

踏上征途
在上一篇文章中我们讨论了迁移到云也就是 GCP(谷歌云计算平台)的原因。一旦确定了迁移,我们就开始问自己三个问题:
我们的云架构在第一天会是什么样子?云平台的确可以让我们做很多令人兴奋的事情,但我们究竟希望自己的 MVP 看起来如何呢?
我们该如何实现?构建一个全新的云环境很容易,但是要把一个现有的基础设施平稳迁移到云上就没有那么容易了。
我们的环境在一年后又会是什么样子?我们知道自己的基础设施不会在第一天就很完美,这没关系,但我们希望会在接下来成功。
我会在这里详细讨论第一个问题。
MVP 架构
单单要求开发团队迁移到云上已经很困难了,而在迁移过程中又不断要求他们重新设计原有的应用程序,这就给整个过程带来了很大的不确定性。所以当我们不能在 GCP 中找到适合我们基础设施的替代品时,我们会尽量避免重新设计原有架构。
即便这样,GCP 上的很多功能已经很棒了,也为我们的基础设施提供了一些足够直接的转换方式,我们也觉得在迁移时进行这些切换是非常适合的。
首先,我们保留的部分:
我们的本地环境有一个单逻辑内部网络。内部服务通过私有 IP 进行通信,大部分通过 Hashicorp Consul 进行协调。我们认为保留这一点对应用程序团队至关重要,至少在迁移期间是这样的。通过使用专用互连和共享VPC网络,我们为开发人员提供了一个就像本地数据中心扩展一样的云。
Liveramp 的大数据处理核心 ETL 和连接管道都运行在 Cloudera Hapdoop 平台上。这一点不会改变,至少目前不会。
尽管本文的重点不是我们的安全和数据隐私决策,但它们与我们做的每一件事都息息相关。我们的运营团队保留了对数据权限和网络规则的控制权。云平台让开发人员更加强大,但也使他们更容易做出非常愚蠢的决定。只有当你知道你不能意外泄露客户数据时,你才能更容易进行安全快速的开发。
那我们又需要改变那些部分呢?有很多,但这里将重点关注下面的三种技术:
在本地数据中心,我们很自然地选择 Hadoop HDFS 来保存持久数据。虽然我们的 HDFS 集群在迁移时仍然运行良好,但无停机或无中断的维护和升级要求让我们倍感压力。随着公司的发展,我们能够跟产品团队协调的停机时间也越来越短,直到再也无法在规定停机时间内完成升级。我们知道我们想使用 GCS(谷歌云存储),只有这样才可以保持作为开发团队的灵活性。
在本地数据中心,我们使用 Chef 管理所有的虚拟机。我们在 Chef 中嵌入了很多逻辑,也尝试在云平台中使用 Chef 管理虚拟机,但是效果不佳。再加上 Docker 和 Kubernetes 为我们提供了非常好的使用体验,我们最终在新环境里完全放弃了 Chef。
最后一点,我们认为 Google 的 BigTable 可以很好地替代我们自主研发的键值数据存储。放弃一个已经使用了这么久的工具的确令人难过,但只有这样才能让我们专注于那些新的令人兴奋的挑战。
云上 Hadoop
接下来,我将着重介绍一下我们的 Hadoop 基础设施,包括过去和现在。我会简要介绍一下我们的基础设施,以及我们在 GCP 上的构建。
下面是我们本地 Hadoop 集群的一个高度简化视图:
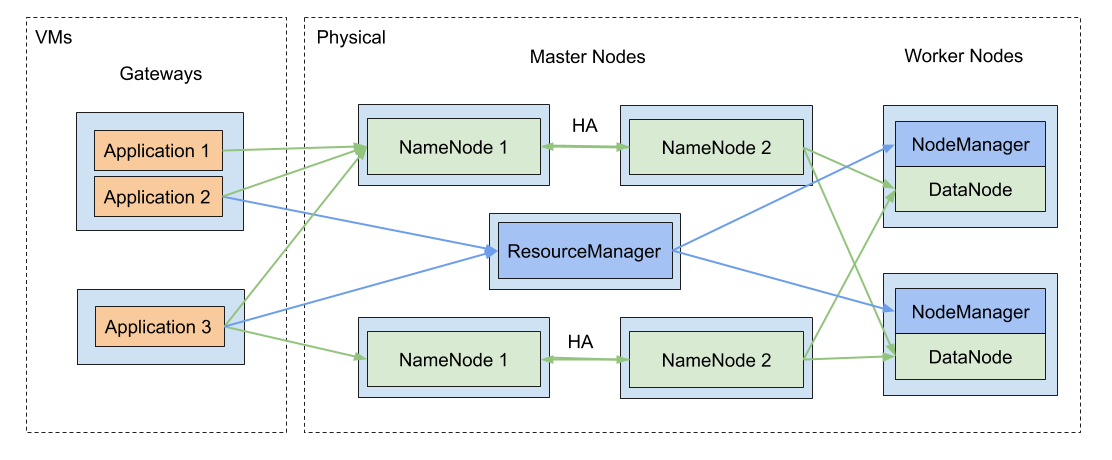
为保持简洁,该图省略了 Journal Nodes、ZooKeeper 和 Cloudera 管理角色。值得一提的是,该生产环境集群能够:
在不同开发团队之间共享;
在不随负载扩展的物理节点上运行;
从网关虚拟机启动作业;
将所有数据存储在一个 HDFS 联邦中(4 个 HA NameNode 对);
自 2009 年以来持续运行(除了某些系统升级的时段)。
毫无疑问,HDFS 是最具可伸缩性的本地文件系统,但与云原生的对象存储(S3,GCS)相比仍有一些缺点。例如,数据会随着实例的销毁而丢失(除非你还保留了持久磁盘记录)。在设计云集群时,我们知道有以下需求:
能够长期运行的临时集群(有问题?结束当前集群重启一个开始就好);
GCS 中所有重要的数据;
按应用程序团队隔离集群;
快速自动伸缩;
从 GKE(谷歌 Kubernetes 引擎)发起工作任务。
所以,我们得到了如下所示的设计:
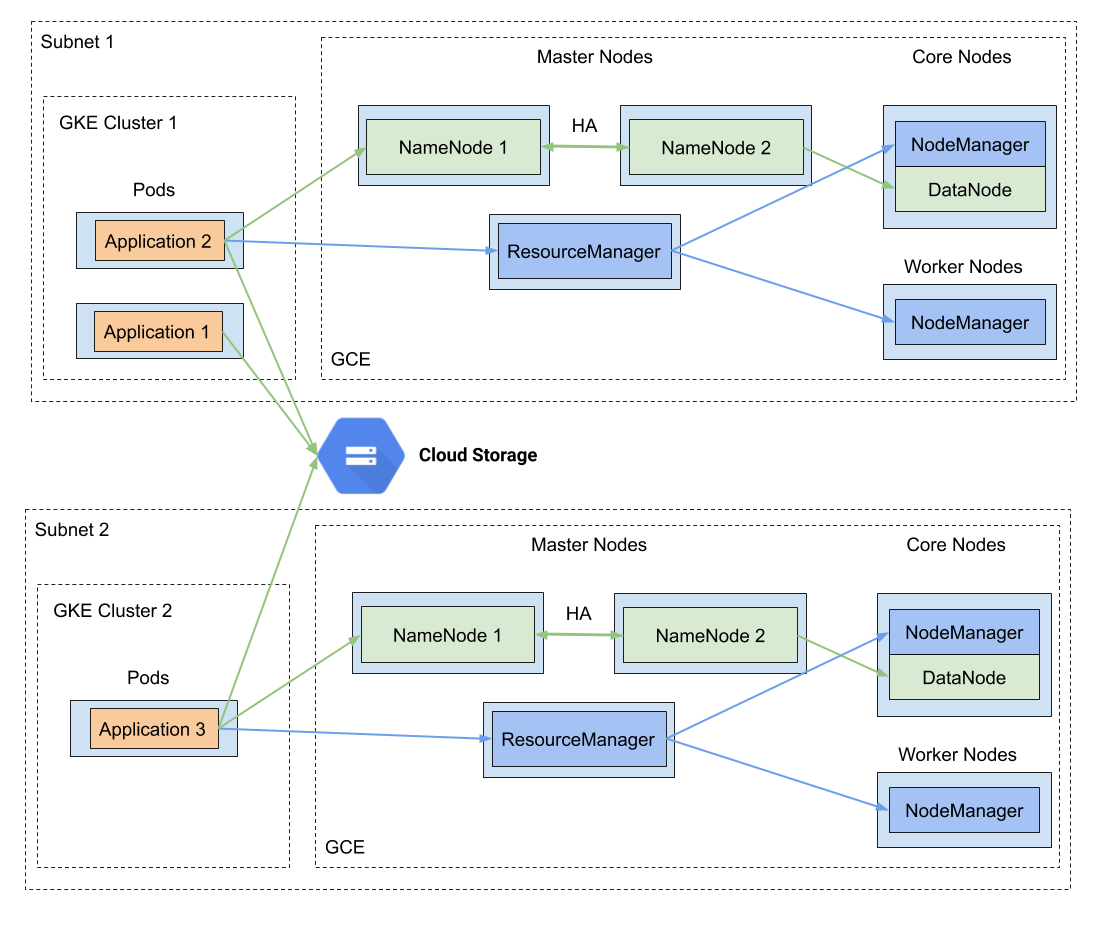
上图包含了很多内容,让我们逐个分析:
不同的集群按应用程序团队运行在不同的子网中;
工作任务从 GKE 发起而不是从虚拟机发起。每个 pod 中只包含一个应用程序,不再需要手动将应用程序打包到虚拟机上;
HDFS 仍然存在,但只有很少的一部分:YARN 使用 HDFS 保存 JobConf、分布式 Cache 和应用程序日志。但所有的应用程序数据都存储在 GCS 上;
因为几乎不怎么使用 HDFS,所以我们只需要几个数据节点。大多数 worker 节点只是节点管理器。它们可以根据应用程序负载快速伸缩。
我会在另一篇文章中更详细地讨论这个问题,但重点是,临时的去数据化基础设施让我们在配置和机器类型上迭代的速度比在物理机器上快了 1000 倍。
这些决定为我们的迁移提供了一个起点。在下一篇文章中,我将讨论迁移的实现细节问题,重点讨论如何在吞吐量有限的情况下处理数据复制。
原文链接:
https://liveramp.com/engineering/migrating-a-big-data-environment-to-the-cloud-part-2/
相关阅读:
大数据公司 LiveRamp 上云记(一):为什么选择 GCP?

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论