在著名的 Netflix 竞赛之后,推荐系统得到了很大的关注和发展,很多出色的工具库也随之出现。但是,绝大多数的工具库都存在跨平台难,内置算法数量少,更新停止等问题。推荐系统领域也存在因为数据集和实现方式不同而导致算法结果很难被复现的问题。因此,不论是工业界还是学术界,对于一个算法充分,结构精良,使用简单,扩展性强的算法工具库的需求越来越强烈。
为了满足以上需求,LibRec 团队设计实现了基于 Java 的跨平台推荐框架,并以 GPL3.0 协议在 GitHub 上开源共享。基于此工具库,科研人员可以快速实现全新的推荐系统算法并以其他推荐算法为基线进行比较,而研发人员也可以基于当前工具库的比较结果来选择具体业务情景下合适的算法或直接将 LibRec 集成在系统平台中。
与其他机器学习系统类似,推荐系统本质上都是对于输入的数据分成两批进行再加工。其中一批数据用于算法模型的训练,另外一批用于算法模型的评估。最后,根据评估结果来判断算法模型的质量。然而在具体到推荐系统的设计时,要同时考虑到针对不同类型的数据源,不同需求的分割方式,以及推荐算法之间的差异和评估结果的不同。这就要求系统必须要有非常高的模型化设计,同时不同模块之间的耦合度要尽可能低。本文接下来着重介绍系统的结构实现,主要为数据结构层,数据模型层,推荐算法层,评估层与过滤层。在此基础上,介绍推荐程序的执行流程与简单示例。
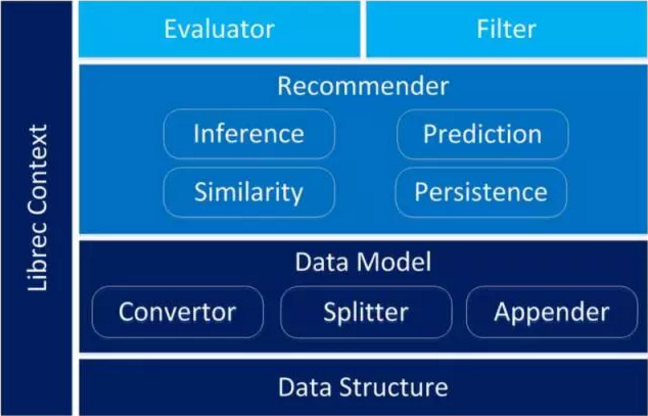
数据结构层
在推荐系统领域内,user-item 矩阵一般都非常稀疏。如果使用传统的数据保存方式,矩阵内会填充大量的 0,从而产生严重的内存和计算浪费。因此,LibRec 使用的基本数据结构为存储紧凑的稀疏向量,稀疏矩阵与稀疏张量。
稀疏矩阵的构建方式为将 n*m 的矩阵转换为 2*r+n (CRS) 或者 2*r+m (CCS),其中 r 为矩阵中非零的个数。n 和 m 分别是矩阵的宽和长。以 CRS 为例,在内部实现构建方式为向量 val 保存所有的数值,向量 col_ind 保存每一个数值在相应行中所处在的列的位置。向量 row_ptr 保存在 col_ind 索引中,换行的位置。因此,为获取坐标 (i, j) 的数值,可以首先在 row_ptr 中查询当前行的数值在 col_ind 与 val 的范围,然后与该范围内的 col_ind 进行匹配并获取到当前位置的数值。稀疏向量与稀疏张量的实现方式与该方式类似,不再展开。
数据模型层
数据模型层是指准备数据的所有过程,包括读取 user-item 数据,读取分割数据,读取关于 user 或者关于 item 的关系数据。这些功能分别由 Convertor,Splitter,Appender 模块实现。
Convertor 负责不同类型和格式的数据读取。具体来说,Convertor 实现了针对于 user-item-rating 或 user-item-rating-date 的数据形式与另外一种更加通用的数据保存形式:arff。第一种格式每一行分别保存一个三元组或三元组加上时间来表示一条记录。数据形式为 3*n 或 4*n,其中 n 为数据的条目数量。Arff 格式的文件需要首先在文件的头部定义关系名称,之后分别定义了每一列的数据类型和数据名称。Arff 也是基于 Java 的著名开源算法包 Weka 中数据的保存格式。
Splitter 模块负责对 Convertor 读取到的数据进行分割。在机器学习过程中,一般都需要将数据集分割为两份或三份。其中一份用来训练模型,另外一份用来验证分类效果的好坏。考虑到具体不同的实现需求,LibRec 的数据分割包括以下几类。
- Ratio. 基于 Ratio 的分类方法为通过给定的比例来将数据分为两部分。这个分类过程可以在所有数据中进行随机分类,也可以在用户或者物品维度上进行分类。当有时间的特征时,可以根据时间顺序留出最后一定比例的数据来进行测试。
- LooCV. LooCV 的分割方法为 leave-one-user/item/rating-out,也就是随机选取每个 user 的任意一个 item 或者每个 item 的任意一个 user 作为测试数据,余下的数据来作为训练数据。在实现中实现了基于 User 和基于 Item 的多种分类方式。
- GivenN. GivenN 分割方法是指为每个用户留出指定数目 N 的数据来作为测试用例,余下的样本作为训练数据。
- KCV. KCV 即 K 折交叉验证。将数据分割为 K 份,在每次执行时选择其中一份作为测试数据,余下的数据作为训练数据,共执行 K 次。综合 K 次的训练结果来对推荐算法的性能进行评估。
- GivenTestSet. GivenTestSet 是指由用户提供测试数据。与其他分割方式相比,使用 GivenTestSet 更方便比较基于不同平台实现的推荐算法。
部分推荐算法 (如 SocialRecommender) 需要通过引入 user 和 user 或者 item 与 item 之间的关系数据。针对这一需求,LibRec 设计了 Appender 模块来进行关系数据读取并返回读取数据之后的稀疏矩阵。
算法层
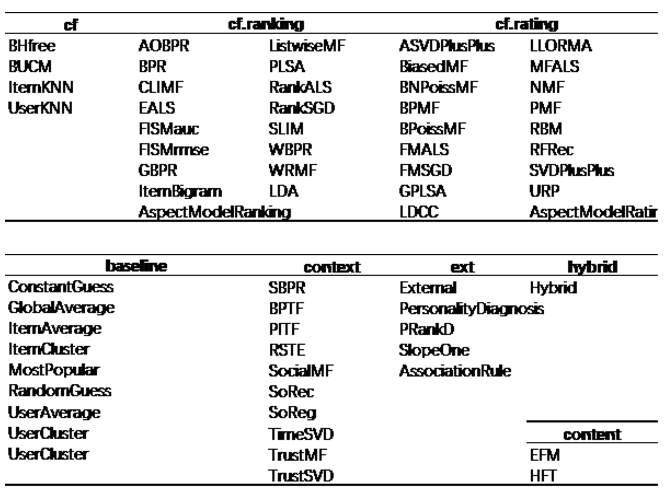
算法层是 LibRec 项目中最核心的部分,也是 LibRec 项目最具有竞争力的部分。目前 LibRec 中包含了 70 余例推荐算法,涵盖了基准算法,协同过滤算法,基于内容的算法,基于情景感知的算法,混合算法以及其他扩展算法。这些算法的时间跨度从 NMF 等经典的算法至 TrustSVD 等近两年提出的算法。目前所包含的算法如下图所示,所有算法对应的论文已经整理在文档中。
在数据预处理部分,数据读取与分割之后保存数据的类为 DataModel,这同时也是 Recommender 类的构造器参数之一。而模型的训练则由 evaluate 方法完成。该方法被不同的算法重写,从而完成不同推荐系统模型的训练。
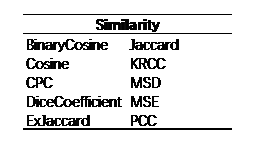
对于具体的算法实现,需要分别实现以下几个模块。模型的推断 (Inference),模型的预测 (Prediction),相似度的衡量 (Similary) 以及模型的持久化 (Persistence)。模型的推断部分用于模型的训练,而模型的预测部分则被 Evaluator 类调用从而进行最终结果的评估。模型的持久化用于保存训练完成的算法,从而避免算法的重复执行。相似度的计算可以通过实例化相似度类进行计算,作为参数输入构造器;也可以使用 Recommender 类直接对 DataModel 计算相似度矩阵。LibRec 中模型相似度的衡量主要涵盖了以下相似度计算方法。具体计算公式不再展开讲解。
评估层
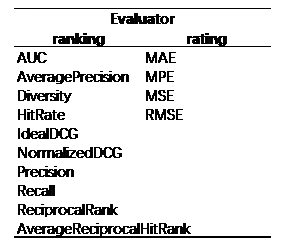
输出层主要包含两部分,其中一部分为 Evaluator,即对模型的评估。另外一部分为 Filter,用于将结果输出时以给定条件进行过滤。评估过程为针对测试数据,根据预测出的结果与实际的结果对推荐算法进行评估。根据推荐算法的不同,最终的评估函数也分为 ranking 与 rating 两种类型。
目前 LibRec 包含的评估函数如下表所示:
Filter 类需要通过 set 方法来写入需要过滤掉的 user 列表与 item 列表,并且可以在推荐算法的结果中进行过滤并手动输出到文件中。具体实现可以参考文档和程序中附带的实例程序。
在当前模块结构下,典型的算法实现流程如下图所示。
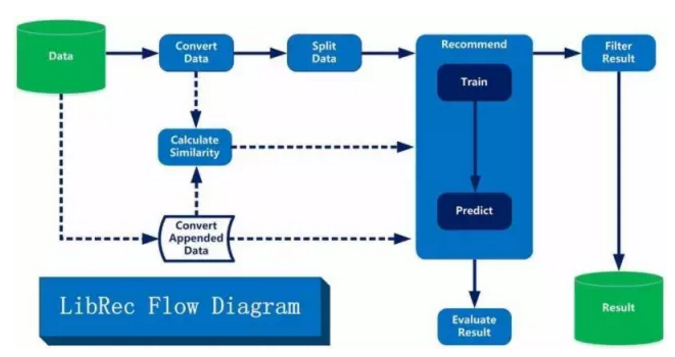
所有的实线为所有算法均需要执行的步骤,而虚线连接为部分算法需要执行的步骤。首先对于输入的数据,读取分割后送给推荐类进行训练。训练结束之后对测试数据进行预测并使用相应的评估器进行评估。同时对于预测之后的结果进行过滤并进行持久化保存。
得益于优良的模块化设计,在具体实现中只需要对相应的类(如推荐算法、评估器)进行实例化并进行调用即可,典型的代码调用如下所示。
public static void main(String[] args) throws Exception {
// set id list of filter
List<string> userIdList = new ArrayList<>();
List<string> itemIdList = new ArrayList<>();
userIdList.add("1");
itemIdList.add("70");
// build data model
Configuration conf = new Configuration();
conf.set("dfs.data.dir", "path/to/data/folder/");
Randoms.seed(1);
TextDataModel dataModel = new TextDataModel(conf);
dataModel.buildDataModel();
// build recommender context
RecommenderContext context = new RecommenderContext(conf, dataModel);
// build similarity
conf.set("rec.recommender.similarity.key" ,"item");
RecommenderSimilarity similarity = new PCCSimilarity();
similarity.buildSimilarityMatrix(dataModel);
context.setSimilarity(similarity);
// build recommender
conf.set("rec.neighbors.knn.number", "5");
Recommender recommender = new ItemKNNRecommender();
recommender.setContext(context);
// run recommender algorithm
recommender.recommend(context);
// evaluate the recommended result
RecommenderEvaluator evaluator = new RMSEEvaluator();
System.out.println("RMSE:" + recommender.evaluate(evaluator));
// filter the recommended result
List<recommendeditem> recommendedItemList = recommender.getRecommendedList();
GenericRecommendedFilter filter = new GenericRecommendedFilter();
filter.setUserIdList(userIdList);
filter.setItemIdList(itemIdList);
recommendedItemList = filter.filter(recommendedItemList);
// print filter result
for (RecommendedItem recommendedItem : recommendedItemList) {
System.out.println(
"user:" + recommendedItem.getUserId() + " " +
"item:" + recommendedItem.getItemId() + " " +
"value:" + recommendedItem.getValue()
);
}
}
</recommendeditem></string></string>
如果是仅使用一种推荐算法,也可以将所有的参数定义完整后使用 LibRec 提供的 RecommenderJob 类以及使用命令行来执行。具体使用方式请参阅 LibRec 文档。
小结
这篇文章细致的总结了 LibRec 项目中整个模块的规划以及每一个模块的功能构成,并最终演示了基于当前项目的模块进行推荐的完整代码。在整个模块的设计过程中,以易用,高内聚,低耦合为目标进行设计,力求使得 LibRec 项目可以成为一个高扩展的算法框架。从最终的执行结果来看,目前 LibRec 的结构完全满足了当初进行 2.0 版本研发时的所有需求。同时,在 LibRec 优良的模块化基础上,其内置的算法的丰富性,配置的灵活性,框架的易用性以及计算流程的清晰性使得 LibRec 成为推荐领域内不可多得的推荐平台。




