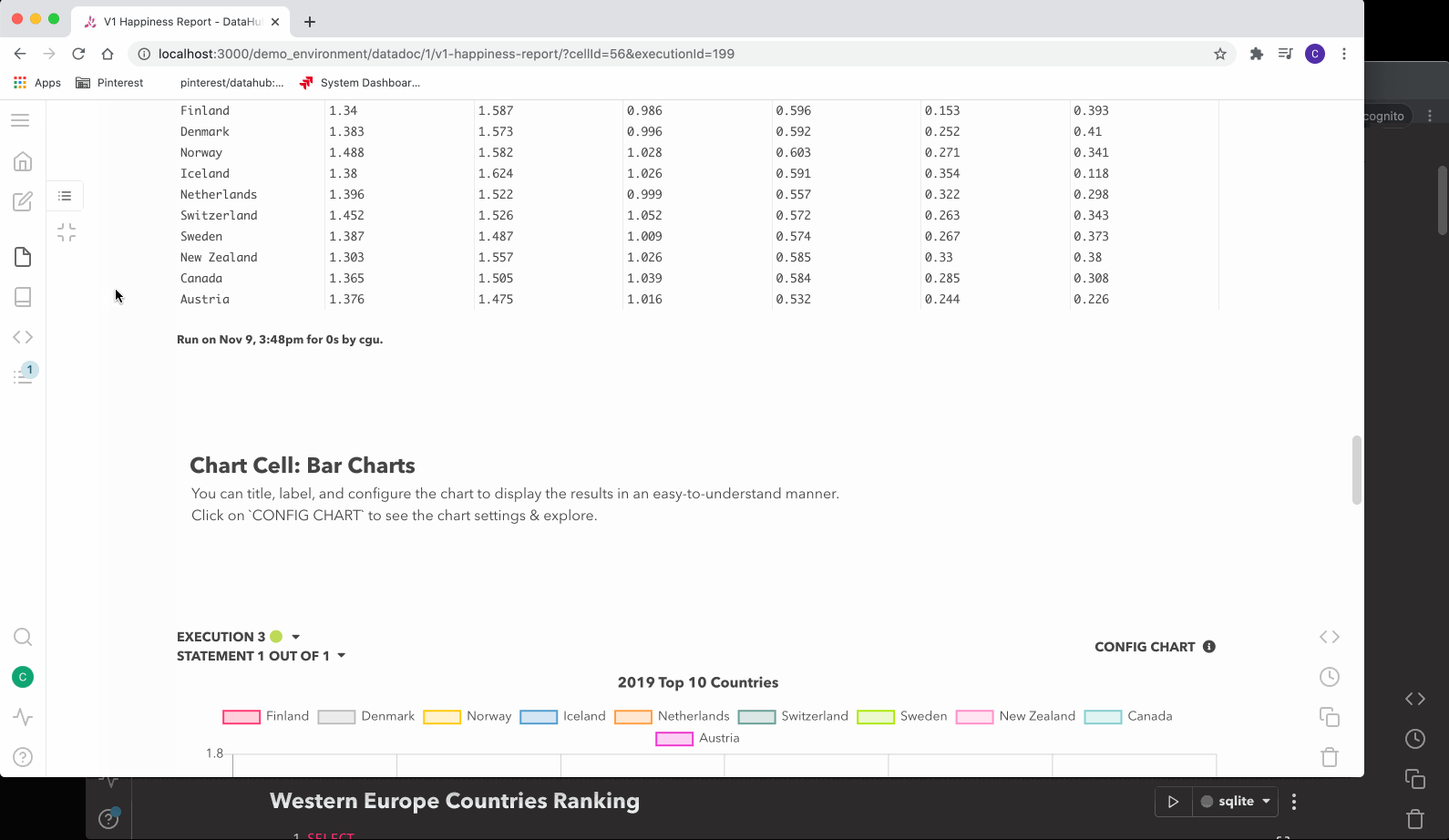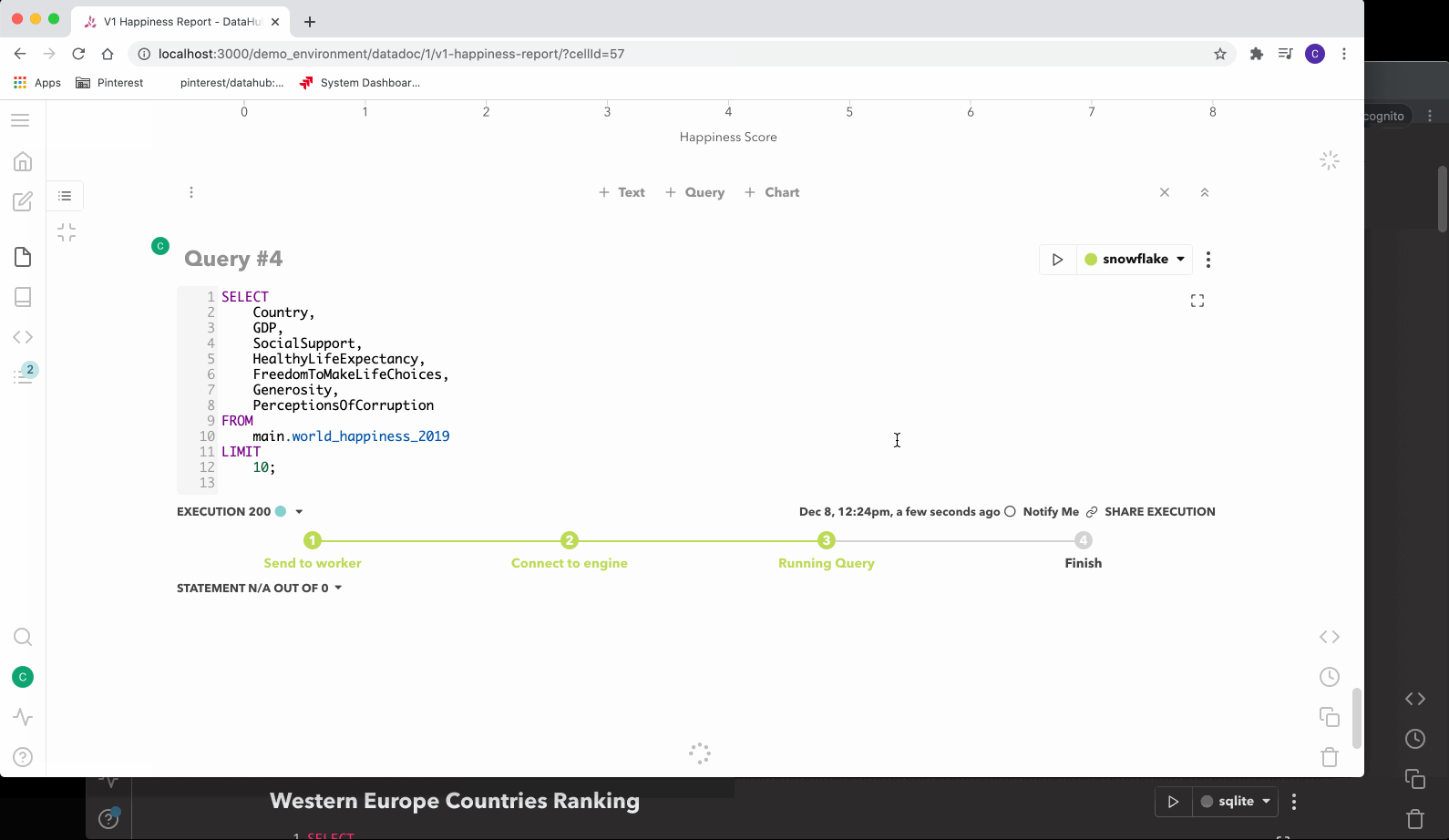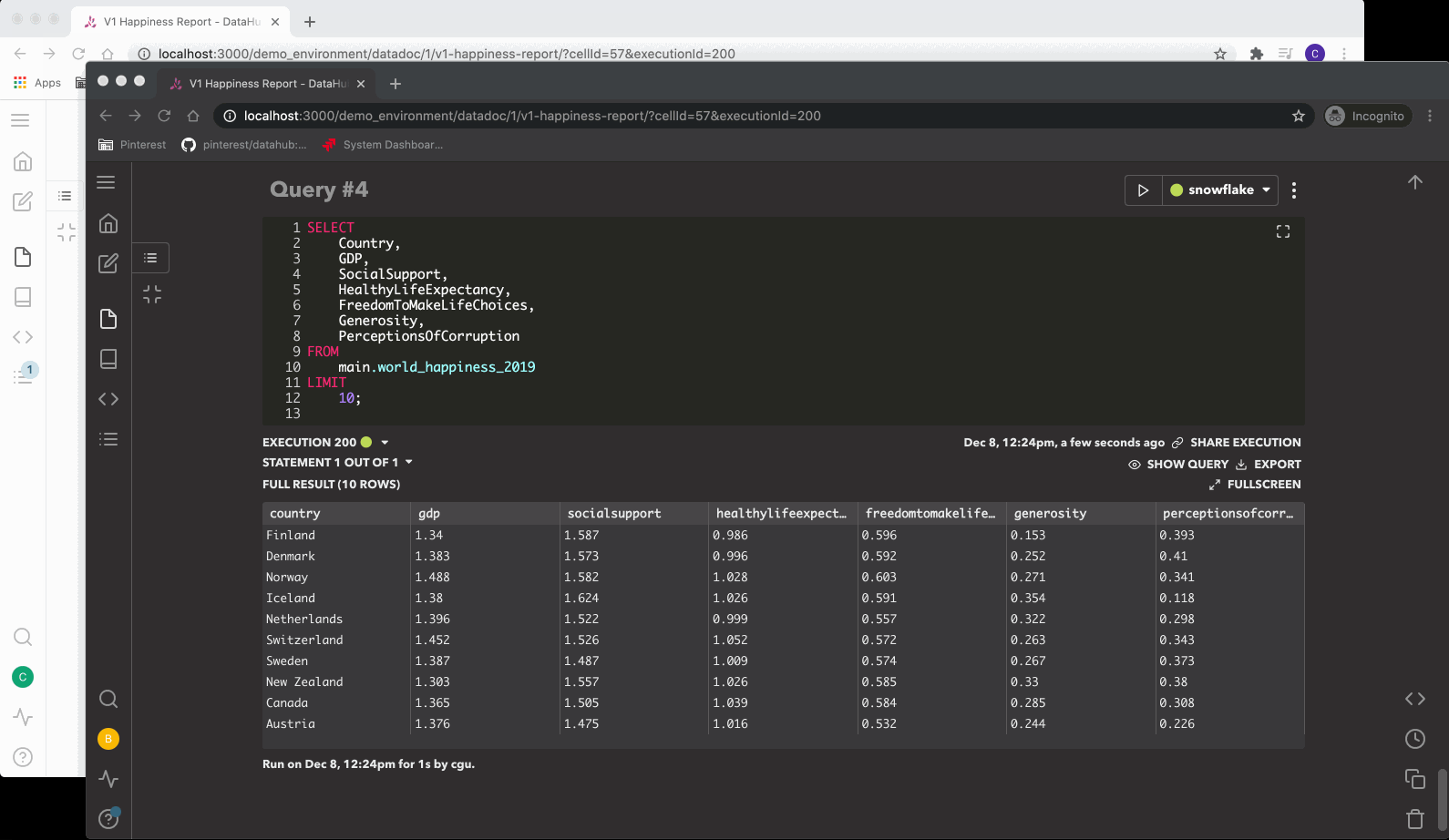
图 1 Querybook 的 Doc UI
用户首次访问时,他们会很快注意到其独特的 DataDoc 界面。这是用户进行查询和分析的主要位置。每个 DataDoc 均由一系列单元格组成,这些单元格可以是以下三种类型之一:文本、查询或图表。
文本单元格带有内置的富文本支持,以供用户记下他们的想法或见解。
查询单元格用于组成和执行查询。
图表单元格用于根据执行结果创建可视化效果。类似 Google Docs,授予用户访问 DataDoc 的权限后,他们可以共同实时协作。
通过直观的图表 UI,用户可以轻松地将 DataDoc 变成一个展示内容的仪表板。你可以选择多种可视化选项,例如时间序列、饼图、散点图等。然后你可以将可视化连接到 DataDoc 任意查询的结果上,并按需对它们做排序和聚合预处理。要自动更新这些图表,你可以使用计划选项并选择所需的时间安排。计划程序可以通知用户成功或失败的结果。结合 Jinja 提供的模板选项,创建实时更新 DataDoc 的速度非常快。
计划任务和可视化特性并不是要取代 Airflow 或 Superset 之类的工具,而是为用户提供了一种简单快速的方法来对其查询进行实验和迭代。Pinterest 工程师通常将 Querybook 用作撰写查询的第一步,之后再创建生产级工作流和仪表板。
最后一点也很重要,Querybook 带有一套自动查询分析系统。它可以对每个执行的查询进行分析,以提取元数据(例如引用的表和查询运行器)。Querybook 使用这些信息自动更新其数据模式和搜索排名,并显示表的常用用户和查询示例。查询越多,表的文档化程度就越高。
架构工程
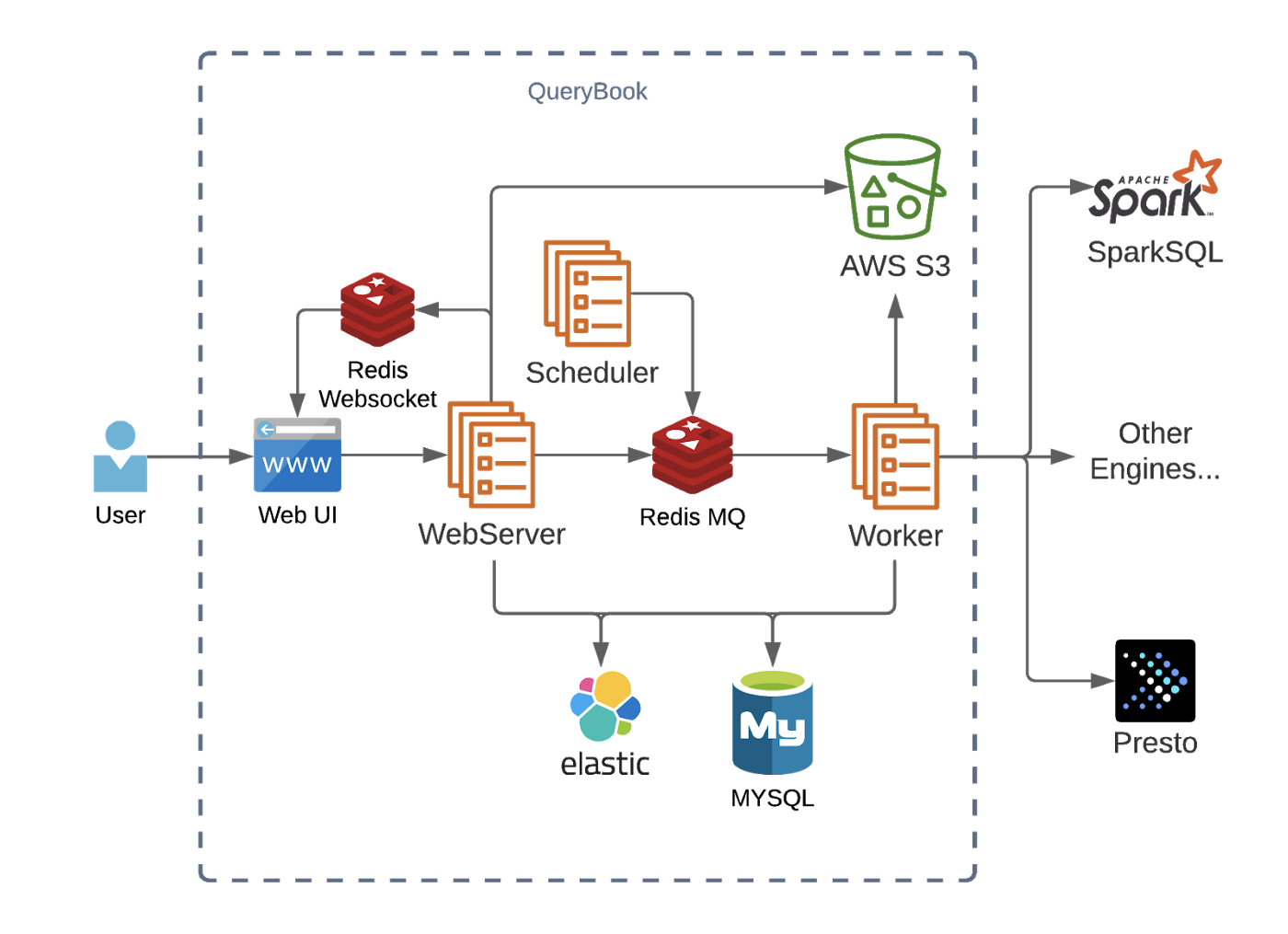
图 2 Querybook 的架构概述
为了了解 Querybook 的工作机制,我们来过一遍编写和执行查询的过程。
第一步是创建一个 DataDoc 并将查询写入一个单元格中。当用户键入内容时,用户的查询将通过 Socket.IO 流式传输到服务器。
然后,服务器将这些增量推送给所有通过 Redis 读取该 DataDoc 的用户。同时,服务器会将更新的 DataDoc 保存在数据库中,并为 worker 创建一个异步作业以更新 ElasticSearch 中的 DataDoc 内容,待以后搜索。
编写完查询后,用户可以单击运行按钮来执行查询,然后服务器将在数据库中创建一条记录,并将一个查询作业插入到 Redis 任务队列中。上述 worker 接受任务并将查询发送到查询引擎(Presto、Hive、SparkSQL 或任何与 Sqlalchemy 兼容的引擎)。在查询运行时,worker 通过 Socket.IO 将实时更新推送到 UI。
执行完成后,worker 加载查询结果并将其分批上传到一个可配置的存储服务(例如 S3)中。最后,浏览器将收到查询完成通知,并向服务器发出一个请求以加载查询结果,显示给用户。
简短起见,本节仅关注 Querybook 的一个用户流,但已经涵盖了其所使用的所有基础架构。Querybook 允许用户自定义其中的一些部分。例如,你可以选择将执行结果上传到 S3、Google Cloud Storage 或本地文件。另外,MySQL 也可以与任何与 Sqlalchemy 兼容的数据库(例如 Postgres)互换。
开源之路
在注意到 Querybook 在内部取得的成功之后,我们决定将其开源。我们遇到的一个挑战是如何在保留一些特定于 Pinterest 的集成的同时让它适合通用场景。为此,我们决定通过一套插件系统来做一个两层的组织,并添加一个 Admin UI(管理界面)。
借助 Admin UI,其他公司可以通过单个友好的界面来配置 Querybook 的查询引擎、表元数据提取和访问权限。以前,这些配置是在配置文件中完成的,需要更改代码并部署才能生效。有了这个新的 UI,管理员无需更改代码或配置文件即可进行实时 Querybook 更改。
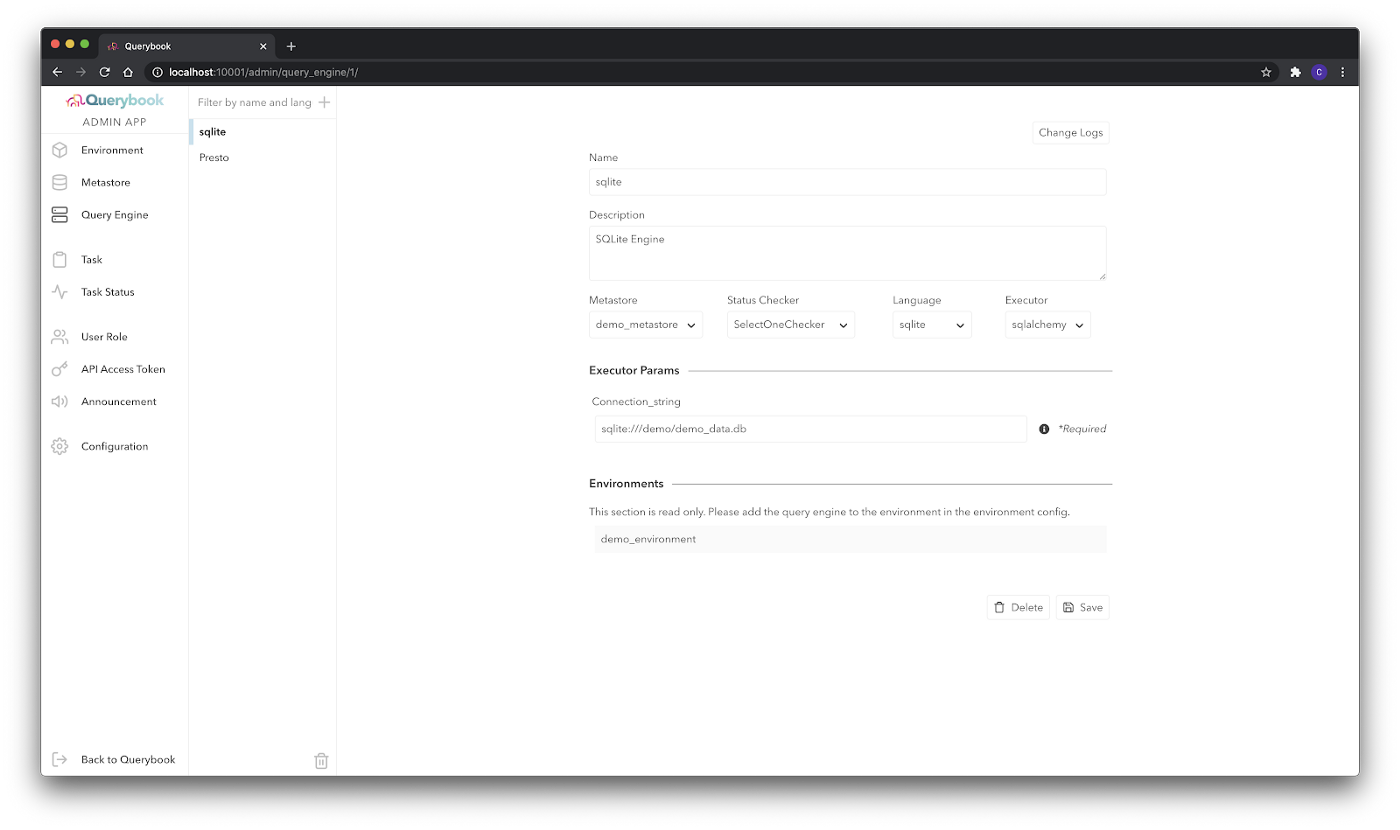
图 3 Admin UI
插件系统使用 Python 的 importlib 将 Querybook 与 Pinterest 的内部系统集成在一起。开发人员可以使用插件系统配置认证、自定义查询引擎并实现对内部站点的导出器。插件系统提供的自定义行为让 Querybook 可以针对用户在 Pinterest 上的工作流程做出优化,同时确保开源项目适合大众使用。
你可以在 Querybook.org 上查看 Querybook 的更多特性及文档,也可以通过 querybook@pinterest.com 与我们联系。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论