

当我们想将一个单机的 tensorflow 训练程序改写成分布式训练(多机多卡)的时候,一般有两个大方向的选择:1.完全异步的梯度更新策略,其代表方法是 parameter server 架构。2.同步的梯度更新策略,代表方法有:百度的 ring all-reduce 策略。本文首先介绍 parameter server 架构。
parameter server 策略:
parameter server 异步更新策略是指每个 GPU 或者 CPU 计算完梯度后,无需等待其他 GPU 或 CPU 的梯度计算(有时可以设置需要等待的梯度个数),就可立即更新整体的权值,然后同步此权值,即可进行下一轮计算。
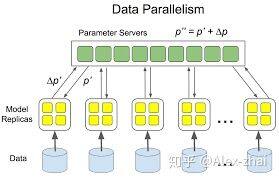
parameter server 的架构
而 Tensorflow 一开始支持分布式的时候,便是这种 parameter server 架构。TensorFlow 一般将任务分为两类 job:一类叫参数服务器,parameter server,简称为 ps,用于存储可训练的参数变量 tf.Variable;一类就是普通任务,称为 worker,用于执行具体的计算。
Tensorflow 支持两种方式实现 parameter server:低阶 API 创建 parameter server 集群方式和 tf.distribute.Strategy 中的 ParameterServerStrategy。
低阶 API 创建 parameter server 集群
完整案例 dist_tf.py:
对于本例而言,我们需要在对应的 5 台机器上分别运行每个任务,共需执行五次代码,生成五个任务。
低阶 API 创建 parameter server 集群缺点:
概念多,学习曲线陡峭。
单机代码到多机修改的代码量大。
需要多台机子跑不同的脚本,当然这可以通过 k8s 集群管理工具来解决。
PS 和 Worker 的比例不好选取。(建议选取偶数个的 ps,我的经验是 ps 和 worker 的比例是 1:3)
训练速度性能损失较大。(通信代价较高)
parameter server 常见的优化点:
如果有参数量较大的 embedding 变量时,可选择使用 embedding_lookup_sparse_with_distributed_aggregation 函数替代 tf.nn.embedding_lookup_sparse 函数。该函数可将 embedding 的聚合计算都放在变量所在的 PS 端,计算后转成稠密张量再传送到 Worker 上继续网络模型的计算。
tf.device 函数中有一个参数是设置变量在 ps 端放置策略的,可使用 tf.contrib.training.GreedyLoadBalancingStrategy 来替代默认的轮循。优点是:可根据参数的内存字节来完成类似在线垃圾收集的工作。根据 weight 和 bias 的字节数来放置到内存合适的 task 中,带来更好的负载平衡。
当参数有超大量级时(比如 embedding 参数),可在创建变量的时候使用分割变量策略:partitioner=tf.fixed_size_partitioner(ps_nums)
优化 input pipeline。链接:https://www.tensorflow.org/guide/performance/datasets
bandwidth 高带宽范亲和策略,保证多个 ps 分布在不同的物理机上。
Estimator 中的 ParameterServerStrategy 策略
需要每个机器配置 TF_CONFIG 环境变量
本文转载自 Alex-zhai 知乎账号。
原文链接:https://zhuanlan.zhihu.com/p/69010949

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论