
大家好,我是来自京东搜索与大数据平台部的王超,很高兴和大家介绍京东在这次 618 大促中在技术方面做的较大的一个尝试,那就是在京东各大平台的主会场和首页的重要位置上,实现了“智能卖场”。
这次介绍我会分以下章节介绍,首先介绍这次京东智能卖场使用的场景,什么是智能卖场;二是介绍我们智能卖场中的整体算法和系统设计;最后是介绍我们的测试过程和实验结果。
京东 618 智能卖场业务场景
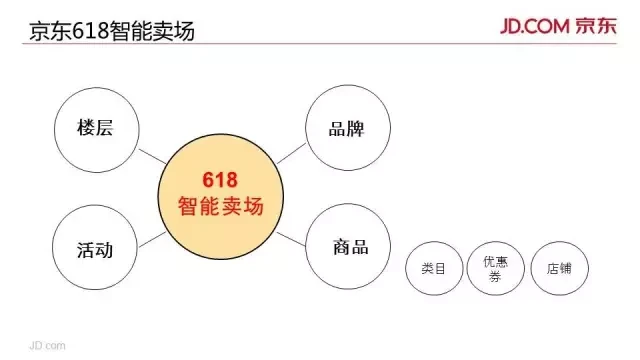
所谓的智能卖场,就是把之前由人工排布的会场元素,变成由算法来排序。
这里面我们实现了不止是传统的商品排序,还实现了楼层、活动、品牌、类目、优惠券及店铺等各种会场元素的算法排序,根据每个人的个人兴趣,给你展现出为你最感兴趣的 618 会场,而不是像以往一样,所有人是千篇一律的一样的促销活动。
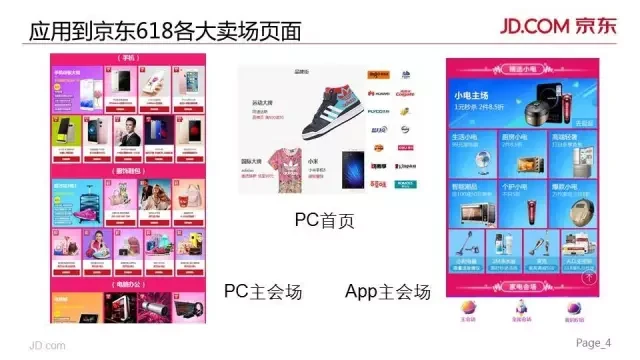
这里展示了一些截图,就是这次 618 京东在 PC 上的主会场、首页,以及 App 上的主会场、首页等位置,在重要区域都实现了个性化智能卖场的概念。
PC 主会场上可以看到,每个大的区块是一个楼层,里面是同一大类的促销活动,我们实现了楼层间的个性化排序,把你最可能感兴趣的楼层排到最上面,比如“手机”就是我看到的第一层。并且,在楼层内部,这些每个图片加链接形式的分会场,我们称之为“活动”,也是实现了个性化排序,我们对每个楼层内的几十个活动进行个性化排序,最终露出前 N 个活动。
中间的截图是 PC 首页上,使用了个性化排序的品牌模块。
右边是手机 app 京东的 618 主会场上,整个楼层都和内部的活动也都是采用了我们的个性化算法进行排序。
个性化算法和系统框架

我们做智能卖场的目的,是看到了对会场做个性化的巨大机会与需求,从商家角度讲,随着京东在各个市场上的扩展,大促期间期望能参与进来的商家越来越多,尤其在 app 上,在小小的屏幕上对所有人展示固定的几个商品或活动,已经远远满足不了商家的需求;而从用户角度讲,在这样小的区域内,所有人看到的都一样,那肯定无法满足所有人需求。
因此,我们认为通过对用户进行个性化精准投放,是一种可以大大提高销售转化率和满足用户需求,达到商家和用户双赢的一种方法。
算法框架
并且我们认为,在京东是可以做起这个事情的,从算法和人工对比看,算法方案在以下几方面是具备优势的:
- 个性化:我们利用京东积累的数据是能分析出消费者的个人兴趣的,从而对其是实现精准投放。
- 大数据驱动:每天京东都会积累上亿的行为数据,这是利用数据来源源不断的驱动算法的关键。
- 内容理解:在决策内容的排名时,机器可以快速充分的分析一个活动内的信息,比如里面有哪些商品,这些商品都是什么类别,销量如何等,而人工再有经验,也没法快速的全面的总结出这样的信息。
- 状态更新:利用算法来布局会场另外一个好处是随时可以根据内容的状态,替换内容,比如商品无货了,那立刻就可以知道并且自动去掉它的展示,排上都是有货的商品。而人工无法做到即时的调整,造成流量和位置上的浪费。
- 减少人工运营成本:采用机器来排,人工就可以解放出来。
算法 + 人工:
- 不过同时,我们现阶段的这次实践还没有完全去除对人工的依赖,我们目前的方案还是需要人工来选择一个模块里,一共都可以放哪些内容,也即选品,只不过不需要像以前那样还要排出顺序来。
- 另外,我们仍然需要人为设计和控制一些规则机制,来满足业务上对排序上的需求。
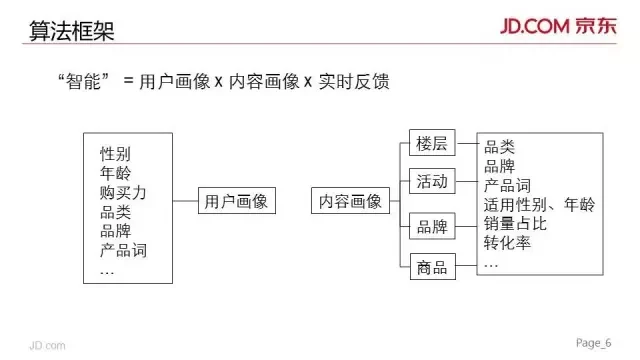
我们现在就先介绍整体的算法框架和特征体系:
整体上讲,我们的模型使用到三类特征:用户画像,内容画像和实时反馈数据。
用户画像就是我们对上亿级别的用户过去几个月或一两年内的行为数据进行挖掘,打标出的性别、年龄、购买力、品类偏好、品牌偏好、产品词偏好等标签。
内容画像,就是对要排序的各类元素,我们都抽象出各自的内容上的特征,如品类,品牌、产品词,以及挖掘出的适用年龄,性别,以及长期反馈型的特征,如销量占比、转化率等。
把以上两类画像中的一些标签类特征做结合,就能计算出交互类特征,从而实现个性化内容匹配。
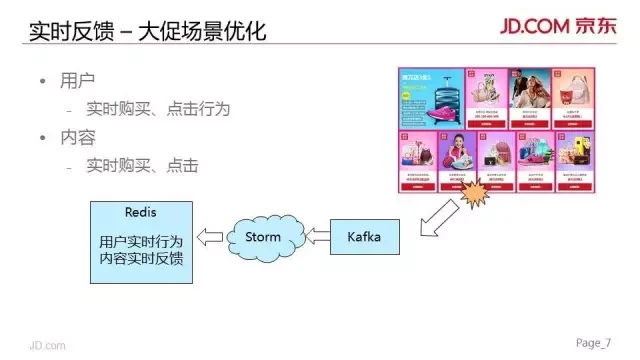
此外,我们在算法中还特别引入了实时反馈类的特征来捕获大促期间用户行为和内容的快速变化。
在用户维度,我们实时收集用户最近几个小时内的点击、购买行为,可以实现分钟级的延迟。
内容维度上,我们也会收集到内容的实时点击和部分购买行为,点击行为可以实现分钟级内的延迟。
这类特征对我们解决数据冷启,非个性化内容的排序、以及补充我们对内容理解上的不足等问题都起到了非常大的帮助。
系统框架
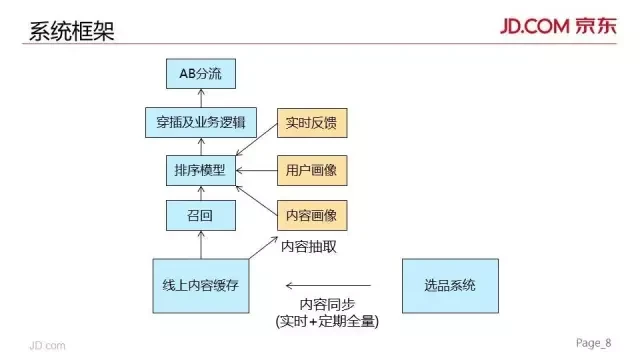
整体系统框架上,我们和传统的推荐系统比较类似。可能最大的不同就是在召回上,我们会根据前端要展示的楼层或模块 ID,来召回对应资源池内的内容元素。这里我们需要特别保证的是在选品系统和线上内容缓存之间要做到实时同步,我们通过实时消息通知和定期全量同步两种机制来保证。
内容同步过来后,我们会有 pipeline 抽取内容中的特征。
在排序阶段,我们设计的排序模型、穿插和业务逻辑对内容进行排序。
在最前面,为了我们内部实验的需求,以及和人工对比,我们也有 AB 分流系统。

在排序模型上,初期为了调试方便,并且也是由于缺少线上训练样本,我们还是采用了人工调参加简单的线性规则的方式来给内容打分。
后期当具备一定流量后,我们在部分模块上,如楼层模块,就开始采用了机器学习方法来训练模型,我们采用的是比较经典的一些方法,GBDT + 点击预估模型,在排序层,优化目标还是最大化点击效果。
相对人工调参,机器学习的模型在部分场景上还是有一定提升的,楼层模块点击率可以有 50% 左右的提升。

在实现过程中,还有其他一些关键环节:
业务逻辑上,之前提到我们会过滤掉无货或下架的内容;此外,我们还是要兼顾一些业务上的需求,重要的就是要平衡楼层、内容的曝光比例,保证一些冷门的类目也能有一定曝光机会,或限制一些特别热门的类目的曝光比例。
我们还特别考虑到如何对冷启用户进行优化。因为在大促期间,尤其是高峰期,大量用户是没有行为数据,或是非常稀疏。比如在 PC 上,这类请求要占到 50% 以上。这里我们就只能用非个性化的特征,尤其是实时反馈类的特征就起到了很大作用。
AB 测试及效果

最后介绍下我们智能卖场从无到有的一个迭代过程。
没有和以往人工模式的对比,我们是没法信服和证明算法模式的优势的。所以从始至终,我们都是保持有人工方案和流量作为对比的,并且在 618 之前,我们借助了多次平时的小型会场、节日的机会来测试我们的算法、系统。
最早我们在今年春节其实就开始过“智能卖场”概念的尝试,那时在年货节上部分品类可以达到 100% 以上的点击率提升。
在之后我们扩大了对智能卖场的支持范围,扩大到品牌、楼层、活动,甚至是优惠券、店铺,都在做个性化排序的尝试。其中对部分品类的测试,我们和人工对比都达到了 50~100% 以上的点击率或转化率提升。正是基于这些实验结果,我们才决定在这次 618,就在主会场和首页的核心位置上大规模采用“智能卖场”模式。
此外,即使在 618 期间,我们也是持续有和人工流量的对比,不过算法流量是占绝大部分。
最终结果页证明了智能卖场的巨大价值,这里可以以部分数字为例,PC 首页和主会场上的品牌模块是效果最为显著的模块之一,在 6/1-6/17 日期间,相对人工,日均点击率提升了 138%,UV 价值(GMV/UV 日均提升超过 200%;在 App 首页会场入口模块,在 6/18-6/20 期间,UV 价值最高有 100% 以上的提升。
Q&A
Q1:当前京东的大数据生产环境,有没有跟你们的京东云进行整合?对于中小型企业,您建议使用原生的 Apache 环境还是使用类似 cdh 这种集成环境?谢谢!
王超:我们这次 618 的大数据的生产环境就已经全部跑在京东云上了。对于中小企业,建议使用 cdh,有比较完整的配套软件服务,而且社区也很完善,使用者众多,遇到的很多问题在网上都可以找到答案 。
Q2:您提到之前小促场景实验了算法,如何保证 618 大促算法效果跟小促类似,谢谢
王超:这方面我们确实也是第一次尝试,首先京东这次 618 不是只有一天,在之前几天就已经有一些预热活动了,以及 PPT 中提到的更早些的小促,在这些预测活动中我们测试了和 618 当天场景非常类似的场景,搭建的会场、活动模式都比较相似;此外,我们特别搭建了一套分钟级别的实时数据指标监控系统,就是为了能在大促期间能实时捕获到异常。
Q3:个性化推荐用到了用户画像,那么你们是否用到 look alike model? 标签是稀疏的,你们是怎么存储的呢,谢谢
王超:我们用户画像中不同标签有不同做法,其中性别、年龄标签用到类似 look-alike 的做法,用种子用户的特征,来给其他相似用户或 item 打标;还有些标签,比如品牌偏好,是计算这个用户行为里的品牌在整体用户群体中的权重,以及在其自己所有行为里的品牌的权重的一个结合;
存储上,我们目前是有两层存储结构,在 hbase 中存储所有用户画像,在 redis 中缓存热点用户的,由于是缓存是分片结构设计的,存储量还可以接受。
Q4:个性化推荐主要用到了哪些算法,谢谢
王超:在智能卖场中,我们主要使用的就是 PPT 提到的用户画像和内容画像匹配的方式来做的,再加上各种特征组合,使用人工调权或点击预估模型打分,用户画像计算的方法刚才已经有些介绍了;
在其他一些推荐场景中,我们也会用到关联召回的方法;
总体上来讲,我们用到的推荐方法还是很多的,不同场景不太一样。
讲师简介
王超:京东搜索与大数据平台部门架构师及总监,先后负责京东商城的推荐和搜索业务,负责京东 618 智能卖场项目的整体规划和架构设计。在加入京东之前,曾担任雅虎美国的主任软件工程师,先后负责雅虎个性化新闻推荐系统和雅虎视频搜索的优化。本科和硕士毕业于北京大学计算机系。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论