看新闻很累?看技术新闻更累?试试下载 InfoQ 手机客户端,每天上下班路上听新闻,有趣还有料!

论文原文地址:
https://arxiv.org/pdf/1805.03832.pdf
据滴滴语音团队介绍,该模型已经在滴滴相关语音产品中上线,替代了基于长短时记忆单元(LSTM)和连接时许分类(CTC)的语音识别系统,取得了 15%~25% 的相对性能提升。滴滴语音团队同时指出,虽然在实际应用产品中,基于 attention 的语音识别取得了显著的性能提升,但仍然有很多问题需要进一步探索。比如在基于 5000 多常用汉字的系统中,可以通过后处理模块从一定程度上解决集外词问题,但相较于基于音素的 CTC 系统而言,在集外词部分却还存在一定的差距。此外针对中英文混合的情况,如何有效地实现中文和英文部分的统一建模,在 attention 系统中依然是个需要深入研究的课题。
以下是对滴滴 attention 端对端语音识别系统的详细解读。
语音识别历史,从 CD-DNN-HMM 到端到端语音识别
近些年来,伴随着深度学习技术的发展,语音识别技术也经历了革命性的变化,基本可以概括为以下三个阶段:
- 基于 DNN-HMM(深度神经网络 - 隐马尔科夫模型)的语音识别
- 基于 CTC(连接时序分类)的端对端语音识别
- 基于 Attention 的端对端语音识别
从 2010 年开始,Dong Yu 以及 Li Deng 等学者首先尝试并提出了基于 CD-DNN-HMM 的声学模型,在大词汇量连续语音识别任务上取得成功,相比于传统的 GMM-HMM 系统可以获得超过 20% 的相对性能提升 [1]。此后大量的研究人员投入到基于深度神经网络的语音声学建模研究中,语音识别取得了突破性的进展。同时,研究者们也在尝试打破基于 HMM 的主流语音识别框架。
伴随着 LSTM 等循环神经网络(RNN)等技术的成功,基于深度学习的端对端建模技术逐渐在学术界和工业界中得到了关注,其中一个经典的算法就是 CTC 算法。在基于 LSTM-CTC 的建模框架中,CTC 替换了 HMM 结构,深度学习技术实现了对语音整个序列的建模,而非仅仅是状态的静态分类。2015 年起, Google、百度等公司已经使用 CTC 模型取得了比传统混合识别系统更好的性能 [2]。目前,基于 CTC 的识别系统已经在多个公司语音产品上广泛应用,已经成为了工业界主流语音识别系统。在滴滴语音团队,在 CTC 语音识别系统技术上,也一直在寻求语音识别技术的下一个突破口。
深度学习技术一直在飞速发展着,从深度学习技术的发展中汲取营养,也一直是语音识别技术取得突破的途径。近些年来,在机器翻译领域,基于 Attention 技术的端对端翻译技术被提出,并很快在大规模的工业系统中得到了应用。在 2017 年,Google 上线了 GNMT(Google Neural Machine Translation)系统 [3],该系统基于 Attention 技术实现了端对端的深层神经网络建模,大幅提升了机器翻译的性能。最近两年大家对 attention 机制的 seq2seq 语音识别模型的研究也取得了大幅的进展,在刚结束的 ICASSP 2018 国际学术会议,谷歌公司已经在基于 attention 机制的 seq2seq 英语语音识别任务上,取得了超过其它语音识别模型的性能的表现 [4]。
对于基于注意力机制的 seq2seq 框架中,语音识别任务被定义为不定长的语音序列到不定长的文本序列的 seq2seq 的转换,同时结合注意力机制,可以通过单个模型,直接学习到语音序列到文本序列的转换过程,其实现了声学信息和语言信息联合学习的功能。因此,其相较于 CTC 模型,对语言模型的依赖更小,甚至可以不需要语言模型。然而,经典的 seq2seq 模型需要以完整的一句语音作为输入,其输出时延相比 CTC 模型会大很多;为了能够满足实时识别,可以采用 Neural Transducer[5] 的方案,通过把一句话切分为固定长度的语音段的方式,有效减少识别时延。
其实在语音识别任务中,所谓的端对端也是一个相对的概念。如下图所示,以汉语语音识别为例:
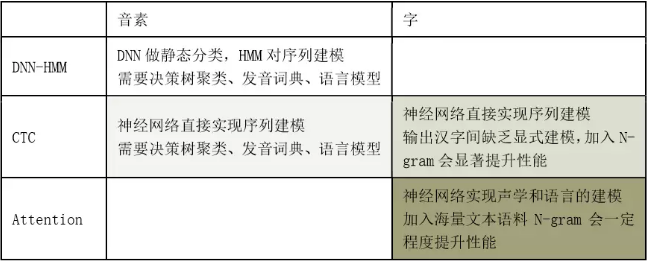
其中 CTC 系统相对 HMM 系统而言,更加地端对端。而基于字的 attention 系统相对于 CTC 系统而言,则可以实现在不加入 N-gram 的情况下也得能够非常好的性能。
滴滴中文 LAS:以 5000 个常用汉字为建模单元
滴滴基于注意力机制的端到端系统建立在 LAS 端到端架构上,此模型框架最早是由 William Chan 等人提出的 [6]。LAS 架构主要由 3 个部分组成,分别是 Listener(Encoder)、Attender、Speller(Decoder)。
Encoder 的功能与传统的声学模型类似,接收输入语音的特征序列 X={x_1,x_2,…,x_t},并将输入映射到一个更高级的特征表示 h^enc, Encoder 通常采用多层循环神经网络的网络结构。Attender 接收 Encoder 传递过来的高层 h^enc,并用来学习输入特征和模型最后输出序列 Y={y_1,y_2,…,y_n}之间的对齐信息。最后,Attender 模块的输出到 Decoder。Decoder 按照链式法则, 结合之前 Decoder 预测的输出、Attender 的输出及 Decoder 自身的网络信息,产生出输出词序列的概率分布。

LAS 模型是一个完整的神经网络系统,其可以实现完整的语音序列到对应的文本序列的转换过程,因此,其训练及使用相比传统模型来说要简单很多。训练时,不需要像传统模型那样把系统区分为单独的模块分别进行训练。同时,由于不需要对齐信息,可以直接使用句子的语音特征序列及与其对应的文字标注序列来进行整个完整模型的训练。为了更好的训练 LAS 模型,滴滴语音团队在训练的时候尝试了各种技巧,包括 schedule sampling、label smoothing、multi-head attention 等。
考虑到滴滴语音的应用场景,滴滴语音团队重点针对汉语语音识别的 attention 建模展开了研究,尤其是其建模单元的研究。针对 attention 的汉语语音识别而言,可考虑的建模单元包括音节和汉字。为了得到了最为完整的结果,滴滴基于海量数据库和自身强大的 GPU 机群,通过大量的模型调参工作,最终发现基于大约 5000 多个常用汉字作为基本建模的 LAS 系统能够得到显著优于 CTC 系统的识别性能 [7]。
在解码的时候,直接使用 beam search 来解码。考虑到可以较容易地获得大量的文本语料,而通常情况下这些语料都是没有对应的语音的,在滴滴的 LAS 系统中,滴滴依然融合了基于海量文本语料训练的 N-gram。在最终的线上系统中,滴滴得到了两点发现。
第一,在 LAS 中文字模型中,beam size 可以比传统语音识别模型小很多。在传统的基于 HMM 框架的语音识别中,由于其模型的不确定性,为防止过早裁剪了最优序列,在解码过程中常常会保留数千条可能路径。而在基于 CTC 框架的语音识别中,由于 CTC 模型输出中有大量 blank,从而可以根据 blank 特性对解码路径约束,从而一定程度上提速解码,但一般依然会保留数千条可能路径。而在滴滴的 LAS 框架中,只需要保留个位数(如 4 或者 8)的可能路径,就能得到最优的识别结果。可能候选路径从数千降低到个位数,一方面带来的解码器框架的大大简化,也带来了实际线上系统的解码速度的大幅提升。
第二,解码过程中,滴滴发现 N-gram 语言模型的最优权重非常低,通常都在 0.1~0.3 之间。作为对比,在 HMM 框架中,N-gram 语言模型的权重一般都是 10-20 之间,在 CTC 框架中,N-gram 的权重一般都在 1.0~2.0 之间。可以看到,LAS 对语言模型的依赖相比传统模型低很多,甚至在有的产品任务中,可以不需要使用语言模型。
从另外一个角度来看,语音识别的研究,从 HMM 到 CTC,再到 Attention,其演进过程是一直伴随着的思路就是如何通过一个神经网络模型实现更多地对语言模型层面的刻画。换言之,则是不断地尝试更好的建模框架取代 N-gram 这样的纯基于统计的建模方法。
在滴滴中文 LAS 模型中,使用了 5000 个左右的常用汉字为建模单元。由于汉字较传统常用的音素建模单元尺度更大,其对训练数据量的需求也会更大。依托于滴滴数据及强大的 GPU 训练集群,此基于注意力机制的模型在滴滴的多个语音产品上获得了很大的性能提升。
根据语音产品对于语音识别的实时性的要求的不同,可以把语音识别任务划分为实时识别和非实时识别:实时识别要求语音识别系统能快速准确的完成语音流到文本的转录,典型的应用有语音输入法、实时语音转录等等,此类任务要求识别能满足较高的实时性并且能够快速的返回识别结果;在非实时识别的情况下,可以实现把语音完整存储下来,识别的时候基本上没有苛刻的实时性要求,语音质检等业务就是典型的非实时识别任务。为了满足实时及非实时两种业务的需求,滴滴的基于注意力机制的 seq2seq 模型采用了两套方案。对于非实时识别系统,由于可以得到完整的语音,可以直接使用基于注意力机制的 LAS 模型,输入为每句的完整语音,LAS 可以直接输出每句话对应的文本。
对于实时识别系统,滴滴采用了基于注意力机制的 Neural Transducer 模型,按照固定的时间长度截取语音流(比如 300ms)作为一个 Block(时间片段),Neural Transducer 接受当前 Block 的语音信息,结合上一个 Block 的输出文本信息及神经网络状态信息,解码得到当前语音流片段的对应文本。通过这样的方法有效地控制解码时延。
滴滴语音团队指出,在滴滴非实时语音识别任务上,基于注意力机制的 LAS 的模型,能够得到 25% 的相对性能提升;基于 Neural Transducer 的实时识别方案在滴滴实时识别任务上,得到了 15% 的相对性能提升。另一方面,滴滴的 Attention 模型大小只有传统 CTC 模型的 1/5 的大小,而且在解码端弱化了甚至脱离了语言模型的依赖,解码的实时率性能获得了显著提升;在滴滴的一个大流量产品上,解码时间降为原来的 1/4,服务 QPS 预期提升 4 倍,在线计算服务器数量也会大大的减少,成本预算直接下降 75%。
参考文献
[1] G. Dahl, D. Yu, L. Deng, A. Acero. Context-Dependent Pre-trained Deep Neural Networks for Large Vocabulary Speech Recognition. IEEE Transactions on Audio, Speech, and Language Processing. 2012
[2] H. Sak, A. Senior, F. Beaufays. Long Short-term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling. INTERSPEECH 2014
[3] Y. Wu, M. Schuster, Z. Chen, Q. V. Le, M. Norouzi, W. Macherey, M. Krikun, Y. Cao, Q. Gao, K. Macherey, et al. Google’s Neural Machine Translation System: Bridging The Gap Between Human And Machine Translation. arXiv:1609.08144, 2016.
[4] C. Chiu, T. Sainath, Y. Wu, R. Prabhavalkar, P. Nguyen, Z. Chen, A. Kannan, R. Weiss, K. Rao, E. Gonina, N. Jaitly, B. Li, J. Chorowski, M. Bacchiani. State-of-the-art Speech Recognition with Sequence-to-Sequence Models. ICASSP 2018.
[5] T. Sainath, C. Chiu, R. Prabhavalkar, A. Kannan, Y. Wu, P. Nguyen, Z. Chen. Improving the Performance of Online Neural Transducer Models. arXiv:1712.01807, 2017.
[6] W. Chan, N. Jaitly, Q. Le, O. Vinyals. Listen, Attend and Spell: A Neural Network for Large Vocabulary Conversational Speech Recognition. ICASSP 2016.
[7] W. Zou, D. Jiang, S. Zhao, X. Li. A Comparable Study of Modeling Units for End-to-end Mandarin Speech Recognition. arXiv:1805.03832, 2018




