本文写给想入门机器学习又苦于大学高数基本不会,高中数学基本忘光,就想入门中一窥的普通程序员们。能够帮助有工程经验的程序员(非算法工程师)快速上手 TensorFlow。
机器学习亦或是深度学习一直是大热话题,网上各式教程林林总总层出不穷。大多上来就讲 CNN、RNN、gradient descent。概念太多,可能一个简单的求导就会你让的想不起是怎么考上大学的。所以本文尽量少讲或者不讲知识点和理论零公式纯实战入门 Tensorflow 的 hello world,所以很多地方只会给结论不会讲为什么。
准备
正文
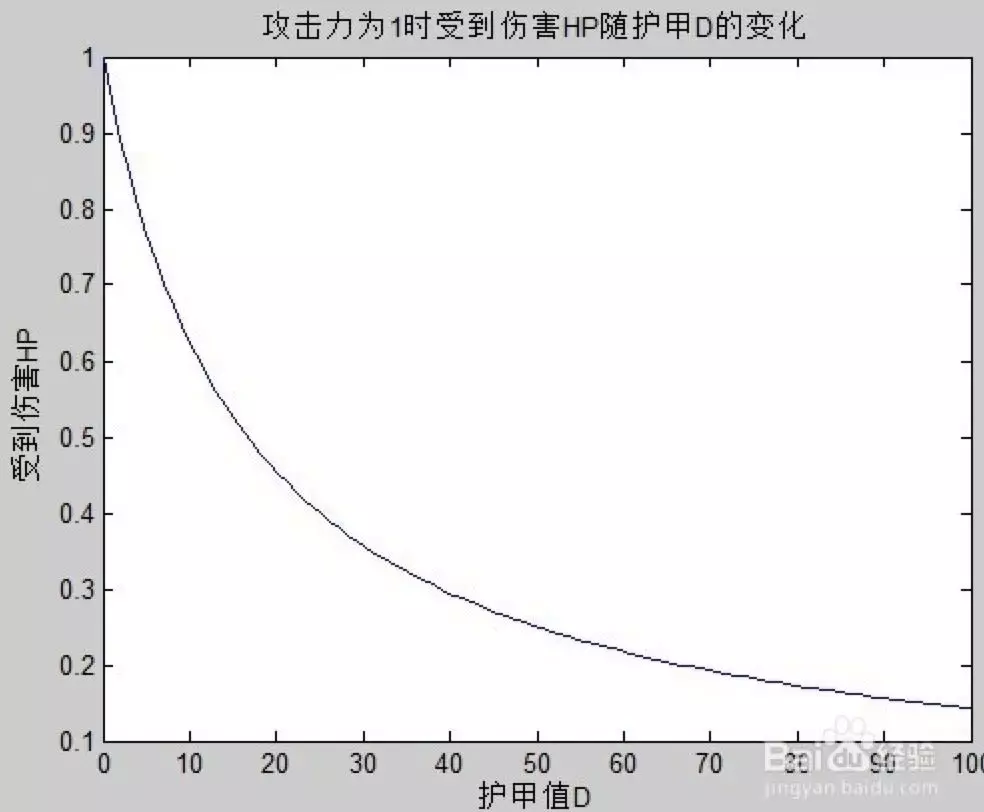
机器学习类似于要解一个数学题,题目的条件固定,求一个答案。解法可能非常非常多,但是只要做出来就能得分。我们今天要解的题目是王者荣耀中的攻击和最终伤害的关系。是每多增加一点攻击就多增加一点伤害吗?如果大家有 dota 类的 moba 游戏经验会知道,防御力的减伤效果并不是等比例增加的,下图是我网上随便找的 dota2 的物理伤害和护甲关系曲线。
大概意思就说你在出了一件物理防御大件的时候效果会非常明显,再出第二件第三件的时候效果不会有第一件那么明显。所以今天的题目就是,王者荣耀攻击和伤害会有类似关系吗?
接下来我们会做一个监督学习中的最简单最简单的线性回归( linear regression)来解这个问题。接下来分 3 步来分解这个问题。第一步,定义 model。第二步,定义 lost function。第三步,寻找最 match 的 model 的参数。这个步骤类似把大象装冰箱,或是开发个网站需要 MVC 分层,套路相对固定。
当然还有个定 0 步,收集数据。我这边使用姜子牙训练营模式站撸木桩韩信的方法收集了 30 条数据。收集的方法是不断的切换无特效的纯攻击装和升级。
攻击:289., 389., 409., 569., 649., 659., 739., 759., 779., 799., 819., 169., 264., 291., 311., 324., 331., 344., 351., 411., 431., 511., 591., 691., 791., 209.0,159.0, 169.0, 189.0, 891.
伤害:175., 236., 247., 348., 395., 397., 446., 460., 470., 486., 499., 102., 160., 175., 189., 196., 201., 208., 211., 250., 260., 310., 358., 420., 480., 126.0,96.0, 102.0, 114.0, 540.
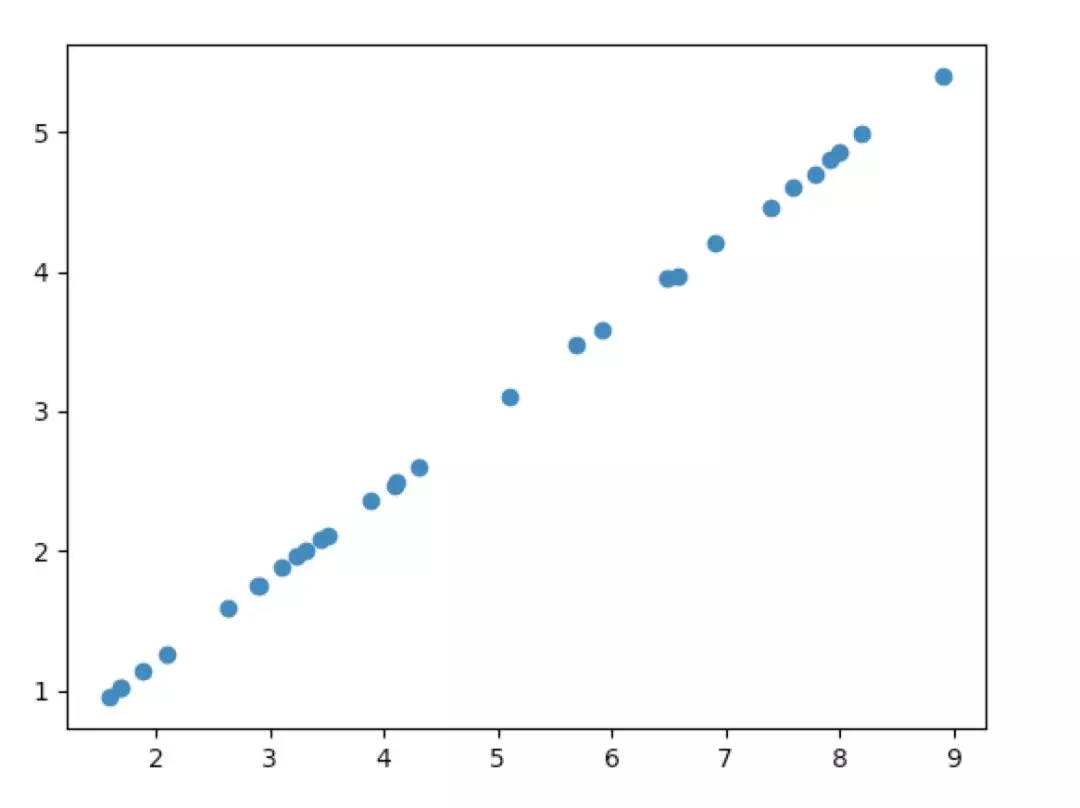
下面贴上数据的分布可以看到还是比较均匀的,同时通过比较直观的感受也可以指导我们定义 model。
python
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
复制代码
好了,我们现在开始一段一段的来写 tensorflow 的 hello world。
第一段 import3 个必要类库
1,numpy 一个数组处理库。
2,tensorflow 我们今天的主角。
3,matplotlib 绘图库用来最后验证结论。
python
# 再看这里先定义两个猜测存在的变量w、b,tf.Variable([初始值], dtype=变量类型),Variable就是tf中的定义变量的封装了
w = tf.Variable([1.0], dtype=tf.float64)
b = tf.Variable([0.0], dtype=tf.float64)
# 最后看这里我们再定义两个变量x(攻击)、y(伤害),因为我们这个地方还没导入数据,但是又要提前定义,所以tf为我们贴心的设计了placeholder用于解决这种情况
x = tf.placeholder(tf.float64)
y = tf.placeholder(tf.float64)
# 先看这里,我们先假设最终的答案是 伤害 = 攻击力 * w + b 其中w和b是我们猜测可能存在的影响变量
linear_model = x * w + b
复制代码
第二段的内容比较多,我把解释直接写在了注释里。
python
#training & testing data
atk_train = np.array( [289., 389., 409., 569., 649., 659., 739., 759., 779., 799., 819., 169., 264., 291., 311., 324., 331., 344., 351., 411., 431., 511., 591., 691., 791., 209.0]).astype(np.float32) / 100
damage_train = np.array( [175., 236., 247., 348., 395., 397., 446., 460., 470., 486., 499., 102., 160., 175., 189., 196., 201., 208., 211., 250., 260., 310., 358., 420., 480., 126.0]).astype(np.float32) / 100
atk_test = np.array([159.0, 169.0, 189.0, 891.]).astype(np.float32) / 100 damage_test = np.array([96.0, 102.0, 114.0, 540.]).astype(np.float32) / 100
复制代码
第三段导入了训练数据和验证数据,这个地方我们取了 4 条数据作为 testing data,剩下 26 条数据作为 training data。这里有个知识点,我们一般大概抽样 20%左右的数据用于验证模型正确性,80%的数据用于训练。这个比例当然不是绝对的,根据场景选择合适的。机器学习的模型都是训练出来的,这个不用再解释了非常好理解。注意到这里在最后我们所有的数据都一个除以 100 的操作,这里是因为我们在后续训练的过程中过大的数会导致 float 溢出,所以同意缩小 100 倍再进行后面的运算。
python
#loss function
loss = tf.reduce_sum(tf.square(linear_model - y))
#optimizer
optimizer = tf.train.GradientDescentOptimizer(0.001)
train = optimizer.minimize(loss)
#accuracy
correct_prediction = tf.abs(tf.cast(linear_model, tf.int32) - tf.cast(y, tf.int32)) < 2
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
复制代码
第四段代码会稍微难以理解,一般的机器学习教程可能这个地方要讲一个小时。
我们刚才定义了一个 linear_model 也给他初始化了一些参数,但是我们怎么样去衡量某个参数是否是好的呢?所以我们需要一个评分标准,这个标准就是 loss function。这个函数返回的数字越小那么意味着参数越优秀。
tf.reduce_sum(tf.square(linear_model - y))是什么意思呢,linear_model 是我们预测的答案,y 是标准答案。我们用(linear_model - y)的平方来表示是否最接近标准答案,很明显 0 是最完美的情况。然后 reduce_sum 是什么意思呢,是分别拿所有的 training data 的最终反馈一一相加。这就是我们定义的 loss function。
optimizer 是优化器,我们已经定义好了 model 和 loss,怎么样去优化参数呢,就需要一个优化器就是 optimizer,这个地方直接使用 tf 已经封装好的 tf.train.GradientDescentOptimizer(0.001),这个优化器用到的算法是梯度下降。这个算法是怎么来的,又有哪些问题,教程很多这里就略过不讲了,目标就就是知其然。
我们只需要知道 GradientDescentOptimizer 就是可以用来优化参数,0.001 是所谓的 learning rate 学习的速率,这里也是需要根据你的模型定义一个合适的值,过大过小都会出问题。
再下面一行我们定义真正要训练的目标,train = optimizer.minimize(loss)目标就是用 optimizer 求 loss 的最小的结果。
再后面的 accuracy 是算最终的正确率,这里我们把正确率定义为预测的伤害值在正负 2 就算预测准确。
python
#初始化所有变量
init = tf.global_variables_initializer()
#训练的时候,tf规定必须运行在一个session里。所以我们new一个session
sess = tf.Session()
并且初始化他
sess.run(init)
#开始训练,循环1W次
for i in range(100000): # 传入要训练的train, 和需要的训练数据
data = sess.run(train, {x: atk_train, y: damage_train})
复制代码
第五段代码,终于开始模型训练行数比较多又比较简单,所以也写在了注释里。
python
#evaluate training accuracy
curr_w, curr_b, curr_loss, curr_accuracy = sess.run([w, b, loss, accuracy], {x: atk_train, y: damage_train})
print("w: %s b: %s loss: %s accuracy: %s" % (curr_w, curr_b, curr_loss, curr_accuracy))
curr_w, curr_b, curr_loss, curr_accuracy = sess.run([w, b, loss, accuracy], {x: atk_test, y: damage_test})
print("w: %s b: %s loss: %s accuracy: %s" % (curr_w, curr_b, curr_loss, curr_accuracy))
复制代码
第六段代码,之前训练的每次循环都会改变我们最开始定义的 w 和 b 变量的值。一万次之后会发生什么呢?所以需要打印验证一下我们训练的结果。第一行输出传入的 training_data,第二行传入的是 testing data 已验证参数是否 overfitting。
output:
w: [ 0.6076637] b: [-0.00811569] loss: 0.00450731719102 accuracy: 1.0 w: [ 0.6076637] b: [-0.00811569] loss: 4.32571875675e-05 accuracy: 1.0
复制代码
后记
哇,我们可以看到最终 w 在约等于 0.6 b 约等于 0 的时候,预测的正确率无论在 testing set 上面还是在 training set 上到表现很好。我们可以得出结论 伤害=攻击力 x 0.6。这个结论和防御力的减伤关系完全不一样。大概意思就是你每加一点攻击就可以得到多一点的伤害。为什么会有这个 0.6 呢,是因为木桩韩信的减伤。所以 ADC 在对手肉盾减伤比例已经非常高的了的时候,需要出一件破甲弓(按百分比减少防御)效果会比再出一件输出装效果要好。如果对手没有肉择不需要再出破甲弓。
做到这里我们终于用机器学习的方法获得了打王者荣耀的小 tips!
如果有下期,我可能会尝试用 Logistic Regression 做一下王者荣耀中的英雄分类问题。
下面是完整可以运行代码
python
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
#Model parameters
w = tf.Variable([1.0], dtype=tf.float64)
b = tf.Variable([0.0], dtype=tf.float64)
#Model input and output
x = tf.placeholder(tf.float64)
y = tf.placeholder(tf.float64) linear_model = x * w + b
#training data
atk_train = np.array( [289., 389., 409., 569., 649., 659., 739., 759., 779., 799., 819., 169., 264., 291., 311., 324., 331., 344., 351., 411., 431., 511., 591., 691., 791., 209.0]).astype(np.float32) / 100
damage_train = np.array( [175., 236., 247., 348., 395., 397., 446., 460., 470., 486., 499., 102., 160., 175., 189., 196., 201., 208., 211., 250., 260., 310., 358., 420., 480., 126.0]).astype(np.float32) / 100
atk_test = np.array([159.0, 169.0, 189.0, 891.]).astype(np.float32) / 100
damage_test = np.array([96.0, 102.0, 114.0, 540.]).astype(np.float32) / 100
#loss function
loss = tf.reduce_sum(tf.square(linear_model - y))
#optimizer
optimizer = tf.train.GradientDescentOptimizer(0.001)
train = optimizer.minimize(loss)
#accuracy
correct_prediction = tf.abs(tf.cast(linear_model, tf.int32) - tf.cast(y, tf.int32)) < 2
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#training loop
init = tf.global_variables_initializer()
sess = tf.Session() sess.run(init)
for i in range(100000):
data = sess.run(train, {x: atk_train, y: damage_train})
#evaluate training accuracy
curr_w, curr_b, curr_loss, curr_accuracy = sess.run([w, b, loss, accuracy], {x: atk_train, y: damage_train})
print("w: %s b: %s loss: %s accuracy: %s" % (curr_w, curr_b, curr_loss, curr_accuracy))
curr_w, curr_b, curr_loss, curr_accuracy = sess.run([w, b, loss, accuracy], {x: atk_test, y: damage_test})
print("w: %s b: %s loss: %s accuracy: %s" % (curr_w, curr_b, curr_loss, curr_accuracy))
复制代码
本文转载自公众号贝壳产品技术(ID:gh_9afeb423f390)。
原文链接:
https://mp.weixin.qq.com/s/d14Qip_NN2eWAelLpNViKg














评论