本文翻译自 Elasticsearch cluster life cycle in eBay ,原作者为 Sudeep Kumar ,翻译已获得原网站授权。
Copyright 2017 eBay Inc. All rights reserved.
定义一个 Elasticsearch 集群的生命周期
eBay 的“Elasticsearch 即服务”(Elasticsearch as service,ES-AAS)平台名叫 Pronto,它可以为各种不同的搜索用例提供全面管理下的 Elasticsearch 集群。我们的 ES-AAS 平台部署在基于 OpenStack 的一个私有内部云环境里。平台现在管理着至少 35 个集群,支持跨多个数据中心的部署。为了实现对 Elasticsearch 集群的最优化管理,这篇文章针对定义一个集群生命周期的方方面面都提供了指导。在 eBay 系统里部署的所有 Elasticsearch 集群都符合我们在下图中描绘的自己定义的 Elasticsearch 生命周期。
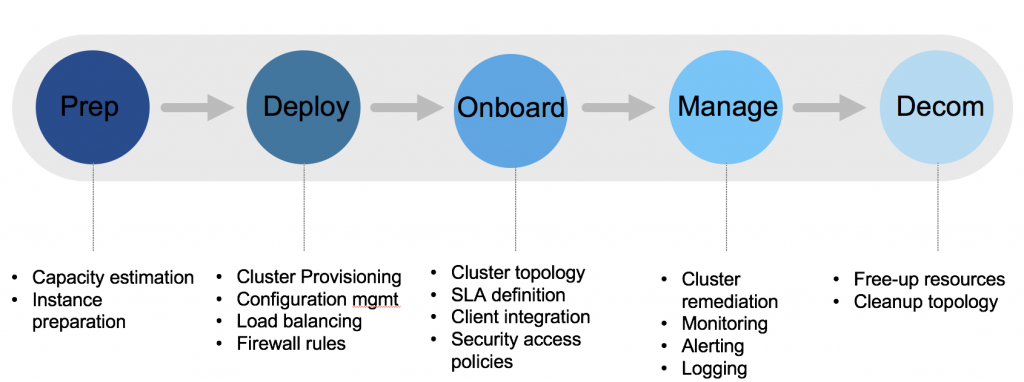
集群准备
当一个新的客户用例被提交到我们的 ES-AAS 平台上的时候,这个生命周期就开始了。
上线信息
客户的全部需求都会用一个上线模板记录下来,包括文档大小、保留策略、读写请求吞吐量等信息。根据客户提供的信息就可以估计集群的规模了,我们估计集群规模的方法是通过大量基准测试得出来的。上线信息在做集群规划、为客户定义服务等级协议等方面都非常有用。
在任何客户用例上线之前,我们都会从客户那里收集下列信息:
- 用例细节:包括对用例描述、重要性等相关的问题的询问结果;
- 规模信息:文档数量、平均的文档大小、每年的增长比例估计等;
- 数据读写信息:包括预期的索引和检索率、写入模式(批量模式或是单条)、数据新鲜度、平均用户数量,以及包含任何聚合、分页或排序操作的特殊检索请求等;
- 数据源与保留:数据源信息(比如 Oracle、MySQL 等)都记录在上线模板上。如果分片是基于时间的,那索引删除策略也要记录下来。一般来说,我们不把 Elasticsearch 用于保存关键应用的数据。
基准测试策略
在做基准测试之前,必须先了解一下你的虚拟机所处的底层基础设施的情况,这非常重要。如果你的测试环境是在云上,那就更要注意这个问题,因为这些信息都是针对终端用户抽象过的了。要小心各种可能的“吵闹的邻居”问题,特别是在多租户的环境里。
和许多人一样,我们也会先在现有的硬件设施和镜像上做一些额外的基准测试。存储在 Elasticsearch 集群里的数据都专属于客户自己的业务。想在属于不同用户的所有数据库里运行基准测试是几乎不可能的。因此,在做任何的基准测试之前我们都会先做一些前提假设,下面的这些假设条件是非常重要的。
- 客户端在对存储在我们部署的 Elasticsearch 集群里的数据进行任何访问时,都会使用 REST 路径。(没有传输客户端)
- 最早的时候我们保持 1GB 的内存对应 32GB 的磁盘空间这样的比例。(在我们从基准测试中得到经验之后,我们对此做了改进)
- 针对不同的副本数量(1、2 和 3 份副本),都有对应的仔细测试过的索引数量。
- 查询基准测试的语句都是 GetById 类的(查询语句都是定制的,对所有不同的查询语句都进行分析是不可行的)。
- 我们使用了固定大小的 1KB、2KB、5KB 和 10KB 的文档。
基于上述假设,我们还会进一步得出从性能角度考虑的最大分片大小(大概 22GB)、对于大批量的请求(约 5MB)的合适载荷大小,等等。我们使用了自己定制的 JMeter 脚本来做基准测试。最近 Elasticsearch 开发并开源了基准测试工具Rally ,这个也很有用。另外,根据我们的基准测试经验,我们还实现了一个容量估计计算器工具,可以向它输入客户需求,再根据客户用例来计算对基础设施的需求。我们也把这个工具直接分享给了终端用户,用它帮助我们避免了与客户之间的许多沟通。
虚拟机缓冲池
我们的Elasticsearch 集群是通过一个智能热缓冲层来部署的。热缓冲层由许多随时可用的虚拟机节点组成,这些节点都是根据某些预定义的规则提前构建好的。这样就能保证虚拟机可以以统一的方式分布在不同的底层硬件之上。有了这个缓冲层,我们就可以在几秒内快速扩张集群。另外,我们的修复引擎也可以利用这一层来成功的在现有的集群上拉起节点,不需要任何手工介入。我们发表过另一篇博客“借助于热缓冲实现的随时可用的虚拟机池”,里面描述了关于这个缓冲池的更多细节。
集群部署
集群的部署通过底层的 Puppet / Foreman 实现了完全自动化。我们不会详细讨论我们是如何利用 Elasticsearch Puppet 模块来部署 Elasticsearch 集群的。这些都在 Elasticsearch Puppet 模块的文档中描写得很充分了。Elasticsearch 的每个版本发布之后,都会有一个相应版本的 Puppet 模块发布。我们对这些 Puppet 脚本做了一些小改动来适应 eBay 的特别需求。Elasticsearch 的不同配置参数都根据我们的基准测试结果作了定制。一般来说,我们不会让 JVM 的堆内存大小超过 28GB(因为这样做会导致很长的垃圾回收周期),而且还会禁止 Elasticsearch JVM 进程的内存切换。不同的数据中心部署不同的集群,并使用负载均衡的 VIP(Virtual IP addresses,虚拟 IP 地址)来访问数据。
通常,每一套部署好的集群我们都会配置两个 VIP,一个用于读操作,另一个用于写操作。读 VIP 通常配置在客户端节点(或者协调节点)上,而写 VIP 则配置在数据节点上。我们的集群在这样配置之后,吞吐量明显上升。
部署图:
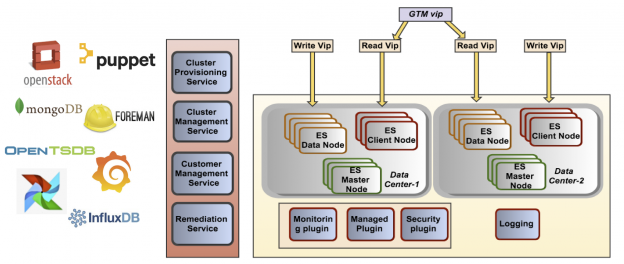
我们的平台上使用了许多开源软件,比如 OpenStack、MongoDB、Airflow、Grafana、InfluxDB(公开版)、openTSDB 等。我们的内部服务,像集群部署、集群管理和客户管理服务等,都使用了基于 API 的 REST 管理方式做部署和配置。在跟踪不同的客户对集群资源的使用情况上,这些软件也很好用。我们的集群部署服务主要用的是 OpenStack。另外,我们还用 NOVA 来管理计算资源(节点),用 Neutron API 来做负载均衡部署,以及用 Keystone 来做我们 API 的内部身份验证和授权。
我们的 Elasticsearch 集群不会使用跨区域的部署方式。因为存在网络延迟,我们不能采用这样的部署方式。但是对于跨区域的用例,我们使用了专门的集群。当集群跨区域部署时,客户端会做两次写入。我们也没有使用 Tribe 节点模式。
集群上线
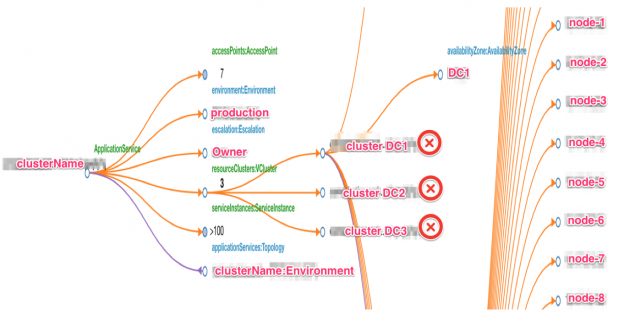
我们在客户业务上线的过程中构建集群拓扑,这样可以跟踪与集群基础设施有关的资源的使用情况。作为集群拓扑的一部分,元数据管理着区域部署信息、服务等级协议、集群管理信息等。我们用了 eBay 的内部配置管理系统(CMS)来以有向图的形式跟踪集群信息。还有一些外部工具与这个拓扑结合起来。这样的外部集成方式让我们可以从集中化的 eBay 专用系统的角度监控我们的集群。
集群拓扑示例:
集群管理
集群安全
我们集群上的安全功能是通过定制的安全插件提供的,它可以对 Elasticsearch 集群的使用情况进行审计和鉴权。我们的安全插件可以拦截消息,并使用内部的认证框架做基于上下文的审计和鉴权。我们也支持对客户端 IP 做显式的白名单配置,这对配置 Kibana 或其它的外部 UI 仪表盘非常有用。配置的管理员用户对 Elasticsearch 集群拥有完全的访问权限。我们建议大家使用基于 TLS 1.2 的 HTTPS 来实现客户端与 Elasticsearch 集群之间的安全通信。
下面这段代码是一段简单的安全规则例子,可以配置在我们部署的集群上。

在上面的示例代码中,“enabled”字段控制着是否启用安全功能。“whitelisted_ip_list”是一个数组,记录所有在白名单里的客户端 IP 地址。所有对索引的开、关或删除操作都只能由管理员用户执行。
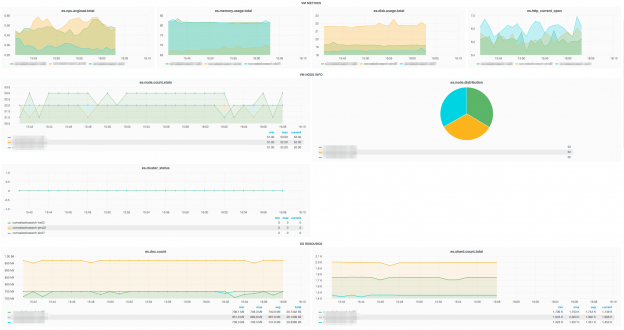
集群监控
集群监控是通过定制的监控插件实现的,它可以从各个 Elasticsearch 节点中把 70 多个指标推送到后端的基于 TSDB 的数据库中。插件基于推的模式工作。外部的仪表盘使用 Grafana 来处理 TSDB 数据库中的数据。我们还在 Grafana 仪表盘上创建了定制的模板,这样就可以很方便地实现对我们集群的集中式监控了。
我们用了一套内部的告警系统来基于存储在 OpenTSDB 中的数据配置基于阈值的告警。根据不同的轻重级别,现在我们已经为集群配置了 500 多种活跃的告警。告警主要分为“错误”和“警告”两大类。如果发生了“错误”类的告警,告警事件马上会被 DevOps 团队或者我们的内部自动修复引擎处理,具体取决于我们对告警规则的配置。

在部署集群的过程中,可以根据不同的阈值来产生告警。比如,如果一个集群的状态变成红色了,那就会抛出一个错误。而如果节点的 CPU 使用率超过了 80%,那就会抛出一个警告。
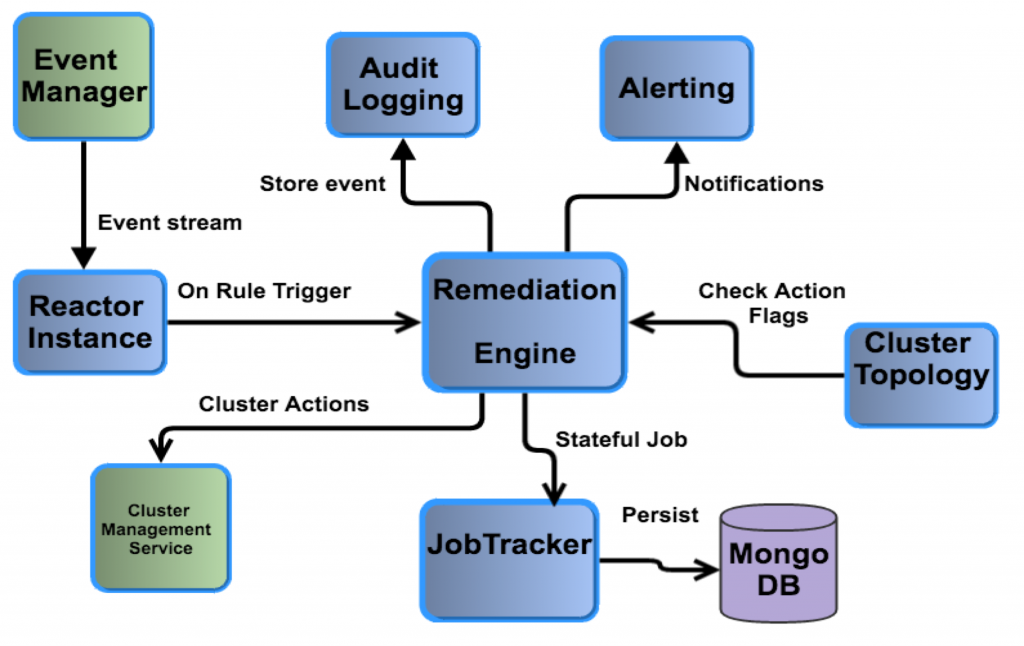
集群修复
收到任何集群内的异常事件时,我们的 ES-AAS 平台都可以自动采取修复动作,具体是由我们定制的“熄灯管理”(Lights-Out-Management,LOM)模块来定义的。这些自动修复模块可以极大地减轻我们 DevOps 团队的手工劳动量。熄灯模块使用基于规则的引擎来监控集群上抛出的所有告警。反应器实例维护着所有已发生的告警事件的上下文,可以根据集群拓扑状态(“自动”模式开或关)来采取修复动作。比如,如果某个集群有个节点宕机了,而且在接下来的 15 分钟内还没能恢复正常状态返回集群,那修复引擎就会通过我们的内部集群管理服务来替换掉这个节点。另一种可选的模式是将告警事件发送给 DevOps 团队,而不是自动采取修复动作。熄灯模块采取的所有行动都会被记录,作为有状态的任务持久化地记录在后端的 MongoDB 数据库中。由于这些任务本身的有状态特性,在需要时就可以重试或者回滚。在同时我们还保留了审计日志,来记录由我们的熄灯模块采取的所有修复行动的历史。
集群日志
在部署标准的 Elasticsearch 系统的同时,我们也会部署我们定制的日志库。这个库会通过一个名为 Sherlock 的内部系统来把所有 Elasticsearch 应用程序的日志推送到后端的 Hadoop 数据库里。这些集中收集起来的日志可以以集群或节点的不同级别查看。一旦 Elasticsearch 日志数据被传上了 Hadoop,我们就可以在日志库上运行每日定时的 PIG 任务,来生成对错误日志或慢日志的计数报告。一般情况下我们会把日志级别设成 INFO,在需要调查问题的时候,我们也会在很短的时间段内把日志级别设成 DEBUG,这样就可以把更细致的日志收集到后端的 Hadoop 数据库中了。
集群下线
我们根据一个集群的下线流程来做 Elasticsearch 的主要版本升级。对于 Elasticsearch 集群的重大升级,我们会用我们可用的最新版的 Elasticsearch 生成一个新的集群,把旧的或现有版本的 Elasticsearch 集群中的所有文档都复制到新的集群中。客户端(用户程序)会把新的写入同时写入新旧两个集群,直到新集群中的数据全补齐了。在完成数据的奇偶校验之后,就可以下线旧集群了。除了释放系统资源之外,我们还会清理所有相关的集群拓扑。Elasticsearch 也提供了迁移插件,用于检查是否可以就地直接对 Elasticsearch 进行大版本升级。小版本的 Elasticsearch 更新是按需进行的,通常是就地升级。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




