在关于深入挖掘性能的演讲中,Eric Brumer 解释了为什么内存往往是最关键的部件。尽管他探讨的是 C++ 开发,但是很多建议都可以应用于托管代码。
高速缓存概观
在 Intel 的 Sandy Bridge 架构中,在 4 核心的 CPU 上,一个核心有 6 条流水线,也就是每个周期内可以处理多达 6 条指令。每个核心内还有 64kB 的 L1-cache 和 256 kB 的 L2-cache,用作指令和 / 或数据的高速缓存。L3-cache 为 4 个核心共享,根据模型的不同,大小从 8MB 到 20MB 不等。
从 L1-cache 中读取 1 个 32 位长的整数需要 4 个指令周期,从 L2-cache 中读取则需要 12 个指令周期,计算一个数的平方根也需要这么多时间。L3-cache 则需要两倍多的时间——26 个指令周期。从内存中读取更是相当相当长了。
数据访问模式
在开始讨论数据访问模式之前,Eric 先拿出了这个空间局部性(spatial locality)很差的矩阵乘法的经典例子,并给出了其解决方案:
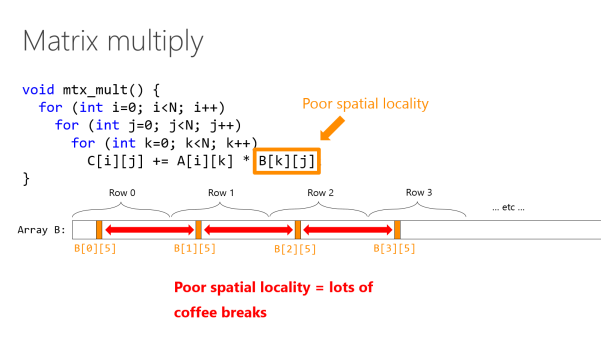
在比较强大的系统上,交换循环变量 j 和 k 就能带来 10 倍的性能改进。在低功率的桌面计算机上,性能改进高达 18 倍。需要重申的是,实际上主体代码并未改变,我们只不过修改了一下循环变量的顺序。
另请注意,Visual Studio 2013 的发布版本有望识别并修正这类例子。这需要改进数据依赖分析引擎,不过前几天发布的预览版本还没有做好准备。
多核的影响
假设有两个数组,每个数组中都保存着 400 万个 float 值,然后将它们按元素相加,保存到第 3 个数组中(即 c[i] = a[i] + b[i]; i = 0…3 999 999)。Eric 在搭载了 40 个核心的处理器上进行了测试。理论上,该计算很容易扩展,可以并行地将其放到 5 个核心上,速度就能提升到原来的 5 倍。但是 Eric 发现速度只提升到了原来的 1.6 倍(扩展率是 32%)。当所用核心数增加到 10 个时,速度是原来的 2.4 倍,扩展率只有 24% 了。
回顾实验结果,他发现所有的时间都花在了内存装载上。三个数组总共有 48MB,超过了 10 核心 CPU 所提供的 30 MB 的 L3-cache。将负载放到两个 CPU 上,并将计算并行地放到 20 个核心上,L3-cache 达到了 60MB。这次速度提升到原来的 18 倍,扩展率为 90%。
Eric 继续说道,实际上核心的数目无关紧要,起作用的其实是高速缓存的大小。他解释说,这个例子有点极端。对大多数程序而言,当相关的线程运行在同一 CPU 上时速度会更快,这是因为它们更容易共享高速缓存。但是这个例子和我们的想象完全相反,标准并行库带来了不利的影响。
向量代码
在下面的例子中,Eric 演示了一个粒子物理问题,该问题中有 4096 个元素相互作用,粒子之间的引力可以按照万有引力公式计算。使用标准的循环程序来计算,每秒可以运行 8 帧。利用 Visual C++ 的自动向量化和 128 位 SSE2 指令,循环迭代次数从 4096 减少到 1024,帧率提升到 18。256 位的 AVK 指令则可将迭代次数减少到 512,但帧率只提升到 23。
后来发现,原来是数据组织的问题。对每个粒子而言,其位置数据在给定的一帧内不会变化,还与要计算的加速数据混到了一起。要装载保存了 8 个粒子的 X 坐标的 256 位 YMM 寄存器,需要执行 9 条独立指令。装载 Y 坐标和 Z 坐标还需要 18 条指令。

重写这段代码使 X、Y 和 Z 三个坐标分别保存到一个单独的连续数组中,这超出了我们的研究范围。因此 Eric 进行了简化,他把它们复制到 3 个临时数组中,运行主循环的一个修改版本,然后将数据复制了回去。

仍然使用 256 位的 AVK 指令,这些额外的内存复制实际上改进了性能,帧率达到 42。应该注意的是,这一改进——即帧率从 8 提升到 42——是在一台搭载单核处理器的笔记本上实现的。
内存对齐
下一个问题是内存对齐。在 L1-cache 中,每一行长 64 字节。如果数据结构的长度都是缓存行长度的因子(比如长 32、16、8 或 4 字节),那就可以直接将其放入缓存行中,而不会浪费空间。不过这要求数据结构按照 64 字节对齐。
回到前面的例子,Eric 修改了一下代码,跳过数组的第一个元素,强制进行非对齐访问。结果与 j 从 0 开始相比,性能损失了 8%。
按照 C 语言标准,malloc 返回的数据只需要按 8 字节对齐。可以使用 _aligned_malloc 获得按 32 字节或 64 字节对齐的内存。我们正在进行相关开发工作,希望数据用于循环体之内时,编译器自动调用 _aligned_malloc,但是这也存在增加内存碎片的风险。我们希望在 VS 2013 Update 1 版本中提供些相关的新特性。
如果要更详细地了解这些内容,并要学习与内存有关的其他性能问题,可以观看 Build 2013 的视频:“ Native Code Performance and Memory: The Elephant in the CPU ”。




