

在本系列的前几篇文章中,我们阐述了如何基于动态更新的配置(一组欺诈检测规则)实现灵活的流分区,以及如何利用 Flink 的广播机制(Broadcast)在运行时将处理配置分配给相关的 operator。
延展阅读:
继上次讨论端到端的解决方案之后,本文将介绍如何使用 Flink 的“瑞士军刀”—— Process Function(流程函数)来创建一个自定义的实现,以满足你的流业务逻辑需求。我们将在 欺诈检测引擎(Fraud Detection engine)的背景下继续讨论。我们还将演示如何在 Datastream API 提供的开箱即用窗口无法满足需求的情况下,如何实现 时间窗口的自定义替换 。特别是,我们将研究在设计需要对单个事件进行的低延迟响应的解决方案时可以做出的权衡。
本文将阐述一些可以独立应用的高级概念,但我们建议你先回顾本系列的第一部和第二部的内容,并检查代码库,以便更容易理解。
本文最初发表在 Apache Flink 官网,经原作者 Alexander Fedulov 授权,InfoQ 中文站翻译并分享。
ProcessFunction 作为“窗口”
低延迟
让我们首先提醒一下希望支持的欺诈检测规则类型:
“只要同一付款人在 24 小时内向同一收款人汇出的款项累计超过 20 万美元时,警报就会被触发。”
换句话说,给定一个由支付方和收款方字段结合的键分割的事务流,我们希望回顾一下时间,并确定对于每一笔传入的事务,两个特定参与者之间以前所有支付的总和是否超过了定义的阈值。实际上,对于特定的数据分区键,计算窗口总是沿着特定数据分区键的最后观察事件的位置移动。
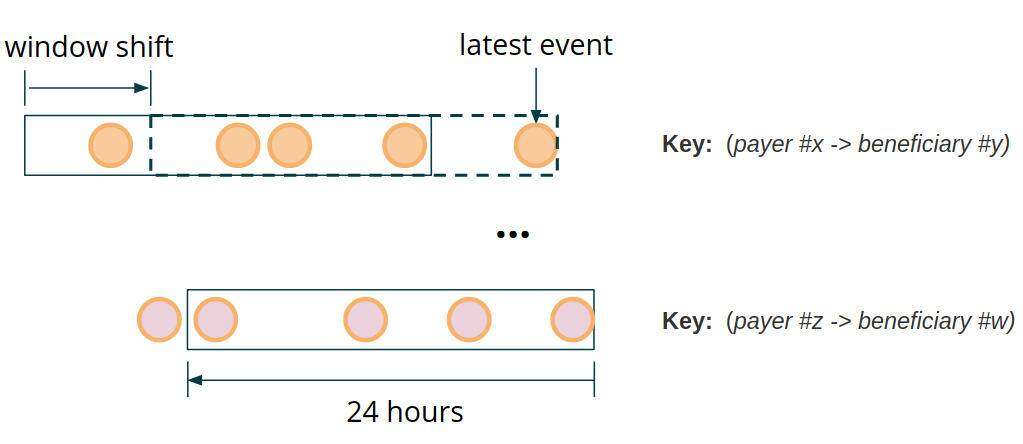
图 1:时间窗口
欺诈检测系统的常见关键要求之一是响应时间短。欺诈行为越早被发现,被阻止的可能性就越大,其负面影响也就越少。这一要求在金融领域尤为突出,因为在金融领域中,有一个重要的限制:评估欺诈检测模型所花费的时间,就是遵纪守法的系统用户等待响应的时间。处理速度往往成为各种支付系统之间的竞争优势,而生成警报的时限可能低至 300~500 毫秒。从将事务事件输入到欺诈检测系统的那一刻起,直到下游系统必须获得警报为止,这是所有的时间。
正如你可能知道的那样,Flink 提供了一个强大的 Window API,适用于各种用例。但是,如果你仔细研究所有可用的受支持窗口类型,你会发现,它们没有一个完全符合我们对这个用例的要求:每个传入事务的低延迟评估。Flink 中并没有任何类型的窗口可以表达“从当前事件返回的 x 分钟/小时/天”的语义。在 Window API 中,事件属于窗口(由窗口分配器定义),但它们本身并不能单独控制窗口的创建和计算(除了会话窗口外,它们仅限于基于会话 间隔的分配)。如上所述,欺诈检测引擎的目标是在接收到新事件时,能够立即对以前的相关数据点进行评估。这就提出了在这种情况下应用 Window API 的可行性问题,Window API 提供了一些用于自定义触发器、清除器和窗口分配器的选项,这些选项可能会得到所需的结果。然而,通常很难做到这一点(而且也很容易打破)。此外,这种方法不提供对广播状态的访问,而广播状态是实现业务规则的动态重新配置所必需的。
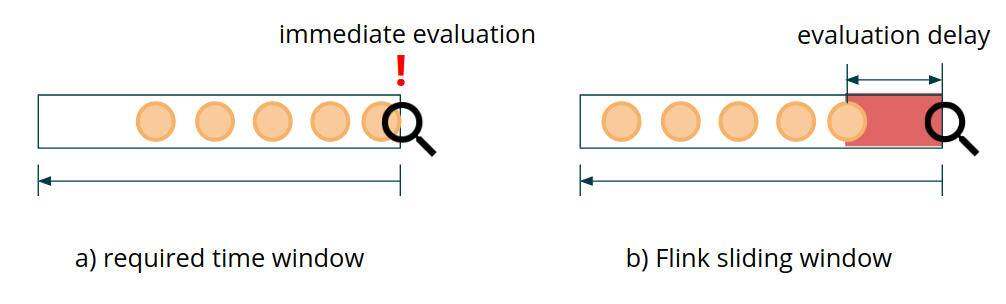
图 2:评估延迟
让我们以使用 Flink 的 Window API 的 滑动窗口为例。使用具有 S 滑动的滑动窗口转换为评估延迟的期望值等于 S/2 。这意味着即使不考虑任何实际计算时间,也需要定义 600~1000 毫秒的窗口滑动,才能满足 300~500 毫秒延迟的低延迟需求。Flink 为每个滑动窗口存储一个单独的窗口状态,这使得这种方法在任何中等高负载条件下都不可行。
为了满足需求,我们需要创建自己的低延迟窗口实现。幸运的是,Fliink 为我们提供了这样做所需的所有工具。ProcessFunction 是 Flink API 中一个低级但功能强大的构建块。它有一个简单的合同。
processElement()逐个接收输入事件。可以通过调用out.collect(someOutput),向下一个操作符生成一个或多个输出事件来对每个输入做出反应。还可以将数据传递到 侧输出(side-output),或者完全忽略特定的输入。当触发先前注册的计时器时,Flink 将调用
onTimer()。同时支持事件时间计时器和处理时间计时器。open()相当于构造函数。它在 TaskManager的 JVM 内部调用,用于初始化,比如注册 Flink 管理的状态。它也是初始化不可序列化且无法从 JobManager 的 JVM 传输的字段的正确位置。
最重要的是, ProcessFunction 还可以访问由 Flink 处理的容错状态。这种结合,在加上 Flink 的消息处理和传递保证,使得使用几乎任意复杂业务逻辑构建弹性事件驱动应用程序成为可能。这包括创建和处理带状态的自定义窗口。
实现
状态与清理
为了能够处理时间窗口,我们需要跟踪程序内部属于该窗口的数据。为了确保这些数据是容错的,并且能够在分布式系统中经受住失败,我们应该将其存储在 Flink 管理的状态中。随着时间的推移,我们不需要保留以前所有的事务。根据示例规则,所有超过 24 小时的事件都将变得无关紧要。我们看到的是一个不断移动的数据窗口,其中过时的事务需要不断地移出范围(换句话说,就是从状态中清除)。
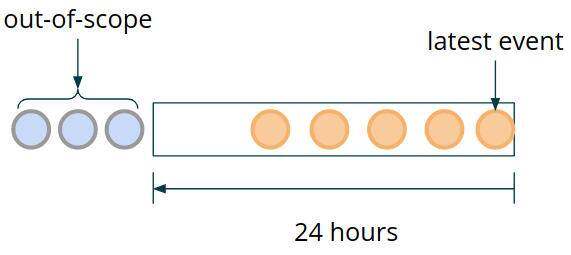
图 3:窗口清理
我们将 使用 MapState 来存储窗口的各个事件。为了有效地清理范围外的事件,我们将使用事件时间戳作为 MapState 键。
在一般情况下,我们必须考虑这样一个事实,即可能存在具有完全相同时间戳的不同事件,因此,我们将存储集合,而不是每个键(时间戳)的单独事务。
旁注:当在
KeyedProcessFunction内部使用任何 Flink 管理的状态时,由state.value()调用返回的数据将自动由当前处理的事件的键确定范围(参见图 4)。如果使用MapState,同样的原则也适用,只是返回的是Map而不是MyObject。如果你不得不执行类似mapState.value().get(inputEvent.getKey())之类的操作,那么你可能应该使用ValueState而不是MapState。由于我们希望为每个键存储多个值,因此,在我们的例子中,MapState是正确的选择。
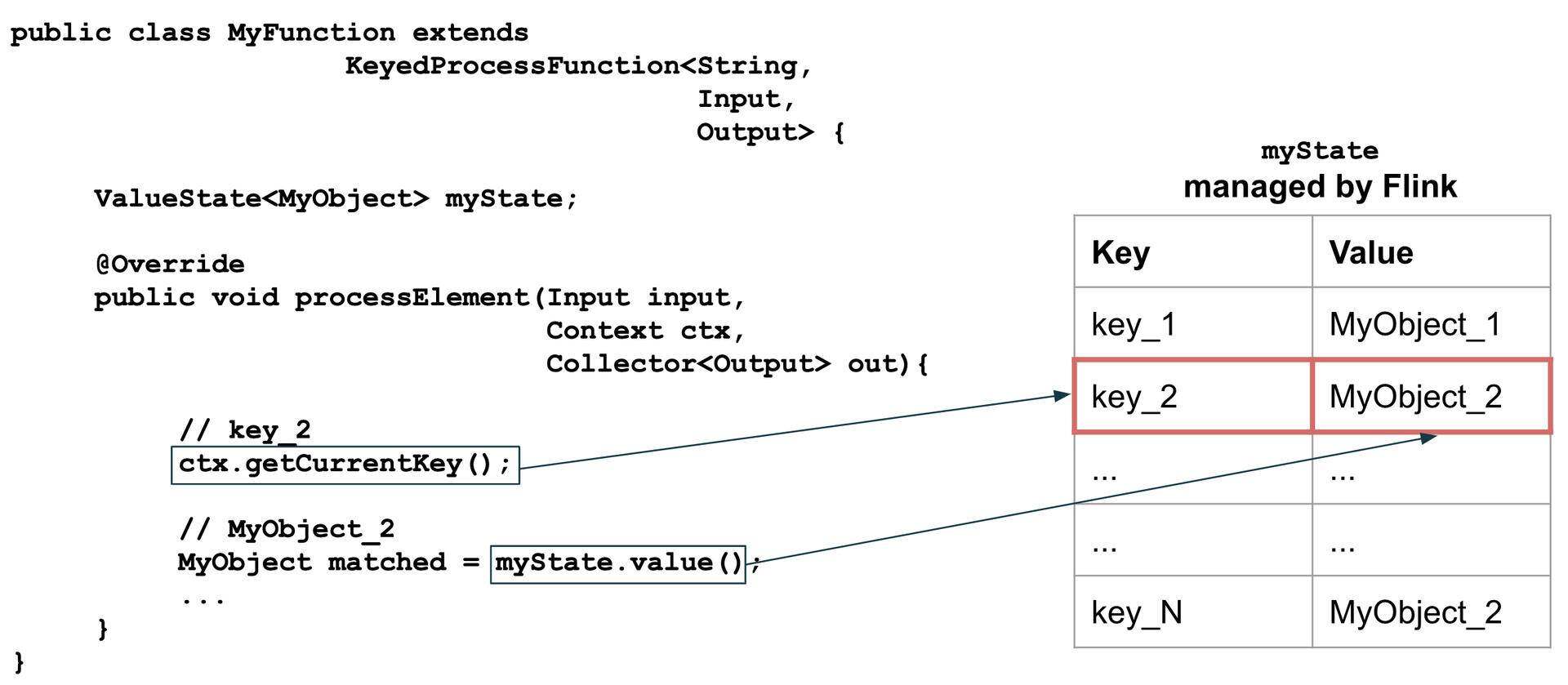
图 4:键状态范围
正如 本系列的第一篇博文所述,我们基于活动欺诈检测规则中指定的键来分派事件。多个不同的规则可以基于相同的分组键。这意味着我们的警报函数可能会接受由同一个键范围的事务(例如 {payerId=25;beneficiaryId=12} ),但是这些事务将根据不同的规则进行评估,这意味着可能会有不同的时间窗口长度。这就提出了问题,即如何在 KeyedProcessFunction 最好地存储容错窗口状态。一种方法是为每个规则创建和管理单独的 MapState 。然而,这种方法很浪费时间:我们将为重叠的时间窗口分别保存状态,因此会不必要地存储重复的事件。更好的方法是始终存储足够的数据,以便能够估计所有当前活动的规则,这些规则都是由同一键限定的。为了实现这一点,每当添加一个新规则时,我们都会确定它的时间窗口是否具有最大跨度,并将其存储在特殊保留的 WIDEST_RULE_KEY 的广播状态。这些信息稍后将在状态清理过程中使用,如本节后面所述。
现在,让我们详细研究一下主方法 processElement() 的实现。在 上一篇博文中,我们阐述了 DynamicKeyFunction 如何允许我们基于规则定义中的 groupingKeyNames 参数执行动态数据分区。接下来的描述,将主要围绕 DynamicAlertFunction ,它使用了其余的规则设置。

图 5:规则定义示例
如本博文系列的前几部分所述,我们的警报过程函数接受类型为 Keyed<Transaction, String, Integer> 的事件,其中 Transaction 是主要的“包装”事件,String 是键(图 1 中的支付方 #x 、收款方 #y ), Integer 是导致此事件分派的规则的 ID。该规则是以前 存储在广播状态中,必须通过 ID 从该状态检索。以下是实现的概要:
步骤的细节如下:
我们首先将每个新事件添加到窗口状态:
接下来,我们检索先前广播的规则,需要根据规则评估传入的事务。
根据规则中定义的窗口跨度和当前事务时间戳,
getWindowStartTimestampFor确定我们的计算应该跨越的时间有多长。通过迭代所有窗口状态项并应用聚合函数计算聚合值。它可以是一个平均值、最大值、最小值,或者像本节开头的示例规则中那样,是一个求和。
有了聚合值,我们就可以将其与规则定义中指定的阈值进行比较,并在必要时触发警报。
最后,我们使用
ctx.timerService().registerEventTimeTimer()注册一个清理计时器。当当前事务要移出范围时,该计时器将负责删除该事物。
注:要注意计时器在创建过程中的舍入。这是一项重要的技术,能够在触发计时器的精度和使用的计时器数量之间进行合理的权衡。计时器以 Flink 的容错状态存储,因此以毫秒级的精度管理可能会造成浪费。在我们的例子中,通过这种舍入,我们将在任何给定的秒中为每个键创建最多一个计时器。Flink 文档提供了一些其他 详细信息。
onTimer方法将触发窗口状态的清理。
如前所述,我们始终保持状态中的事件数量,以满足评估具有最大窗口跨度的活动规则的需要。这意味着在清理过程中,,我们只需删除超出这个最宽窗口范围的状态即可。

图 6:最宽的窗口
清理程序的实现方法如下:
注:你可能想知道为什么我们不使用
ListState,因为我们总是在迭代窗口状态的所有值?这实际上是针对使用RocksDBStateBackend时的优化。在ListState上进行迭代将导致反序列化所有Transaction对象。使用MapState的键迭代器只会导致键的反序列化(类型为long),因此减少了计算开销。
实现细节的描述就到此为止。我们的方法在新事务到达时出发对时间窗口的评估。因此,它满足了我们的主要要求:发出潜在警报的低延迟。关于完整的实现,请查看 GitHub 上的项目。
改进与优化
本文所述方法的优缺点是什么?
优点:
低延迟功能。
量身定制的解决方案,具有针对特定用例的潜在优化。
有效的状态重用(具有相同键的规则共享状态)。
缺点:
无法利用现有 Window API 中使用潜在的未来优化。
没有延迟事件处理,这在 Window API 中是现成可用的。
二次计算复杂度与潜在的大状态。
让我们看一下后两个缺点,看看是否能够解决它们。
延迟事件:
处理延迟事件提出了一个特定的问题:如果事件延迟到达,重新评估窗口是否仍然还有意义?如果需要这样做的话,则需要按最大语气无序度扩展用于清理的最宽窗口。这样可以避免在延迟触发时可能出现不完整的时间窗口数据(参见图 7)。
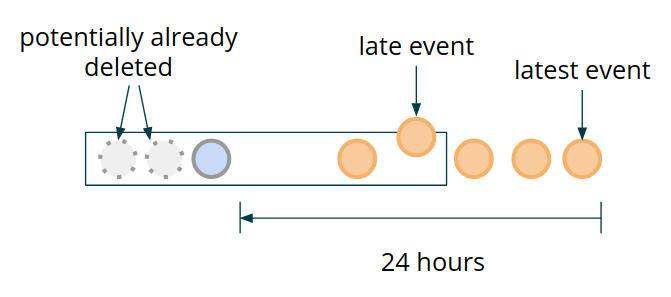
图 7:延迟时间处理
然而,可以说,对于强调低延迟处理的用例来说,这种延迟触发是没有意义的。在这个例子中,我们可以跟踪到目前为止观察到的最新时间戳,对于不单调增加这个值的时间,只需将它们添加到状态中,并跳过聚合计算和警报触发逻辑。
冗余的重新计算和状态大小:
在我们描述的实现中,我们将单个事务保持在状态中,并在每个新事件上反复检查它们以计算聚合。就重复计算上浪费计算资源方面而言,这显然并不是最佳选择。
保持单个事务状态的主要原因是什么?存储事件的粒度直接对应于时间窗口计算的精度。因为我们单独存储事务,所以只要单个事务离开精确的 2592000000 毫秒的时间窗口(以毫秒为单位的 30 天),我们就可以精确地忽略它们。在这一点上,值得提出一个问题:在估算如此长的时间窗口时,我们真的需要这种毫秒级的精度吗?或者,在特殊情况下接受潜在的五保可以吗?如果你的用例的答案是不需要这种精度,那么可以基于 bucketing 和 pre-aggregation 实现额外的优化。这种优化的想法可以细分为以下内容:
创建一个父类,它可以包含单个事务的字段,也可以包含根据对一组事务应用聚合函数计算的组合值,而不是存储单个事件。
不要使用以毫秒为单位的时间戳作为
MapState键,而是将它们摄入到你愿意接受的“分辨率”级别,例如,一整分钟。因此,每个条目代表一个 bucket。无论何时评估窗口,都要将新师傅的数据附加到 bucket 聚合中,而不是每个师傅存储单个数据点。
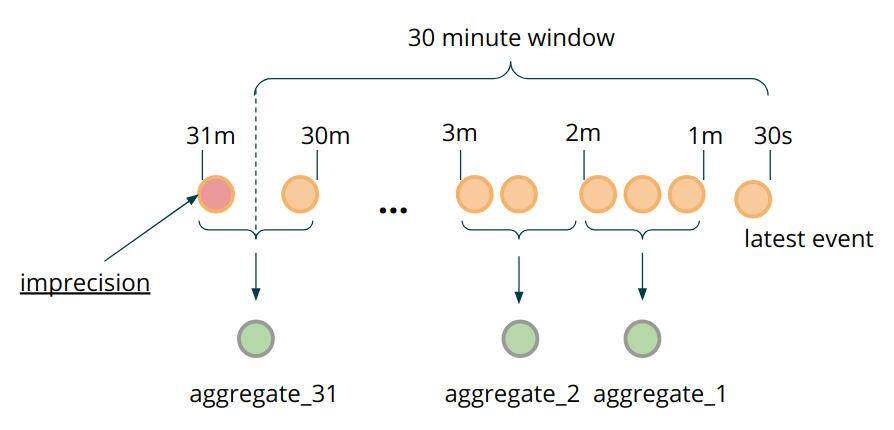
图 8:Pre-aggregation
状态数据和序列化器
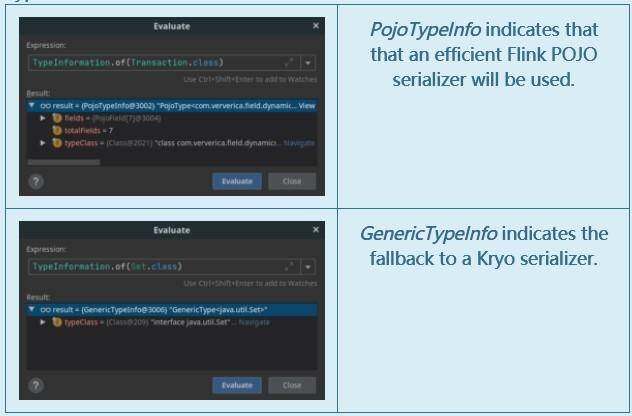
为了进一步优化实现,我们可能要问自己的另一个问题是,获得具有完全相同时间戳的不同事件的可能性有多大?在所描述的实现中,我们演示了一种解决这一问题的方法,即在 MapState<Long, Set<Transaction>> 中为每个时间戳存储事务集。然而,这样的选择可能会对性能产生比预期更大的影响。原因是,Flink 目前没有提供原生集序列化程序,而是强制回退到效率较低的 Kryo 序列化程序( Flink-16729)。一种有意义的替代策略是,假设在正常情况下,没有两个不一致的事件会具有完全相同的时间戳,并将窗口状态转换为 MapState<Long, Transaction> 类型。你可以使用 侧输出来收集和监控任何与你的假设相矛盾的意外事件。在性能优化期间,我通常会建议你 禁用回退到 Kyro,并通过确保使用 更高效的序列化程序来验证你的应用程序可能在哪里得到进一步优化。
技巧:通过设置断点并验证返回的
TypeInformation的类型,可以快速确定要将哪个序列化程序用于你的类。
事件修剪 :我们可以将单个事件的数据减少到仅相关的信息,而不是存储完整的事件并对序列化/反序列化机制施加额外的压力。这可能需要将单个事件“解压缩”为字段,并根据活动规则的配置将这些字段存储到通用的 Map<String, Object> 数据结构中。
虽然这种调整可能会对大型对象产生显著的改进,但它不应该成为你的首选,因为它很容易导致过早的优化。
总结
本文总结了我们在 第一部中开始描述的欺诈检测引擎的实现。在这篇博文中,我们演示了如何利用 ProcessFunction 来“模拟”一个具有复杂自定义逻辑的窗口。我们已经讨论了这种方法的优缺点,并详细阐述了如何应用自定义用例特定的优化,这在 Window API 中是不可能直接实现的。这篇博文的目的是说明 Apache Flink API 的强大功能和灵活性。它的核心是 Flink 的支柱,它为开发人员节省了大量的工作,并广泛适用于各种用例:
分布式集群中的高效数据交换。
通过数据分区实现横向扩展。
具有快速、本地访问的容错状态。
用于处理此状态的方便抽象,它就像使用局部变量一样简单。
多线程并行执行引擎。
ProcessFunction代码在单个线程中运行,无需同步。Flink 处理所有并行执行方面,并正确访问共享状态,而无需你作为开发人员考虑这一点(因为并发性很难)。
所有这些方面都使得使用 Flink 构建应用程序成为可能,这些应用程序远远超出了简单的流 ETL 用例,并支持任意复杂的、分布式的事件驱动应用程序的实现。有了 Flink,你可以重新考虑处理各种用例的方法,这些用例通常依赖于使用无状态并行执行节点,并将状态容错问题“推”到数据库中,这种方法在数据量不断增加的情况下通常注定会遇到可扩展性问题。
作者介绍:
Alexander Fedulov,VervericaData 系统架构师。专注分布式系统的可扩展性问题。目前为 Apache Flink 工作。
原文链接:
https://flink.apache.org/news/2020/07/30/demo-fraud-detection-3.html

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论