
在 1.5 版发布了 2 个半月之后,Pivotal发布了 Spring Cloud Data Flow (SCDF)1.6,该项目用于构建和编排到运行时的实时数据处理管道(如 Pivotal Cloud Foundry,简称 PCF;Kubernetes 和 Apache Mesos)的项目,具有以下新功能:
- 新的 PCF 任务调度程序
- 控制面板的改进
- Kubernetes 支持的增强
- 新的应用程序托管工具和本地存储库
我们在这里对其中一些新功能进行了检测。
入门
与 SCDF 以前的版本一样,此快速入门指南展示了如何用docker-compose 实用工具启动该新版本:
DATAFLOW_VERSION=1.6.1.RELEASE docker-compose up
建立后,可以通过 http://localhost:9393/dashboard 在本地访问 SCDF 控制面板。
任务调度
由于将原生 PCF 调度程序集成到了 Cloud Foundry 的 SCDF ,任务定义可以通过 cron 表达式用 SCDF 安排调度和取消调度了。PCF 调度程序是处理像数据库迁移和 HTTP 调用等任务的服务。开发人员可以创建、运行和调度作业及查看历史。调度程序可以通过 SCDF 控制面板上的 Tasks 菜单访问。

SCDF 应用程序托管工具
另外,1.6 版的新功能是 SCDF应用程序托管工具,用 Spring Shell 构建而成,旨在构建和维护本地网络上的独立 SCDF应用程序存储库,针对的是开发人员在防火墙后面运行SCDF 的情况,例如,无法访问 Spring Maven 存储库的时候。应用程序托管工具 scdf-app-tool,可以通过源代码或下载二进制文件进行构建。
启动后,应用程序托管工具启动一个 REPL,其初始提示为:binder-undefined:>,表示需要定义一个流应用程序。以下所示的是,在调用帮助命令时,该工具可以使用的命令。
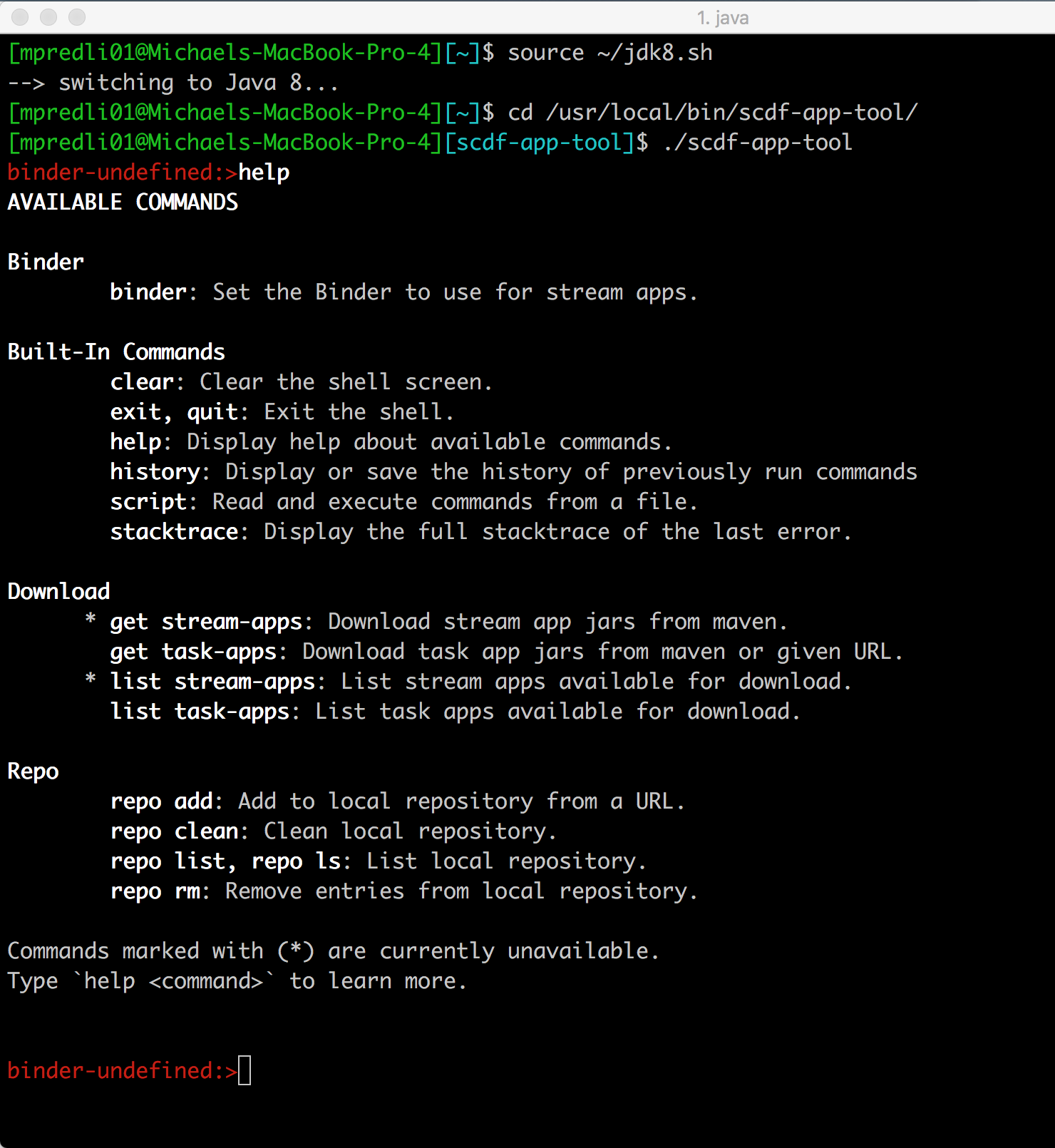
请注意:get stream-apps 和 list stream-apps 这些命令在此时是不可用的。只要用如下所示的 binder 命令定义了流应用程序,就可以使用这些命令了。支持的绑定器有 kafka、kafka-10 和 rabbit,但是,重要的是,用于 binder 命令的 kafka 参数是 kafka-10 的别名。
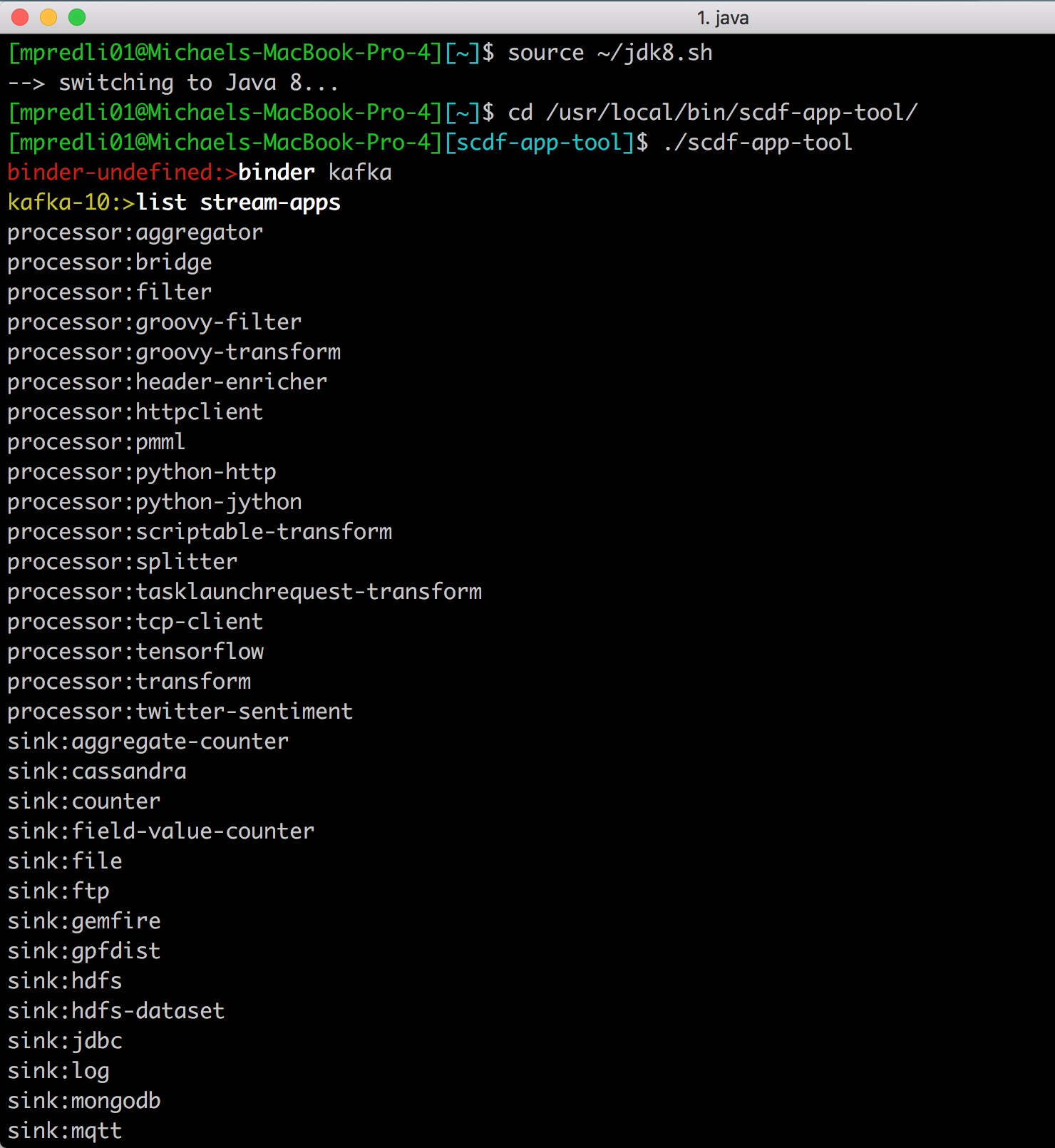
请注意:提示变成 kafka-10:> 的时候,可以调用 get stream-apps 和 list stream-apps 命令。
SCDF 应用程序存储库
SCDF应用程序存储库(Spring Boot 应用程序)是一个基于web 的存储库,用于构建流和任务应用程序以注册和部署应用程序而无需外部Maven 存储库。该应用程序存储库(scdf-app-repo)位于scdf-app-tool 的配置目录下面,可以按下面的步骤构建:
$ cd config/scdf-app-repo $ ./mvnw clean package
该应用程序存储库可以部署到云平台或在本地运行:
$ java -jar target/scdf-app-repo-0.0.1-SNAPSHOT.jar
开始运行后, 可以通过 http://localhost:8080/repo/ 在本地访问存储库上的托管工件。
Pivotal 的高级工程师 Mark Pollack 向 InfoQ 介绍了该最新版本。
InfoQ:是什么使得 Spring Cloud Data Flow 有别于其他实时数据处理管道?
Pollack:Spring Cloud Data Flow 是个轻量级的 Spring Boot 应用程序,它提供数据集成工具包,分别把 Spring Cloud Stream(SCSt)和 Spring Cloud Task(SCT)微服务应用程序组合编排成一致的实时流和批量数据管道。实时流应用程序可以使用各种中间件产品,如 Kafka KStreams、RabbitMQ 和谷歌的 Pub-Sub。所有这一切基于的都是 Spring Boot。从编程模型到测试、CI/CD 和这些应用程序在云平台(如 Cloud Foundry 或 Kubernetes)上的运维都是一致的。
尽管市场上有很多流媒体平台和实时分析解决方案,但从架构上来说,我们对数据处理工作负载的云原生方法是独一无二的,其中用于流媒体应用程序的 CI/CD 是一等公民。在这种程度上,数据处理逻辑(也即,Spring Boot 应用程序)可以对实时流量模式做出反应,通过不中断上游或下游数据处理而自动扩展或滚动升级来完成。
InfoQ:Spring Cloud Data Flow 即将发布什么?
Pollack:Spring Cloud Data Flow 横跨生态系统中的多个项目,其中每个项目有独立的待办和发布节奏。
我们的主要目标是,在构建实时流和批量数据管道时,提高开发人员的工作效率。尽管添加新功能改进流流体和批量编程模型是最优先考虑的,但我们也密切关注在云平台(如 Cloud Foundry 或 Kubernetes)方面的运营改进。
一些值得注意的功能:
在 Kafka 和 Kafka Streams 生态系统上持续投资,以促进状态存储(State Storages)和交互查询(Interactive Queries),并保持云原生实践的完整性。
批量 / 任务负载通常基于重复的节奏或 cronjob 进行调度。Cloud Foundry(通过 PCF 调度程序)和 Kubernetes 的实现(基于 CronJob 规范)尚在开发。
可用性是个重点。控制面板有大量的改进,包括编排机制、交互性和整体的观感及体验。
对于我们的很多客户来说,安全性仍然是首要的,对我们的团队来说,也是如此。Streams 启动任务的其他安全功能以及对组合任务功能的支持是即将发布的版本的目标。还有审计跟踪功能也将在下一个版本中发布,以解答“谁在何时做了什么?”的问题。
我们还积极推动下一代数据处理工作负载的设计。我们的基金会今天围绕着 Spring Boot uber-jar,而明天可能就是些复古简单的 Function jar 了。Spring Cloud Stream、Spring Cloud Function 和 Spring Cloud Stream App Starter 都从整体目标、设计和架构角度重新进行了评估。
尤其是,PCF 的 Spring Cloud Data Flow 自动化了 Cloud Foundry 中的配置方面以及端到端 SSO 的深度安全模型。有兴趣继续优化该图块以加强开发人员和操作人员与 SCDF 进一步的互动。
InfoQ:您目前的职责是什么?也就是,您的日常工作是什么?
Pollack:作为团队的领导,每件事我都会做一点。我帮助定义路径图、做些功能开发、维护、验收测试、发布管理和客户支持。我也尝试在 Robotron 中获得更高的分数。
参考资料
Baeldung 的用Spring Cloud Data Flow 进行流处理的入门(2018 年4 月4 日)
查看英文原文: Pivotal Releases Spring Cloud Data Version 1.6 Featuring a New App Hosting Tool
感谢冬雨对本文的审校。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论