

本文最初发表于 Medium 博客,经原作者 Abhijit Patil 授权,InfoQ 中文站翻译并分享。
在本文中,我们将介绍使用原生 AWS 服务构建 ETL 流程的众多设计之一,以及如何集成这些设计来构建端到端数据管道。
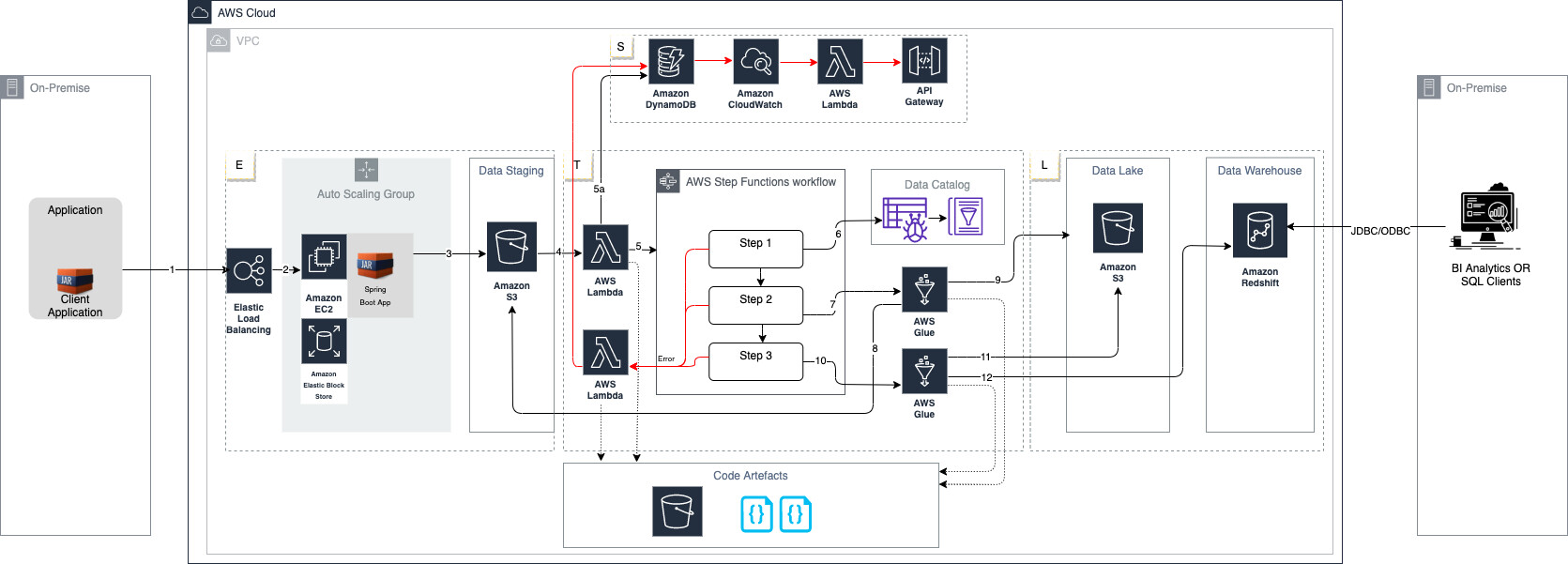
AWS 数据流(ETL)
在上图中,它代表了数据管道的四个主要方面,即数据摄取(Data Ingestion,E)、数据转换(Data Transformation,T)、数据加载(Data Load,L)和服务(Service,S)。
数据摄取(E)
在将数据从企业内部摄取到 AWS S3 中,还有很多其他模式。在这个流程中,我们代表了使用 HTTP 接口摄取数据的模式之一。其他模式可以使用 AWS 数据迁移服务,详情可参阅:https://aws.amazon.com/cloud-data-migration/。
a. 文件上传器 API
HTTPs API 使用托管在 EC2 上的 Spring boot 应用程序来上传/下载数据。这支持数据的多部分上传。
你可以使用 Spring boot 框架来编写文件上传器 API,并将其托管在自动伸缩的 EC2 上。要创建 Java 服务器端的文件上传器程序,请参考这个简单指南:https://spring.io/guides/gs/uploading-files/。
要让这个应用程序更具弹性,你可以将 ELB 和 Amazon EC2 Auto Scaling 添加到应用程序前面。
b. 数据移动到 S3
一旦收到数据文件,应用程序将暂时把数据保存在 EBS 卷中,然后使用 AWS SDK,可以把它移动到 S3 存储桶(Staging)。当数据移动到 S3 时,将会引发 S3 事件。通过该事件,可以触发 Lambda 函数,然后通过调用 Step 函数来触发 ETL 工作流。
注:S3 staging 存储桶将主要保存从源接收的原始数据。
数据转换(T)
强烈建议将可能是各种格式(如 JASON、XML、CSV 或任何其他格式)的原始数据转换成统一的数据格式,如数据湖(Data Lake)中的 parquet 格式。这样就能使数据湖的数据的标准化。
将按照下列高级步骤进行数据转换:
在 Step 函数工作流中,所有 ETL 转换阶段将被定义,一旦数据通过 Lambda 函数登陆到 staging S3 存储桶,该工作流就会被触发。工作流的第一阶段将是日期控制检查或业务日期检查,这将使用 Lambda 来完成,它在内部访问 DynamoDB,该数据库将存储日期控制和假日日历表。在上图中用箭头 4、5 和 5a 表示。在执行任何数据操作之前,Step 函数(状态机)的第一步是检查文件的完整性,例如校验和检查、行计数检查等,然后调用 Glue Crawler(爬网程序)来更新 Glue Catalog 中的模式,以获得新的数据。Step 函数的第二步将调用 Glue 作业,该作业将从 S3 存储桶的 staging 层读取数据,并将其转换为 parquet 格式,然后将最终的 parquet 文件写入 S3 持久层(数据湖)存储桶中。
注:一旦所有处理完成,可以调用相同的 Lambda 函数来更新 DynamoDB 中工作流的状态。
数据加载(L)
数据加载是将数据从持久层(数据湖)S3 存储桶加载到 Redshift 中。Redshift 将作为数据仓库或数据集市使用,用于定义域数据模型。
将按照下列高级步骤进行数据加载:
在成功完成 Step 函数的第二步后,将触发 Step 函数的第三步。Step 函数的第三步将触发另一个 Glue 作业(Glue Python shell 作业),它将执行 SQL(来自 Artefact 的 S3 存储桶),将数据从 S3 存储桶复制到 Redshift 表中。一旦数据加载完成,Lambda 将更新 DynamoDB 中工作流的状态。
注:在 SQL 函数中,你可以使用所有的业务逻辑。对于其他需要复杂转换的用例中,你可以调用 Glue Job 并调用 Java/Scala 代码。
错误处理与服务集成
在这种方法中,我们创建了一个通用的 Lambda 函数,如果 Step 函数中的任何步骤失败,就会调用这个函数。然后这个 Lambda 函数更新 Dynamo DB 审计表的状态。该 Lambda 函数参考了 S3 代码 Artefact 存储桶中的代码。
在 DynamoDB 审计表中的每一次插入都会生成一个触发器,该触发器将调用通用错误处理 Lambda,而该触发器又可以调用内部的 API,以提出服务工单(service ticket)或发送关于任何失败/警告的电子邮件。
设计中使用的工具/服务
我们主要使用以下 AWS 原生服务来实现数据管道:
AWS Lambda:这主要用于整合不同的服务。我们不建议在 Lambda 函数中加载大量的业务逻辑。在这个设计中,Lambda 被用于:
捕获 S3 文件生成事件。触发相应的 ETL 工作流程(Step 函数)。捕获 DynamoDB 表中的审计信息。如果需要,触发其他依赖性的 AWS 服务,如 Glue Crawler,Athena 查询,API 网关等。
AWS Step 函数:这是一个简洁的图形化表示,用来定义作业的子任务的相互依赖关系。
帮助定义/执行工作流中特定数据文件的不同任务。不同的任务可以是胶水作业(glue job)或 Lambda 函数。
AWS Glue Job:这主要用于计算/转换作业。
从 S3 staging 层存储桶中读取数据。将数据文件转换为 parquet 格式。触发 Redshift 的 SQL 查询,将 S3 存储桶加载数据或从 S3 存储桶卸载数据。
AWS DynamoDB:在这个设计中,我们用来保存与 ETL 作业相关的元数据,并维护作业执行的审计。这有助于维护 ETL 管道元数据。ETL 管道元数据可以是:
每个数据文件的日期控制信息;
每个数据文件的假日日历信息(工作流/Gluejob);
胶水作业依赖性的元数据;每个数据文件/工作流/胶水作业的审计信息。
AWS Redshift:用于定义域数据模型,在该模型中可以建立 Star 或 snowflake 模式来表示事实和维度。
这将主要用于创建数据仓库/数据集市。
https://aws.amazon.com/cloudwatch/:用于监控作业的执行情况并发出警报。
捕捉跨不同工作流和 AWS 服务的日志信息。在出现错误/警告等情况下生成 CloudWatch 事件/警报。
调用企业内部的 API 来发送任何操作事件/信息,如故障、警告、操作统计等。
Amazon EC2/EBS:
托管文件上传器应用程序和服务,将数据传输到 S3。EBS 将作为文件上传器应用程序的存储平台,并临时存储数据文件。
总结
这是在 AWS 上实现数据管道的一种方法,通过设计和使用无服务器或托管服务的 AWS 原生服务,可以实现弹性。
作者介绍:
Abhijit Patil,云数据工程和架构总监,擅长构建企业规模的产品和服务,在各种技术和金融领域拥有 20 多年的丰富经验。
Hukumchand Shah: 工程副总裁,专业从事云数据工程,大数据、微服务、领导力和健康爱好者。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论