在大数据井喷的时代,各行各业所产生的数据就是一座座金矿,如何设计大数据应用,更有效、创新的发掘大数据的价值,也是行业内一直在追寻并探索的答案。
12 月 17 日,有极客邦 InfoQ 和神策数据共同策划的技术沙龙在中关村成功举办,来自诸葛找房、神策数据、91 金融和 51 理财的技术专家分享了大数据开发场景,建模,结果应用,扩展等技术内容,全面展示互联网金融、房产领域大数据的分析方法和价值,帮助参会者寻找新的数据利用突破点和应用模式。以下是分享内容的简单整理。
大数据在房产行业的应用探索(下载讲义)
诸葛找房合伙人 &CTO 张文战根据自身所在的领域,分享了诸葛找房的数据体系和架构(如下图),BASIC 里面包括很基础设施,URL META 适用来建立全国唯一房源编号的;房价预测基础数据来源于房产政策性信息、历史房价预估偏差、历史真实成交价格、历史挂牌价,起到一个参考的作用。楼盘字典这部分包含楼盘基本信息、凶宅信息、户型图、历史成交记录等信息。虚假房源字典则是房源质量评估系统评分较低的房源库。
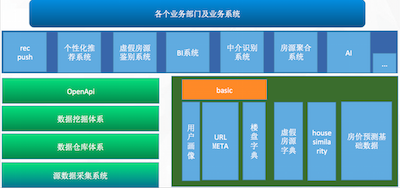
中介识别系统包括模式识别、虚假信息、中介号码库、用户⾏行为分析等,其目的就是为了识别出虚假房源:房源本身不存在、房源已售、中介冒充个人、描述不真实、价格异常等房屋信息。识别的技术方式包括通过成交记录、图片识别率、房源相似度等手段来识别。
为了获取更多有效数据,数据挖掘系统起到了至关重要的作用,数据挖掘系统的构成包括:数据源,数据预处理系统,特征⼯程,数据挖掘平台,算法库,算法评估系统,算法结果反馈及优化系统。
- 数据源:链家、我爱我家、爱屋及屋、搜房、豆瓣、贴吧、建委、合作商
- 数据挖掘平台:Job 调度、大数据可视化;
- 数据预处理系统:异构数据源、结构化处理、数据清洗;
- 特征工程:数据和特征决定数据挖掘上限;
- 算法库:统一定义 input、output,灵活适应;
- 算法评估及反馈优化系统:点击、转化、回炉策略、正负样本学习拟合;
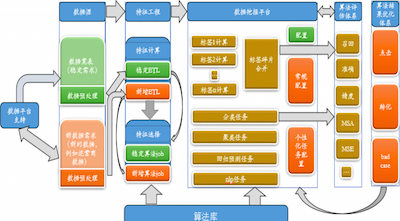
数据挖掘体系的算法库的功能在于提供各种算法包,统⼀定义了输⼊与输出规范,适用于相对应的数据挖掘工作。这其中就有三个基础版本:单机版,Hadoop 版,Spark 版,适用于不同的场景。而具体使用到的技术分类如下:
- 分类:LR,SVM,朴素贝叶斯,决策树,HMM
- 聚类:k-means,Dirichlet Process,Minhash,Canopy,Spectral
- 回归:Linear Regression
- 特征选择:SVD,PCA,ICA
- 关联规则:FP growth
- 推荐算法:ItemCF
- 时间序列:exponential smoothing
神策分析的设计与实现(下载讲义)
神策分析是一个支持私有化部署的用户行为分析产品,支持全端埋点、海量数据任意维度的实时分析,并且还提供了完全开放的 PaaS 平台特性。神策数据联合创始人兼首席架构师 付力力介绍了神策分析的产品理念,以及由此所决定的技术选型和架构设计的思路,并对几个核心模块的实现进行深度解析。
在设计之初,就要考虑客户需求,产品功能,技术选型等因素,同时还要考虑产品的私有化部署属性,对数据的安全与隐私、数据资产积累、数据的深度应用与二次开发都有着很高的要求。这其中的核心技术决策包括:可以私有化部署,并优化运维部署的成本;以开源方案为主,便于复用和客户二次开发;数据模型尽量简洁,减少 ETL 代价和使用成本;每天十亿级别数据量下,秒级导入,秒级查询;存储明细数据,随用随查。
关于技术实现,它的整个流程是这样的,先是数据接入,数据传输,然后是数据建模 / 存储,紧接着是数据查询,最后是数据可视化 / 反馈,将分析结果展示出来。整个架构图如下:
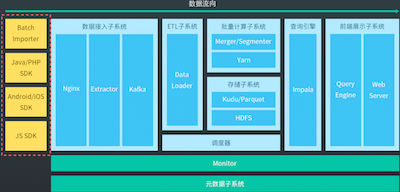
在前端埋点上,神策提供了三种不同的埋点方式,第一个是默认埋点:自动采集所有的页面浏览、控件操作、App 启动等;可视化埋点:采集指定的控件操作,无法自定义属性;代码埋点:自定义任意的事件和属性。在数据传输方面,使用了 Nginx、Kafka 等开源组件,其中 Nginx 作为据接收层,保证接入层的性能和高可用,而 Kafka 则提供了高可用的分布式消息队列,用作导入过程中的数据缓冲。
在数据存储方面,神策使用了 Kudu,一个新的开源存储引擎,用作 WOS (Write Optimized Store),来保证秒级的实时写入。数据查询上则主要通过神策自己的 QueryEngine 来生成 SQL,并提交给 Impala 执行。
付力力最后说到,由于神策分析主要是部署在客户的私有网络环境里,这样就需要一个强大的拥有自我修复功能的监控系统,在无人干预的情况下尽可能的保证系统的稳定运行。
利用大数据对金融界用户画像进行分析(下载讲义)
来自 91 金融的 CTO 宋传胜介绍了在互联网广告以及互联网金融领域,用户画像地位很重要,应用也很广泛。但是在独立的第三方金融系统中,如何获得大数据,并且通过大数据的分布式算法对用户进行画像分类和画像分析,是很关键的技术点。
首先是收集有价值的数据,来源是通过用户在各种网络设备上的行为沉淀的数据,金融机构会选择合适的数据,识别出同一个用户的不同行为,然后是建立模型,并且验证数据的可用性。为了避免数据重复,所以要确定用户的唯一 ID,采集不同维度的用户数据,包括结构化和非结构化的数据集。整个过程依靠任务调度系统进行数据挖掘,收集上来的数据涵盖 PV/UV、访问时长、地域、时间、跳出率、停留时间等等。
除此之外,还会有第三方数据采集的途径,包括桌面软件的 Cookie 植入、桌面安装软件列表特征抽取、提取 URL History,特征抽取、网站域名和分类、通过模板抽取查询词、Category 抽取、提取键盘输入信息等等。电商和社交环境下,关键的数据收集基本上来自类目、购物车、收藏、支付、转发、评论、关注、点赞等等。
宋传胜重点讲了数据挖掘模型的构建内容,LDA 文档主题模型涵盖用户文档、特征词汇(类目,行为,查询,网址)、主题属性;通过人工标注的方式来选取有用的数据;之后是将主题属性代入模型实现迭代训练。例如像识别羊毛客这样的风控应用,就可以识别出 IP 属性(代理、VPN、网关、服务器),以及用户的行为特征,包括发生时间,行为间隔等等。




