本文翻译自: How Uber Manages A Million Writes Per Second Using Mesos And Cassandra Across Multiple Datacenters ,已获得原网站授权。
如果你也是 Uber 技术团队的一员,司机和乘客 App 每 30 秒就要发出一次定位数据,而你就要把这些数据全保存下来,你会怎么做?在 Uber 有很多类似的要实时处理的数据。
Uber 的解决方案是非常完善的。他们在 Mesos 上面运行了 Cassandra,基于这样的底层构建了自己的系统。Uber 的一位软件工程师 Abhishek Verma 在最近的一次非常精彩的谈话“ Cassandra on Mesos Across Multiple Datacenters at Uber ”( slides ) 中详细解释了这个架构。
你是不是也在做着类似的事情呢?在听 Abhishek 的谈话时你就会不由自主地冒出这个有趣的想法。
在现在这个时代开发者总是要做出许多艰难的选择。我们是不是该把程序全部署在云上?选哪个云?会不会太贵?怕不怕用上就脱离不开了?或者是不是该将云上和自建两种方式结合,精心打造出自己的混合型架构?或者还是为了避免由于没能达到 50% 毛利润的目标而被董事会纠结,索性不要上云,全部自建?
Uber 的最终选择就是自建,甚至更进一步,他们是把两个非常强大的开源模块拼接在了一起,打造出了他们自己的系统。需要的就是一种让 Cassandra 和 Mesos 可以一起工作的方法,而这正是 Uber 做的。
对于 Uber 来说做这个决定并不是那么困难。他们现金流非常充裕,所以能够请得到顶尖的人才,可以获得所需要的最好资源,以此来创建、维护以及更新这样复杂的系统。
由于 Uber 对于系统的目标是要让系统对于任何地方的任何人都有 99.99% 的可用性,所以对于系统在未来向无限种可能扩张这个目标来说,也是非常合情合理的。
但是当你听到这个谈话的具体内容的时候你就会意识到要做成这样的系统所有付出的惊人代价。这是不是一家象你这样的普通公司所能承受得了的呢?可能完全不行。如果你也对云持否定态度,总是觉得所有人都应该自建机房自己从头做起从硬件到软件地构建自己的系统的话,请你牢牢记住上面所说的这一点。
用钱来买时间通常都是划算的,而用钱来买技术就更是绝对必要的了。
就 Uber 的可用性目标而言,每一万个请求中只能允许最多有一个失败,那么他们的系统就必须构建于多个数据中心的基础之上。因为 Cassandra 已经被业界实践证实可以跨数据中心处理海量请求,所以用它做数据库的候选是完全可以胜任的。
而且,如果你想让交通运输对于任何地方的任何人都非常可靠,你就要非常高效地利用自己的资源。所以才需要使用类似 Mesos 这样的数据中心操作系统。据统计数据显示,在相同的服务器集群上复用多种服务可以帮你节约 30% 的服务器,这也就是节约了成本。选择 Mesos 的原因也是因为 Uber 的需求已经是要运行上万台服务器的集群,而在当时 Mesos 是唯一被证实能满足这个需求的产品。Uber 做的系统总是规模很大。
还有没有别的更有趣的发现?
- 可以在容器中运行有状态的服务。Uber 发现把 Cassandra 直接运行在服务器上,与把它运行在用 Mesos 管理的容器中相比,两者几乎没有什么性能差别,只有 5-10% 的损耗。
- 性能看起来不错,平均读延迟 13ms,写延迟 25ms,99% 的测试数据都很令人满意。
- 对他们最大的集群来说可以支持每秒超过一百万次写操作,以及数十万次读操作。
- 灵活性比性能更重要。在这样的架构下 Uber 获得了灵活性。在集群之间运行和分担负载都不在话下。
以下是谈话摘要:
系统最早期
在服务之间静态分配服务器。
比如,50 台服务器供 API 专用,50 台供存储用,等等,而且它们之间并不重合。
现在的系统
准备在 Mesos 上面运行所有的东西,包括 Cassandra 和 Kafka 之类的有状态的服务。
- Mesos 是一种数据中心操作系统,允许你针对数据中心来编程,就象是一个资源池一样。
- 在当时 Mesos 已被证实可以运行在数以万计的服务器上,这也是 Uber 的需求之一,所以他们才选了 Mesos。现在 Kubernetes 可能也能符合这个要求。
- Uber 自己构建了名为 Schemaless 的基于 MySQL 的分布式数据库,也就是说 Cassandra 和 Schemaless 将是 Uber 的两大存储选择。现有的基于 Riak 的系统都会迁移到 Cassandra 上。
单机服务器上可以运行不同种类的服务。
统计数据表示,在相同的服务器上复用服务可以让总的服务器需求减少 30%。这个数字是 Google 用 Borg 做的实验中总结出来的。
比如,如果一种服务会消耗非常多的CPU,那它就可以和另一种使用非常多存储或内存的服务共处得很好,它们两个可以在相同的服务器上运行。就提高了服务器使用率。
Uber 现在已经有了约 20 个 Cassandra 集群,计划在将来可能会有 100 个。
灵活性比性能更重要。你要能非常方便地管理这些集群,并在上面做各种操作。
为什么在容器中运行 Cassandra,而不是直接在裸服务器上运行?
- 目标是存储几百个 G 的数据,还希望它们能跨数据中心在多台服务器之间复制。
- 也希望在不同的集群之间做到资源隔离和性能隔离。
- 在一个共享集群中达到上面所有目标是非常困难的。比如,如果你的 Cassanra 集群已经超过了 1000 个节点,那就难以扩展了,或者会在不同集群之间产生性能的干扰。
生产环境
在两个数据中心(西海岸和东海岸)之间有约 20 个集群在同步数据。
最初是有 4 个集群的,包括中国。但在与嘀嘀合并之后,那些集群就关闭了。
两个数据中心共有约 300 台服务器。
最大的两个集群,每秒有超过一百万次写操作和约十万次读操作。
- 有一个集群存储的是位置数据,是由司机和乘客 App 每秒 30 秒就发送一次的数据。
平均读延迟为 13ms,写延迟为 20ms。
大多数采用的都是 LOCAL_QUORUM 一致性级别,也就是强一致性。
Mesos 背景知识
Mesos 将 CPU、内存和存储从物理服务器上抽象出来。
你将不再针对单台服务器,而是要针对一个资源池来编程。
线性扩展。可以运行在上万台服务器上。
高可用。使用 ZooKeeper 在配置好的复本内部做选举。
可以在 Mesos 容器内部运行 Docker 容器。
可插拔式资源隔离。Linux 上有 Cgroup 来做内存和 CPU 的隔离器,还有 Posix 隔离器。这些都是不同的操作系统上做资源隔离的方法。
两级调度。Mesos 代理把资源分配给不同的框架。框架再在内部调度自己的任务来使用这些资源。
Apache Cassandra 背景知识
Cassandra 对于 Uber 的使用场景非常合适。
水平扩展。在新节点加入时读写能力都可以线性扩展。
高可用。可以调节一致性级别,提供不同程度的容错性。
低延迟。在数据中心内部达到微秒级延迟。
操作简单。同构的集群,没有主库的概念,所以集群中没有特殊的节点。
丰富的数据类型。有列、复合主键、计数器和第二索引等。
容易使用其它开源软件。Hadoop、Spark、Hive 等都有可以接入 Cassandra 的连接器。
Mesosphere + Uber + Cassandra = Dcos-Cassandra-Service
Uber 和 Mesosphere 合作写出了 mesosphere/dcos-cassandra-service ——一个自动化服务,可以很容易在 Mesosphere 的数据中心及操作系统上自动化部署服务。
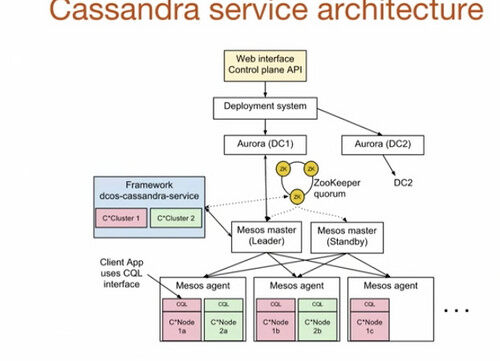
顶层是 Web 接口或控制层的 API。你定好你需要多少个节点、需要多少个 CPU、写好 Cassandra 配置,然后提交给控制层 API 即可。
Uber 部署系统的底层是 Aurora ,它是专用于运行无状态服务的,用于启动 dcos-cassandra-service 框架。
在例子中 dcos-cassandra-service 框架有两个与主 Mesos 交互的集群。Uber 在系统内使用了五个 Mesos 主,并用 ZooKeeper 完成选主操作。
ZooKeeper 也用于存储框架元数据:哪些任务在运行、Cassandra 的配置、集群健康状况等。
Mesos 代理运行在集群的每一台服务器之上。代理向 Mesos 主提供资源,主再把它们分配给具体的请求者。框架可以接受或拒绝分配给它的资源。在一台机器上可能运行多个 Cassandra 节点。
用的是 Mesos 容器,而不是 Docker 容器。
- 要覆盖掉五个默认配置(storage_port, ssl_storage_port, native_transport_port,rpcs_port,jmx_port),这样就可以在一台机器上运行起多个容器了。
- 使用了持久卷,这样数据就可以保存在沙箱目录之外了。如果 Cassandra 出了故障崩溃了或者重启了,数据仍然在持久卷上,还可以恢复出来。
- 动态预订技术用于保证在重新启动一个失败了的任务时,是有资源可用的。
Cassandra 服务操作
- Cassandra 有一个种子节点的概念,可以在新节点加入时启动一个进程来把数据迁移过去。在 Mesos 集群中创建了一种定制的种子提供者,在想自动替换 Cassandra 节点时可以启动它。
- Cassandra 集群中的节点数可以通过一个 REST API 来增加。它会启动新增节点,分给它种子节点,再启动其它的 Cassandra 守候进程。
- 所有 Cassandra 的配置参数都是可改的。
- 用了 API,死掉的节点就可以被替换掉。
- 要在副本之间修复数据并同步出去。修复是一个一个节点按主键去修的。这种操作不会影响性能。
- 清除操作会删掉不需要的数据。如果有新节点加入,部分数据被移到新节点上了,那旧节点上就要执行清除操作来删除已经移走了的数据。
- 多数据中心之间的数据复制可以通过框架配置。
多数据中心支持
- 每个数据中心都有单独安装的 Mesos。
- 每个数据中心都有框架的独立实例。
- 框架之间会相互通信,并周期性地交换种子。
- 这就是所有 Cassandra 需要的东西。通过启动另一个数据中心的种子进程,节点就可以学到各个节点的拓扑、数据等。
- 在数据中心之间轮询 ping 延迟是 77.8ms。
- 50% 的异步复制延迟是 44.69ms,95% 是 46.38ms,99% 是 47.44ms。
调度器执行
- 调度器执行被抽象成了计划、阶段和块等。调度计划下面有不同的阶段,一个阶段有不同的块。
- 调度器执行的第一阶段是同步,它会找到 Mesos,了解都运行了什么。
- 还有部署阶段,会检查配置中的节点是不是都已经存在了,并按需要部署它们。
- 一个块表现为 Cassandra 的节点描述。
- 还有其它阶段:备份、恢复、清理、修复等,取决于调用的是什么 REST 服务。
集群可以以一分钟一个新节点的速度启动。
- 希望能优化到 30 秒启动一个新节点。
- 在 Cassandra 中不同的节点不能并行启动。
- 通过每个 Mesos 节点会分配 2TB 的磁盘空间,以及 128GB 的内存。每个容器分配 100GB,每个 Cassandra 进程分配 32GB 堆空间(注意,这一点不太确定,细节可能有出入)。
- 用的是 G1 垃圾回收器,而不是 CMS,不需要做什么调节就可以有非常好的延迟和性能。
裸服务器与用 Mesos 管理的集群之间的对比
使用容器有什么性能代价?裸服务器意思是 Cassandra 没有运行在容器中。
读延迟:几乎没差别,5-10% 的开销。
- 在裸服务器上平均是 0.38ms,而在 Mesos 上是 0.44ms。
- 在 99% 的情况下,裸服务器是 0.91ms,而 Mesos 是 0.98ms。
读吞吐量:几乎没差别。
写延迟。
- 在裸服务器上平均是 0.43ms,而 Mesos 上是 0.48ms。
- 在 99% 的情冲印上,裸服务器是 1.05ms,而 Mesos 上是 1.26ms。
写吞吐量:几乎没差别。
更多引用文章请参考原文附录。




