
本文要点
- 事件溯源技术用于可靠地更新状态并发布事件,它突破了其它解决方案的局限。
- 在事件驱动架构中使用事件溯源,该设计理念可很好地与微服务架构匹配。
- 通过组合特定时间点上的所有事件做聚合查询时,使用快照可以改进性能。
- 事件溯源对查询提出了挑战,借助于 CQRS 指南和物化视图可以克服这些挑战。
- 事件溯源和 CQRS 无需任何特殊的工具或软件,有很多已有框架在一定程度上补全了底层功能。
在第一部分中,我们介绍了领域模型、事务、查询与功能分解之间的相互抵触是我们使用微服务架构的最主要障碍。前文所给出解决方法是将每个服务的业务逻辑实现为一系列DDD 聚合,每个事务更新或创建一个独立的聚合,使用事件维护聚合(还有服务)间的数据一致性。
在第二部分中,我们将介绍聚合的自动更新和事件发布,这是使用事件的主要挑战所在。我们将给出通过事件溯源解决这类问题的方法。事件聚合用于业务逻辑的设计和持久化,是一种以事件为中心的方法。然后我们会介绍微服务是如何让查询变得难以实现的,并给出一种称为命令查询职责分离(CQRS,Command Query Responsibility Segregation)的方法。CQRS 可以实现可扩展且高效的查询。
可靠的状态更新和事件发布
使用事件维护聚合间的一致性从表面上看是非常直接的方法,因为服务在创建或更新了数据库中的聚合时只是发布了一个事件。但是这里存在一个问题,就是必须要原子地完成数据更新并发布事件。否则如果一个服务在更新数据库之后还没来得及发布事件就崩溃了,那么系统将依然会保持不一致的状态。传统的解决方案是使用分布式事务,分布式事务涉及了数据库和消息代理。但是正如我们在第一部分中所介绍的那样,两阶段提交并非一个有效的方法。
有一些方法可以不使用两阶段提交解决这个问题。图1 显示了其中的一种解决方法。该方法让应用通过将事件发布到 Apache Kafka 这样的消息代理执行更新,由订阅了消息代理的消息消费者对数据库做最终更新。该方法能保证了数据库更新和事件发布。但是缺点在于该方法实现了一种更为复杂的一致性模型,应用不能立刻读取自己所写入的数据。
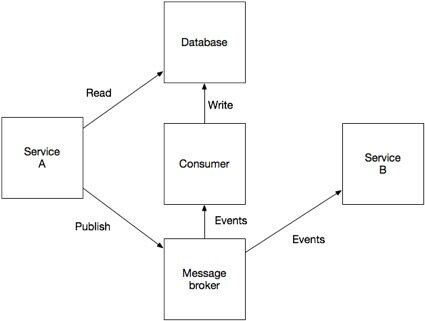
图 1 通过发布到消息代理来更新数据库。
图 2 给出了另一种解决方法。该方法让应用实时跟踪数据库事务日志(也称为提交日志),将日志中记录的每次变更转化为事件,并将事件发布到消息代理。该方法的主要优点在于无需任何对应用做更改,缺点在于难以反向工程成高层的业务事件,这些事件虽然与数据库更新有关,不过将底层的变更转化成表中的数据行并不容易。
(点击放大图像)

图2 实时跟踪数据库交易日志
图3 给出了第三种解决方法。该方法使用数据库表作为临时消息队列。服务在更新了聚合后,就将事件作为本地ACID 事务的组成部分插入到名为EVENTS 数据库表中。EVENTS 表被一个独立的进程轮询,该进程将事件发布到消息代理。该方法的优点之一是服务可以发布高层业务事件,而不好的一面是该方法容易出错,因为事件发布代码必须与业务逻辑同步。
(点击放大图像)

图 3 使用数据库表作为消息队列
以上三种方法都有显著的缺点。发布到消息代理再做更新的方法并未提供读自写(read-your-writes)一致性。实时跟踪事务日志的方法提供了一致读,但是发布的业务事件不会总是高层业务事件。使用数据库表作为消息队列的方法提供了一致读并可发布高层业务事件,但是该方法依赖开发人员实现状态变更即发布事件的机制。幸好还有另外一种解决方法,即以事件为中心实现持久化和业务逻辑的方法,称为事件溯源。
使用事件溯源开发微服务
事件溯源是一种以事件为中心实现持久化的方法。事件溯源并非一个新理念。我在五年多前就听说过事件溯源,但是直至我着手去开发微服务时,它依然是一个新奇事物。下面你们将会看到,事件溯源是一种实现事件驱动微服务架构的好办法。
使用事件溯源的服务将每次聚合持久化为一系列的事件。在创建或更新一个聚合时,服务将一个或多个事件保存在数据库中,这时我们也将数据库称为事件存储。事件溯源通过加载并回放事件,重建了聚合的当前状态。在函数式编程理念中,服务通过对事件执行 reduce(在函数式编程中多称为 fold)操作重建聚合的状态。因为事件就是状态,自动更新状态和发布事件的问题不再存在。
回到上文的例子,Order 服务并非将每个订单都作为 ORDERS 表的一行数据,而是持久化每个 Order 聚合为一系列的事件,保留“Order Created”、“Order Approved”、“Order Shipped”等事件。图 4 显示了这些事件在基于 SQL 的事件存储中的存储情况。
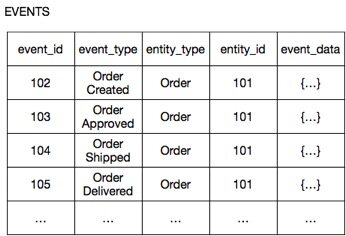
图 4 使用事件溯源持久化 Order 服务。
表中各列的意义如下:
- entity_type 和 entity_id 列:用于标识聚合。
- event_id:标识事件。
- event_type:事件类型。
- event_data:序列化成 JSON 的事件属性。
一些事件中包含了大量的数据。例如“Order Created”事件就包括了全部订单,其内容涉及订单的单项产品、支付信息和快递信息等。而 Order Shipped 等事件包含了少量数据甚至不包含数据,这些事件只是表示状态的转移。
事件溯源和事件发布
严格意义上讲,事件溯源仅是将聚合持久化为事件,但是将事件溯源作为可靠的事件发布机制使用也是非常简单的。保存事件在本质上是一个原子的操作,它确保了事件存储将向感兴趣的服务交付事件。举个例子,如果事件存储于上文所介绍的 EVENTS 表中,为了处理新的事件,订阅者可以直接去轮询 EVENTS 表。更为复杂的事件存储将使用到另一种方法,该方法具有相似的一致性保证,但是具有更高的性能和扩展性。例如, Eventuate Local 使用事务日志进行实时跟踪,从 MySQL 的复制流中读取插入到 EVENTS 表中的事件,并将这些事件发布到 Apache Kafka。
使用快照改进性能
Order 聚合具有相对较少的状态转移,因此它只有少量的事件。在事件存储中查询这些事件并重建 Order 聚合是很高效的。不过有些聚合会包含大量的事件。例如 Customer 聚合可能包含大量的 Credit Reserrved 事件。久而久之,在这些事件上的 load 和 fold 操作将会日渐低效。
一个常用的解决方法是将聚合状态周期性地持久化为快照。通过加载最近的快照以及仅在快照创建后发生的事件,应用可以恢复聚合的状态。从函数式编程的角度看,快照是 fold 操作的初始值。如果聚合具有一个易于序列化的基本结构,那么就可以使用它的序列化格式作为快照,比如 JSON。更为复杂的聚合可以通过使用备忘录模式(Memento pattern)形成快照。
在网店例子中,Customer 聚合具有一个非常简单的结构,其中包括客户信息、客户的信用额度以及客户的信用余额。Customer 聚合的快照仅是该聚合状态的JSON 格式。图5 显示了如何从Customer 快照中重新创建一个Customer,这个快照所对应的是Customer 在发生#103 事件时的状态。Customer 服务只需加载该快照和事件#103 之后发生的事件。
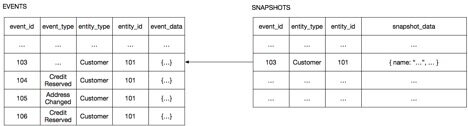
图5 使用快照优化性能。
通过反序列化快照的JSON,Customer 服务可以重建Customer 聚合,然后可加载并应用从#104 到#106 的所有事件。
实现事件溯源
事件存储是数据库和消息代理的混合体。将事件存储看作是一个数据库,因为它具有通过主键插入和检索聚合事件的API。另一方面,事件存储也是一个消息代理,因为它具有订阅事件的API。
事件存储有一些不同的实现方法。一种方法是编写你自己的事件溯源框架。例如可以在RDBMS 中持久化事件。订阅者通过轮询EVENTS 表找到事件,这种事件发布方法简单,但是低效。
另一种方法是使用专用的事件存储,这些专用的事件存储通常会提供丰富的特性、更好的性能和可扩展性。事件溯源的先行者Greg Young 就提供了一个基于.NET 的开源事件存储,称为“ Event Store ”。他所创立的公司以前称为 Typesafe,提供一种称为 Lagom 的基于事件溯源的微服务框架。我的初创公司 Eventuate 也以云服务形式提供了一种用于微服务的事件溯源框架,该架构是基于 Kafka/RDBMS 的开源项目。
事件溯源的优缺点
事件溯源具有其优缺点。一个主要优点是无论聚合的状态如何改变,事件溯源都能可靠地发布事件。这为事件驱动微服务框架提供了很好的基础。此外,因为每个事件都可以记录做用户的标识信息,所以事件溯源提供了准确的审计日志。事件流可用于很多其他的目的,包括向用户发送通知以及应用集成。
另一个优点是事件溯源存储了每个聚合的完整历史。你可轻易地实现基于时间的查询,去检索聚合的历史状态。为确认特定时间点上的聚合状态,你只需对到该时间点为止所发生的事件做 fold 操作。例如,可直接实现计算过去某个时间点上客户的可用信用额度。
事件溯源也在很大程度上避免了 O/R 阻抗匹配问题。这是由于它持久化了事件而非聚合。事件通常具有简单的、易于序列化的结构。通过将聚合状态序列化为备忘录,服务可以对复杂聚合进行快照。备忘录模式在聚合及其序列化之间添加了一个中间层。
当然,事件溯源也并非“银弹”,它也存在一些缺点。事件溯源是一种不为人所熟悉的编程模型,因此存在一定的学习曲线。对于已有应用,为使用事件溯源,你必须重写已有应用的业务逻辑。好在这是一个相当机械化的转换过程,可以在将应用迁移到微服务时完成。
事件溯源的另一个缺点是消息代理通常保证至少一次交付。非幂等的事件处理器必须检测并丢弃重复的事件。通过赋予每个事件一个单调递增的标识符,可使事件溯源框架发挥作用。然后事件处理器可以通过追踪最大事件的标识符去检测重复的事件。
事件溯源的另一个挑战是事件的模式(以及快照!)会随时间演化。因为事件是永久存储的,在重建聚合时,服务可能需要对多个模式版本对应的事件做 fold 操作。一种简单的方法是让事件溯源框架在从事件存储中加载所有事件时,将所有的事件转换为最新版本的模式。最后,服务只需要对最新版本的事件做 fold 操作。
事件溯源的另一个缺点在于对事件存储的查询将面临挑战。例如,假设你需要找到信用额度较低但是信用良好的客户,仅是编写查询语句 “SELECT * FROM CUSTOMER WHERE CREDIT_LIMIT < ? AND c.CREATION_DATE > ?”并不能解决问题,因为并不存在包含信用额度的列。你必须使用更为复杂而低效的包含嵌套 SELECT 语句的查询来计算信用额度,通过对信用的初始值事件和调整事件做 fold 操作计算出来。此外,通常基于 NoSQL 的事件存储只支持基于主键的查找,这让事情变得更加糟糕。基于上述原因,实现必须要使用称为命令查询职责分离(CQRS,Command Query Responsibility Segregation)的方法。
使用 CQRS 实现查询
事件溯源是在微服务架构中实现高效查询的一个主要障碍,但并非是唯一的问题。例如,查找下过大额订单的新客户的 SQL 查询:
SELECT * FROM CUSTOMER c, ORDER o WHERE c.id = o.ID AND o.ORDER_TOTAL > 100000 AND o.STATE = 'SHIPPED' AND c.CREATION_DATE > ?
在微服务架构中,你不能在 CUSTOMER 和 ORDER 表间做连接操作。因为每个表属于不同的服务,只能通过服务的 API 来访问。你不能对属于不同服务的表编写传统查询实现连接查询。事件溯源会让事情变得更加糟糕,它会阻止你编写简单直接的查询。让我们看一下在微服务架构中实现查询的方法。
使用 CQRS
一种好的查询实现方法是使用称为“命令查询职责分离(CQRS)”的架构模式。正如其名字所示,CQRS 将应用分割为两个部分。第一部分是命令端的,用于命令处理(例如,HTTP POST、PUT 和DELETE),实现创建、更新和删除聚合。当然这些聚合是使用事件溯源实现的。应用的第二部分是查询端的,通过查询聚合的一个或更多的物化视图实现查询处理(例如HTTP GET)。通过订阅命令端服务的事件,查询端将保持视图与聚合的同步。
每个查询端视图可使用任何类型的数据库实现,只要该数据库对要求的查询提供良好的支持。根据需求不同,应用的查询端可使用一到多个下表所列的数据库:
表1 查询端视图存储
如果你需要……
可以使用……
例如……
基于主键查找JSON 对象
文档数据库,例如 MongoDB ,或者键值数据库,例如 Redis 。
通过维护包含客户订单的客户 MongoDB 文档实现订单历史。
基于查询查找 JSON 对象
文档数据库,例如 MongoDB。
使用 MongoDB 实现客户视图。
文本查询
文本搜索引擎,例如 Elasticsearch 。
通过维护每个订单的 Elasticsearch 文档,实现对订单的文本搜索。
图查询
图数据库,例如 Neo4j 。
通过维护客户、订单和其他数据的图结构实现欺诈检测。
传统的 SQL 报表 /BI
RDBMS
标准业务报表和分析报告。
使用 RDBMS 作为存储记录的系统,并使用全文搜索引擎来处理查询,比如 Elasticsearch,这种方式应用很广泛。从很多方面来看,CQRS 是这种方式的一般化实现,而且是基于事件的。CQRS 不仅限于文本搜索引擎,还可使用非常宽泛类型的数据库。此外,CQRS 可以通过事件订阅近乎实时地更新查询端视图。
图 6 显示了在网店例子中对 CQRS 模式的应用。Customer 服务和 Order 服务是命令端服务,提供了创建和更新 Customer 和 Order 的 API。Customer View 服务是查询端服务,它们提供查询 Customer 的 API。
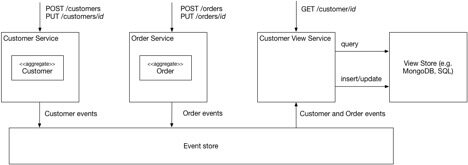
图 6 在网店例子中使用 CQRS。
Customer View 服务订阅了由命令端服务发布的 Customer 和 Order 事件。该服务更新由 MongoDB 实现的视图存储。服务维护了 MongoDB 所存储一系列文档,每个用户一个文档。每个文档中包括了客户细节信息的属性,还包括存储客户近期订单的属性。这一系列文档支持多种查询,包括之前所提到的查询。
CRQS 的优缺点
CQRS 有其优点,也有缺点。一个主要优点是 CRQS 使得在微服务架构中实现查询成为可能,尤其是使用事件溯源的微服务架构。CRQS 让应用可以高效地支持多种类型的查询。另一个优点是关注点的分离会简化应用的命令查询端。
CQRS 也存在一些缺点。其中的一个缺点是 CRQS 需要对系统的开发和操作做额外工作。你必须开发并部署那些更新和查询视图的查询端服务。此外,你还需要部署视图的存储。
另一个缺点在于 CRQS 需要处理命令端和查询端之间的“延迟”。正如你能想到的,命令端的更新在查询端生效会有一定的延迟。如果客户应用更新聚合后就立刻查询视图,该应用将看到前一个版本的聚合。在编写客户应用时,必须避免把这种不一致性暴露给用户。
总结
使用事件维护服务间数据一致性的主要挑战在于更新数据库和发布事件的原子性。传统的解决方案是使用跨数据库和消息代理的分布式事务。但是对于现代应用,两阶段提交并非可用的技术。更好的方法是使用事件溯源,事件溯源是一种以事件为中心的方法,用于逻辑设计和持久化。
查询是使用微服务架构中要面临的另一个挑战。通常查询需要连接属于多个服务的数据。但是由于数据对于服务是私有的,连接运算不可直接实现。由于当前的状态并非显式地存储,使用事件溯源也增加了查询的难度。解决方案是使用命令查询职责分离(CQRS,Command Query Responsibility Segregation),维护一个或多个聚合的物化视图。
 Chris Richardson是一位程序开发人员和架构师。他还是一名 Java 冠军程序员(Java Champion),同时也是《用轻量级框架开发企业应用》一书的作者。这本书的内容是关于如何使用 Spring 和 Hibernate 等框架去构建企业级 Java 应用。Chris 也是 CloudFoundry.com 的创始人。他还担任了一些企业的顾问,指导企业如何去改进应用的开发和部署过程。他目前正致力于发展他的第三个初创企业。读者可以通过 Twitter 账号 @crichardson 和 Eventuate 网站联系到 Chris。
Chris Richardson是一位程序开发人员和架构师。他还是一名 Java 冠军程序员(Java Champion),同时也是《用轻量级框架开发企业应用》一书的作者。这本书的内容是关于如何使用 Spring 和 Hibernate 等框架去构建企业级 Java 应用。Chris 也是 CloudFoundry.com 的创始人。他还担任了一些企业的顾问,指导企业如何去改进应用的开发和部署过程。他目前正致力于发展他的第三个初创企业。读者可以通过 Twitter 账号 @crichardson 和 Eventuate 网站联系到 Chris。
查看英文原文: Developing Transactional Microservices Using Aggregates, Event Sourcing and CQRS - Part 2
感谢薛命灯对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论