

本文最初发表在 Towards Data Science 博客,经原作者 Vinay Kudari 授权,InfoQ 中文站翻译并分享。
本文作者带你演示如何使用 Fastai——基于 PyTorch 的高级深度学习库,用 15 行代码来创建一个口罩分类器。
Fastai 是一个基于 PyTorch 的高级深度学习库。Jeremy Howard 最近推出了该库的最新版本,同时还推出了非常方便、适合初学者的一本书和一门课程。我对它的抽象程度相当惊讶,它能帮助你在短短几分钟内就创建出最先进的模型,而无需担心背后的数学问题。
本文是为初学者写的,就算你没有多少编程经验,你也能按照这篇文章做出来。读完本文后,你就可以从头开始写一段代码,可以识别你最喜欢的超级英雄,甚至可以通过动物发出的声音来识别它。
下面是口罩分类器的结果快照,我使用了少量的训练数据、几行代码,以及在一个 GCP 集群上几分钟的训练。点击这里可以免费设置你自己的 FastAI GPU VM。

为了实现这一结果,我们首先需要在图像中找到人脸,也就是定位,然后对每个人脸进行分类,并根据它所述的类别(绿色:
with_mask;红色:no_mask;黄色:mask_worn_inproperly)绘制出彩色边框。现在,让我们来了解多类图像分类问题。
该项目的代码可以在这里找到。
我会在写一些代码的同时,解释深度学习和计算机视觉的一些基本概念。我强烈建议你在 Jupyter Notebook 上逐行运行代码,因为我们理解了抽象函数背后的思想。
处理数据
该库分为几个模块,主要有表格、文本和视觉。由于我们今天的问题将涉及到视觉,因此,让我们从 vision 库导入我们需要的 all 函数:
就像我们如何通过观察图像来学习识别物体一样,计算机也需要数据来识别图像。为了检测出口罩,我整理了一个从 Kaggle 和其他来源收集的带有标签的数据集,你可以从这里下载。
我们存储数据集所在的路径。Path 返回一个 apathlib 对象,它可以非常容易地用于执行某些文件操作。
在训练模型(即教会模型识别图像的算法)之前,我们首先需要告诉它一些事情:
预期的输入和输出是什么?问题域是什么?
数据位于何处,以及如何标记?
我们需要保留多少数据来评估模型的性能?
我们需要转换数据吗?如果需要,又该如何转换?
Fastai 有一个名为 DataBlock 的函数,它超级灵活,可以输入上述问题并准备一个模板:
get_image_files 函数递归地获取给定路径中的所有图像文件文职并返回它们,这样我们就可以告诉 Fastai 在哪里 get_items。
在我们的数据集中,我将图像放在根据类别命名的单独文件夹中,parent_label 函数根据路径返回文件的父目录。
例如:
你可以根据数据的标签方式来编写自己的函数:
知道输入图像和目标标签的文件路径后,我们需要根据问题的类型对数据进行预处理。图像的预处理步骤示例包括使用 Pillow 从文件路径创建图像并将其转换为张量。
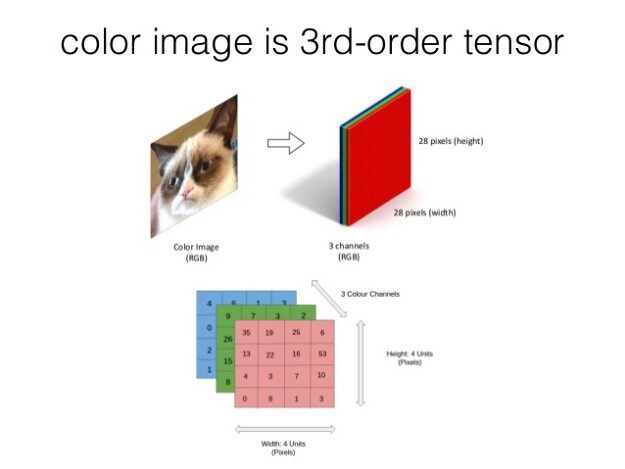
图像在电脑中是如何表示的?
每张图像都是一个像素密度矩阵。每个值的范围为 0~255。0 是各通道最黑的,255 是各通道最亮的。
彩色图像是一个三层矩阵/三价张量。每层由红(Red)、绿(Green)、蓝(Blue)强度组成,而黑白图像则是一维矩阵。
我们将 TransformBlock 类型的元组 (input_transformation, output_transformation) 传递给 blocks。在我们的问题中,需要预测图像的类别,因此传递 (ImageBlock, CategoryBlock)。如果假设你想根据一个人的图片来预测他的年龄,你需要传递 (ImageBlock, RegressionBlock)。
深度学习模型在所有图像大小相同的情况下效果最好,而且当分辨率较低时,模型学习的速度更快。我们将通过 item_tfms 传递一个合适的 resize 函数来告诉如何调整图像的大小,这个函数将被应用到每张图像上。

使用 ResizeMethod.Squish、ResizeMethod.Pad 和 ResizeMethod.Crop 方法调整图像大小。
Fastai 提供了各种调整大小的方法:裁剪、填充或压缩。它们中每个方法都有一些问题。有时候,我们甚至可能会丢失一些关键信息,就像在中心裁剪之后的第三张图像中一样。
我们可以使用 RandomResizedCrop 来解决这个问题。在这里,我们随机选择图片的一部分,并对模型进行几个轮数(epoch)的训练(即一次完整地遍历数据集中所有图片),每个轮数涵盖了每张图片的大部分区域。min_scale 决定了每次选择图像的最小值。

在训练数据集上进行模型正确率评估会导致评分出现偏差,可能会导致对未见过的数据的性能较差。我们需要告诉 DataBlock API 留出一部分经过预处理的数据来评估模型的性能。算法看到数据称为训练数据,保留的数据称为验证数据。通常,数据集将定义验证集,但在我们的示例中,我们并没有验证集,因此,需要将 split 函数传递给 splitter。
Fastai 有几个 split 函数,让我们用 RandomSplitter 来解决今天的问题,valid_pct 将确定需要保留的训练数据部分,并且 seed 将确保始终保留相同的随机图像。
拥有多样化的数据集对于任何深度学习模型的性能都至关重要。那么,如果你没有足够的数据量,该怎么办呢?我们在现有数据的基础上生成新的数据,这个过程称为“数据增强”(Data augmentation)。
数据增强(Data augmentation)指的是创建输入数据的随机变化,使得它们看起来不同,但实际上并不改变数据的含义。
——Fastbook

使用 aug_transforms() 对单个泰迪熊图像进行增强。
上面的图片都是有一张泰迪熊的照片生成的。在现实世界中,我们经常需要对看不见的数据进行预测,如果模型只是记住训练数据,那么它的性能会很差(过拟合),而应该理解数据。事实证明,在很多情况下,数据增强对提高模型的性能很有帮助。
在 Fastai 中,我们有一个预定义的函数 aug_transforms,它执行一些默认的图像转换,比如翻转、改变亮度、倾斜等等。我们将这个函数传递给 batch_tfms,值得注意的是,这些转换是在 GPU 上执行的(如果可用的话)。
DataBlock 保存将在数据集上执行的列表指令。这将充当创建 DataLoader 的蓝图,该 DataLoader 采用我们的 DataSet 路径,按照 DataBlock 对象的定义对图像应用预处理转换,并将其加载到 GPU 中。数据被加载之后,batch_tfms 数据将应用于该批。默认批大小为 64,你可以通过 bs=n 传递给数据读取器函数,根据你的 GPU 内存增加或减少批大小。
提示:!nvidia-smi 命令可以在 Jupyter Notebook 随时执行,以了解 GPU 使用的详细信息。你可以重新启动内核以释放内存。
dls 是一个 DataLoader 对象,它包含训练数据和验证数据。你可以使用 dls.show_batch() 查看转换后的数据。
训练口罩分类器模型
模型是一组值,也称为权重,可用于识别模式。模式识别无处不在,对于生物来说,这是一个认知过程,发生在大脑中,而我们却没有意识到它。就像我们小时候通过盯着颜色、物体和字母学会识别一样。训练模型就是确定一组正确的权值,它可以解决一个特定的问题,在我们的示例中,是将一幅图像分类为三类:with_mask、without_mask、mask_weared_incorrect。
如何快速训练模型?
作为成年人,我们几乎可以立即学会识别物体,这是因为我们从出生起就一直处于学习模式。最初,我们学会了辨别颜色,然后是简单的物体,比如球、花之类的。几年后,我们就能够识别人和其他复杂的物体。类似的,在机器学习中,我们有预训练模型,这些模型已经经过训练来解决类似的问题,并且可以通过修改来解决我们的问题。
将预训练模型用于不同于最初训练的任务,称为迁移学习。
——FastBook
resnet34 就是这样一个模型,它是在 ImageNet 数据集上训练出来的,该数据集包含大约 130 万张图片,可以将图片分类为 1000 多种类别。在我们的问题中,只有三个类别,因此,我们使用初始层来识别基本的模式,如线、角、简单的形状,然后在最后一层进行重新训练。
Fastai 提供了一个 cnn_learner 函数,该函数在计算机视觉模型的训练中特别有用。其中包括 DataLoader 对象 dls、预训练模型 resnet34(此处的 34 表示有 34 层),以及一个度量 error_rate(用于计算在验证数据上分类错误的图像百分比)。
度量是使用验证集度量模型预测质量的函数。
——Fastbook
迁移学习是如何工作的?
最初,我们用一个或多个具有随机权重的新层替换我们预训练模型的最后一层,这部分被称为头部。我们使用反向传播算法更新头部的权重,有关这部分我将在另一篇文章中阐述。
Fastai 提供了一种方法 fine_tune,该方法执行调整预训练模型的任务,以使用我们整理的数据来解决我们的特定问题。
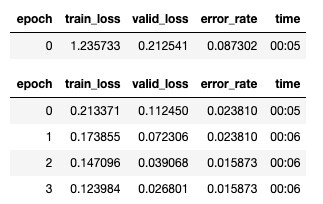
fine_tune 函数的输出。
我们将一个数字传递给 fine_tune,它告诉你需要训练多少个轮数(即完全浏览数据集的次数)。这是你需要处理的事情,并没有硬性规定。这取决于你的问题、数据集和你希望花在训练上的时间。你可以使用不同的轮数次数来运行该函数。
Jeremy 的提示和我的经验教训:
训练大量的轮数可能会导致过拟合,这可能会导致在未见过数据上的性能不佳。如果验证损失在连续的轮数中持续增加,意味着我们的模型正在记忆训练数据,就需要停止训练。
我们可以对模型进行不同分辨率的训练来提高性能。例如,使用 224 × 224 像素进行训练,然后再使用 112 × 112 像素进行训练。
数据增强在一定程度上有助于与防止过拟合。
使用模型进行推理
现在,我们已经有了经过训练的口罩分类器,它可以根据一个人的脸部照片来分类一个人是否正确地、或错误地佩戴口罩。我们可以导出这个模型,并用它来预测其他类。
我们可以使用 load_learner(‘path/to/model/export.pkl’) 来加载这个模型。
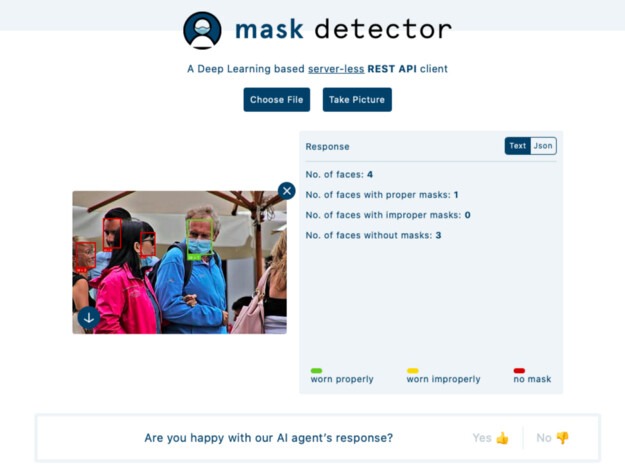
Web App 的截图
我接着做了一个 REST API,将这个模型公开到互联网上,并在朋友 Vaishnavi 和 Jaswanth 的帮助下,制作了一个 Web 应用程序,它获取输入图像,并根据人脸所述的类别以及人脸类别的计数绘制边框。Web 应用程序已上线,网址为:https://findmask.ml。
结语
现在,你可以构建图像分类器了。你还可以使用这一技术将声音转换成谱图或任何合适的图像形式来进行分类。
作者介绍:
Vinay Kudari,机器学习工程师、社会企业家。
原文链接:

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论